Machine Heart Reports
Machine Heart Editorial Team
The application prospects of large models will become increasingly broad.
Typically, the inference code for neural networks is written in Python.However, compared to Python, C/C++ code runs faster and is more rigorous in the writing process, which is why some developers attempt to implement neural networks using C/C++.
Among the many developers who write neural network code in C/C++, Georgi Gerganov stands out. Georgi Gerganov is a seasoned open-source community developer who previously developed whisper.cpp for OpenAI’s Whisper automatic speech recognition model.

Georgi Gerganov
In March of this year, Georgi Gerganov launched the open-source project llama.cpp, which allows developers to run Meta’s LLaMA model without a GPU. Llama.cpp enables developers to run the LLaMA model without a GPU. After the project was released, developers quickly attempted and successfully ran LLaMA on MacBooks and Raspberry Pis.
Visiting Georgi Gerganov’s personal homepage, we find a plethora of open-source projects filled with valuable content.

Now, Georgi Gerganov has announced the establishment of a new company, ggml.ai, aimed at supporting the development of ggml. GGML is a machine learning tensor library built by Georgi Gerganov using C/C++, which helps developers implement large models on consumer-grade hardware and improve model performance. The ggml tensor library has the following features:
-
Written in C;
-
Supports 16-bit floating point numbers;
-
Supports integer quantization (including 4-bit, 5-bit, 8-bit);
-
Automatic differentiation;
-
Built-in optimization algorithms (e.g., ADAM, L-BFGS);
-
Specific optimizations for Apple chips;
-
Uses AVX / AVX2 Intrinsics on x86 architecture;
-
Provides web support through WebAssembly and WASM SIMD;
-
No third-party dependencies;
-
Zero memory allocation at runtime;
-
Supports guided language output.
As a framework written entirely in C, ggml significantly reduces the operating costs of large models. Both llama.cpp and whisper.cpp utilize ggml; let’s take a look at examples using llama.cpp and whisper.cpp.
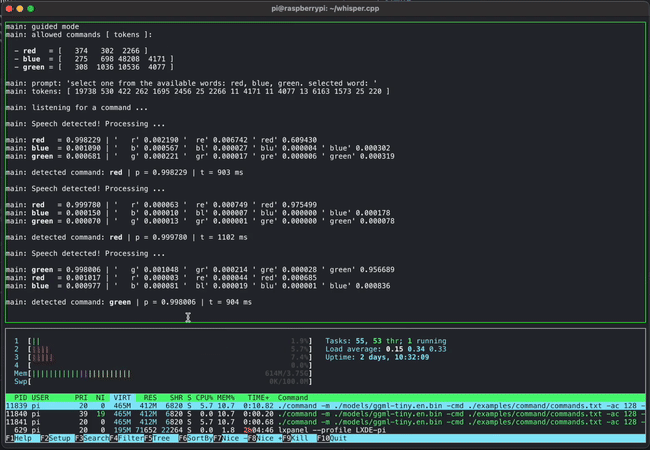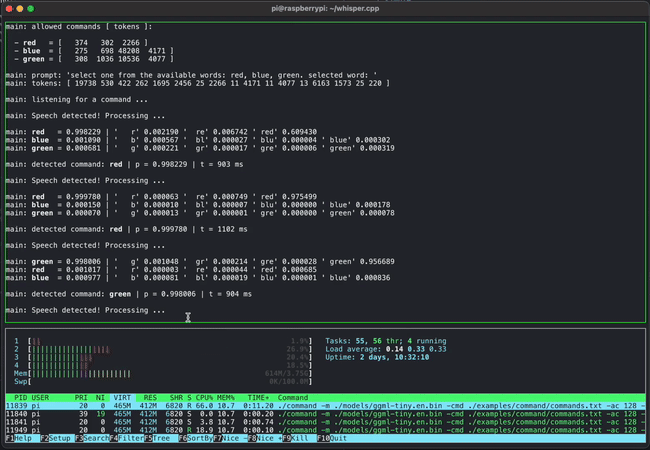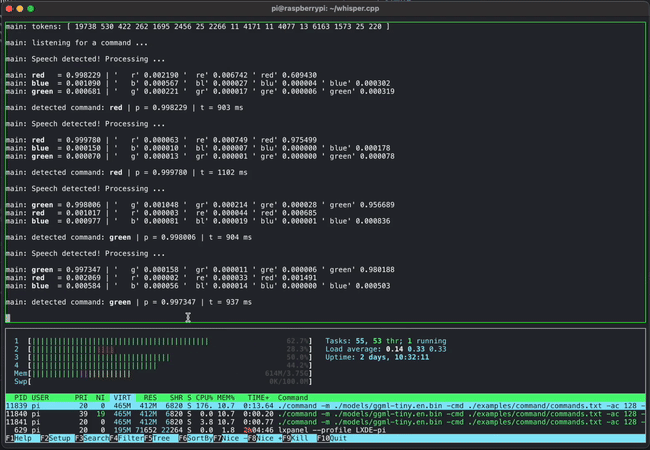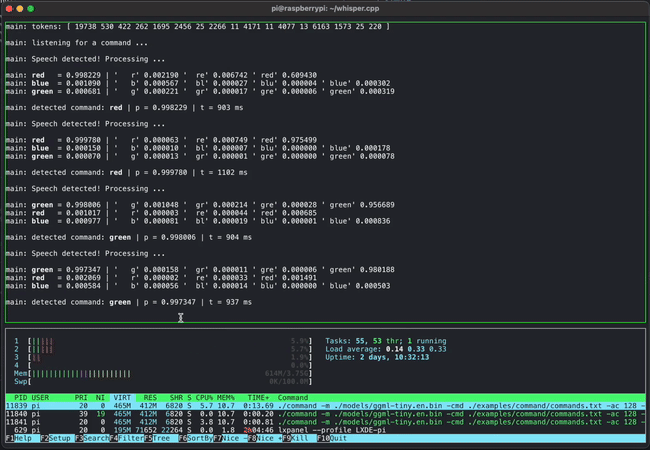
The image below shows an example of using whisper.cpp to detect short voice commands on a Raspberry Pi:
Running 4 instances of LLaMA-13B + Whisper Small simultaneously on a single M1 Pro, as shown in the image below:
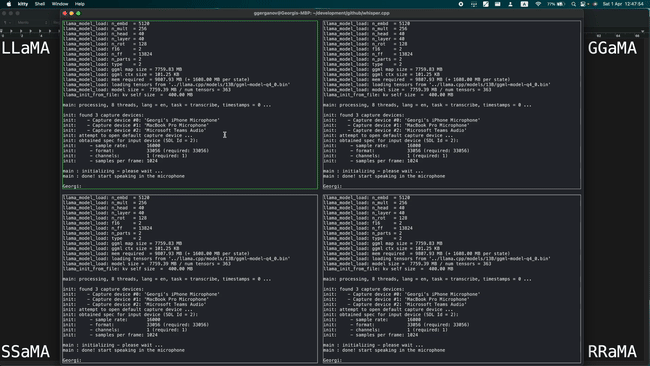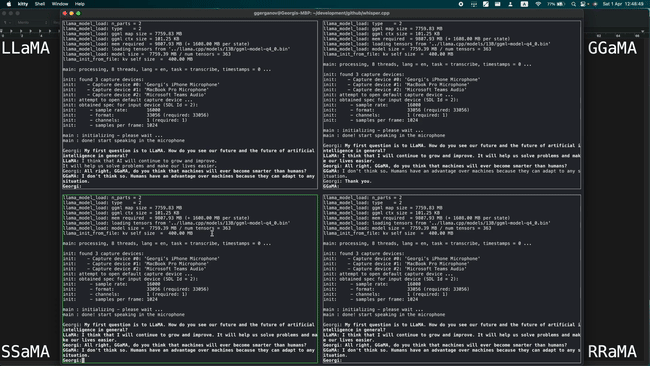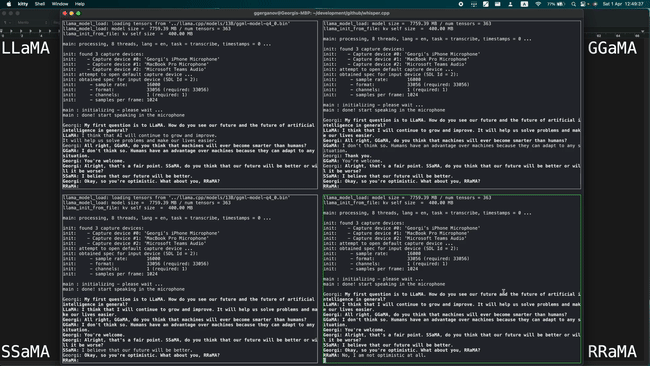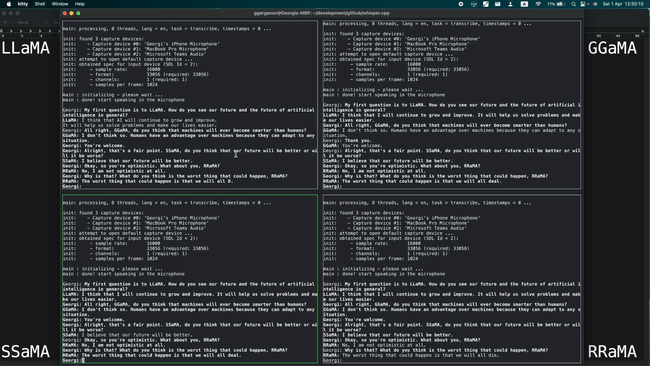
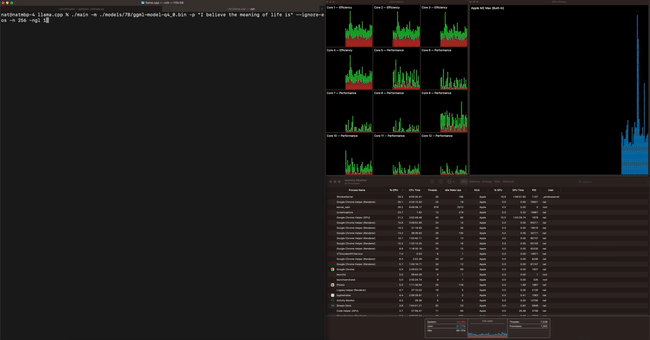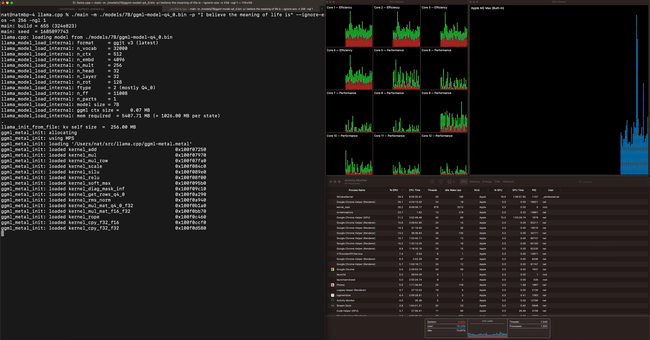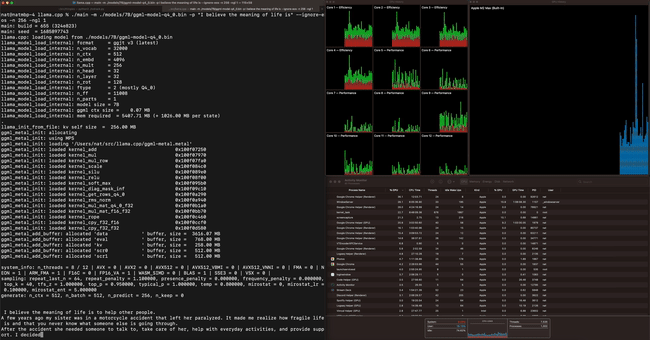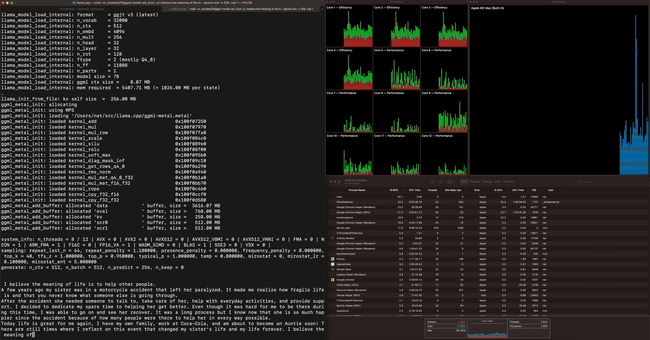
Running LLaMA-7B at a speed of 40 tok/s on M2 Max, as shown in the image below:
Overall, ggml makes it easier to run large language models locally and simplifies operations. After the establishment of his new company, the simple and efficient ggml tensor library will gain more support from developers and investors. We believe that as developers make technical efforts, the application prospects of large models will become increasingly broad.
Reference link: http://ggml.ai/
© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]