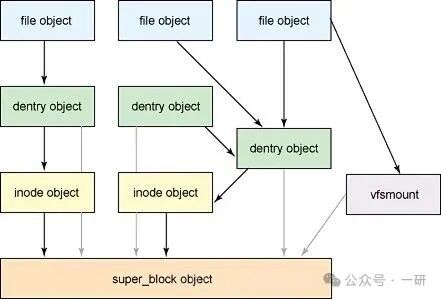
In the Linux system, the virtual file system (VFS) serves as an abstraction layer for file systems, providing a unified file operation interface for upper-level applications.
The previous article detailed the core member interface functions of Linux VFS, helping to understand the underlying implementation of file systems.
The atomic operation mechanism implemented at the VFS layer is the core of ensuring file system consistency and reliability.
This article will delve into the typical atomic operation functions provided by the VFS layer and their implementation principles.
1. Overview of VFS Layer Atomic Operations
As an abstraction layer for file systems, VFS defines standard file operation interfaces file_operations and inode operation interfaces inode_operations.
Many functions in these interfaces require atomicity to ensure data consistency in multi-process and multi-thread environments.
“`c
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
// …
};
struct inode_operations {
int (*create) (struct inode *, struct dentry *, umode_t, bool);
struct dentry * (*lookup) (struct inode *, struct dentry *, unsigned int);
int (*link) (struct dentry *, struct inode *, struct dentry *);
int (*unlink) (struct inode *, struct dentry *);
int (*symlink) (struct inode *, struct dentry *, const char *);
int (*mkdir) (struct inode *, struct dentry *, umode_t);
int (*rmdir) (struct inode *, struct dentry *);
// …
};
“`
Key Technology Explanation:
VFS allows different file systems (such as ext4, XFS, Btrfs) to implement their own atomicity mechanisms while maintaining the same API through unified interface abstraction.
This design ensures that upper-level applications do not need to concern themselves with the specific implementation details of the underlying file systems.
2. Atomicity of File Creation and Deletion
2.1 Atomic Operation of File Creation (create)
VFS provides atomicity guarantees for file creation through the vfs_create() function:
“`c
int vfs_create(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode, bool want_excl)
{
int error;
// Check directory permissions
error = may_create(mnt_userns, dir, dentry);
if (error)
return error;
// Check if create operation is supported
if (!dir->i_op->create)
return -EACCES;
// Acquire directory inode lock to ensure atomicity
inode_lock(dir);
// Call the specific file system’s create method
error = dir->i_op->create(mnt_userns, dir, dentry, mode, want_excl);
// Release lock
inode_unlock(dir);
return error;
}
“`
Key Technology Explanation:
• Lock Granularity Optimization: inode_lock() only locks the parent directory inode, rather than the entire file system, significantly reducing lock contention.
• Namespace Awareness: Modern kernels support user namespace isolation through the user_namespace parameter.
• Pre-validation Mechanism: All permission and feasibility checks are completed before acquiring the lock, minimizing the length of the critical section.
2.2 Atomic Operation of File Deletion (unlink)
File deletion is implemented atomically through vfs_unlink():
“`c
int vfs_unlink(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, struct inode **delegated_inode)
{
struct inode *target = d_inode(dentry);
int error;
// Permission and status checks
error = may_delete(mnt_userns, dir, dentry, 0);
if (error)
return error;
// Deletion operation not supported
if (!dir->i_op->unlink)
return -EPERM;
// Acquire locks for directory and target inode
inode_lock(target);
inode_lock_nested(dir, I_MUTEX_PARENT);
// Actual deletion operation
error = dir->i_op->unlink(dir, dentry);
if (!error) {
// Disconnect dentry from inode
dont_mount(dentry);
detach_mounts(dentry);
}
inode_unlock(dir);
if (!error)
d_delete(dentry);
inode_unlock(target);
return error;
}
“`
Key Technology Explanation:
• Mount Point Handling: detach_mounts() ensures that the deletion operation correctly handles mount points, preventing mount leaks.
• Nested Lock Application: Using I_MUTEX_PARENT clarifies the locking hierarchy, avoiding lock order issues.
• dentry State Management: d_delete() marks the dentry as deleted, but actual release may be delayed.
3. Atomicity of Rename Operations
File renaming is one of the most complex atomic operations in VFS:
“`c
int vfs_rename(struct renamedata *rd)
{
struct inode *old_dir = rd->old_dir;
struct dentry *old_dentry = rd->old_dentry;
struct inode *new_dir = rd->new_dir;
struct dentry *new_dentry = rd->new_dentry;
unsigned int flags = rd->flags;
int error;
bool is_dir = d_is_dir(old_dentry);
// Complex permission and status checks
error = may_delete(rd->old_mnt_userns, old_dir, old_dentry, is_dir);
if (error)
return error;
// Check target directory permissions
if (new_dir != old_dir) {
error = may_create(rd->new_mnt_userns, new_dir, new_dentry);
if (error)
return error;
}
// Acquire locks for all related inodes to avoid deadlocks
lock_two_inodes(old_dir, new_dir, I_MUTEX_NORMAL);
// Handle errors when renaming a directory to a subdirectory
if (is_dir) {
error = -EINVAL;
if (new_dir == old_dir)
goto out;
error = -ENOTEMPTY;
if (d_mountpoint(old_dentry))
goto out;
}
// Call the specific file system’s rename method
error = old_dir->i_op->rename(rd);
out:
inode_unlock(new_dir);
if (new_dir != old_dir)
inode_unlock(old_dir);
return error;
}
“`
Key Technology Explanation:
• Unified Parameter Encapsulation: The renamedata structure encapsulates all renaming parameters, simplifying the interface.
• Mount Point Check: d_mountpoint() checks ensure that mount points are not renamed, maintaining the integrity of the mount tree.
• Cross-File System Handling: If the old and new directories are on different file systems, VFS will fall back to a copy+delete method.
4. Atomicity of Link Operations
4.1 Creating Hard Links
“`c
int vfs_link(struct dentry *old_dentry, struct user_namespace *mnt_userns,
struct inode *dir, struct dentry *new_dentry,
struct inode **delegated_inode)
{
struct inode *inode = d_inode(old_dentry);
int error;
// Permission check
error = may_create(mnt_userns, dir, new_dentry);
if (error)
return error;
// File system does not support linking
if (!dir->i_op->link)
return -EPERM;
// Cannot create hard links to directories
if (S_ISDIR(inode->i_mode))
return -EPERM;
// Cross-device link check
if (dir->i_sb != inode->i_sb)
return -EXDEV;
// Lock protection
inode_lock(inode);
inode_lock_nested(dir, I_MUTEX_PARENT);
// Actual link operation
error = dir->i_op->link(old_dentry, dir, new_dentry, delegated_inode);
if (!error) {
// Update link count and timestamp
fsnotify_link(dir, inode, new_dentry);
}
inode_unlock(dir);
inode_unlock(inode);
return error;
}
“`
Key Technology Explanation:
• Delegated Inode Handling: The delegated_inode parameter supports delegation mechanisms for network file systems like NFS.
• Atomic Update of Link Count: The inode’s i_nlink field is updated atomically to ensure concurrent safety.
• Safe Event Notification: fsnotify_link() notifies monitoring processes of link creation events.
5. Atomicity of Directory Operations
5.1 Directory Creation (mkdir)
“`c
int vfs_mkdir(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry, umode_t mode)
{
int error;
error = may_create(mnt_userns, dir, dentry);
if (error)
return error;
if (!dir->i_op->mkdir)
return -EPERM;
// Set directory permission bits
mode &= (S_IRWXUGO|S_ISVTX);
error = security_inode_mkdir(dir, dentry, mode);
if (error)
return error;
error = dir->i_op->mkdir(mnt_userns, dir, dentry, mode);
if (!error)
fsnotify_mkdir(dir, dentry);
return error;
}
“`
Key Technology Explanation:
• Security Hook Integration: security_inode_mkdir() calls LSM hooks, supporting mandatory access control.
• Event Notification Integrity: The fsnotify_mkdir notification is sent only after successful directory creation.
• Permission Inheritance Mechanism: New directories typically inherit the SGID bit from the parent directory, supporting group collaboration.
5.2 Directory Deletion (rmdir)
“`c
int vfs_rmdir(struct user_namespace *mnt_userns, struct inode *dir,
struct dentry *dentry)
{
int error;
struct inode *target = d_inode(dentry);
error = may_delete(mnt_userns, dir, dentry, 1);
if (error)
return error;
if (!dir->i_op->rmdir)
return -EPERM;
inode_lock(target);
inode_lock_nested(dir, I_MUTEX_PARENT);
// Check if directory is empty
error = -ENOTEMPTY;
if (d_empty(dentry))
error = dir->i_op->rmdir(dir, dentry);
inode_unlock(dir);
if (!error) {
d_delete(dentry);
fsnotify_rmdir(dir, dentry);
}
inode_unlock(target);
return error;
}
“`
Key Technology Explanation:
• Directory Empty Check: d_empty() checks if the directory is truly empty, preventing accidental deletion of non-empty directories.
• Event Timing Guarantee: The directory lock ensures that event notifications occur in the same order as the operations.
• Error Code Precision: Clearly distinguishes between permission errors (-EPERM) and non-empty directory errors (-ENOTEMPTY).
6. Synchronization Mechanisms for VFS Atomic Operations
6.1 Inode Lock Mechanism
VFS uses read-write semaphores to protect inode operations:
“`c
// Modern kernels use i_rwsem read-write semaphores
void inode_lock(struct inode *inode) {
down_write(&inode->i_rwsem);
}
void inode_unlock(struct inode *inode) {
up_write(&inode->i_rwsem);
}
// Nested lock support
void inode_lock_nested(struct inode *inode, unsigned int subclass) {
down_write_nested(&inode->i_rwsem, subclass);
}
// Locking multiple inodes (to avoid deadlocks)
void lock_two_inodes(struct inode *inode1, struct inode *inode2,
unsigned subclass) {
if (inode1 == inode2) {
inode_lock_nested(inode1, subclass);
} else if (inode1 < inode2) {
inode_lock_nested(inode1, subclass);
inode_lock_nested(inode2, subclass + 1);
} else {
inode_lock_nested(inode2, subclass);
inode_lock_nested(inode1, subclass + 1);
}
}
“`
Key Technology Explanation:
• Lock Order Normalization: A deterministic lock order based on memory addresses is key to preventing deadlocks.
• Advantages of Read-Write Semaphores: Supports multiple concurrent readers, optimizing read-heavy workloads.
• Lock Class Debugging Support: Lock class mechanisms help the lockdep deadlock detector identify the hierarchy of locks.
6.2 Reference Count Management
VFS uses atomic operations to manage the reference counts of inodes and dentries:
“`c
struct inode {
// …
atomic_t i_count; // Reference count
// …
};
// Increase reference count
static inline void ihold(struct inode *inode)
{
atomic_inc(&inode->i_count);
}
// Decrease reference count, destroy inode if it reaches 0
void iput(struct inode *inode)
{
if (!inode)
return;
if (atomic_dec_and_lock(&inode->i_count, &inode->i_lock)) {
// Actual destruction logic
iput_final(inode);
}
}
// dentry reference count
static inline void dget(struct dentry *dentry)
{
atomic_inc(&dentry->d_count);
}
void dput(struct dentry *dentry)
{
if (unlikely(!dentry))
return;
if (atomic_dec_and_lock(&dentry->d_count, &dentry->d_lock)) {
// Actual destruction logic
d_free(dentry);
}
}
“`
Key Technology Explanation:
• Memory Order Guarantees: Atomic operations include appropriate memory barriers to ensure multi-core consistency.
• Safe Decrement Check: atomic_dec_and_lock() atomically checks the reference count and acquires the lock if necessary.
• Delayed Release Optimization: Dentries may enter the LRU list instead of being released immediately, improving performance.
7. Implementation of Atomic Operations in Specific File Systems
7.1 Atomic Renaming in the Ext4 File System
“`c
static int ext4_rename(struct user_namespace *mnt_userns,
struct inode *old_dir, struct dentry *old_dentry,
struct inode *new_dir, struct dentry *new_dentry,
unsigned int flags)
{
handle_t *handle;
int credits;
struct inode *old_inode = d_inode(old_dentry);
struct inode *new_inode = d_inode(new_dentry);
// Calculate required log credits
credits = ext4_rename_entries(old_dir, old_dentry, flags);
if (credits < 0)
return credits;
handle = ext4_journal_start(old_dir, EXT4_HT_DIR, credits);
if (IS_ERR(handle))
return PTR_ERR(handle);
// Execute renaming operation within a transaction
// …
// Commit transaction
error = ext4_journal_stop(handle);
return error;
}
“`
Key Technology Explanation:
• Dynamic Credit Calculation: ext4_rename_entries() calculates the required log space based on the complexity of the actual operation.
• Log Handle Management: The transaction handle ensures that all metadata changes occur within a single atomic transaction.
• Error Recovery Mechanism: The logging system can replay or roll back incomplete transactions after a crash.
7.2 Log-Based Atomicity Guarantees
Modern file systems ensure the atomicity of metadata operations through a logging mechanism:
1. Transaction Start: Allocate log space and record a transaction start marker.
2. Metadata Log: Write metadata changes to the log area first.
3. Commit Record: Write a transaction commit marker, indicating that the log entries are complete.
4. Checkpoint: Write changes from the log to the actual file system locations.
5. Log Cleanup: Reclaim log space after confirming that the checkpoint is complete.
Key Technology Explanation:
• Write-Ahead Logging: Most Linux file systems use write-ahead logging, recording logs before modifying actual data.
• Atomic Commit: Writing the commit record is the key point of transaction atomicity.
• Crash Recovery: Consistency is restored by replaying committed but uncheckpointed log entries.
8. Key Technologies for Building Reliable Systems
8.1 Atomic File Update Pattern
“`c
// Use renaming to achieve atomic file updates
int atomic_file_update(const char *filename, const void *data, size_t len)
{
char tmpname[PATH_MAX];
int fd, ret;
struct stat st;
mode_t mode = 0644;
// Get original file attributes (if it exists)
if (stat(filename, &st) == 0) {
// Preserve original file permissions and ownership
mode = st.st_mode;
}
// Create temporary file (on the same file system)
snprintf(tmpname, sizeof(tmpname), “%s.XXXXXX”, filename);
fd = mkstemp(tmpname);
if (fd < 0)
return -1;
}
// Set permissions and ownership
fchmod(fd, mode);
if (fstat(fd, &st) == 0) {
fchown(fd, st.st_uid, st.st_gid);
}
// Write data
ret = write(fd, data, len);
if (ret != len) {
close(fd);
unlink(tmpname);
return -1;
}
// Ensure data is flushed to disk
fsync(fd);
close(fd);
// Atomic replacement (requires on the same file system)
ret = rename(tmpname, filename);
if (ret < 0) {
unlink(tmpname);
return -1;
}
// Sync parent directory to ensure renaming is persistent
sync_parent_dir(filename);
return 0;
}
“`
Key Technology Explanation:
• Cross-File System Limitation: rename() requires the source and target to be on the same file system to guarantee atomicity.
• Ownership Preservation: Retains the UID/GID of the original file, maintaining security attributes.
• Persistence Guarantee: Directory synchronization ensures that directory entry updates are persistent.
8.2 Best Practices for Error Handling
1. Pre-validation: Validate all prerequisites before starting actual operations.
2. Resource Reservation: Pre-allocate all necessary resources to avoid failures during operations.
3. Ordered Locking: Acquire locks in a globally consistent order to prevent deadlocks.
4. Error Rollback: Restore to a consistent state when operations fail.
5. Persistence Confirmation: Call synchronization functions after critical operations to ensure data is flushed to disk.
Key Technology Explanation:
• Resource Leak Protection: Each allocation path should have a corresponding release path.
• State Machine Design: Operations are designed as a state machine, where each state can be safely aborted.
• Idempotency Considerations: Design operations so that repeated execution does not produce side effects (supporting reentrancy).
Technical Summary:
1. Evolution of Lock Mechanisms: From global locks to fine-grained inode locks, balancing concurrency performance and consistency.
2. Transaction Support: Log file systems ensure the atomicity of metadata operations through transactions.
3. Reference Integrity: Manage object lifecycles through reference counting and delayed releases.
4. Error Recovery: Comprehensive error handling paths ensure the system is always in a consistent state.
5. Performance Optimization: Techniques like read-optimized locks and delayed updates enhance concurrency performance.
Linux VFS provides powerful atomic operation guarantees for upper-level applications through carefully designed synchronization mechanisms and unified interface abstractions. A deep understanding of these mechanisms is crucial for building highly reliable systems.
In actual system development, one should:
• Choose file systems and mount options that match the workload (mount optimization options will be detailed in a subsequent article).
• Understand the levels of atomicity guarantees and limitations of different operations.
• Implement appropriate error handling and recovery strategies.
• Conduct thorough concurrency and failure testing (reliability will be detailed in a subsequent article).
The atomic operation mechanisms of VFS represent the culmination of decades of file system development wisdom, and these technologies are not only applicable to local file systems but also provide important insights for distributed storage and database systems.

Every view or like is a great encouragement; let’s grow together.