1. IntroductionRecently, a group member in our WeChat group encountered a problem: on an ARMv8 architecture CPU, after the Linux system starts, when dynamically enabling 1G huge pages, the maximum contiguous memory allocated is only 32M.This has caused confusion among everyone, and with this issue in mind, today we will discuss huge pages.2. What are Huge Pages?Huge Pages are a memory access optimization technique in operating system memory management.As we know, current operating systems like Linux perform virtual address to physical address translation using the MMU’s page table to record the mapping between virtual and physical addresses. By selectingthe page table format, one can choose the granularity of page sizes (such as 4KB, 16KB, 64KB, which are currently supported by CPU architectures likex86, ARM64, and riscv64). By settingthe number of page table levels, different sizes of pages can be mapped at the corresponding granularity.The common Linux operating system defaults to using 4KB granularity memory pages (previously, the OpenEuler community also discussed that the ARM64 version of the OpenEuler system defaults to using 64KB granularity pages). When using4KBpages as granularity, it can map memory pages of sizes 2MB and 1GB, with the use of 2MB and 1GB memory pages referred to asHuge Pages, or huge pages.2. Why Use Huge PagesThe core idea of Huge Pages isto use large memory blocks (such as 2MB or 1GB) that far exceed the standard memory page size (usually 4KB) to reduce memory access overhead.2.1 Disadvantages of Traditional 4KB Pages
- Page Table Bloat: Each 4KB page requires 1 page table entry; if 1GB of memory is needed, it requires1024^3 = 262144 page table entries, consuming memory space;
- Insufficient TLB Coverage: TLB (Translation Lookaside Buffer) cache is limited (usually 64~512 entries), leading to frequent misses (TLB Miss);
- Table Lookup Overhead: Traversing a 4-level page table requires 4 memory accesses (using ARMv8 as an example);
2.2 Advantages of Huge PagesIn some virtualization and user-space driver scenarios (such as DPDK, SPDK),usinghuge pages can effectively reduce operating system overhead and improve application performance.A. The table below lists the number of page table entries used and TLB coverage range and page table levels when using huge pages (using ARMv8 as an example):
| Page Size | PTE Required for 1GB Memory | TLB Coverage Range | Page Table Levels |
|---|---|---|---|
| 4KB | 262,144 | 4MB (512 entries) | 3 |
| 2MB | 512 | 1GB | 2 |
| 1GB | 1 | 1GB/entry | 1 |
B. Page Table Traversal Overhead Optimization:
| Page Size | Stage 1 Traversal Levels | Total Lookup Count |
|---|---|---|
| 4KB | L0→L3 | 4 |
| 2MB | L0→L2 | 3 |
| 1GB | L0→L1 | 2 |
3. Hardware Support for Huge Pages (using ARMv8 as an example)The ARMv8 MMU supportsStage 1 translation and Stage 2 translation, where Stage 2 translation is mainly used for virtualization. This article will introduce information related to Stage 1 translation, while virtualization will be presented in other articles.3.1 Page Table TranslationARMv8 supports4KB, 16KB, and 64KB three types of conversion granularity, taking 4KB as an example: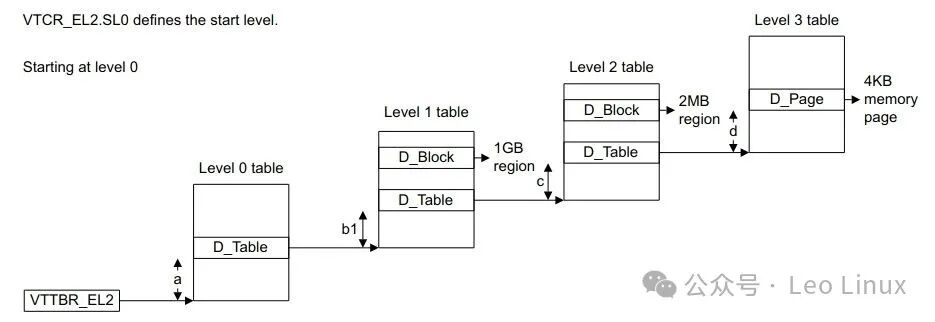
-
D_Table is a Table descriptor
-
D_Block is a Block descriptor
-
D_Page is a Page descriptor
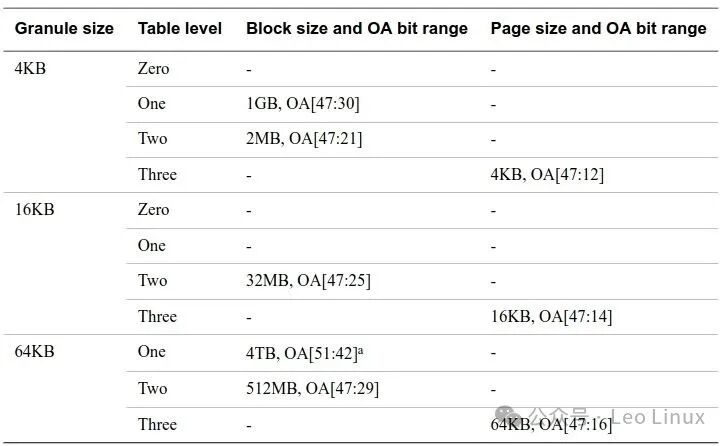
3.2 Conversion Granularity Size and Its Associated Blocks and Pages
The table below lists the conversion granularity size, block/page size, and output address:
3.3 1G Huge Page
When constructing the page table format with 4KB pages, 1GB can be mapped using only a single-level page table:
 4. Linux Kernel Support for Huge PagesThis articleanalyzes the Linux kernel 6.1.26 source code.4.1 Core Data Structures
4. Linux Kernel Support for Huge PagesThis articleanalyzes the Linux kernel 6.1.26 source code.4.1 Core Data Structures<span><span>struct hstate</span></span>
struct hstate {struct mutex resize_lock;int next_nid_to_alloc;int next_nid_to_free;unsigned int order;unsigned int demote_order;unsigned long mask;unsigned long max_huge_pages;unsigned long nr_huge_pages;unsigned long free_huge_pages;unsigned long resv_huge_pages;unsigned long surplus_huge_pages;unsigned long nr_overcommit_huge_pages;struct list_head hugepage_activelist;struct list_head hugepage_freelists[MAX_NUMNODES];unsigned int max_huge_pages_node[MAX_NUMNODES];unsigned int nr_huge_pages_node[MAX_NUMNODES];unsigned int free_huge_pages_node[MAX_NUMNODES];unsigned int surplus_huge_pages_node[MAX_NUMNODES];#ifdef CONFIG_CGROUP_HUGETLB/* cgroup control files */struct cftype cgroup_files_dfl[8];struct cftype cgroup_files_legacy[10];#endifchar name[HSTATE_NAME_LEN];};Several important elements include:
struct hstate {...... unsigned long nr_huge_pages; // Total number of huge pages struct list_head hugepage_freelists[MAX_NUMNODES]; // Free list unsigned int order; // Page order (1GB page: order=18)......};4.2 Huge Page InitializationThe Linux Kernel’s initialization of Huge Pages mainly consists of three parts:
- hugetlb cma reserve initialization;
-
Creation and initialization of the hstate structure;
-
Initialization of Huge Page parameters based on command_line;
4.2.1 hugetlb cma reserve initialization
start_kernel--->setup_arch(&command_line); --->bootmem_init() { /* * must be done after arch_numa_init() which calls numa_init() to * initialize node_online_map that gets used in hugetlb_cma_reserve() * while allocating required CMA size across online nodes. */ #if defined(CONFIG_HUGETLB_PAGE) && defined(CONFIG_CMA) arm64_hugetlb_cma_reserve(); #endif } --->/* * Reserve CMA areas for the largest supported gigantic * huge page when requested. Any other smaller gigantic * huge pages could still be served from those areas. */ #ifdef CONFIG_CMA void __init arm64_hugetlb_cma_reserve(void) { int order; if (pud_sect_supported()) order = PUD_SHIFT - PAGE_SHIFT; else order = CONT_PMD_SHIFT - PAGE_SHIFT; /* * HugeTLB CMA reservation is required for gigantic * huge pages which could not be allocated via the * page allocator. Just warn if there is any change * breaking this assumption. */ WARN_ON(order <= MAX_ORDER); hugetlb_cma_reserve(order); } #endif /* CONFIG_CMA */ --->hugetlb_cma_reserve(order); From the comments in the arm64_hugetlb_cma_reserve() function, we can see that:Reserving CMA areas is to support the largest size of huge pages, whileother smaller sizes ofhuge pagescan still be allocated from these areas.
4.2.1 Creation and Initialization of hstate Structure
start_kernel --->arch_call_rest_init() --->noinline void __ref rest_init(void) { ...... pid = user_mode_thread(kernel_init, NULL, CLONE_FS); ...... } --->kernel_init() --->do_basic_setup() --->do_initcalls() --->subsys_initcall(hugetlb_init); --->hugetlb_add_hstate(HUGETLB_PAGE_ORDER);4.2.1 Initialization of Huge Page Parameters Based on Command Line
<span><span>hugepages</span><span>: indicates the number of huge pages prepared for the system after the Linux Kernel starts;</span></span><span><span>hugepagesz</span><span>: indicates</span></span><span><span>the size of huge pages prepared for the system after the Linux Kernel starts; if the system is 4KB granularity, it can be 2MB or 1GB;</span></span><span><span>default_hugepagesz</span><span>: indicates the default size of huge pages;</span></span><span><span>if the system is 4KB granularity, it can be 2MB or 1GB;</span></span><span><span>hugetlb_cma</span>: indicates the size of the CMA area for allocating gigantic huge pages;</span>
start_kernel --->after_dashes = parse_args("Booting kernel", static_command_line, __start___param, __stop___param - __start___param, -1, -1, NULL, &unknown_bootoption); --->__setup("hugepages=", hugepages_setup);--->hugepages_setup(char *s) --->__setup("hugepagesz=", hugepagesz_setup);--->hugepagesz_setup(char *s) --->__setup("default_hugepagesz=", default_hugepagesz_setup);--->default_hugepagesz_setup(char *s) --->early_param("hugetlb_cma", cmdline_parse_hugetlb_cma);--->cmdline_parse_hugetlb_cma(char *p)4.3 Page Fault Exception Handling Path
Key Function Call Stack:
handle_mm_fault() --->hugetlb_fault() --->hugetlb_no_page() --->alloc_huge_page() # Allocate physical pages from hstate --->set_huge_pte_at() # Write block descriptor --->flush_tlb_page() # Flush TLB4.4 Analysis and Summary
Through the above source code analysis, we find that:
-
In the ARMv8 architecture, the Linux Kernel will allocate a reserved area for huge pages based on the default CMA area size duringbootmem_init() initialization;
-
When the command_line parameter is configured with the hugetlb_cma parameter, the CMA huge page area will be reallocated;
-
When the command_line parameter is configured with huge page-related parameters, the reserved area for huge pages will be set according to the parameters;
5. Problem Reproduction
-
Problem:
On an ARMv8 architecture CPU, after the Linux system starts, when dynamically enabling 1G huge pages, the maximum contiguous memory allocated is only 32M.
-
Problem Background Communication:
1) The command_line did not configure huge page parameters and hugetlb_cma;
2) After the system starts, huge page parameters were configured in user space, with a size of 1G;
-
Analysis:
1) From the above initialization process, we can see that the initialization of huge pages only allocates a reserved area for huge pages based on the default CMA area size during bootmem_init;
2) Since the huge page parameters were not set in the command_line beforehand, setting huge page parameters after the system starts has no effect, and the available huge page area is only 32MB of the CMA area;
-
Solution:
1) Configure appropriate huge page parameters in the command_line: hugepages, hugepagesz;
2) If you want the CMA area to also support huge pages, first configure the size of the CMA area in the Linux kernel to be greater than or equal to the desired huge page size, then configure hugetlb_cma in the command_line;
6. Conclusion
Huge pages overcome the two major bottlenecks of traditional memory management by expanding the granularity of memory management, using a “space for time” strategy:
-
Insufficient TLB Coverage: Reduces Misses and Improves Addressing Efficiency;
-
Page Table Traversal Depth: Shortens the Physical Address Translation Path;
Huge pages significantly improve performance in user-space drivers (DPDK, SPDK), virtualization, RDMA, HPC, and other scenarios, making them a cornerstone technology for high-performance systems.