
Introduction
The Tensor Processing Unit (TPU) is an artificial intelligence accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning, particularly using Google’s own TensorFlow software. Google began using TPU internally in 2015 and made them available as part of its cloud infrastructure in 2018, selling smaller versions of the chip to third parties.

The TPU was announced at Google I/O in May 2016, when the company stated that TPU had been in use in its data centers for over a year. The chip is designed specifically for Google’s TensorFlow framework for machine learning applications such as neural networks.
Compared to a graphics processing unit, it is designed for a large number of low-precision calculations (e.g., as low as 8-bit precision) with more input/output operations per joule, without the need for hardware for rasterization/texture mapping. According to Norman Jouppi, the TPU ASIC is mounted in a cooling component that can be installed in hard drive slots within data center racks. Different types of processors are suitable for different types of machine learning models, with TPU being very suitable for CNNs, while GPUs excel in some fully connected neural networks, and CPUs excel in RNNs.
After several years of development, TPU has released four versions, and here is its development history:
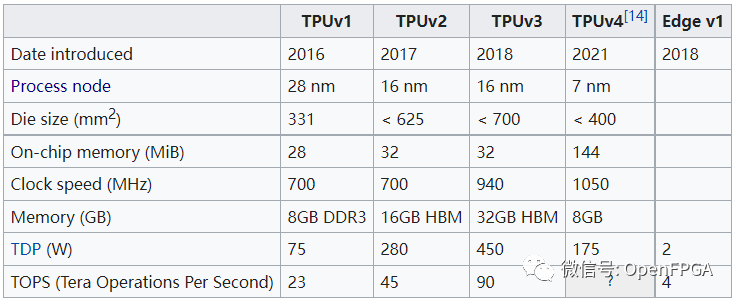
For detailed introduction: <What is TPU?>
Next, we will introduce some TPU projects.
tinyTPU
❝
https://github.com/jofrfu/tinyTPU
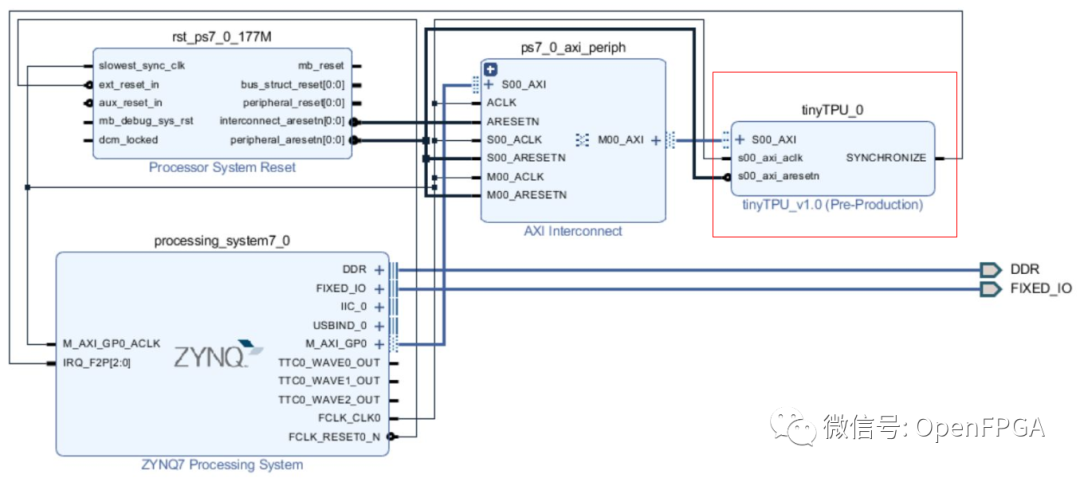
The purpose of this project is to create a machine learning coprocessor with a similar architecture to Google’s TPU. The resources of this implementation are customizable and can be used in different sizes to fit each type of FPGA. This allows for the deployment of this coprocessor in embedded systems and IoT devices, but can also be scaled for use in data centers and high-performance machines. The AXI interface allows for use in various combinations. An evaluation was performed on the Xilinx Zynq 7020 SoC. Below is a link to a DEMO using Vivado:
❝
https://github.com/jofrfu/tinyTPU/blob/master/getting_started.pdf
At the same time, this project is also a verification project for a paper, the paper address:
❝
https://reposit.haw-hamburg.de/bitstream/20.500.12738/8527/1/thesis.pdf
Performance
The sample model trained with the MNIST dataset was evaluated on MXUs of different sizes, with a frequency of 177.77 MHz and a theoretical performance of up to 72.18 GOPS. The actual timing measurements were then compared with traditional processors:
TPU at 177.77 MHz:
| Matrix Width N | 6 | 8 | 10 | 12 | 14 |
|---|---|---|---|---|---|
| Instruction Count | 431 | 326 | 261 | 216 | 186 |
| Duration in us (N input vectors) | 383 | 289 | 234 | 194 | 165 |
| Duration per input vector in us | 63 | 36 | 23 | 16 | 11 |
Below are the comparison results with other processors:
| Processor | Intel Core i5-5287U at 2.9 GHz | BCM2837 4x ARM Cortex-A53 at 1.2 GHz |
|---|---|---|
| Duration per input vector in us | 62 | 763 |
Free-TPU
❝
https://github.com/embedeep/Free-TPU

The compiled BOOTbin can be used directly for verification, as the TPU is not associated with the pins.
❝
https://github.com/embedeep/Free-TPU-OS
Description
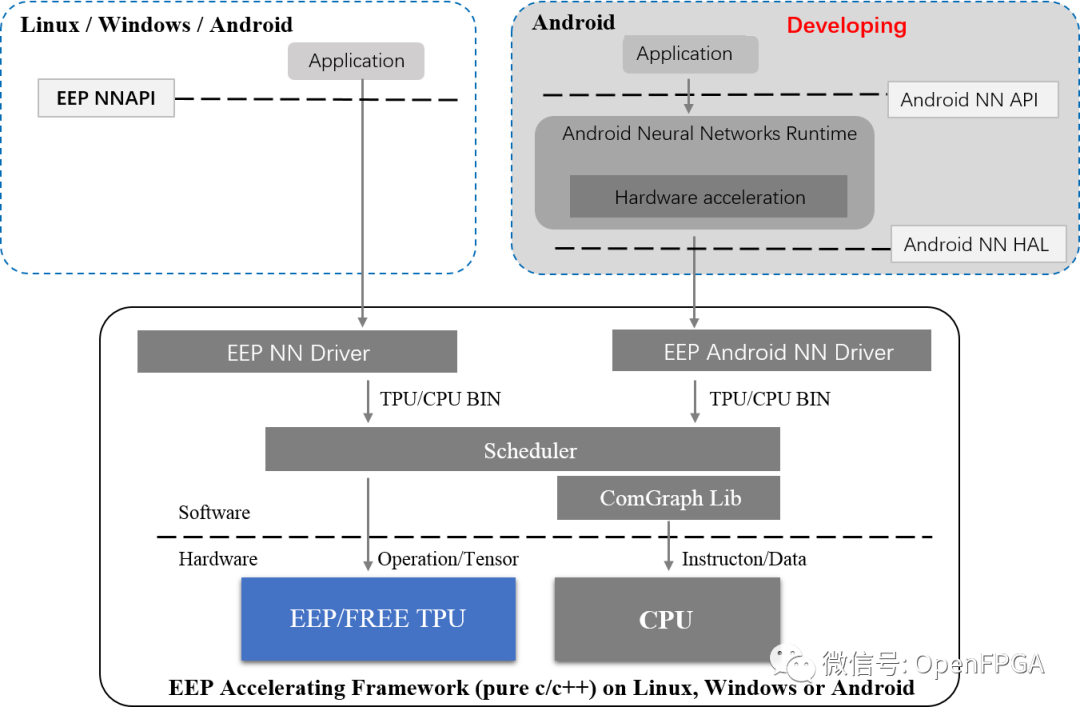
Free TPU is a free version of the commercial TPU design for deep learning EDGE inference that can be deployed on any FPGA device, including Xilinx Zynq-7020 or Kintex7-160T (both are good production choices). In fact, not only the TPU logic design, Free TPU also includes an EEP acceleration framework supporting all caffe layers that can run on any CPU (like ARM A9 or INTEL/AMD on Zynq-7020). TPU and CPU collaborate under the deep learning inference framework (in any alternating order).
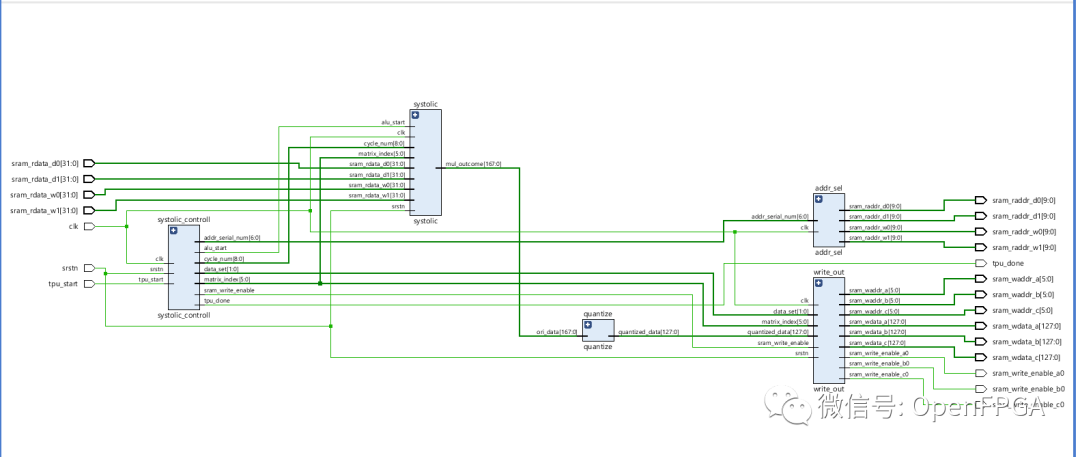
System Architecture
Comparison
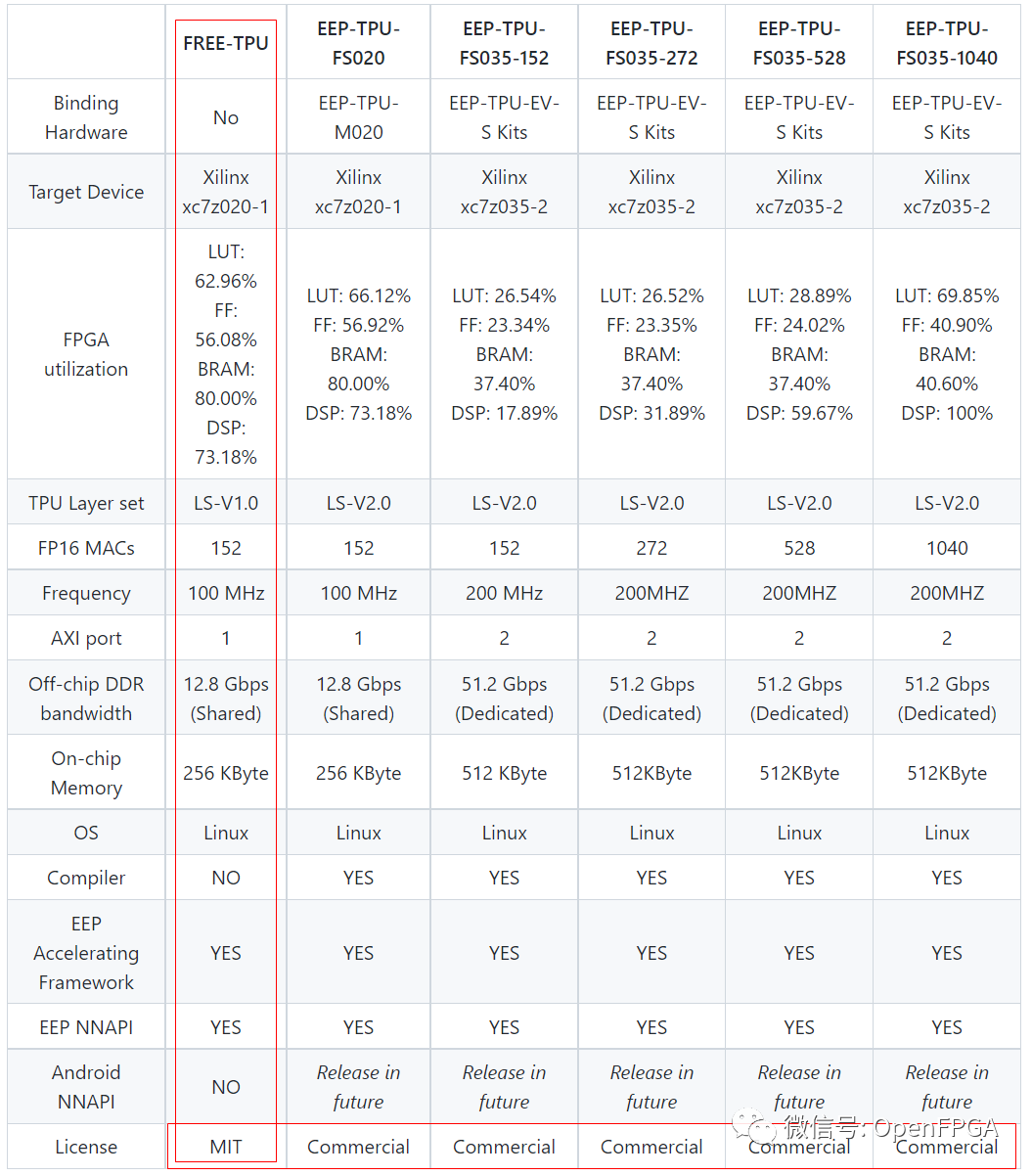
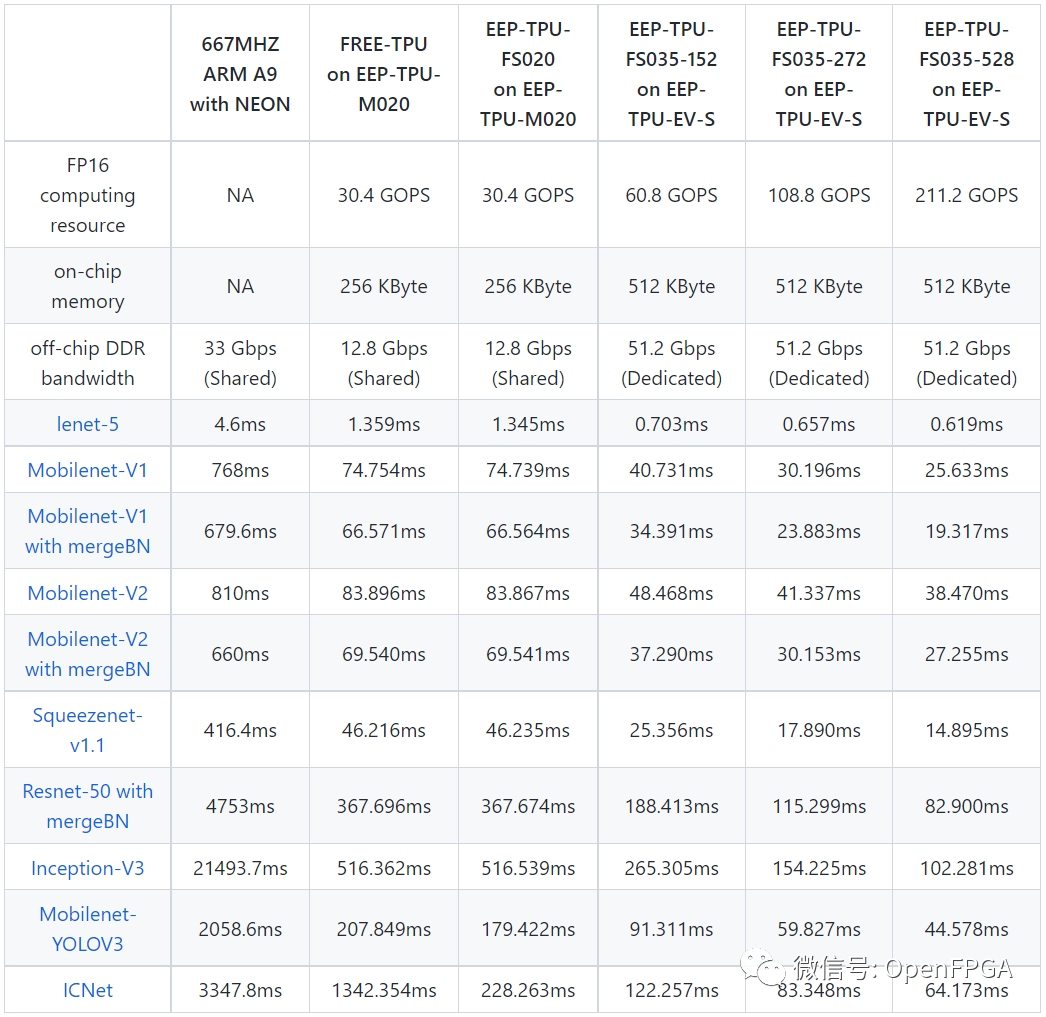
From the user’s perspective, Free-TPU and EEP-TPU have the same functions, but the inference times differ.
This is an extremely complete project, with very detailed steps on how to run and call, which will not be elaborated here. For more details, please visit:
❝
https://www.embedeep.com
SimpleTPU
❝
https://github.com/cea-wind/SimpleTPU
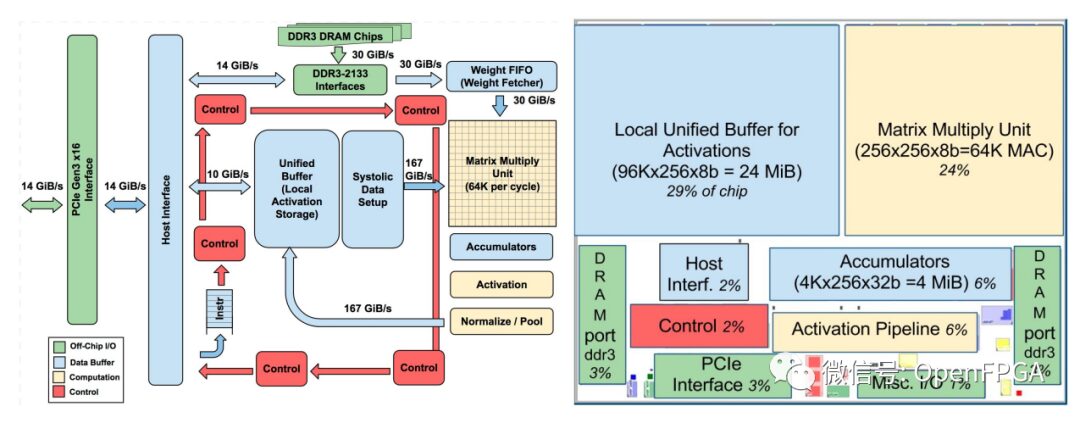
The TPU is designed to accelerate matrix multiplication, especially for multilayer perceptrons and convolutional neural networks.
This implementation mainly follows Google TPU Version 1, which is introduced in
❝
https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
Major features of Simple TPU include
-
Int8 multiplication and Int32 accumulator -
VLIW-based parallel instructions -
Data parallel based on vector architecture
Below are some operations that Simple TPU can support.
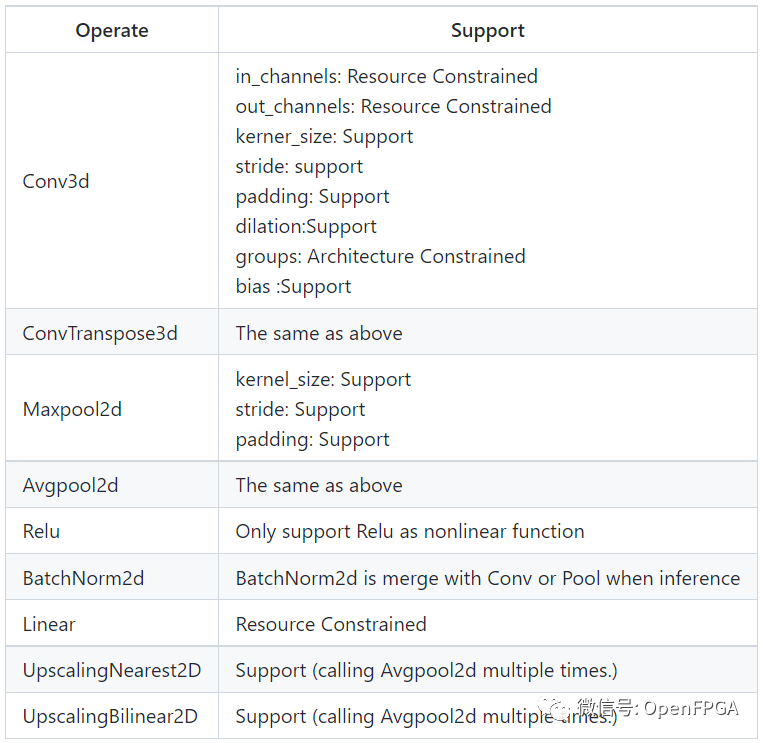
Resource Usage
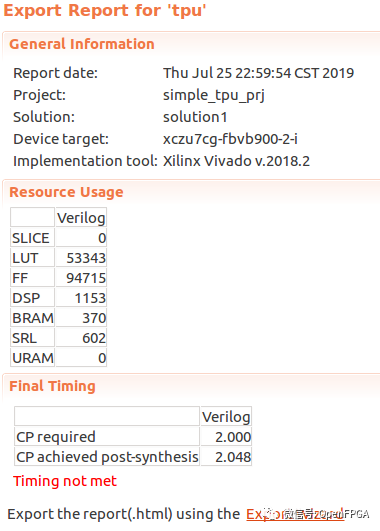
Although this project is quite complete and has subsequent DEMO demonstrations, it is made using HLS. For detailed information, please refer to the link below
❝
https://www.cnblogs.com/sea-wind/p/10993958.html
tiny-tpu
❝
https://github.com/cameronshinn/tiny-tpu
Google’s TPU architecture:
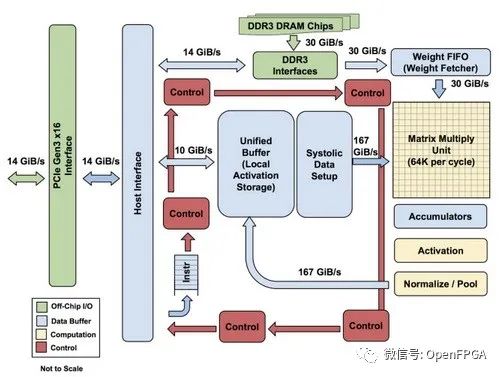
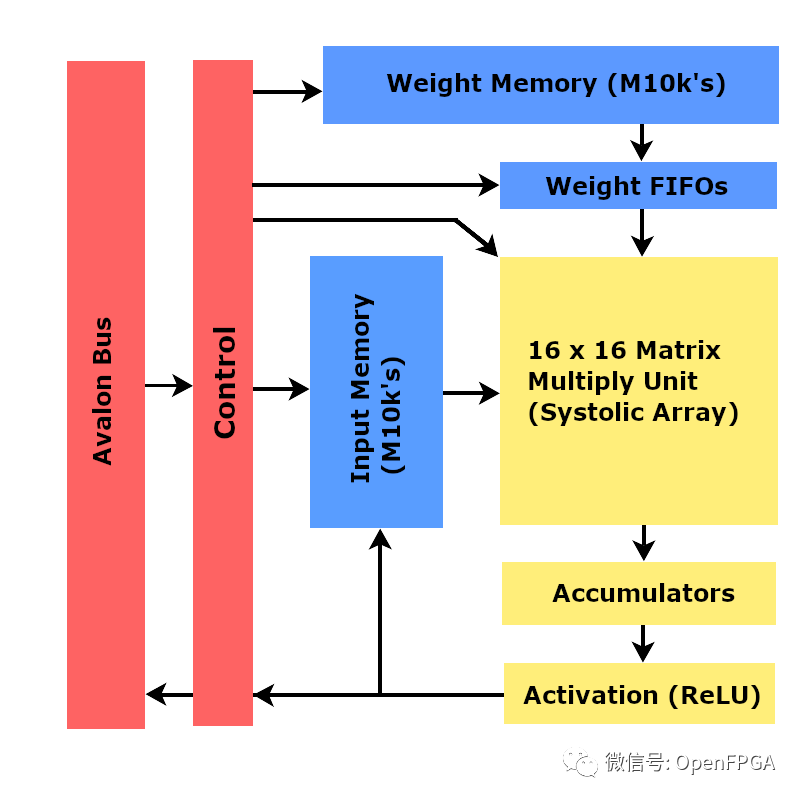
Tiny TPU is a small-scale implementation of Google TPU based on FPGA. The goal of this project is to understand the end-to-end technology of accelerator design from hardware to software while deciphering the low-level complexity of Google’s proprietary technology. In the process, we explore the possibility of a small-scale, low-power TPU.
This project was synthesized and programmed on the Altera DE1-SoC FPGA using Quartus 15.0.
For more detailed information:
❝
https://github.com/cameronshinn/tiny-tpu/blob/master/docs/report/report.pdf
TPU-Tensor-Processing-Unit
❝
https://github.com/leo47007/TPU-Tensor-Processing-Unit
Introduction
In a scenario where two matrices need to perform matrix multiplication, matrix A (select weight matrix) and matrix B (select matrix) are both 32×32. Finally, they start to perform the multiplication of each matrix, and each matrix’s factors will first be converted into a sequential input into the TPU, inputting its specific matrix, and then these units will input towards the direction connected to them. In the next cycle, each unit will assign its weights and data direction to the next cell. From left to right.
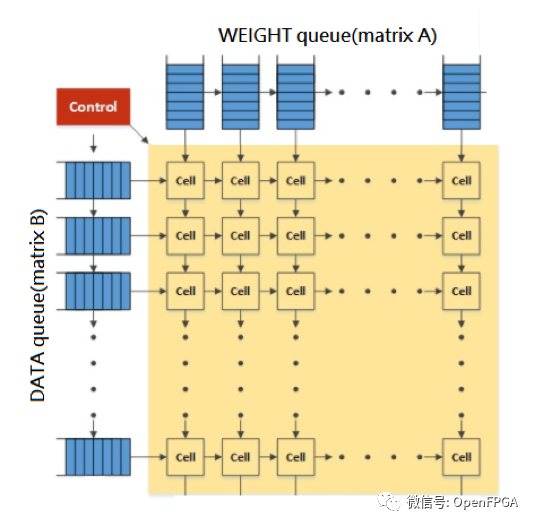
Since this project has a detailed introduction in Chinese, it will not be elaborated here.
❝
https://zhuanlan.zhihu.com/p/26522315
Systolic-array-implementation-in-RTL-for-TPU
❝
https://github.com/abdelazeem201/Systolic-array-implementation-in-RTL-for-TPU
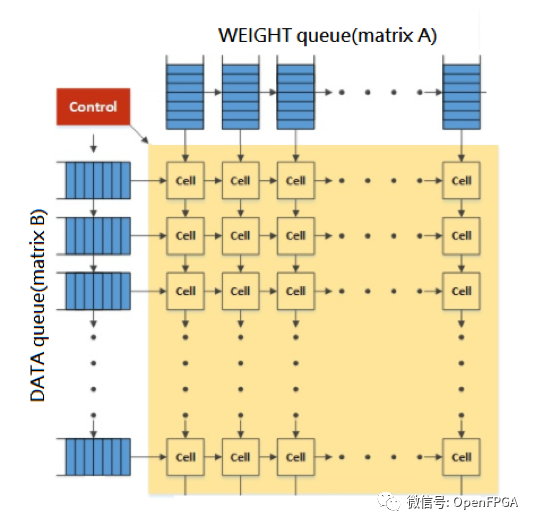
As shown below, in a scenario where two matrices need to perform matrix multiplication, matrix A (named weight matrix) and matrix B (named data matrix) are multiplied, with each matrix being 8×8. Once they start performing matrix multiplication, the coefficients of these two matrices will first be converted into a sequential input into the TPU, then input into each specific queue. These queues will output up to 8 data to the connected units, which will perform multiplication and addition based on the weights and data it receives. In the next cycle, each unit will forward its weights and data to the next unit. Weights go from top to bottom, and data goes from left to right.
This project, while achieving its related goals, still requires some optimization for actual use.
super_small_toy_tpu
❝
https://github.com/dldldlfma/super_small_toy_tpu
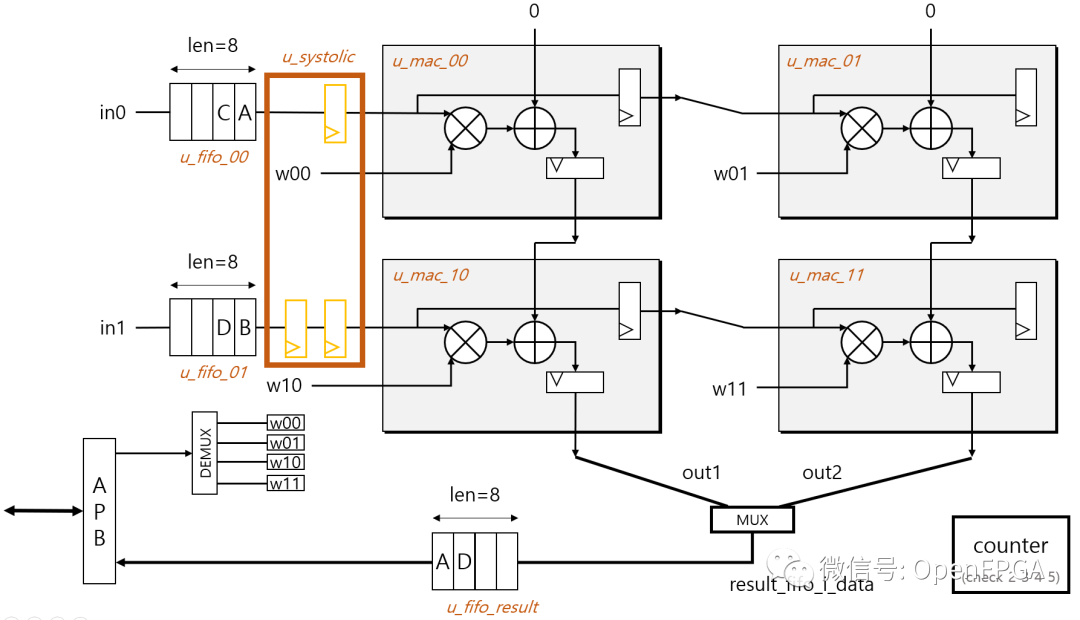
If the above several TPUs are relatively complex, then this one can be described as “streamlined”.
The entire code is very streamlined, suitable for beginners who want to study TPU.
AIC2021-TPU
❝
https://github.com/charley871103/TPU
❝
https://github.com/Oscarkai9139/AIC2021-TPU
❝
https://github.com/hsiehong/tpu
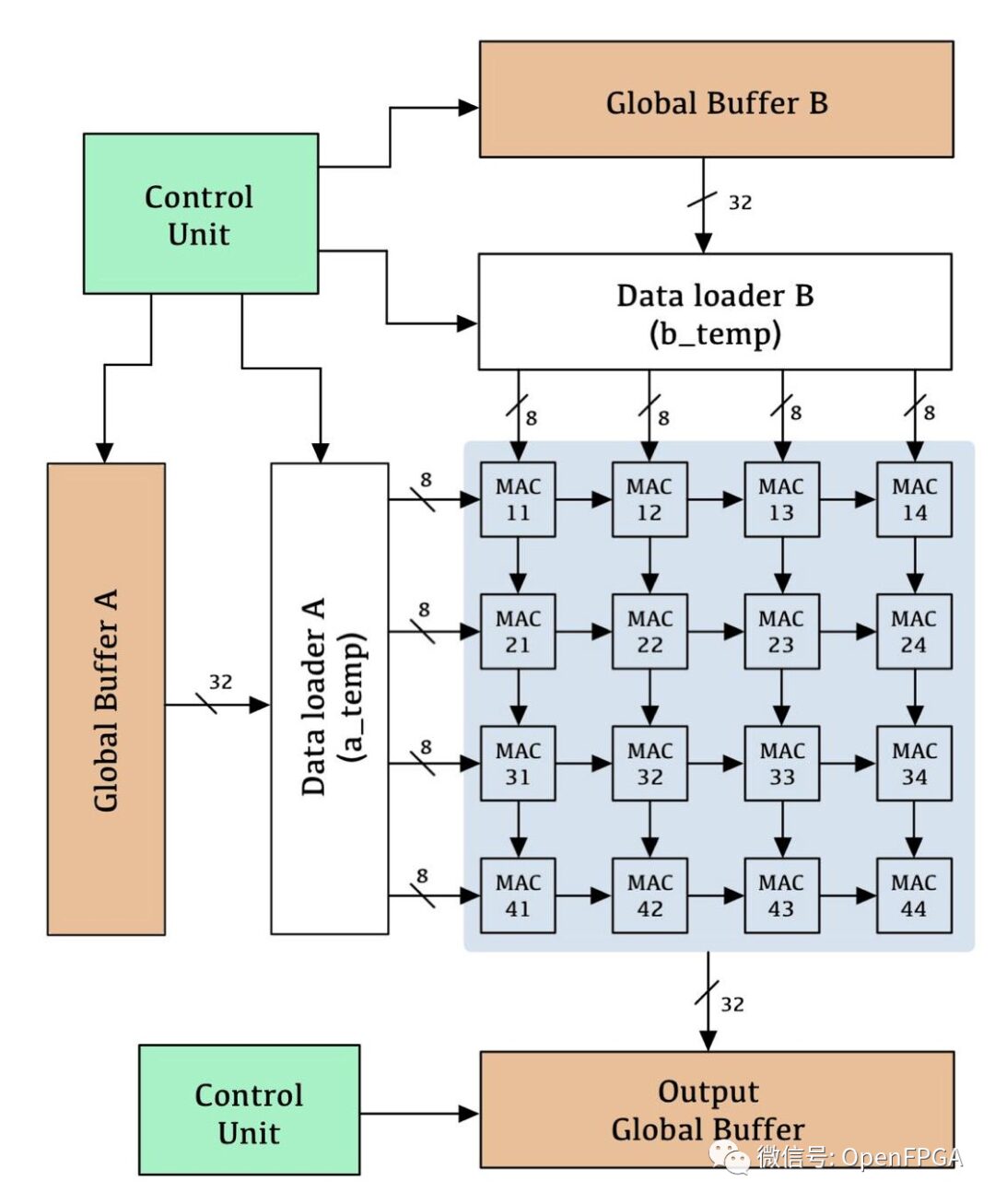
This project is AIC2021-TPU, and there are many similar projects, all of which are theoretical research projects, very suitable for beginners. The theories inside are extremely detailed.
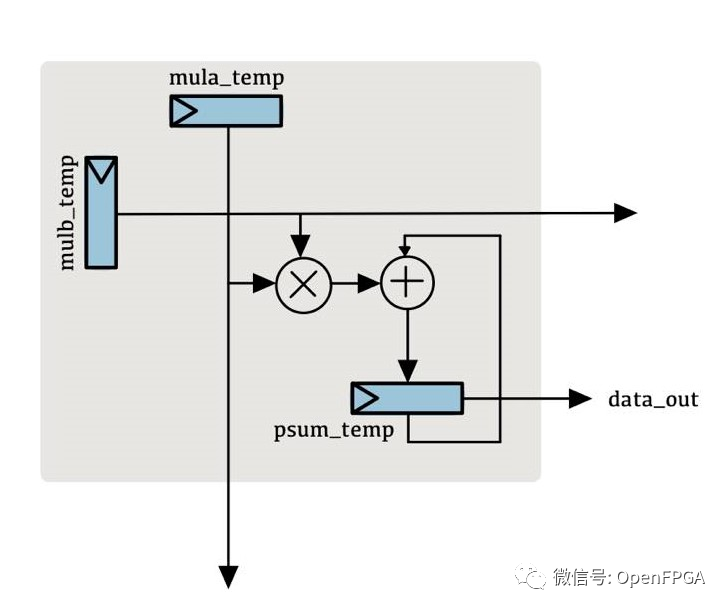
systolic-array
❝
https://github.com/Dazhuzhu-github/systolic-array
Verilog implementation of the systolic array computation convolution module in TPU
data is experimental data
source is the source code
testbench is used to test various modules
data-preprocessing was originally intended to write a Python preprocessing operation for the convolution operation, but later directly generated data using MATLAB for testing
tpu_v2
❝
https://github.com/UT-LCA/tpu_v2
The project has no extra introduction, and the entire project is designed based on Altera-DE3, with Quartus II as the EDA tool.

google-coral-baseboard
❝
https://github.com/antmicro/google-coral-baseboard

The open hardware design files for the baseboard of NXP i.MX8X and Google’s Edge TPU ML inference ASIC (also part of the Coral Edge TPU development board). The board provides standard I/O interfaces and allows users to connect to two compatible MIPI CSI-2 video devices via a unified flexible flat cable (FFC) connector.

The PCB project files were prepared in Altium Designer 14.1.
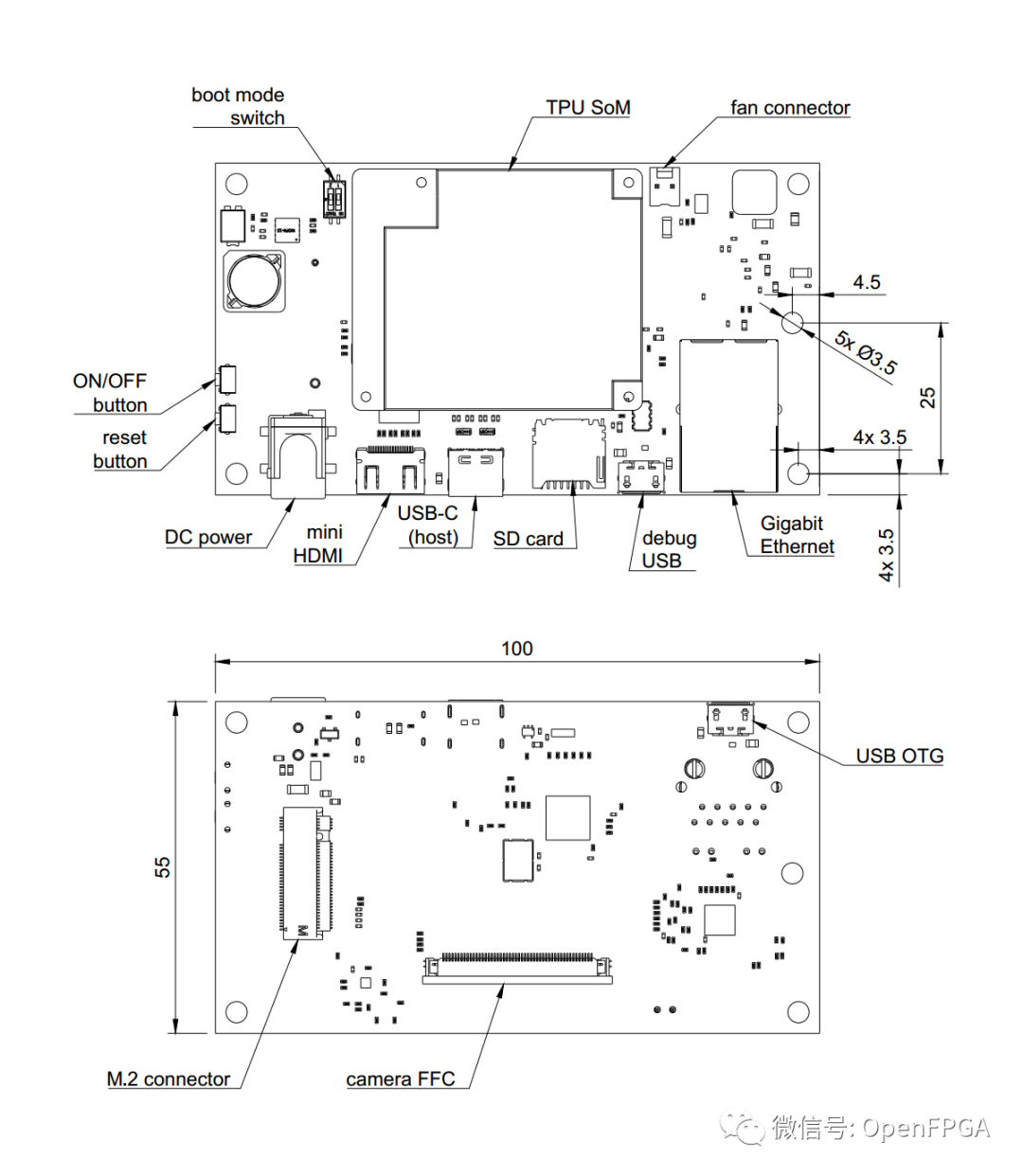
This project is a hardware solution, a hardware verification solution for Google’s Coral Edge TPU.
neural-engine
❝
https://github.com/hollance/neural-engine
Most new iPhones and iPads have a neural engine, a special processor that can make machine learning models very fast, but the public knows little about how this processor actually works.
The Apple Neural Engine (or ANE) is a type of NPU, representing a Neural Processing Unit. It is similar to a GPU, but an NPU accelerates neural network operations such as convolution and matrix multiplication instead of graphics.
ANE is not the only NPU—many companies, besides Apple, are developing their own AI accelerator chips. Besides the neural engine, the most famous NPU is Google’s TPU (or Tensor Processing Unit).
This project is not an implementation of TPU, but a collection of documents introducing the Apple Neural Engine (or ANE) and its related documentation.
Summary
Today we introduced several TPU projects, as many people may not have heard of TPU in China, so I will publish a few articles to introduce them. Meanwhile, the earlier projects are very complete and can be optimized for commercial promotion (note the open-source agreement), while the last few projects are supplementary knowledge. Friends who want to understand related knowledge can take a look.
Finally, thanks to all the great projects that have been open-sourced, which have benefited us immensely. If there are any areas of interest in future projects, everyone can leave a message in the background or add WeChat to leave a message. That’s all for today, I’m the exhausted碎碎思, looking forward to seeing you in the next article.
Excellent Introduction to Verilog/FPGA Open Source Projects (I) – PCIe Communication

Excellent Introduction to Verilog/FPGA Open Source Projects (II) – RISC-V
Excellent Introduction to Verilog/FPGA Open Source Projects (III) – Large Factory Projects

Childhood Restoration Series – Introduction to PC Engine/TurboGrafx-16 and FPGA Implementation

Excellent Introduction to Verilog/FPGA Open Source Projects (IV) – Ethernet
Excellent Introduction to Verilog/FPGA Open Source Projects (V) – USB Communication

Excellent Introduction to Verilog/FPGA Open Source Projects (VI) – MIPI

Introducing some excellent websites for beginners in FPGA (Added 2)

Rescuing Childhood Series – Introduction to GameBoy and FPGA Implementation

Excellent Introduction to Verilog/FPGA Open Source Projects (VII) – CAN Communication

Excellent Introduction to Verilog/FPGA Open Source Projects (VIII) – HDMI

Excellent Introduction to Verilog/FPGA Open Source Projects (IX) – DP (Revised Version)
Excellent Introduction to Verilog/FPGA Open Source Projects (X) – H.264 and H.265

Excellent Introduction to Verilog/FPGA Open Source Projects (XI) – SPI/SPI FLASH/SD Card
Excellent Introduction to Verilog/FPGA Open Source Projects (XII) – FPGA Not Boring

Excellent Introduction to Verilog/FPGA Open Source Projects (XIII) – I2C
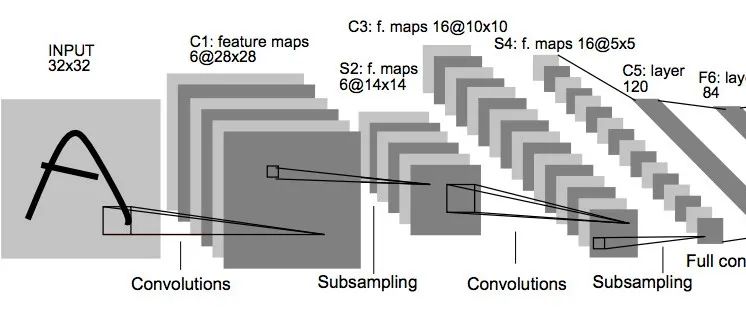
Excellent Introduction to Verilog/FPGA Open Source Projects (XIV) – Using FPGA to Implement the LeNet-5 Deep Neural Network Model

To Accelerate Neural Networks with FPGA, You Must Understand These Two Open Source Projects
Excellent Introduction to Verilog/FPGA Open Source Projects (XVI) – Digital Frequency Synthesizer DDS
Excellent Introduction to Verilog/FPGA Open Source Projects (XVII) – AXI

Perfectly Recreating Windows 95 on FPGA

Summary of OpenFPGA Series Articles
Discussion on Future Hardware Architecture of FPGA – NoC

If You Want to Learn About High-Speed ADC/DAC/SDR Projects, This Project You Must Understand

Excellent Introduction to Verilog/FPGA Open Source Projects (XIX) – Floating Point Processor (FPU)
Take Off! Debug FPGA via Wireless WIFI Download

Convenient FPGA Development – TCL Store (Open Source)