(Click the public account above to quickly follow)
Source:WsztRush
Link: http://wsztrush.github.io/%E7%BC%96%E7%A8%8B%E6%8A%80%E6%9C%AF/2015/05/13/Linux-Memory.html
Most servers today run on Linux, so as a programmer, it is necessary to have a basic understanding of how the system operates. Regarding memory, you need to know:
-
Address Mapping
-
Memory Management Methods
-
Page Faults
First, let’s look at some basic knowledge. From the perspective of a process, memory is divided into kernel space and user space, as illustrated below:

Transitioning from user space to kernel space is generally achieved through system calls or interrupts. The memory in user space is divided into different regions for different purposes:

Of course, kernel space is not used indiscriminately, so its division is as follows:

Next, let’s take a closer look at how this memory is managed.
Address
The address mapping process within Linux is logical address -> linear address -> physical address. The physical address is the simplest: it is the numerical signal transmitted on the address bus, while the linear and logical addresses represent a conversion rule. The linear address rule is as follows:
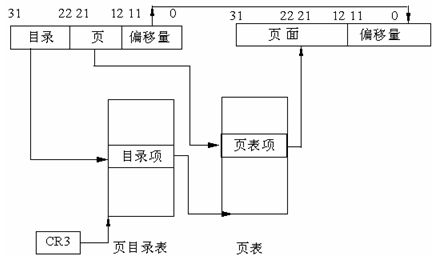
This part is completed by the MMU, and the main registers involved are CR0 and CR3. The machine instructions use logical addresses, and the logical address rule is as follows:
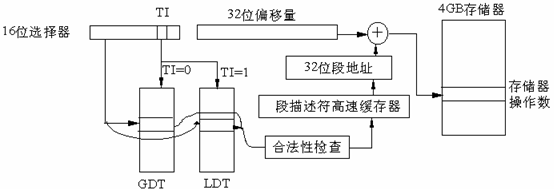
In Linux, the logical address equals the linear address, which means that Intel made things complicated for compatibility, while Linux simplifies it and takes a shortcut.
Memory Management Methods
During system boot, the size and status of the memory are detected. Before establishing complex structures, a simple method is needed to manage this memory, which is bootmem. In simple terms, it is a bitmap, but it also includes some optimization ideas.
No matter how optimized bootmem is, its efficiency is not high. When allocating memory, it still needs to traverse. The buddy system can solve this problem: it internally keeps some free memory fragments of sizes that are powers of 2. If 3 pages need to be allocated, it takes one from the 4-page list, allocates 3, and returns the remaining 1. The memory release process is just the reverse. This can be illustrated as follows:
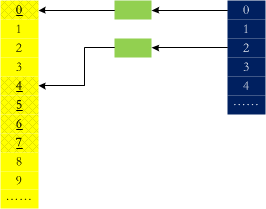
As you can see, 0, 4, 5, 6, and 7 are in use. When 1 and 2 are released, will they merge?
static inline unsigned long
__find_buddy_index(unsigned long page_idx, unsigned int order)
{
return page_idx ^ (1 << order);// Update the highest bit, swap 0 and 1
}
From the above code, we can see that 0 and 1 are buddies, and 2 and 3 are buddies. Although 1 and 2 are adjacent, they are not. Memory fragmentation is a major enemy of system operation, and the buddy system mechanism can prevent fragmentation to some extent. Additionally, we can use cat /proc/buddyinfo to obtain the number of free pages in each order.
The buddy system allocates memory in units of pages (4KB), but most data structures used during system operation are quite small. Allocating 4KB for a small object is clearly not cost-effective. Linux uses slab to solve the allocation of small objects:
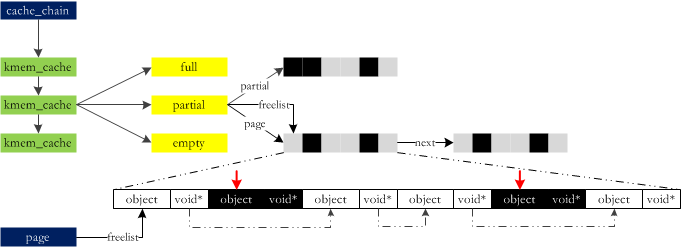
At runtime, slab “wholesales” some memory to the buddy, processes it into blocks, and then “retails” it. With the widespread use of large-scale multiprocessor systems and NUMA systems, slab has finally exposed its shortcomings:
-
Complex queue management
-
High overhead for managing data and queue storage
-
Long-running partial queues can become very long
-
NUMA support is very complex
To address these issues, experts developed slub: it modifies the page structure to reduce the overhead of slab management, and each CPU has a locally active slab (kmem_cache_cpu), etc. For small embedded systems, there is a slab simulation layer called slob, which is more advantageous in such systems.
The small memory issue is resolved, but there is still a large memory issue: when allocating 10 x 4KB of data using the buddy system, it will look for 16 x 4KB in the free list (to obtain contiguous physical memory). However, it is very likely that there is memory in the system, but the buddy system cannot allocate it because it is fragmented into small pieces. Therefore, vmalloc is designed to piece together these fragments to form a large memory, akin to collecting some “scraps” and assembling them into a finished product for “sale”:
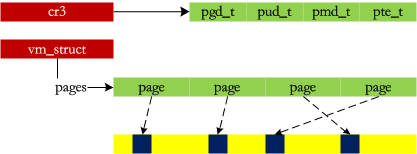
Previously, memory was directly mapped, and this is the first time we feel the existence of page management. Additionally, for high memory, the kmap method provides a linear address for the page.
Processes consist of segments of different lengths: code segments, dynamic library code, global variables, and dynamically generated data such as heaps and stacks. In Linux, a set of virtual address spaces is managed for each process:
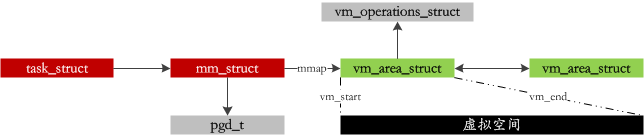
When we write code and call malloc, we do not immediately occupy that much physical memory; we only maintain the virtual address space above. Physical memory is only allocated when truly needed, which is the COPY-ON-WRITE (COW) technique. The process of physical allocation is the most complex part of handling page faults, so let’s take a look!
Page Faults
Before the actual need for data in a certain virtual memory area, the mapping relationship between virtual memory and physical memory is not established. If the part of the virtual address space accessed by the process has not yet been associated with a page frame, the processor automatically triggers a page fault. The information available to the kernel when handling a page fault includes:
-
cr2: The linear address accessed
-
err_code: The reason for the exception, pushed onto the stack by the control unit when the exception occurred
-
regs: The values of the registers at the time of the exception
The handling process is as follows:
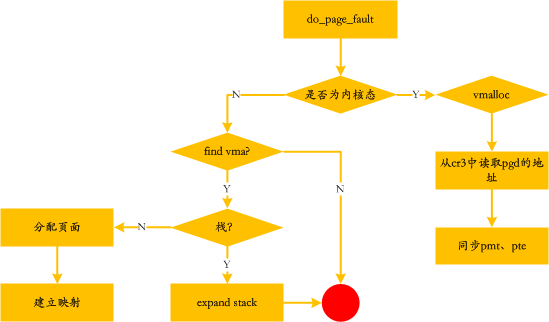
When a page fault occurs, it may have been swapped to disk due to infrequent use. The commands related to swap are as follows:

If the memory is mmap mapped into memory, then reading or writing to the corresponding memory will also generate a page fault.
【Today’s WeChat Public Account Recommendation↓】