Click the card below to follow「AI Vision Engine」public account
( Please add a note: direction + school/company + nickname/name )


Large-scale generative models like DeepSeekR1 and OpenAI-O1 benefit greatly from Chain of Thought (CoT) reasoning; however, improving their performance often requires massive datasets, large model sizes, and full parameter fine-tuning. While Parameter-Efficient Fine-Tuning (PEFT) helps reduce costs, most existing methods primarily address domain adaptation or hierarchical allocation, rather than explicitly customizing data and parameters based on different response requirements.
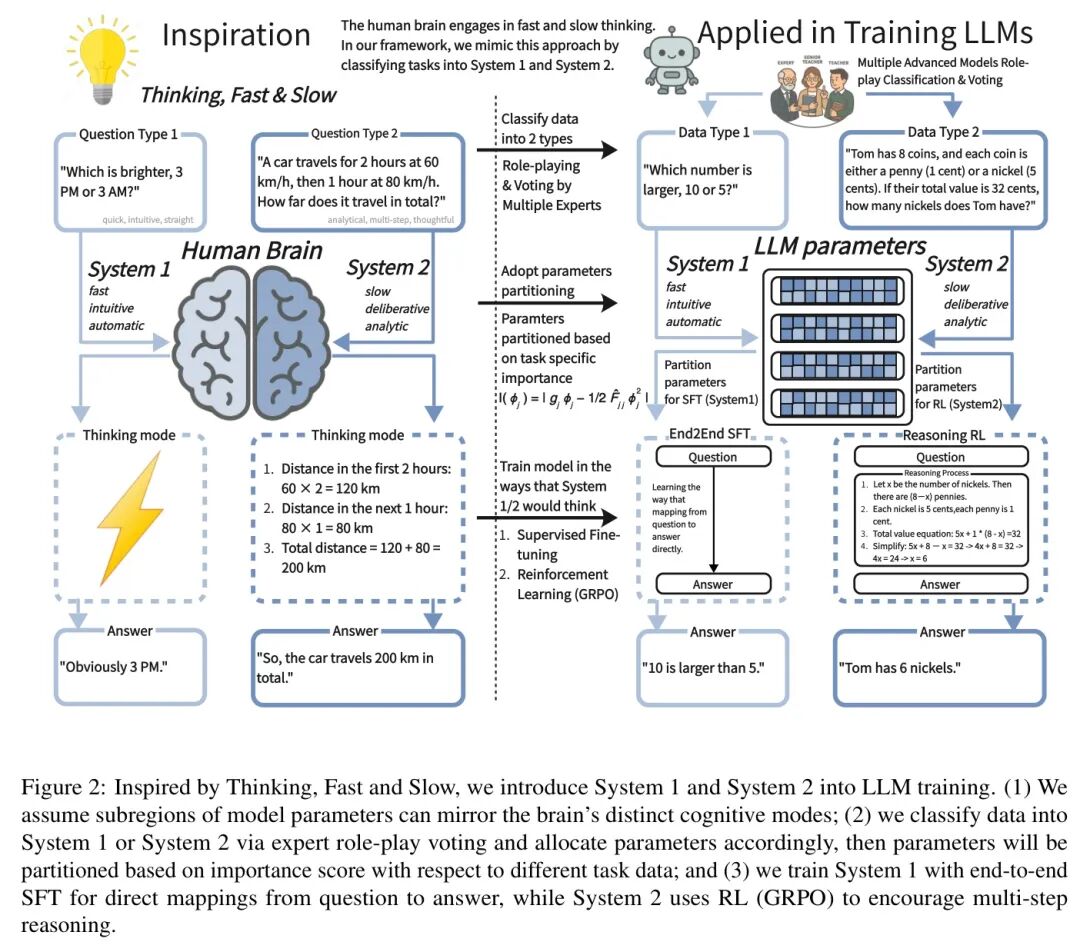
Inspired by “Thinking, Fast and Slow,” which describes two distinct modes of thinking—System 1 (fast, intuitive, often automatic) and System 2 (slower, more deliberate, and analytical)—the author draws an analogy that different “sub-regions” of LLM parameters may also be specialized for tasks requiring quick, intuitive responses versus those requiring multi-step logical reasoning.
Therefore, the author proposes LoRA-PAR, a dual-system LoRA framework that partitions data and parameters according to the needs of System 1 or System 2, using fewer but more focused parameters for each task.
Specifically, the author classifies task data through multi-model role-playing and voting, partitions parameters based on importance scores, and then adopts a two-stage fine-tuning strategy: first using Supervised Fine-Tuning (SFT) to train System 1 tasks to enhance knowledge and intuition, and then using Reinforcement Learning (RL) to optimize System 2 tasks to strengthen deeper logical thinking.
A large number of experiments show that the two-stage fine-tuning strategy of SFT and RL reduces the active parameter usage while matching or surpassing the SOTA PEFT baseline.
unsetunset1 Introductionunsetunset
Large Language Models (LLMs) such as DeepSeekR1 and OpenAI-O1 (Contributors et al., 2024) have shown significant progress in complex reasoning when equipped with CoT prompts. However, elevating their performance to new levels typically relies on massive datasets and full parameter fine-tuning, which requires substantial computational resources and large model sizes. To alleviate this burden, Parameter-Efficient Fine-Tuning (PEFT) methods have emerged as a promising alternative. However, most existing PEFT methods primarily insert uniform adapter modules (e.g., LoRA (Hu et al., 2021)) and do not specifically tailor their parameter configurations to the unique needs of different tasks or reasoning levels. Although there have been recent attempts to design more task- or data-aware PEFT solutions, these efforts have mainly focused on domain adaptation or layer-wise parameter allocation, rather than explicitly targeting higher-level multi-step reasoning capabilities.
At the same time, inspired by “Thinking, Fast and Slow” (Kahneman, 2011), the author integrates the dual-system concept into the parameter-efficient fine-tuning of LLMs. Specifically, as shown in Figure 2, the author draws on the concept that the human brain employs partially different neural processes in System 1 and System 2. Recent studies further demonstrate that large language models can exhibit or benefit from different “fast” and “slow” modes: (Hagendorff et al., 2022) showcased human-like intuitive biases, (Pan et al., 2024) proposed dynamic decision-making mechanisms inspired by Kahneman’s framework, and broader discussions support linking cognitive dual-process theory with AI (Booch et al., 2020).
By analogy, the author hypothesizes that the parameters of LLMs can be divided into specialized “sub-regions” that respond to different response needs. The author achieves this through three steps:
(1) The author uses multi-expert role-playing and voting to classify each training instance as a System 1 or System 2 task, ensuring that fast, direct “fast thinking” questions are separated from more deliberate multi-step tasks;
(2) The author then assigns different subsets of LoRA module parameters to System 1 and System 2 (through importance-based partitioning), similar to activating different cognitive modes;
(3) The author uses end-to-end SFT to train System 1 parameters for direct question-answer mapping and employs Reinforcement Learning (GRPO (Shao et al., 2024)) to optimize System 2 parameters, similar to models like DeepSeek-R1 (DeepSeekAI et al., 2025) that achieve deeper chain-of-thought style reasoning.
In this way, llm-LoRA-PAR_2507 remains within the lightweight range of PEFT while still capturing the dual-process advantages of human cognition—rapid, intuitive responses and organized, step-by-step logic.
unsetunset2 Related Workunsetunset
2.1 Parameter Importance Calculation and Pruning
SparseGPT (Frantar and Alistarh, 2023) effectively prunes large-scale LLM parameters without retraining, significantly reducing model size with minimal performance loss.
Wanda (Sun et al., 2023) employs activation-aware magnitude pruning without retraining, significantly outperforming traditional magnitude-based methods. LLM-Pruner (Ma et al., 2023) identifies and removes structurally redundant components through gradient-based scoring while retaining general multi-task capabilities.
Týr-the-Pruner (Li et al., 2025) applies second-order Taylor approximation for global structured pruning, achieving high sparsity levels with minimal accuracy loss.
2.2 Selective Freezing and Two-Stage Training
LIMA (Zhou et al., 2023) shows that minimal fine-tuning can effectively align pre-trained models, meaning that most parts of the model can remain frozen without losing knowledge. ILA (Shi et al., 2024) developed an analytical technique to selectively freeze non-critical layers, improving fine-tuning efficiency and performance.
Safe layer freezing (Li et al., 2024) suggests freezing identified “safety-critical” layers during further fine-tuning to maintain original alignment and safe behavior.
2.3 LoRA and PEFT Variants
LoRA (Hu et al., 2021) introduced low-rank adaptation, significantly reducing fine-tuning overhead by freezing most parameters while updating small adapter matrices. PiSSA (Meng et al., 2024) uses pre-trained singular vectors to initialize LoRA adapters, accelerating convergence and improving task accuracy.
OLoRA (Büyükakyüz, 2024) enhances LoRA initialization through orthogonal matrices, significantly accelerating fine-tuning convergence. QLoRA (Dettmers et al., 2023) achieves efficient 4-bit quantization fine-tuning for large models, greatly reducing computational demands without sacrificing performance. (Hayou et al., 2024) optimizes LoRA fine-tuning through learning rate scaling, achieving faster convergence and higher accuracy.
unsetunset3 Methodunsetunset
3.1 Overall Workflow
The overall workflow proposed by the author is as follows. First, multiple teacher LLMs classify each query token as either fast, single-step (System 1) or multi-step reasoning (System 2) through voting. Next, the author calculates parameter importance in LoRA and retains only the parameters with the highest cumulative importance scores in each system while identifying a shared subset important to both systems. Finally, the author adopts a two-stage fine-tuning strategy, using SFT for System 1 tasks and RL for System 2.
Shared parameters can be partially activated in both stages, controlled by and. This design effectively addresses the “fast thinking vs. slow thinking” problem within a single LLM by freezing irrelevant parameters and concentrating updates on the most critical sub-regions.
3.2 Multi-Model Role-Playing and Voting Data Classification
Before partitioning model parameters into different thinking modes, it is necessary to identify which category a question belongs to. The author designs a multi-model role-playing method instead of relying on a potentially error-prone or biased single classifier. Here, several advanced LLMs (as “teachers”) each play the role of the “target” model (as “students”) and classify questions accordingly. Since these teacher models typically have a broader pre-training coverage, they can approximate how the student model perceives the type of question—whether it is System 1 or System 2. The role-playing prompts and example questions for System 1 and System 2 are shown in Figure 3.

As shown in the upper panel of Figure 1 (see “Sample Splitter”), each teacher independently provides a classification, and then the author applies a voting procedure to aggregate these judgments. This ensures that disagreements arising from the different architectures or training histories of the teachers are resolved in a robust manner. The resulting token subsets (System 1) and (System 2) are input into subsequent modules, where they guide parameter partitioning and two-stage training.
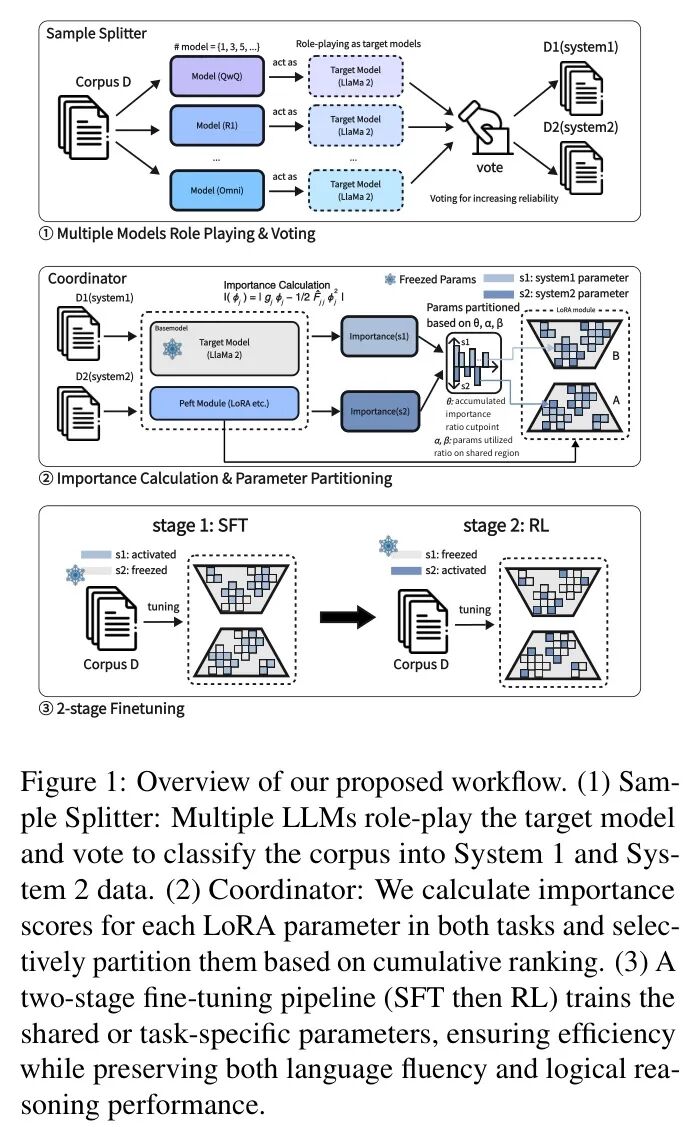
3.3 Parameter Importance Calculation for Sub-Region Partitioning
After classifying the questions, the next step is to determine which LoRA parameters should be “activated” for each category. The author adopts LoRA instead of full parameter fine-tuning
Classification Prompt
Parameter fine-tuning retains the global knowledge of the base model and enables modular activation or freezing strategies for System 1 and System 2 tasks. This partitioning process is analogous to how different regions of the brain are activated in response to different cognitive demands (Kahneman, 2011). In large language models, parameter gradients serve as analogs of neural activations. If a parameter has a large gradient, it indicates that the parameter is crucial for correcting output errors for a specific task. To enhance the model’s ability to answer different types of questions (System 1 or System 2), the author applies a mask in the loss calculation to ignore prompt and context tokens—i.e., the author focuses only on output positions. This ensures that the author’s importance scores emphasize each parameter’s contribution to generating the correct final answer, rather than merely modeling the prompt text.
Calculating Importance Scores
In practice, the author attaches LoRA modules at the Q/K/V/Gate/Up/Down positions within the target model layers. Let denote an individual LoRA parameter. The author measures its importance by performing a second-order Taylor expansion on the masked loss:
Here, is the gradient of the masked loss with respect to, while is the diagonal of the Fisher matrix approximated from the gradients of each sample. Focusing on output tokens aligns parameter importance with the model’s ability to produce correct answers.
Selecting and Freezing Parameters. The author ranks and selects the top proportion (controlled by) as the “active” sub-region for each system. During training, the activated parameters remain learnable, while the remaining parameters are frozen, thereby reducing overhead.
Some parameters may be crucial for both System 1 and System 2; these “overlapping” parameters are shared between the two fine-tuning stages. By partitioning parameters in this way, llm-LoRA-PAR_2507 is closer to a neural analogy, where different “sub-regions” are called upon for tasks requiring fast thinking versus slow thinking.
3.4 Two-Stage Fine-Tuning Strategy Based on Importance Parameter Selection
Based on the importance scores calculated in, the author now formalizes how (i) to determine the number of parameters to activate for each system, (ii) to handle the overlap between System 1 and System 2 parameters, and (iii) to schedule the fine-tuning process in two different stages. As shown in Algorithm 1, llm-LoRA-PAR_2507 relies on three hyperparameters—, and—which control which parameters and how many parameters are updated in System 1 (SFT) and System 2 (RL).

Threshold θ: Selecting the Most Important Parameters. From the parameter importance visualization (see Figure 4), the author observes that System 1 and System 2 each rely on partially disjoint sets of LoRA parameters, with significant overlap. Additionally, each dataset contains many “low-impact” parameters, which have near-zero importance for both systems. The author introduces a cumulative importance threshold. Specifically, for the importance ranking of each system, the author retains only the most important subset of parameters whose cumulative importance scores exceed, discarding tail parameters with negligible importance to reduce overhead and avoid unnecessary updates. For example, setting means the author retains only those parameters whose cumulative importance scores exceed, which are crucial for the tasks of System 1 and System 2.
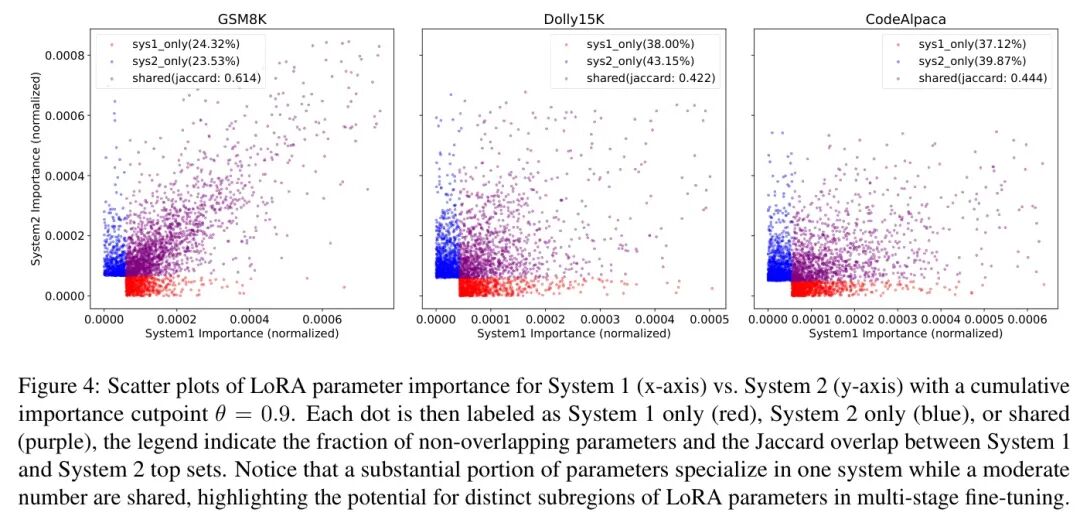
Activation Scores α and β: Handling Overlap. Applying θ separately to System 1 and System 2 yields two top-ranked sets of LoRA parameters that partially overlap. Specifically, some parameters rank highly in both systems; the author refers to these parameters as “shared” parameters (see the purple area in Figure 4). Therefore, the author introduces two activation scores α and β to control how many of these shared parameters are updated during the two training stages:
• First Stage (SFT on System 1 Tasks): The author activates (a) all parameters in the System 1 subset and (b) a portion of the shared parameters. If, the author only partially trains the shared region in this stage.
• Second Stage (RL on System 2 Tasks): The author then activates (a) all parameters in the System 2-specific subset and (b) a proportion of the shared parameters. The remaining parameters remain frozen, allowing the author to flexibly allocate more (or fewer) shared parameters to System 2 based on the value of.
By adjusting and, the author fine-tunes the balance between System 1’s “fast, direct” adaptation and System 2’s “multi-step, deliberate” adaptation, ensuring that parameters useful for both can be partially or fully trained as needed in each stage.
Why two different stages (SFT then RL)?
The author adopts the SFT and RL approach, following practices in the literature related to OpenAI GPT, DeepSeek-R1, and multi-stage language model training. System 1 tasks—rapid, direct question-answering—are naturally suited for end-to-end SFT, which establishes “fast thinking” capabilities without delving into complex reasoning. This “knowledge base” helps kickstart the second stage, where RL encourages stepwise logical reasoning for System 2 tasks (similar to the “slow thinking” process). Essentially, RL refines and expands the capabilities gained through SFT, rewarding correct multi-step strategies rather than just direct answers.
Integrating All Parts
Algorithm 1 formally outlines these steps. In the first stage (SFT), only the System 1 subset and a portion of the shared parameters are trained; in the second stage (RL), only the System 2 subset and a portion of the shared parameters are updated. This design ensures that each system’s dedicated sub-regions are optimized for their respective tasks while shared parameters can flexibly contribute to both fast and slow thinking modes.
unsetunset4 Experimentsunsetunset
4.1 Experimental Setup
The author first partitions each dataset through multi-model role-playing and voting, then calculates LoRA parameter importance and retains the top-ranked parameters for each system. Training is divided into two stages: (1) SFT for System 1 and (2) RL for System 2, with shared parameters managed by and. The author measures accuracy on GSM8K (Cobbe et al., 2021), MMLU (Hendrycks et al., 2021) (trained using Dolly15K (Conover et al., 2023) or OpenPlatypus (Lee et al., 2023)), and HumanEval (Chen et al., 2021) (code tasks), comparing llm-LoRA-PAR_2507 with LoRA (Hu et al., 2021), OLoRA (Büyükakyüz, 2024), PiSSA (Meng et al., 2024), and others, all based on LLaMA2 7B. Key hyperparameters include (proportion of top-ranked parameters),, (proportion of activated overlapping parameters), and 1-2 training epochs for each baseline model.
4.2 Role-Playing and Voting for Data Classification
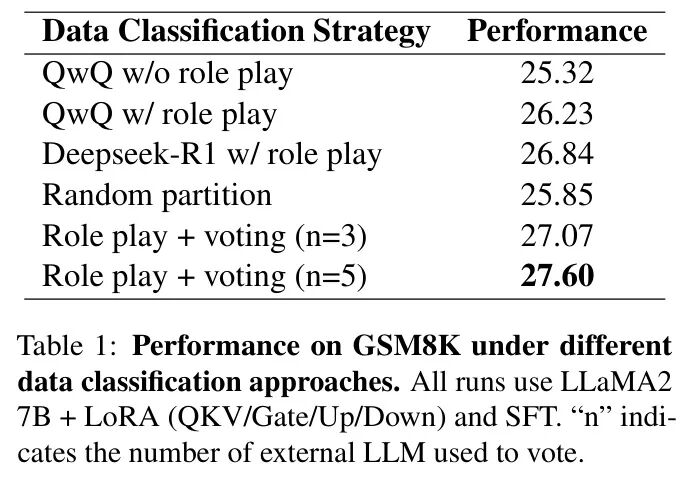
The author first validates the role-playing and voting method introduced in by comparing various data classification strategies on GSM8K. Specifically, the author compares (a) a single model without role-playing, (b) a single model prompted to “play” LLaMA2 7B, (c) random partitioning, and (d) multi-model with role-playing and voting. As shown in Table 1, the multi-model role-playing + voting setup achieves the highest performance. The external LLM mimicking the decision boundaries of the target model (role-playing) reduces misclassifications compared to its default reasoning style, while voting integration mitigates individual biases and produces more robust splits. This result aligns with the author’s intuition that combining multiple “teacher” perspectives can better approximate how LLaMA2 7B distinguishes between System 1 and System 2 questions, ultimately enhancing downstream fine-tuning effectiveness.
4.3 Adaptive Parameter Usage through
The author next investigates how changing the cumulative importance cutoff point (from to) affects the number of activated LoRA parameters and performance under SFT. Essentially, determines which parameters to update and how many parameters to update, as described in§. For each setting, the author compares three LoRA module configurations—QKV, GUD, and QKVGUD—with a random selection baseline that chooses the same proportion of parameters without considering importance.
Algorithm 1 Two-Stage Fine-Tuning
1: Input: LoRA parameters , importance scores , threshold
2: Step 1 (Partition):
3: Rank parameters according to and retain the most important portion as .
4: , .
5: Step 2 (Stage 1: SFT):
6: Activate all parameters in .
7: For each, if it ranks in the top α proportion according to, activate it.
8: Freeze all other parameters.
9: Step 3 (Stage 2: RL):
10: Activate all parameters in .
11: For each , if it ranks in the top proportion according to , activate it.
Freeze all other parameters.
4.4 Utilizing Shared Parameters through
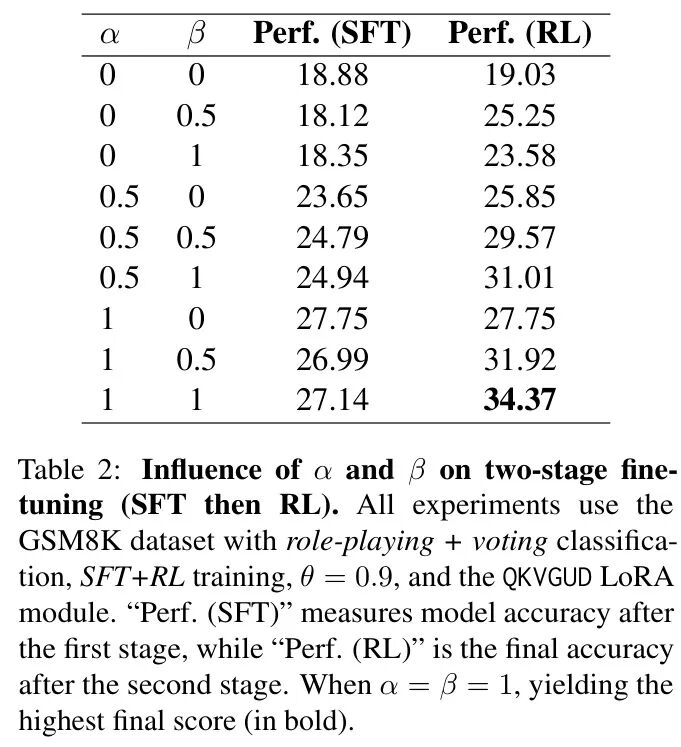
To recap, and (introduced in) control how many shared parameters remain active during the SFT (System 1) and RL (System 2) stages. The author fixes the activation scores for each system and then varies and to measure their impact on training dynamics. Table 2 shows the results using QKVGUD LoRA on GSM8K. The “Performance (SFT)” column reflects accuracy after the first stage, while “Performance (RL)” is the final accuracy after the second stage. When is set, shared parameters remain fully active in both stages—maximizing SFT pre-training weights and yielding the best final score (34.37). Lower or values reduce overlap, limiting early gains in SFT or hindering multi-step reasoning capabilities in the RL stage. In practice, a strong SFT foundation provides a “warm start” for RL (System 2), allowing the model to build deeper logical reasoning on top of its fast thinking skills.
4.5 Final Performance Comparison with Baselines
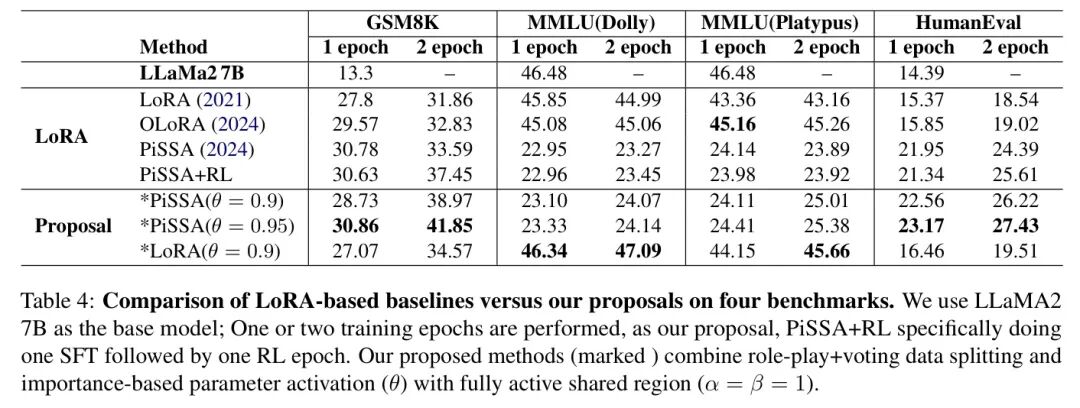
The author summarizes by evaluating llm-LoRA-PAR_2507 against several LoRA-based baselines (LoRA (Hu et al., 2021), OLoRA (Büyükakyüz, 2024), PiSSA (Meng et al., 2024), and others) across four tasks: GSM8K, MMLU (trained using Dolly15K or Platypus), and HumanEval. Each column in Table 4 corresponds to one of these tasks, trained for one or two epochs. For example, GSM8K is trained on its own data, while MMLU(Dolly) and MMLU(Platypus) use Dolly15K and OpenPlatypus, respectively. HumanEval relies on code-focused data (CodeAlpaca (Chaudhary, 2023), CodeFeedback). The base model (LLaMA2 7B) is shown as a reference without fine-tuning. Baselines typically perform two rounds of SFT, except for, which performs one SFT epoch followed by one RL epoch. The author’s proposal (Token being) applies importance-based parameter selection ( or) along with role-playing + voting data partitioning and fully active overlap). Notably, PiSSA ( or) uses only about of the full LoRA parameters, yet outperforms the original PiSSA, indicating that focusing on high-importance sub-regions can yield stronger results. Overall, llm-LoRA-PAR_2507 achieves the best accuracy on GSM8K, surpassing PiSSA by about, while significantly reducing the number of parameters used. On MMLU, the author also observes better performance than standard LoRA and PiSSA, confirming that selectively activating the most relevant parameters is both efficient and effective. Aside from PiSSA, the author’s QKVGUD configuration activates only about of the LoRA parameters for each system (based on or 0.95), yet still outperforms full LoRA and comparably sized random subsets. As shown in the scatter plot in Figure 4, these “top” parameters form a highly specialized sub-region for fast intuitive (System 1) versus multi-step (System 2) tasks. In other words, by concentrating updates on parameters important for each reasoning style, the author achieves a dual-system analogy—different parameter subsets excel at fast intuitive SFT or stepwise RL—while reducing the usage of active parameters.
unsetunset5 Limitationsunsetunset
The author’s experiments confirm that selectively activating LoRA parameters for System 1 and System 2 brings significant benefits in performance and parameter efficiency. By combining role-playing-based data partitioning with importance-driven parameter partitioning, the author effectively approximates the dual-process paradigm in large language models (LLMs). However, there are some limitations: (1) Multi-model labeling. Although using multiple teacher LLMs improves labeling quality, it increases computational overhead and presupposes access to diverse, high-capacity models. (2) Granularity of task partitioning. llm-LoRA-PAR_2507 handles tasks at a coarse-grained level (System 1 vs. System 2). More nuanced distinctions (e.g., intermediate steps or partial multi-hop reasoning) may require finer-grained analysis. (3) Applicability to other architectures. The author demonstrates results on LLaMA2 7B; generalizing to other model families (e.g., encoder-decoder hybrid architectures) may require corresponding adjustments to the LoRA parameters and scoring methods.
unsetunset6 Conclusionunsetunset
The author proposes a dual-system PEFT framework inspired by “Thinking, Fast and Slow,” where the “System 1” and “System 2” sub-regions of LoRA parameters handle fast, intuitive tasks and slower multi-step reasoning, respectively.
The author’s process (i) classifies queries through multi-model role-playing and voting, (ii) determines the importance of each LoRA parameter relative to System 1 or System 2, and (iii) conducts two-stage fine-tuning—SFT for intuitive responses followed by RL for deeper logic. On the GSM8K, MMLU, and HumanEval datasets, the author finds that concentrating updates on top-ranked parameters not only reduces the usage of active parameters (typically down to or less) but also surpasses the baseline PEFT methods that fine-tune larger parameter sets uniformly.
By assigning each sub-region to different “cognitive” modes, the author effectively coordinates fast and slow thinking within a single LLM. The author believes that this “sub-region specialization” opens new directions for cognitive-guided LLM adaptation, making models more efficient while excelling in both intuitive and structured reasoning.
unsetunsetReferencesunsetunset
[1]. LoRA-PAR: A Flexible Dual-System LoRA Partitioning Approach to Efficient LLM Fine-Tuning
Click the card above to follow「AI Vision Engine」public account