
This article shares information about the industrial time-series database IoTDB (full name Apache IoTDB) and some of its applications.
IoTDB originated from the School of Software at Tsinghua University. Under the leadership of Dean Wang, the team began focusing on it in 2011, and started its development in 2014/2015, consistently revolving around industrial data software, including data management software, machine learning software, data processing software, and application development software. I am mainly responsible for data management software. To unleash the value of data, it is crucial to manage the data properly for future data processing and application development.
Today, I will share about the industrial time-series database IoTDB (full name Apache IoTDB) and some of its applications, mainly divided into four aspects: what type of data IoTDB is solving; its relationship with industry; management challenges for this type of data; the characteristics of IoTDB and our practical applications.
Industry and Time-Series Data
What exactly is the industrial data we need to manage, and what is its relationship with industry? As shown in the figure below, with the development of industries, the proportion of manufacturing in the entire GDP will decrease, while service-oriented manufacturing will develop rapidly. The essence is how to provide stronger productivity under limited production resources as competition becomes increasingly fierce, and how to further enhance the value of products manufactured under the same productivity?
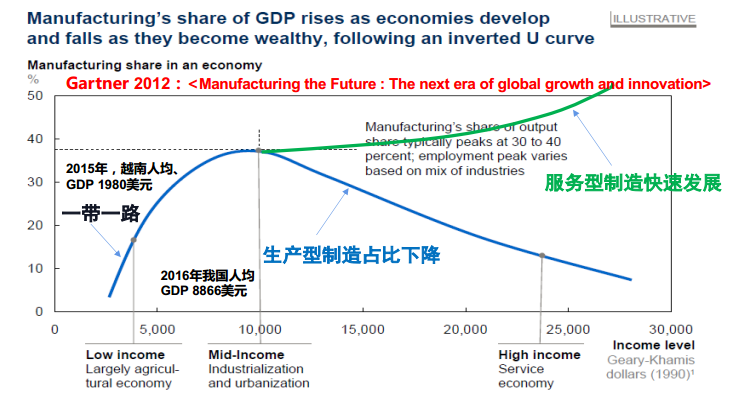
Under the impact of the pandemic, many industrial enterprises have further enhanced the value of their products and provided value-added services based on their products to improve competitiveness. How can we turn a downward curve into an upward green curve?
Big data is the core production material and key enabling technology in the entire industrial digital transformation and upgrade. It can be roughly divided into three categories:
The first category is industrial information data, which comes from traditional CRM, PLM, and other systems, including order information, maintenance information, etc., generated mainly by humans. The second category is cross-domain data, as all production operations are related to the broader environment; for example, disasters, weather conditions, and rising oil prices can all cause fluctuations in the final production value. The third category is data generated by machines and devices, which in this era are equipped with numerous sensors that help people diagnose and monitor the operational status of equipment, enabling more effective management or maintenance of these devices.
These three types of data together constitute the main body of industrial big data. Today, we will focus on the data generated by machines and the data produced by humans, which are quite different. In many cases, machines operate 24/7; for example, a power plant may require several million investments to ignite once, and once ignited, even if the power is saturated and production needs to be reduced, it will only lower the power and not stop operations. Many large machines need to run continuously for many days, and the frequency at which these machines collect data may be very high, with data being collected every second, millisecond, or even microsecond. Thus, the rate at which data is generated by these machines far exceeds the rate at which data is produced by humans.
Gradually, machines have become the main source of industrial big data. With this data, humans can better drive or adjust these devices, thus these devices themselves have also become the main consumers of this data. This data generated by machines is what we will discuss today, the time-series data.
Why is it called time-series data? Because the most typical feature of this data is that it records the changes of certain indicators of each device at different times. If viewed through a relational database, it takes the form of a table structure, and when visualized, with the horizontal axis as the time axis, we can see that each time series represents the changes of certain physical quantities or indicators of a device over time.
The Relationship Between Time-Series Data and Industry
GE pointed out as early as 2012 that massive time-series data is a historic opportunity to drive the new generation of industrial revolution.
Taking electricity as an example, automation systems in various stages of power generation, transmission, and distribution have been generating and collecting this data. How can we manage and utilize this massive data to ensure safety and optimize supply-demand balance?
For example, Goldwind can effectively help each wind turbine increase its power generation by collecting wind speed data, wind turbine orientation data, and power generation data, thus generating very intuitive and substantial economic value.
In the manufacturing stage, whether it is discrete manufacturing or process manufacturing, there is a wealth of process parameter data worth collecting, further ensuring production safety and improving yield and capacity. For instance, in the semiconductor industry, during the SMT component placement process, by collecting data changes such as the area, height, volume, and offset of each component, potential issues like blade wear and solder paste concentration affecting yield can be detected early. Additionally, through these time-series data, corresponding models can be trained to enhance the re-evaluation capability of monitoring equipment, reducing the workload of secondary manual re-evaluation and further stabilizing yield rates.
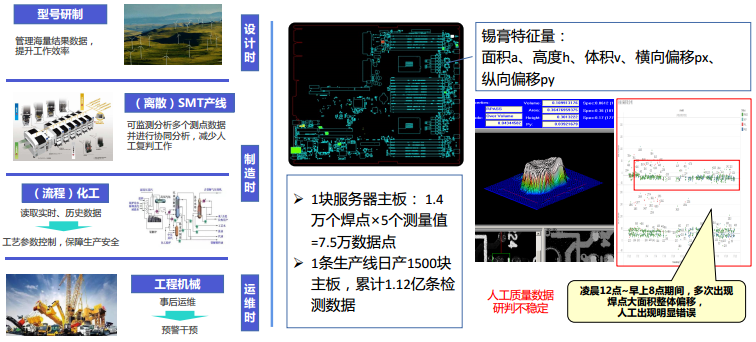
By collecting and analyzing a series of data such as the actual fuel consumption of construction machinery, geographical location changes, current load, and the pressure on the accelerator pedal by the driver, it can help drivers plan how to accelerate and which route to take to optimize fuel consumption. In the process of industrial transport and construction machinery usage, saving 10% of fuel can yield significant economic benefits.
To continuously leverage the value of data in industrial scenarios, it fundamentally depends on how much time-series data can be collected and managed. Many smart devices now claim to monitor the real-time status of equipment, but only manage real-time data. When these real-time data can be stored in a database and converted into historical data, more valuable explorations can be made.
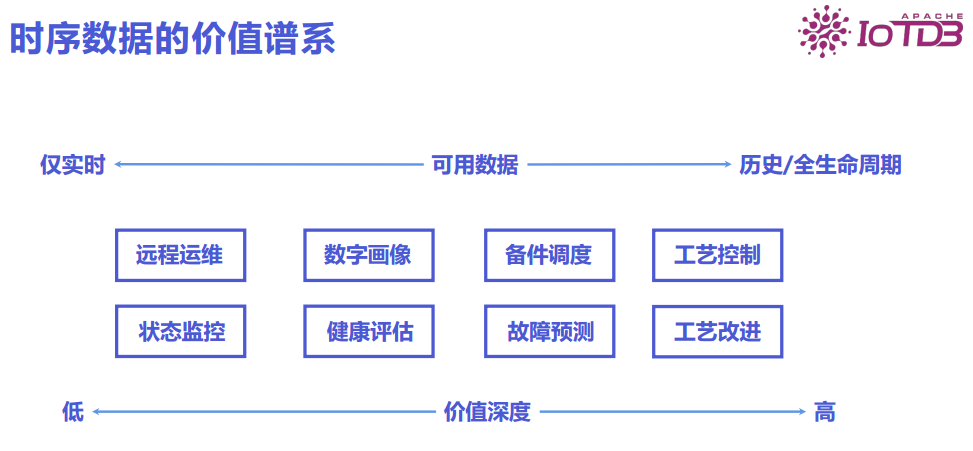
The following figure illustrates the process of actual data management from less to more, which is also the process of the value of time-series data increasing from low to high. With real-time data, status monitoring and remote operations can be performed; with a longer duration of data, digital representations of these devices can be created for health assessments, deterioration trend discovery, fault prediction, and spare parts scheduling; with data from the entire lifecycle of the equipment, improvements and controls can be made to its manufacturing process based on its performance during service. The more historical data accumulated, the deeper the discoverable value.
New Demands and Challenges in Time-Series Data Management
In the industrial sector, time-series data is not a new concept; these data have been collected and stored in DCS systems since the invention and mass adoption of automation equipment. Why are we discussing this data again now? Because the demands in the industrial field are changing.
Traditional DCS systems are mostly deployed on the factory side, but now there are smart meters, smart connected vehicles, smart streetlights, and many movable smart devices that also have data collection capabilities, and this data needs to be managed.
Meanwhile, to achieve more refined applications, the frequency at which devices collect data may have changed from once every five seconds to once every second, or even once every millisecond, significantly increasing the performance requirements for underlying data management systems from tens of thousands of points per second to millions, or even hundreds of millions of points per second.
Moreover, traditional applications such as status monitoring and real-time alerts do not have high storage demands for historical data, so in many cases, a strategy of sampling one out of ten or one out of a hundred is employed, only storing certain critical data while discarding normal or subtle changes. However, qualitative changes arise from quantitative changes; it is precisely these subtle changes that help us gain insights into problems more quickly and deeply, leading to a gradual shift towards full storage of all data.
Additionally, in the past, after data was generated on the device side, it would be sent to the cloud, where the data could be viewed at the data center. Now, as hardware becomes cheaper and edge computing capabilities increase, local intelligence also requires data management capabilities and needs to work well with the cloud. Under these new demands, simply storing these time-series data would continuously increase management costs; only through thorough analysis and computation can costs be transformed into value. In this process, there are many challenges in time-series data management brought about by the unique scenarios of industrial users.
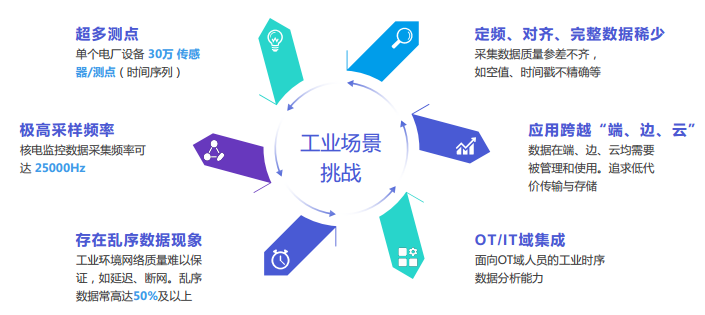
Industrial equipment is complex enough, especially the number of indicators observed on expensive industrial equipment can be very large. For example, due to some historical reasons and secondary processing of data, a power plant may need to observe over 300,000 indicators; additionally, for vibration analysis, the sampling frequency of this data may reach megahertz levels.
Due to the harsh environment of industrial scenarios and issues with upgrading industrial controllers, many real-time data do not arrive at the cloud in the order they were generated. An industrial device may consist of multiple controllers from different brands, each determining the data collection frequency based on the importance of the components, and the starting time for data collection may also differ. If represented in a table, although this device has 300,000 indicators to monitor, at one moment it may only have seven or eight indicators, while at another moment it may have 30 indicators. This inconsistency greatly increases the cost and difficulty of using the data in the future.
Fast Iteration of Edge Devices. In the past, a device monitored three to five points, but as applications deepened, more important points needed to be monitored, necessitating the addition of small components to diagnose the device, which increased the amount of data that could be collected and sensed.
When using traditional relational databases for storage, the maintenance workload for the schema is very large, and errors often occur, resulting in a large amount of data being collected but unable to be stored. IoTDB addresses this situation by adopting a cloud-side adaptation method for edge-side data, automatically creating metadata for the sequences based on the incoming data to reduce management costs and allow more data to be stored.
Massive Measurement Points for Complex Devices. Traditional relational databases often use vertical partitioning schemes to divide a table into several tables to express a complex object or device, which creates additional workloads and reduces performance. IoTDB can accommodate an unlimited number of time series, allowing for an arbitrary complex description of asset management relationships and the composition of devices, as well as the relationships between these compositions and measurement points on various components.
High Sampling Frequency. When the sampling frequency becomes very high, traditional relational databases can easily reach the single-table storage limit of 10 million rows, and horizontal partitioning schemes require daily partitioning, leading to the concept of daily tables in many IT systems. This can cause issues with querying and other operations. IoTDB’s unique handling of time-series data helps users continuously and efficiently write, query, and manage ultra-high throughput data, with very low storage costs, accommodating PB-level data.
Independent Data Collection for Each Component. The data collection for different components on a device is independent, with different frequencies and misaligned collection times, leading to practical issues such as differing vector lengths during visualization or correlation analysis of two sequences. IoTDB organizes this data management work within the database, allowing it to support time-series data by aligning multiple sequences by time and filling in missing values, making it easier for users to utilize the data and unleash its value.
Out-of-Order Data Arrival in Industrial Environments. The quality of industrial network environments is difficult to guarantee, often experiencing issues like delays and disconnections, causing data to arrive out of order. IoTDB supports out-of-order writing of time series.
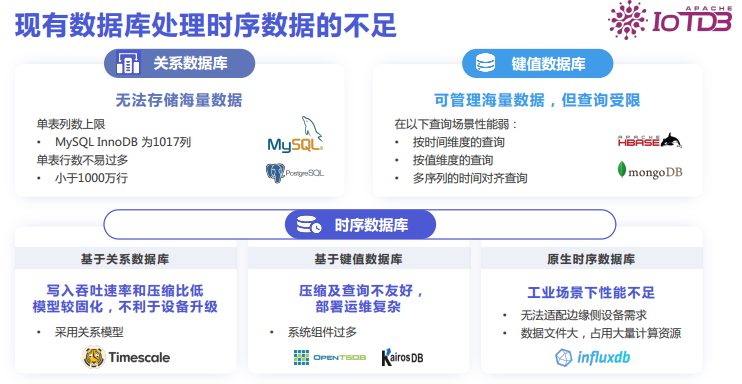
In summary, in terms of time-series data processing, some time-series databases have certain shortcomings in performance, functionality, and storage costs. There are many new time-series databases available on the market, but their application scenarios and underlying technology stacks are not designed for industrial purposes; they are designed for performance monitoring in internet enterprises, leading to unstable or poor performance when facing the special requirements of industrial scenarios.
IoTDB and Its Derivative Products
The original intention of developing IoTDB is to help industrial users solve the problems of storage, querying, and utilization of time-series data, supporting massive read/write of machine data and enabling users to store data at ultra-low costs and conduct in-depth analysis and mining. We hope IoTDB can become one of the infrastructures for smart manufacturing or the future industrial internet of things.
The main features of IoTDB, besides high-throughput data, low cost, high compression, and high availability, also include an IoT-native model and edge-cloud collaborative mode. As a database, it also provides users with interfaces for writing and querying.
IoTDB originated from a project under the 863 Program, and during collaboration with a leading industrial enterprise in the country, it was noted that their engineering machinery data was experiencing bottlenecks in management within Oracle, making it impossible to further apply business uses.
Since 2015, we have been independently developing IoTDB and have validated it in many scenarios and technologies. In 2018, we officially submitted IoTDB to the Apache Foundation, attracting a series of domestic and international peers to develop and utilize it. In 2020, IoTDB officially graduated and became a top global project of Apache. Following its continuous promotion, IoTDB has won a series of open-source awards in the country.
Currently, IoTDB is the only project under Apache’s IoT database, and it can even be said to be the only project specifically designed for time-series data. IoTDB has also been selected for the National “13th Five-Year” Science and Technology Innovation Achievement Exhibition and has won the first prize for scientific and technological progress in Beijing. During the independent research and development process of IoTDB, a large number of new patents related to time-series data were generated, and some papers were published. It is an IoT-native time-series database with its own benchmark performance.
We hope to help users improve quality and efficiency and reduce data management costs through this product. Most importantly, we aim to provide users with low-cost and high-performance services, facilitating the import of data from other systems into IoTDB, and providing a rich data processing ecosystem and one-stop solutions.
Compared to some other open-source systems, IoTDB’s writing performance is far ahead, and in practical user cases, a single IoTDB can replace a cluster of 15 NoSQL database servers. In terms of query performance, IoTDB leads similar products, whether for raw data queries or aggregate queries. A single IoTDB can simultaneously meet the needs for real-time data monitoring and massive historical data querying.
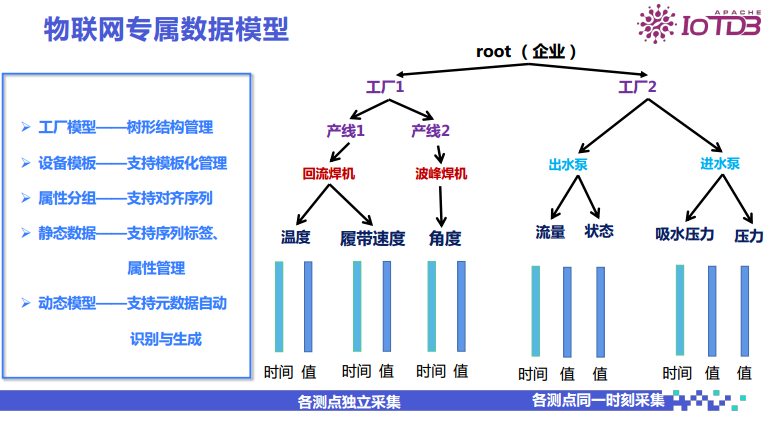
The tree-structured data model managed by IoTDB is very suitable for factories. A factory may have multiple units of the same model of production equipment, and when the observed indicators are the same, IoTDB provides a template management method. For multiple indicators on a device, it can collect them simultaneously; when the collection frequency is the same, it can use aligned collection modes. For collections at different times with varying frequencies, we provide a unit sequence method for independent data collection of each measurement point. For this data, there is both static data management and data management along with time changes. Additionally, nodes can be added to the tree to achieve dynamic modeling.
Although there is some learning cost for traditional IT personnel, it is more aligned with the business scenarios for OT personnel. To achieve low-cost storage, we independently developed a columnar file format called Tsfile. It has both a columnar storage form and a highly compressed coding structure, along with various segment aggregation statements and information to help users quickly perform down-sampling, aggregate queries, and generate reports. At the end of the file, we also have an index for the file set to help users quickly locate data under massive amounts of data.
When the sampling frequency is increased to the millisecond level, different applications may require different sampling frequencies for querying data. Therefore, we provide users with real-time down-sampling capabilities, allowing a sequence to be down-sampled into a sparser data density sequence to alleviate the pressure on the business or application side. We can write the processed down-sampled data or other results back into the database, generating original data, processed data, and further processed data, ultimately transforming them into knowledge and decisions.
For data of lower quality, simple down-sampling can be performed, aligning the data by time and filling in missing values within each minute to help users obtain a neater and more analyzable dataset. In addition to writing modeling and querying, IoTDB provides a large number of analytical functions, supporting customized analysis and allowing users to develop and create functions to meet industrial mechanism analysis needs. Currently, IoTDB has completed a total of 75 functions.
Not only that, but from the moment data enters IoTDB, capabilities for data computation throughout the entire lifecycle of collection, storage, querying, and analysis are provided. When a data point is collected and written into the database, a trigger mechanism is provided. Users can make predictions, judgments, and alerts for each newly written data point, and can process and modify the data, deriving new variables from multiple data calculations.
Once the data enters the database, we also provide users with a backend offline computing mode, helping users retrieve data for processing and then writing it back into the database. This may be referred to as materialized views within the database. By executing periodically, we assist users in gradually processing the original data during non-busy times. When users perform real-time queries, they can also conduct calculations through UDF function mechanisms.

When IoTDB is integrated with big data ecosystems such as Spark and Flink, more big data analysis applications can be developed. Throughout the process, calculations can be performed on each incoming data value, or calculations can be made based on time windows, allowing users to customize their calculation logic to better organize data.
Furthermore, the design concept of edge-cloud collaboration in IoTDB aims to break the traditional process where data generated at the edge must be encoded, compressed, and uploaded to the cloud, where it is decoded, decompressed, and written to the database, consuming CPU and memory for sorting and indexing the data. When the edge side has sufficient computing power, data can be encoded, uploaded to the cloud, and analyzed directly in the cloud. In this mode, the CPU usage on the cloud side is significantly reduced, and network bandwidth is also greatly lowered. We have also collaborated with some ecosystem software, allowing users to conveniently use our database for data visualization, interactive analysis, and big data analysis of time-series data using standard languages such as Spark.
IoTDB inherits many features from Apache’s open-source projects and deploys Apache, covering all stages from collection, processing, analysis, to application.
As a time-series database, IoTDB primarily provides capabilities for modeling, querying, processing, analyzing time-series data, and low-cost storage. Beyond this, we are gradually deriving additional functions around IoTDB to assist users in data collection alerts, complex alerts based on rule engines, data visualization, interactive analysis, and big data analysis.
Application Cases
Tsinghua has promoted IoTDB for many years, and it has been used extensively by numerous open-source users and enterprise clients, currently serving hundreds of enterprises, including a series of state-owned enterprises, industrial leading companies, and some national dual-cross platforms.
Currently, the most distant application is on a satellite, where a small box installed with IoTDB manages real-time data in space. Slightly lower is the data management for airplanes; the data management for the trial phase of the C919 large passenger aircraft from COMAC uses IoTDB, as does the test flight data for Chengfei UAVs. Currently, IoTDB has managed trillions of data points, with data volume reaching several TB.
On the ground, we have linked with many factories and subway vehicles; at sea, we collaborate with China Shipbuilding to manage ship and hydrological change data.
IoTDB also has many international users, collaborating with German companies to serve BMW, Deutsche Bahn, and others. Collaborations with Bosch, Siemens, and other companies are also underway.
First, let’s discuss domestic applications:
In collaboration with CRRC, we manage data for all trains in the Shanghai subway. Previously, this was managed by 15 KairosDBs and a Cassandra backend, managing data for 144 trains, with each train having 3000 measurement points and a sampling frequency of 500 milliseconds. After upgrading, a single IoTDB can manage this level of data and significantly increase the upper capacity. When the system fully transitions to IoTDB, we will re-import the data that was originally stored in CTV for three years; the 200TB of data stored over three years with other systems can be compressed to 16TB in IoTDB, reducing storage costs by nearly 90%.
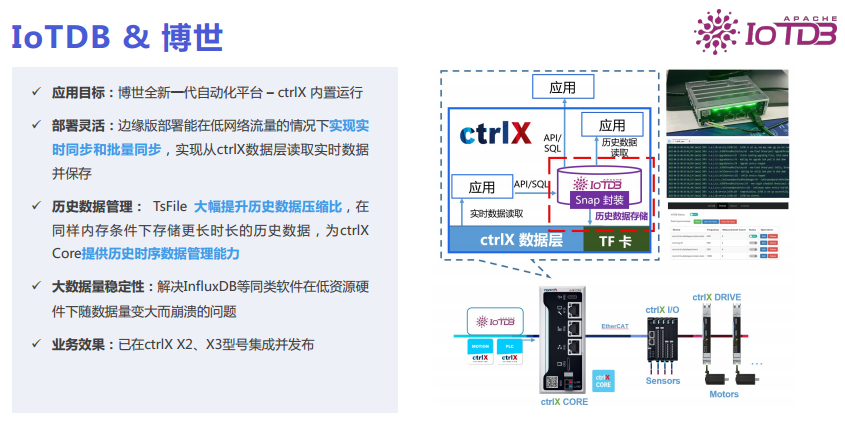
In collaboration with Bosch, the ctrlX AUTOMATION from Bosch, shown in the top right corner of the image, can be deployed directly on the factory side. It is somewhat similar to domestic industrial PCs. However, it integrates better with other Bosch devices, making it extremely promising. Previously, this box did not have the capability to manage historical data; we installed IoTDB inside the box, allowing it to manage historical data. Last month, this product was launched at Bosch’s exhibition in Germany and at the SPS exhibition.
In collaboration with Hunan Zhongyan, two to three years ago, we helped manage data for the centralized control workshop and factory, monitoring the status of 260 devices in the twisting and packaging workshops, involving the collection of 90135 time-series data, aggregating data from multiple factories into a company-level big data platform, forming a multi-level data management system for workshops, factories, and groups, managing various process parameter data during manufacturing to improve production efficiency and reduce losses.
In collaboration with Datang Xianyi, we replaced open TSDB in four thermal power plants and over 60 renewable energy power generation enterprises to manage data; what previously required a cluster can now be handled by a single node, reducing operational costs by 95%.
In collaboration with State Grid, IoTDB is applied in business scenarios such as the Chengdu Shidai Jiajia charging station and the Beijing Yizhuang photovoltaic station, where IoTDB is placed inside the meter box to achieve real-time status monitoring of the charging station, as well as local load calculation, harmonic calculation, and terminal fault warning capabilities.
In collaboration with Changan Automobile, we helped Changan aggregate data to the cloud, building a cloud platform that improved the response speed for fault data queries from minutes to seconds, enhancing user experience and enabling more business applications.
In collaboration with Taiji, this is an application in a thermal power plant, using IoTDB to replace Apache Druid, constructing a remote analysis platform for generator sets, managing data from 11 generator sets and significantly reducing operational costs.
In collaboration with the China Meteorological Administration, we store real-time data from 100,000 ground meteorological observation stations nationwide. Previously, it was inconvenient to view single station data, especially historical data for a single station, as meteorological forecasters somewhat rely on visual residuals when forecasting data. To quickly view changes in data over different times and visually create animation effects, it requires the database to highlight the data changes at each moment at very high speeds, which IoTDB precisely meets.
In collaboration with Dongfang Guoxin, we built the Dongfang Guoxin Cloudiip platform, which has been selected as one of the top ten dual-cross platforms in the country for four to five consecutive years. The underlying time-series database is based on IoTDB, and we have also released derivative products called CirroData-TimeS based on IoTDB.
In collaboration with Yonyou, we managed data from factory production equipment. Yonyou is also building corresponding products based on IoTDB. Additionally, there are some application scenarios that are slightly further from industry, including finance and DFS. We welcome everyone to pay attention to the open-source project IoTDB.
Editor: Wang Jing
Proofreader: Lin Yilin
