1. Web Crawler Architecture
👉 Several important elements of web page writing:
- 【html】 The full name in Chinese is Hypertext Markup Language, similar to XML format.
- Hypertext: Refers to images, links, and even non-text elements like music and programs within the page.
- The structure of HTML includes the “head” part and the “body” part, where the “head” part provides information about the webpage, and the “body” part provides the specific content of the webpage.
Open the Chrome browser, go to a website, and select Developer Tools:
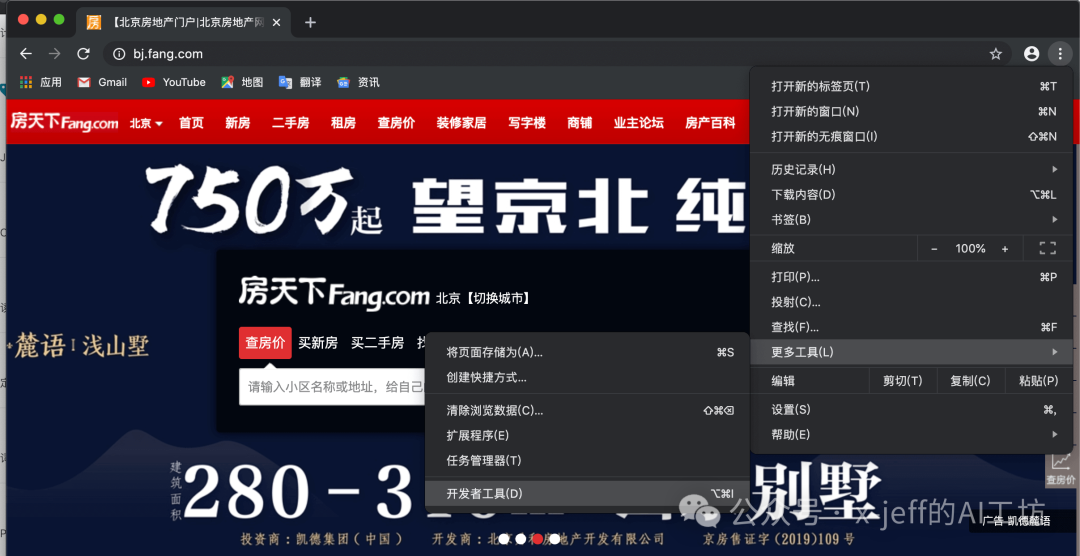
Below are several commonly used windows:
- Elements: HTML language.
- Styles: CSS format.
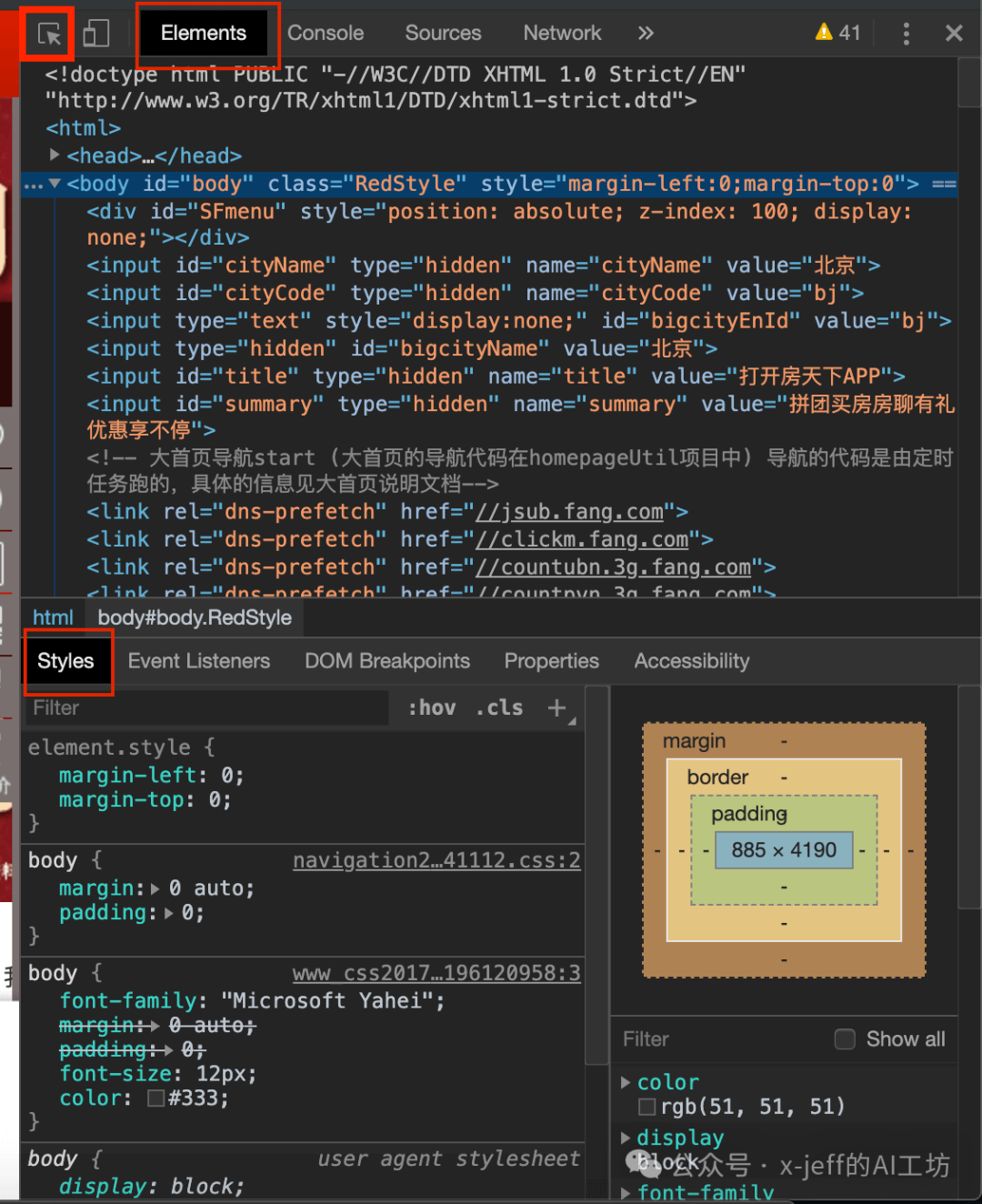
- Click the arrow icon in the upper left corner to view the corresponding HTML code for each content of the webpage and make local modifications, for example:
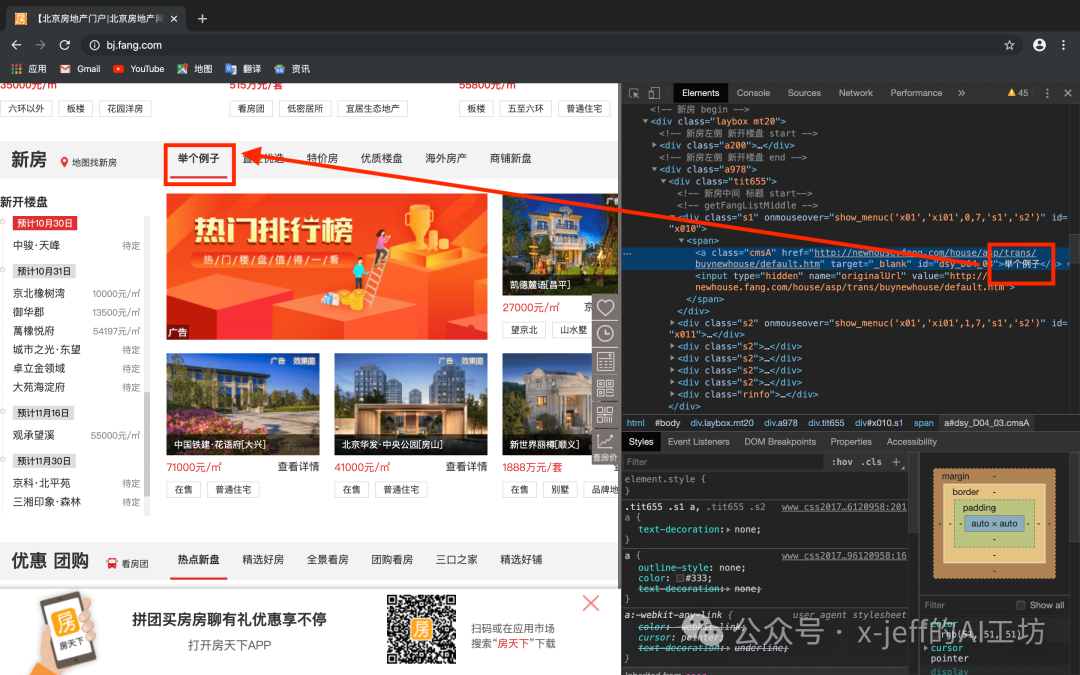
<span>$('a').remove</span> to remove all links from the webpage.- All: Requests made (various types of requests: CSS, JS scripts, images, text, etc.).
- Doc: Text information of the webpage (99% of the text information is here, the remaining 1% may be in “HDR” or “JS”).
- Response: HTML language (webpage response information)
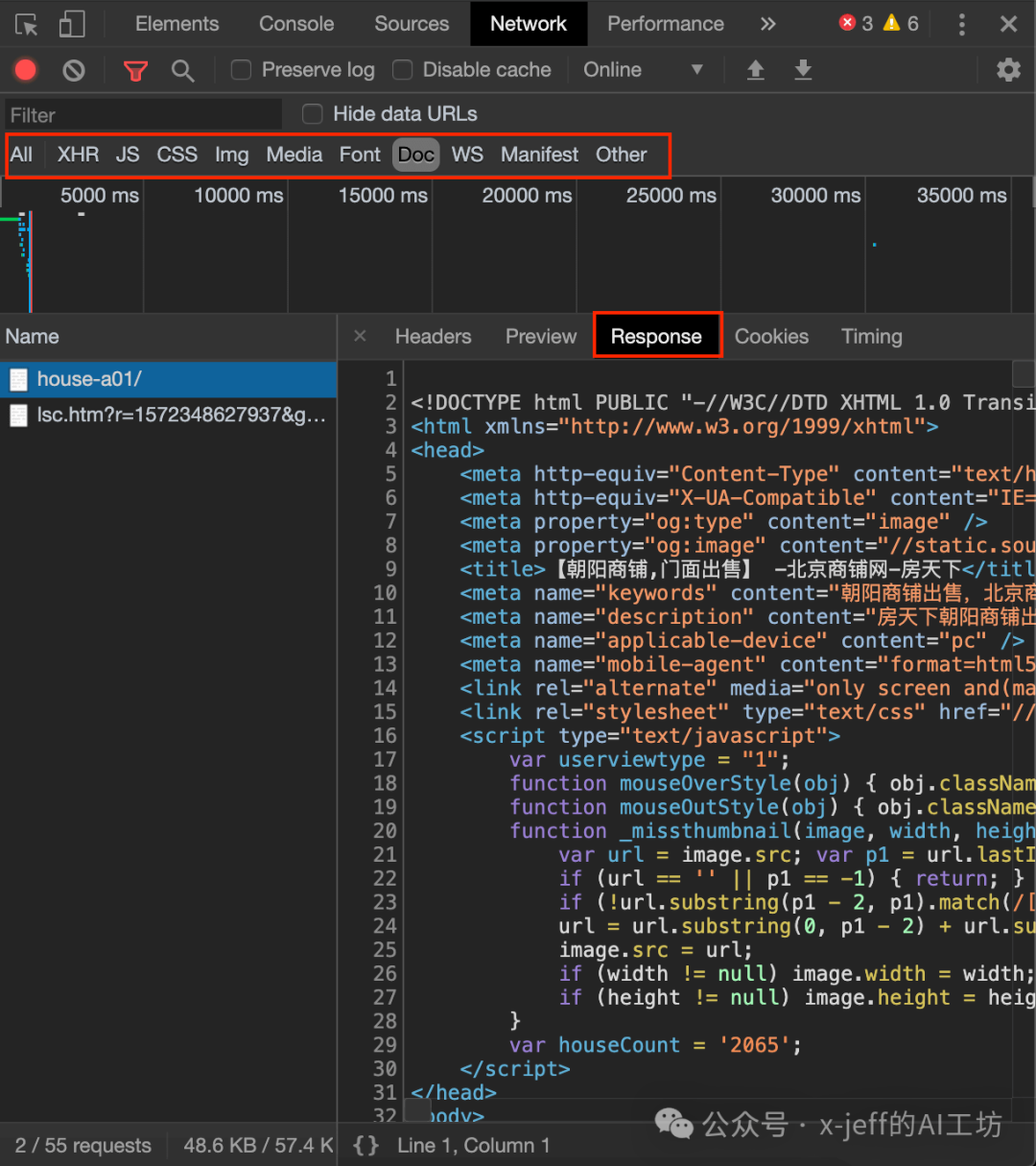
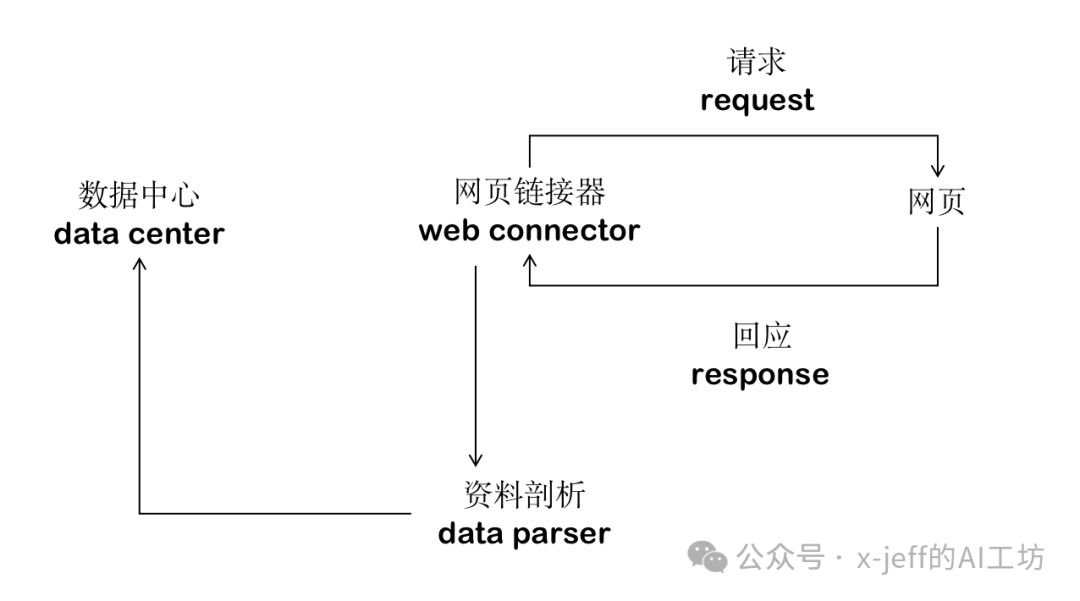
Web Crawler Architecture:
2. Obtaining Text Information from Webpages
Install the following two packages:
<span>pip install requests</span><span>pip install BeautifulSoup4</span>
Or directly install Anaconda (which includes both packages).
Assuming we want to obtain the text information from the Tencent News homepage:
import requests
newsurl='http://news.qq.com/'
res=requests.get(newsurl)
print(res.text)Partial screenshot of the result is shown below:
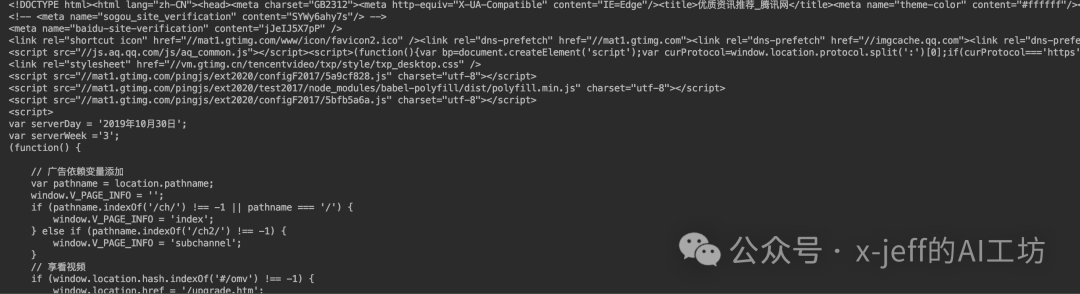
The obtained data is in HTML format, and we hope to extract useful information and remove the cumbersome formatting.
3. Using BeautifulSoup
3.1. DOM Tree
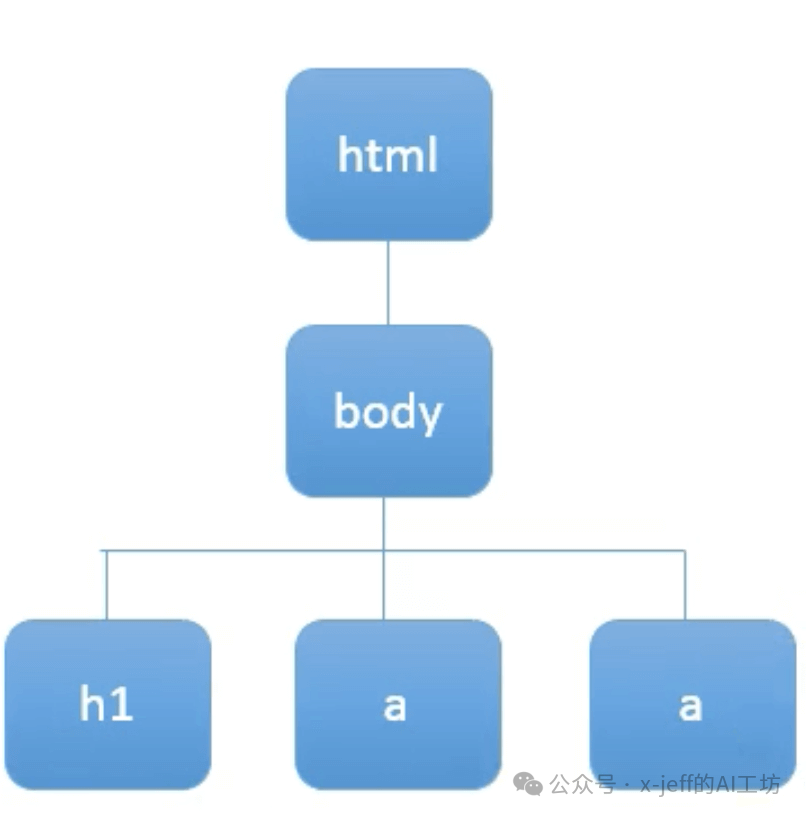
Assuming we have the following HTML formatted data:
<html>
<body>
<h1 id="title">Hello World</h1>
<a href="#" class="link">This is link1</a>
<a href="# link2" class="link">This is link2</a>
</body>
</html>Where h1 is the main title, and the two a tags correspond to two links, with href being the address of the link.
BeautifulSoup can parse HTML data into a DOM (Document Object Model) Tree:
3.2. Using BeautifulSoup to Parse HTML Data
Using BeautifulSoup to parse the above HTML data:
from bs4 import BeautifulSoup
html_sample='\
<html>\
<body>\
<h1 id="title">Hello World</h1>\
<a href="#" class="link">This is link1</a>\
<a href="# link2" class="link">This is link2</a>\
</body>\
</html>'
soup=BeautifulSoup(html_sample,'html.parser')
print(soup.text)
<span>\</span>can be used to break long strings into new lines.
In the function <span>BeautifulSoup()</span>, the first parameter is the HTML data, and the second parameter is the type of parser, which can be html.parser, html5lib.parser, lxml.parser, etc. Different parsers have different advantages and disadvantages. Here we use html.parser.
The output of the above code is:

It returns a string format of data, and we can see that we have crawled all the text information from the data.
3.3. Finding All HTML Elements with Specific Tags
👉 So what if we want to crawl a specific tag?
header=soup.select('h1')
print(header)
alink=soup.select('a')
print(alink)The output is:

The returned data is in list structure.
👉 Further crawl the elements under a specific tag:
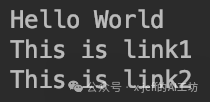
print(soup.select('h1')[0].text)
for xx in alink:
print(xx.text)The output is:
3.4. Obtaining Elements with Specific CSS Attributes
👉 Use select to find all elements with id equal to title (⚠️ id must be prefixed with #):
alink=soup.select('#title')The output is a list structure: <span>[<h1 id="title">Hello World</h1>]</span>
👉 Use select to find all elements with class equal to link (⚠️ class must be prefixed with .):
for link in soup.select('.link'):
print(link)The output is:
<a class="link" href="#">This is link1</a>
<a class="link" href="# link2">This is link2</a>id is unique, but class can appear multiple times.
3.5. Obtaining Attribute Values within Tags
👉 Use select to find all a tag’s href and class:
alinks=soup.select('a')
for link in alinks:
print(link['href'])
print(link['class'])The output is:
#
['link']
# link2
['link']To obtain a specific attribute value under a specific tag:
alinks[0]['href'] # Output: ‘#’. In string format.
alinks[0]['class'] # Output: ['link']. In list structure.4. Basic Ideas of Web Crawlers
For example, if we want to crawl the news titles from the Tencent News website (https://news.qq.com/), we use the Chrome browser’s developer tools to determine the location of the news titles:
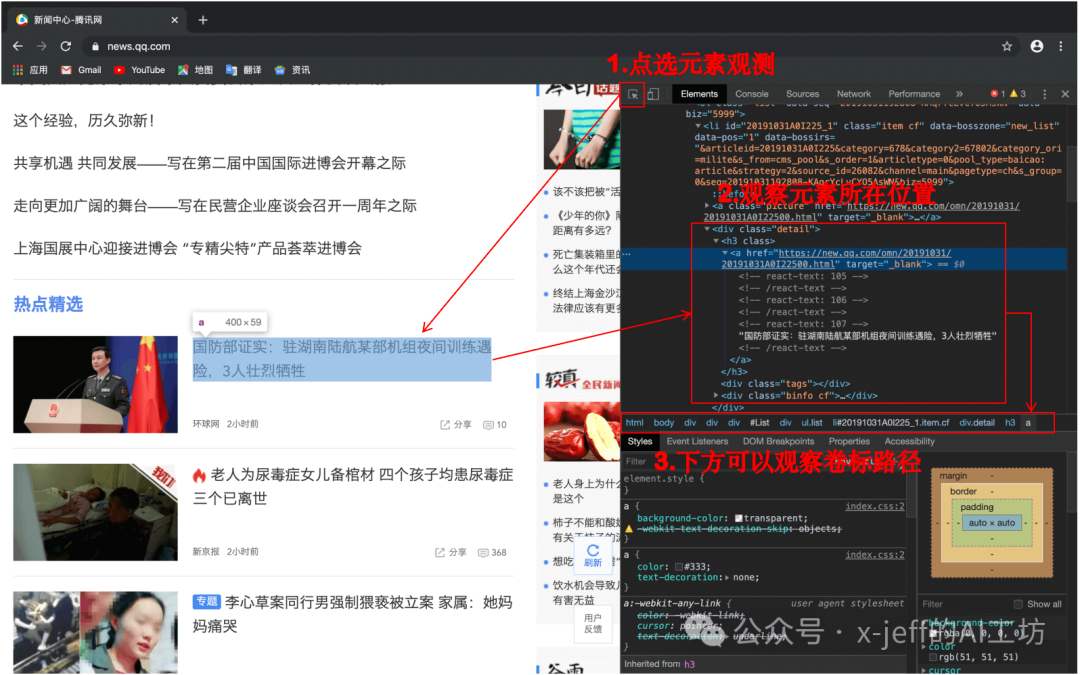
Then, using the BeautifulSoup knowledge discussed in section 3, we can crawl the text content.
5. Practical Application – Collecting Housing Data in Beijing
Assuming we need to collect the housing price information of new houses in Beijing. First, open the Beijing Fang.com website, and go to the “New House” interface. Enter developer mode to check the storage location of the text information:
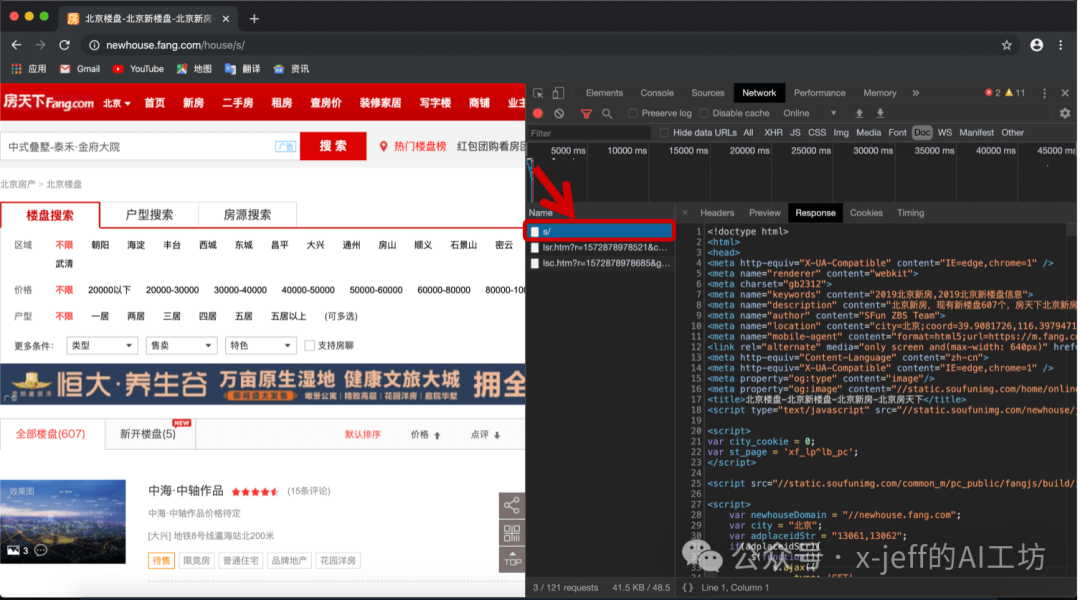
It can be seen that only the first link among the three contains the webpage’s text information:https://newhouse.fang.com/house/s/.
Crawl the housing price information in Beijing: <span>res=requests.get('https://newhouse.fang.com/house/s/')</span>.
In section 2, we discussed extracting text information from websites using
<span>requests.get()</span>, but it is important to note that the content being crawled may differ from the real-time content of the webpage, as the content of the webpage may be continuously refreshed, while the crawled content only reflects the state of the webpage at the time of the crawling operation.
⚠️ At this point, the crawled content may have Chinese characters appearing garbled, requiring a specific encoding method. The encoding method of a webpage can generally be found in the following two places:
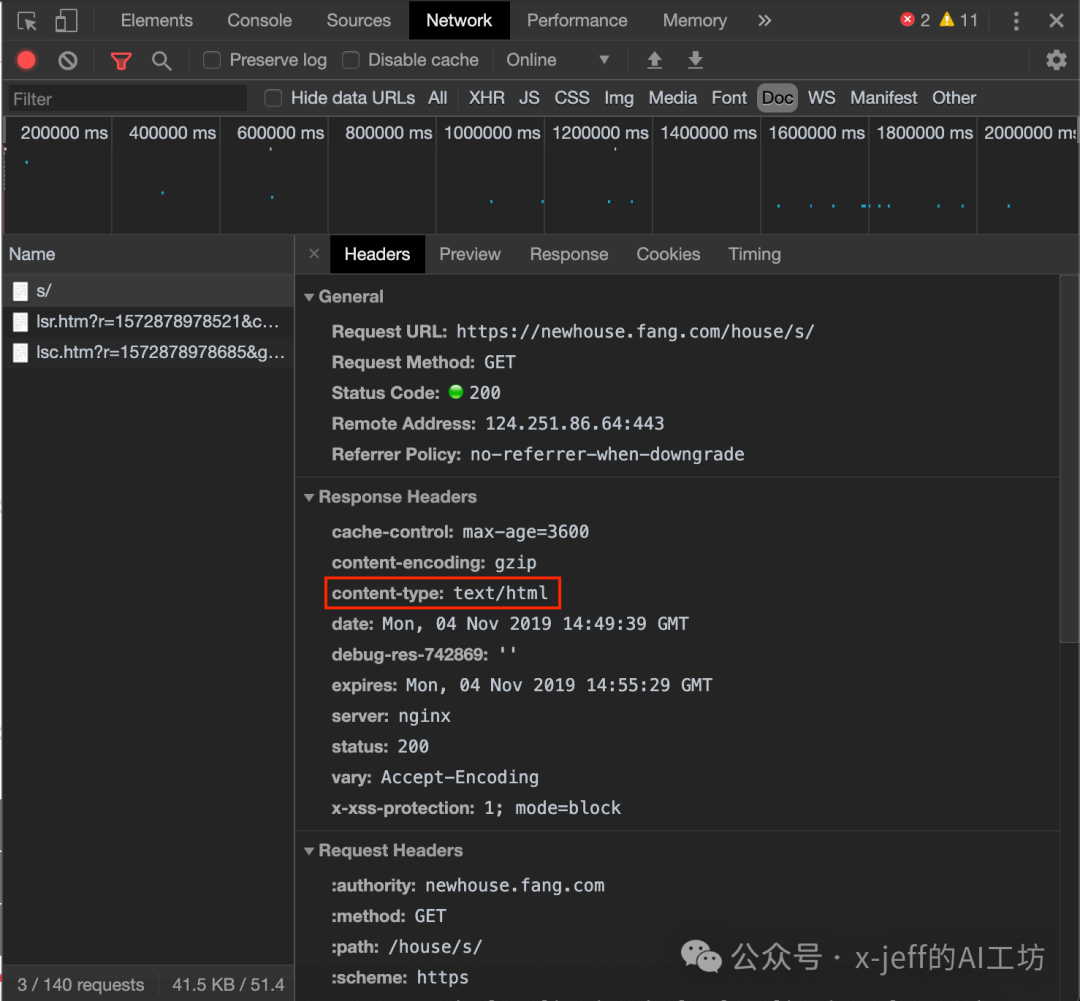
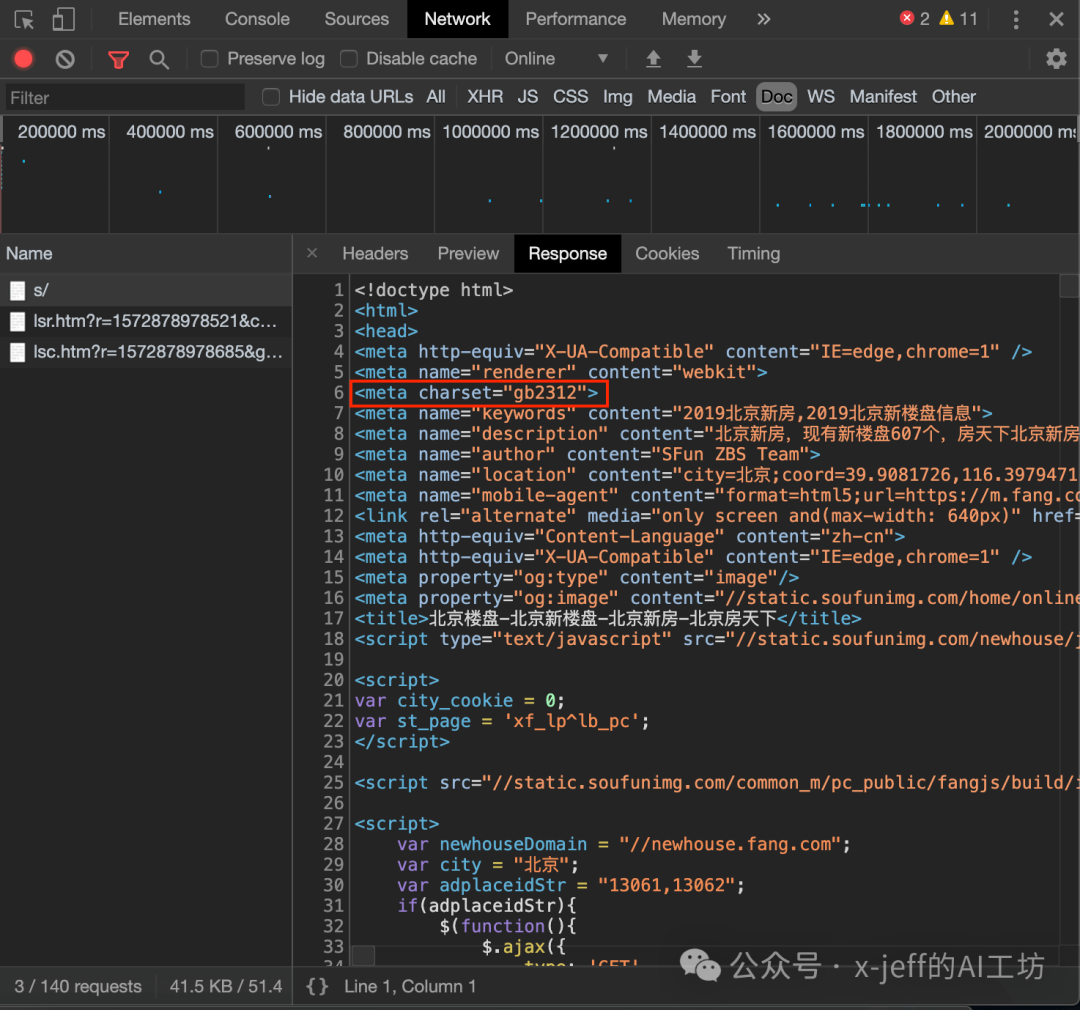
It can be seen that the encoding method of the webpage in this example is “gb2312”, which can be resolved by <span>res.encoding='gb2312'</span> to solve the Chinese garbled problem.
Then, by clicking the arrow icon in the upper left corner of developer mode to locate the content specifically (for details, please refer to section 4). In this example, the names of the houses are all under the <span>class="nlcd_name"</span> tag:
soup=BeautifulSoup(res.text,'html.parser')
for house_name in soup.select('.nlcd_name'):
print(house_name.text.strip())Thus, we have obtained all the house names on that page:

If we want to output not only the names of the houses but also the network links to the house information.
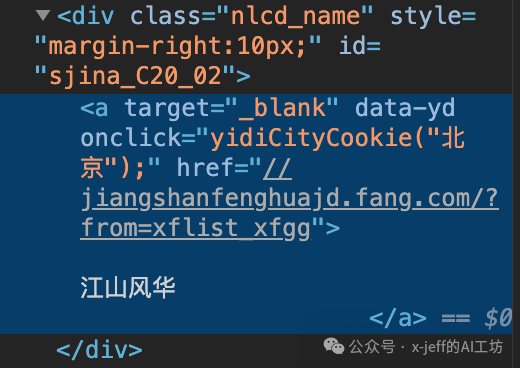
As shown in the figure above, the link href of the house is in the a tag, which is a sub-tag of the div tag, and this link needs to be prefixed with <span>https:</span>:
for house_url in soup.select('.nlcd_name a'):
print('https:' + house_url['href'])The output is shown below:
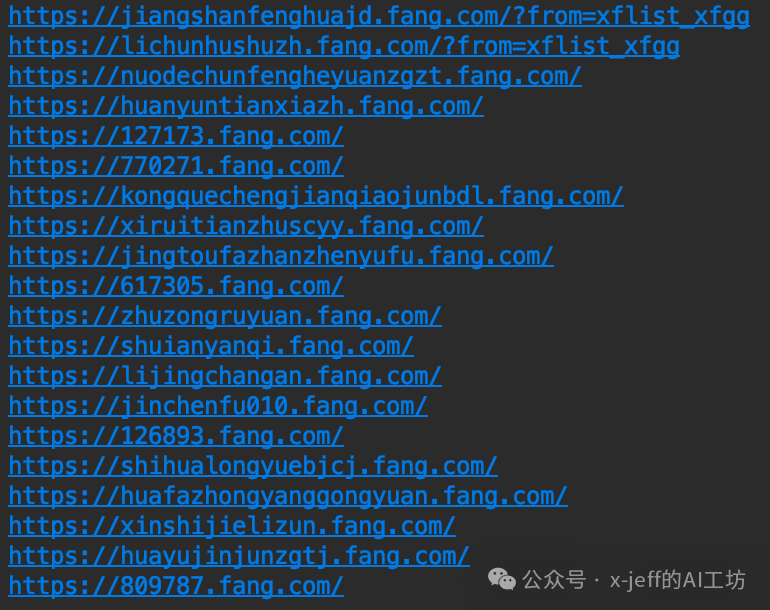
❗️<span>.nlcd_name a</span> indicates that the tag a is a sub-tag of the tag with class=”nlcd_name”.
❗️ However, there is a special case: if class=”info rel floatr”. If you directly use <span>soup.select('.info rel floatr')</span>, it will be considered that .info, rel, and floatr are in a nested relationship, resulting in no matches and only outputting empty values. The correct way to write this is:<span>soup.select('.info.rel.floatr')</span>
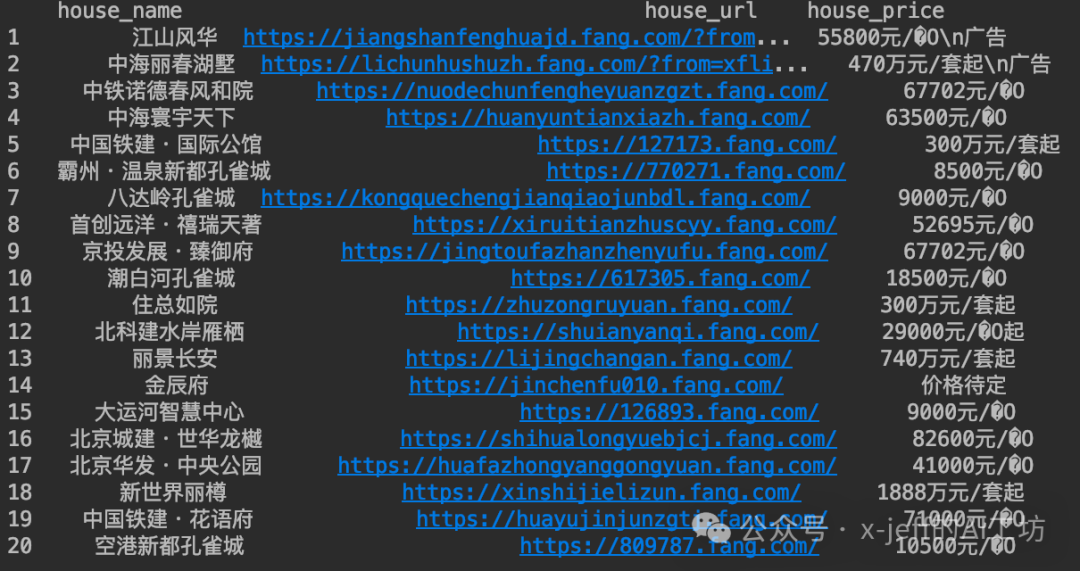
Similarly, we can also output the price, layout, address, and other information of the houses, which can all be encapsulated in a function for easy calling. The final results can be stored in a DataFrame and further exported to Excel or other formats:
6. Code Repository
-
https://github.com/x-jeff/Python_Code_Demo/tree/master/Demo8
🔥 Click “Read the original text” to jump to the personal blog for a better reading experience~