CMSIS_NN Overview
Paper Title: “CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs”, 2018
Organization: ARM
0. Introduction
CMSIS-NN is a neural network inference library for ARM Cortex-M series chips, designed for deploying neural networks on low-performance chips/architectures.
1. Convolution and Matrix Multiplication
Using the 16-bit multiply-accumulate SIMD instruction, SMLAD.
1.1 __SXTB16 Data Extension
Most NN functions use 16-bit MAC instructions, so before sending them into SIMD, 8-bit data needs to be extended to 16-bit. CMSIS_NN provides the function arm_q7_to_q15. The implementation involves two steps: 1. Use the signed extension instruction __SXTB16 to extend; 2. Rearrange the extended data. The data rearrangement is mainly caused by the __SXTB16 extension instruction, as shown in the figure:
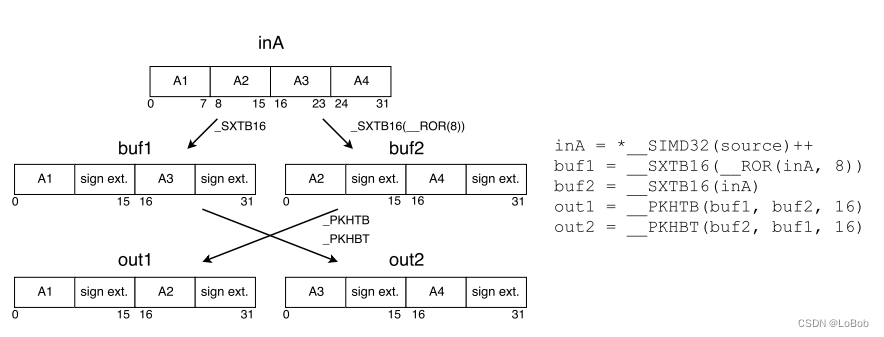
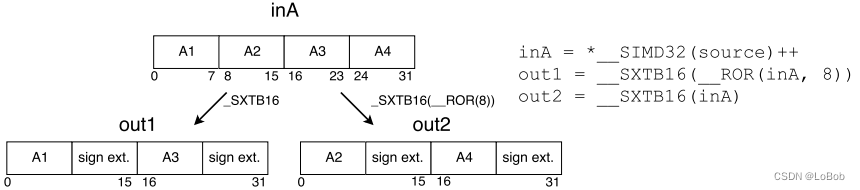
Extending to 16-bit is essential, but data rearrangement is not always necessary. Assuming we can ignore the rearrangement after extending to 16-bit, the process is as follows:
1.2 Matrix Multiplication
Matrix multiplication is divided into 2×2 blocks, allowing some data to be reused, thus reducing the load data instructions. The accumulator is of int32(q_31_t) data type, while both the addend and augend are of int32(q_15_t) data type. The accumulator is initialized with bias data, meaning the bias is added first, and the computation uses the SMLAD instruction.
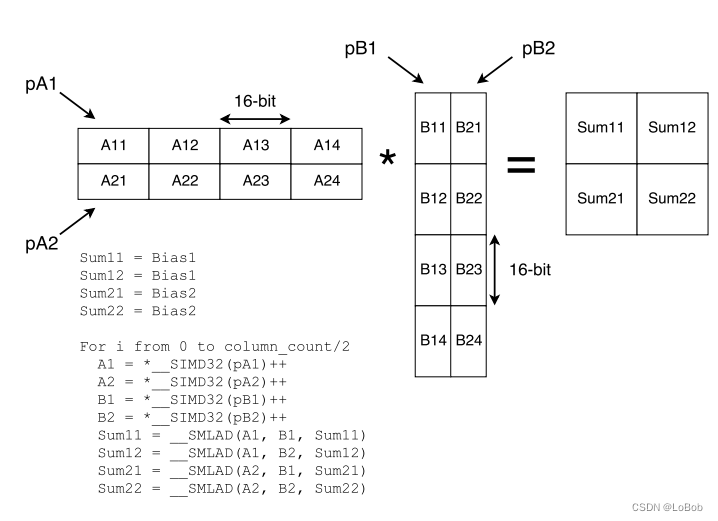
This figure clearly shows that for A×B, matrices A and B are divided into 2×2 blocks, and the specific operations are:
Accumulator: sum11/sum12/sum21/sum22
sum11 += A11×B11
sum12 += A11×B21
sum21 += A21×B11
sum22 += A21×B21
sum11 += A12×B12
sum12 += A12×B22
sum21 += A22×B12
sum22 += A22×B22
sum11 += A13×B13
sum12 += A13×B23
sum21 += A23×B13
sum22 += A23×B23
sum11 += A14×B14
sum12 += A14×B24
sum21 += A24×B14
sum22 += A24×B24
sum11 = A11×B11 + A12×B12 + A13×B13 + A14×B14 = (A11, A12, A13, A14)×(B11, B12, B13, B14).Transpose
sum12 = A11×B21 + A12×B22 + A13×B23 + A14×B24 = (A11, A12, A13, A14)×(B21, B22, B23, B24).Transpose
sum21 = A21×B11 + A22×B12 + A23×B13 + A24×B14 = (A21, A22, A23, A24)×(B11, B12, B13, B14).Transpose
sum22 = A21×B21 + A22×B22 + A23×B23 + A24×B24 = (A11, A12, A13, A14)×(B21, B22, B23, B24).Transpose
Assuming the input or network weights are of int8 data type, they need to be extended to int16; if both the input and network weights are int8, they also need to be extended to int16, but without data rearrangement; if the weights are int8 and the input is int16, the weights can be converted in advance, as shown in the figure:
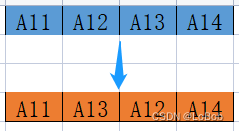
Then during the extension, the order will change, eliminating the need for rearrangement.
Regarding Dense/fully-connected, it is the matrix-vector multiplication, using a 1×2 method, which can be increased, such as 1×4, but this is limited by the number of registers. The ARM Cortex-M series has 16 registers.
Additionally, network weights can be rearranged in memory to reduce addressing and cache misses.
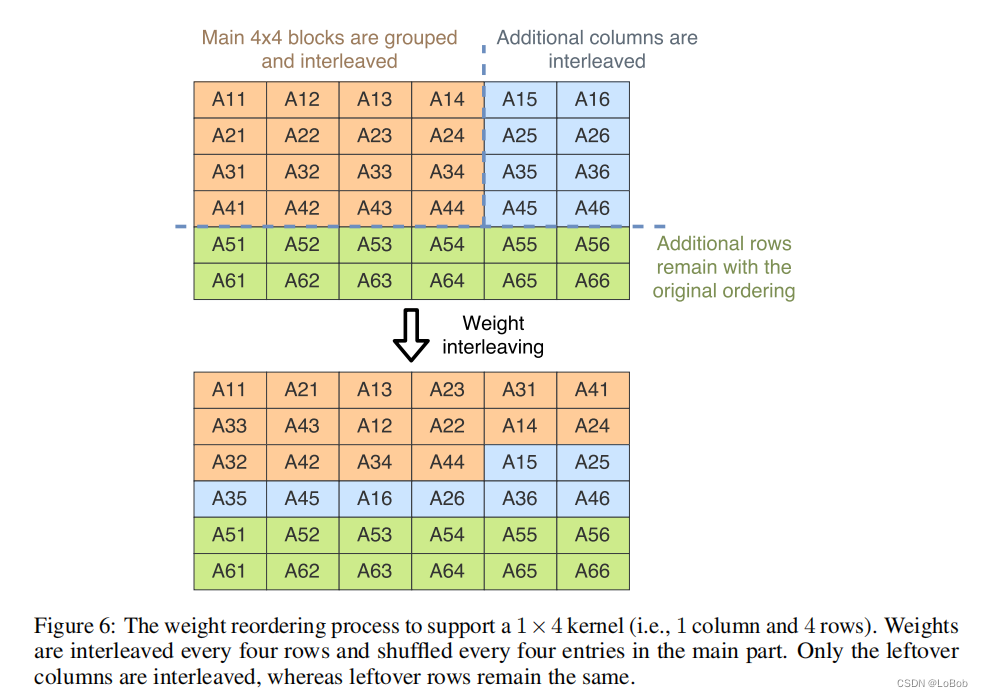
Based on the data extension instruction _SXTB16, as shown in Figure 6-1. I have illustrated the necessary rearrangements in the diagram (Figure 6-2).
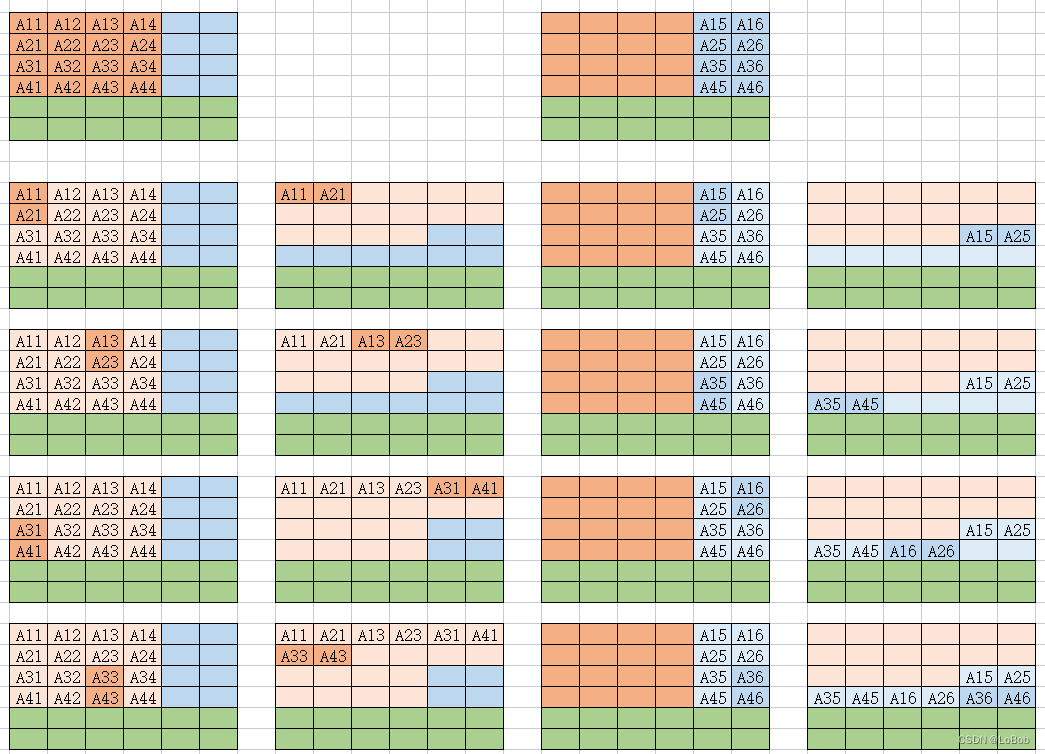
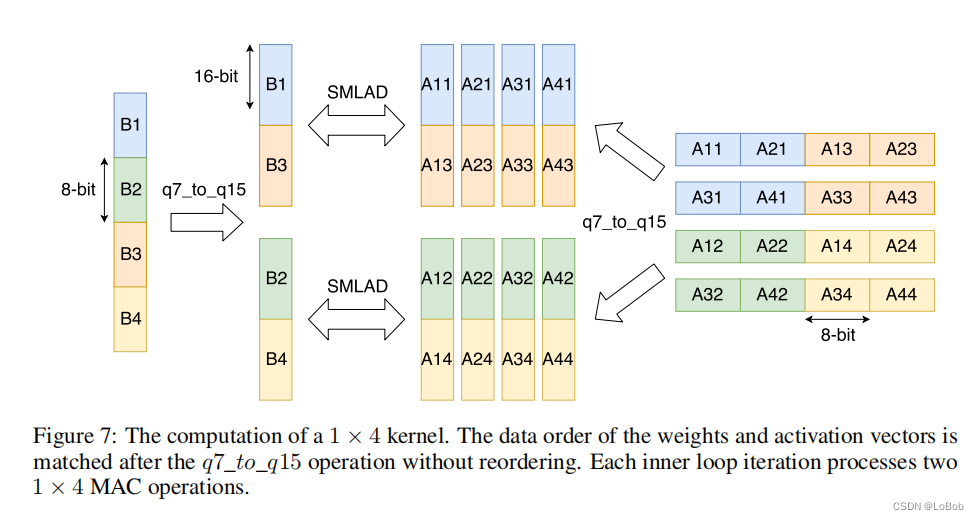
Figure 7 shows the 1×4 data extension. The order of the extended data is consistent with what was mentioned above.
1.3 Convolution
Partial im2col
Convolution first performs im2col, as shown in the figure. You can also check my previous article on Zhihu for further understanding of im2col – Zhihu (zhihu.com).
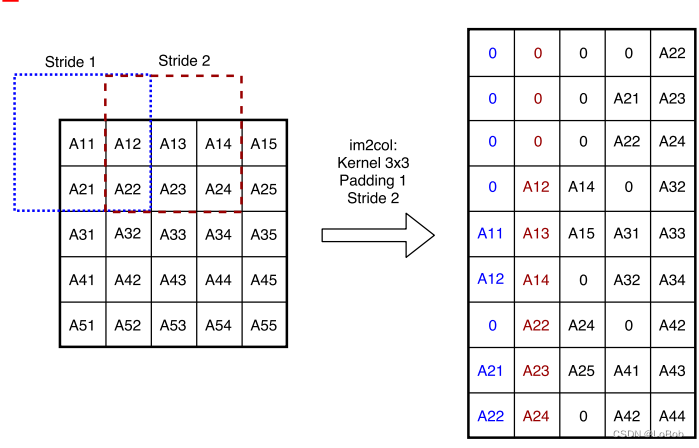
However, im2col uses space to exchange for time, which is limited in memory for the ARM Cortex-M series. As a trade-off, partial im2col is used, limiting the number of columns.
HWC Data Layout:
The analysis in the paper is somewhat redundant; the author conducted tests showing that HWC’s im2col is faster than CHW due to reduced addressing. But why are layouts like NCNN and MNN in NCHW, while CMSIS-NN uses NHWC? Is it because NCNN’s design is flawed? Not at all. My current understanding is that because Cortex-M series multiply-accumulate can only handle 4 numbers, i.e., res += a[0]×b[0] + a[1]×b[1] + a[2]×b[2] + a[3]×b[3], and the DSP vector computation for Cortex-M currently only supports int16×int16 multiplication (if anyone has information on int8×int8, please share). Therefore, CMSIS-NN must first extend int8 to int16 before performing multiplication. Additionally, my personal understanding of why int8×int8 matrix multiplication units are not provided is that the accumulation result of int8×int8 is in int32 data type, and the operation of “+=” can easily overflow with many accumulations, while int16×int16 accumulation exists in int64, significantly reducing the risk of overflow.
2. Pooling
Pooling has two implementation methods: Split x-y pooling and Window-based pooling.
2.1 Window-based Pooling
Window-based is a very intuitive implementation method, where a pooling window slides continuously. This method is what I first wrote about, and it is said that Caffe also uses this method. This method has average memory access due to the HWC layout, as pooling is done over HW, but it can also be parallelized along the C dimension, which can alleviate some memory access delays.
/**
* @brief Q7 max pooling function
* @param[in, out] Im_in pointer to input tensor
* @param[in] dim_im_in input tensor dimension
* @param[in] ch_im_in number of input tensor channels
* @param[in] dim_kernel filter kernel size
* @param[in] padding padding sizes
* @param[in] stride convolution stride
* @param[in] dim_im_out output tensor dimension
* @param[in,out] bufferA Not used
* @param[in,out] Im_out pointer to output tensor
*/
int16_t i_ch_in, i_x, i_y;
for (i_ch_in = 0; i_ch_in < ch_im_in; i_ch_in++){
for (i_y = 0; i_y < dim_im_out; i_y++) {
for (i_x = 0; i_x < dim_im_out; i_x++) {
int max = -129;
// The following two are a pooling window, e.g., 2×2
for (k_y = i_y * stride - padding; k_y < i_y * stride - padding + dim_kernel; k_y++) {
for (k_x = i_x * stride - padding; k_x < i_x * stride - padding + dim_kernel; k_x++) {
if (k_y >= 0 && k_x >= 0 && k_y < dim_im_in && k_x < dim_im_in) {
if (Im_in[i_ch_in + ch_im_in * (k_x + k_y * dim_im_in)] > max) {
max = Im_in[i_ch_in + ch_im_in * (k_x + k_y * dim_im_in)];
}
}
}
}
Im_out[i_ch_in + ch_im_in * (i_x + i_y * dim_im_out)] = max;
}
}
}
2.2 Split x-y Pooling
CMSIS-NN uses this method. I couldn’t understand it from the paper and had to look at the code to understand it.
In simple terms, this method compares pooling by taking a set of C dimension data at a time, directly comparing the data in the C dimension and storing the comparison results in the output matrix. Another key point is that comparisons are first made in the x direction, then in the y direction. The benefit of this approach is that the C dimension values are continuous, allowing for vectorization.
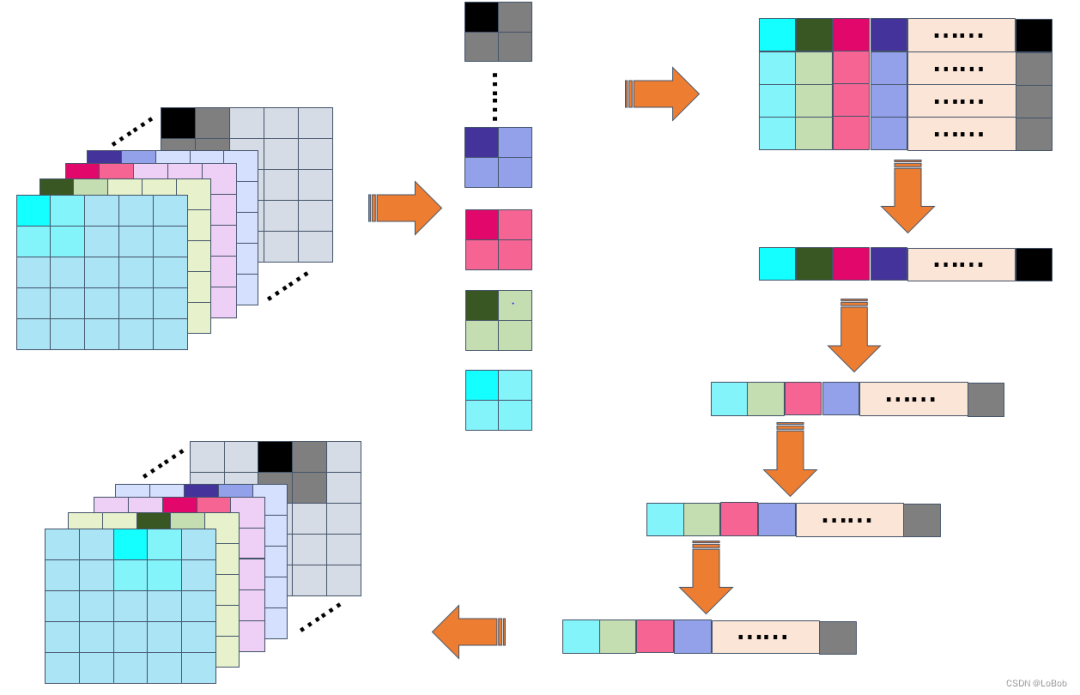
Looking at the figure, assuming H=5, W=5, Pool=(2,2), pool stride=2. The layout is NHWC, i.e., the C channel is continuous in memory, so: 1. Take C numbers at once for processing (Max/Average), directly memory or load data using vectorization; 2. Compare 4 numbers together, allowing for vectorized processing, i.e., obtaining 4 comparison results in one cycle; 3. Continue comparing the next set, Pool=(2,2), resulting in a total of 4 comparisons, each time in groups of C numbers.
The question arises: how is it reflected that x-pooling is done first, then y-pooling? The function arm_max_pool_s8 actually performs 2 x-direction pools first, then 2 y-direction pools. CMSIS-NN also has the arm_maxpool_q7_HWC implementation, which first performs the entire HW’s x-direction pool, then the entire HW’s y-direction pool. I understood this function, but I found that TensorFlow Lite Micro did not use this function, so I won’t illustrate it further. There is a slight difference.
// TensorFlow Lite Micro's max pool
TfLiteStatus MaxEvalInt8(TfLiteContext* context, const TfLiteNode* node,
const TfLitePoolParams* params, const OpData& data,
const TfLiteEvalTensor* input,
TfLiteEvalTensor* output) {
RuntimeShape input_shape = micro::GetTensorShape(input);
RuntimeShape output_shape = micro::GetTensorShape(output);
const int depth = MatchingDim(input_shape, 3, output_shape, 3);
cmsis_nn_dims input_dims;
input_dims.n = 1;
input_dims.h = input_shape.Dims(1);
input_dims.w = input_shape.Dims(2);
input_dims.c = depth;
cmsis_nn_dims output_dims;
output_dims.n = 1;
output_dims.h = output_shape.Dims(1);
output_dims.w = output_shape.Dims(2);
output_dims.c = depth;
cmsis_nn_pool_params pool_params;
pool_params.stride.h = params->stride_height;
pool_params.stride.w = params->stride_width;
pool_params.padding.h = data.reference_op_data.padding.height;
pool_params.padding.w = data.reference_op_data.padding.width;
pool_params.activation.min = data.reference_op_data.activation_min;
pool_params.activation.max = data.reference_op_data.activation_max;
cmsis_nn_dims filter_dims;
filter_dims.n = 1;
filter_dims.h = params->filter_height;
filter_dims.w = params->filter_width;
filter_dims.c = 1;
cmsis_nn_context ctx;
ctx.buf = nullptr;
ctx.size = 0;
if (data.buffer_idx > -1) {
ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
}
TFLITE_DCHECK_EQ(
arm_max_pool_s8(&ctx, &pool_params, &input_dims,
micro::GetTensorData<int8_t>(input), &filter_dims,
&output_dims, micro::GetTensorData<int8_t>(output)),
ARM_CMSIS_NN_SUCCESS);
return kTfLiteOk;
}
For example, let’s illustrate MaxPooling:
CMSIS-NN has two implementations in
CMSIS\
Source\
PoolingFunctions\arm_max_pool_s8.cCMSIS\NN\Source\PoolingFunctions\arm_pool_q7_HWC.c.
First, let’s analyze arm_max_pool_s8.c.
arm_cmsis_nn_status arm_max_pool_s8(const cmsis_nn_context *ctx,
const cmsis_nn_pool_params *pool_params,
const cmsis_nn_dims *input_dims,
const q7_t *src,
const cmsis_nn_dims *filter_dims,
const cmsis_nn_dims *output_dims,
q7_t *dst)
{
const int32_t input_y = input_dims->h;
const int32_t input_x = input_dims->w;
const int32_t output_y = output_dims->h;
const int32_t output_x = output_dims->w;
const int32_t stride_y = pool_params->stride.h;
const int32_t stride_x = pool_params->stride.w;
const int32_t kernel_y = filter_dims->h;
const int32_t kernel_x = filter_dims->w;
const int32_t pad_y = pool_params->padding.h;
const int32_t pad_x = pool_params->padding.w;
const int32_t act_min = pool_params->activation.min;
const int32_t act_max = pool_params->activation.max;
const int32_t channel_in = input_dims->c;
(void)ctx;
q7_t *dst_base = dst;
for (int i_y = 0, base_idx_y = -pad_y; i_y < output_y; base_idx_y += stride_y, i_y++){// H dimension
for (int i_x = 0, base_idx_x = -pad_x; i_x < output_x; base_idx_x += stride_x, i_x++) {// W dimension
/* Condition for kernel start dimension: (base_idx_<x,y> + kernel_<x,y>_start) >= 0 */
const int32_t ker_y_start = MAX(0, -base_idx_y);
/* Condition for kernel end dimension: (base_idx_<x,y> + kernel_<x,y>_end) < dim_src_<width,height> */
const int32_t kernel_y_end = MIN(kernel_y, input_y - base_idx_y);
const int32_t kernel_x_end = MIN(kernel_x, input_x - base_idx_x);
int count = 0;
for (int k_y = ker_y_start; k_y < kernel_y_end; k_y++){// This part compares a pool, each time a group of C dimension data is sent in for comparison
for (int k_x = ker_x_start; k_x < kernel_x_end; k_x++){
const q7_t *start = src + channel_in * (k_x + base_idx_x + (k_y + base_idx_y) * input_x);
if (count == 0){
arm_memcpy_q7(dst, start, channel_in);
count++;
}else{
compare_and_replace_if_larger_q7(dst, start, channel_in);
}
}
}
/* 'count' is expected to be non-zero here. */
dst += channel_in;
}
}
clamp_output(dst_base, output_x * output_y * channel_in, act_min, act_max);// This is for clamping
return ARM_CMSIS_NN_SUCCESS;
}
__STATIC_FORCEINLINE void arm_memcpy_q7(q7_t *__RESTRICT dst, const q7_t *__RESTRICT src, uint32_t block_size)
{
memcpy(dst, src, block_size);
}
static void clamp_output(q7_t *source, int32_t length, const int32_t act_min, const int32_t act_max){
union arm_nnword in;
int32_t cnt = length >> 2;
while (cnt > 0l){
in.word = arm_nn_read_q7x4(source);
in.bytes[0] = MAX(in.bytes[0], act_min);
in.bytes[0] = MIN(in.bytes[0], act_max);
in.bytes[1] = MAX(in.bytes[1], act_min);
in.bytes[1] = MIN(in.bytes[1], act_max);
in.bytes[2] = MAX(in.bytes[2], act_min);
in.bytes[2] = MIN(in.bytes[2], act_max);
in.bytes[3] = MAX(in.bytes[3], act_min);
in.bytes[3] = MIN(in.bytes[3], act_max);
arm_nn_write_q7x4_ia(&source, in.word);
cnt--;
}
cnt = length & 0x3;
while (cnt > 0l)
{
int32_t comp = *source;
comp = MAX(comp, act_min);
comp = MIN(comp, act_max);
*source++ = (int8_t)comp;
cnt--;
}
}
Among them:
if (count == 0){
arm_memcpy_q7(dst, start, channel_in);
count++;
}
arm_memcpy_q7 encapsulates memcpy(dst, src, block_size), which means that within a pooling window, I only take one group of numbers in place, whose length is the input/output channel. After taking the numbers, I compare them using compare_and_replace_if_larger_q7(dst, start, channel_in). I have explained my understanding in the comments.
static void compare_and_replace_if_larger_q7(q7_t *base, const q7_t *target, int32_t length)
{
q7_t *dst = base;
const q7_t *src = target;
union arm_nnword ref_max;
union arm_nnword comp_max;
int32_t cnt = length >> 2; // Since each time 4 numbers are processed, directly left shift by 2
while (cnt > 0l) // 0L long, cnt is length/4's integer part
{
ref_max.word = arm_nn_read_q7x4(dst);
comp_max.word = arm_nn_read_q7x4_ia(&src);
if (comp_max.bytes[0] > ref_max.bytes[0]) ref_max.bytes[0] = comp_max.bytes[0];
if (comp_max.bytes[1] > ref_max.bytes[1]) ref_max.bytes[1] = comp_max.bytes[1];
if (comp_max.bytes[2] > ref_max.bytes[2]) ref_max.bytes[2] = comp_max.bytes[2];
if (comp_max.bytes[3] > ref_max.bytes[3]) ref_max.bytes[3] = comp_max.bytes[3];
arm_nn_write_q7x4_ia(&dst, ref_max.word);// After comparison, overwrite the memory location of the data taken by arm_memcpy_q7, which is an in-place operation, saving memory
cnt--;
}
cnt = length & 0x3; // 0x3 means 0011, which is length%4, processing the tail
while (cnt > 0l)
{
if (*src > *dst){
*dst = *src;
}
dst++; src++; cnt--;
}
}
3 Activation Functions
3.1 Relu
The simplest approach is to iterate through the data, setting values less than 0 to 0.
void arm_relu_q7(q7_t *data, uint16_t size){
/* Run the following code as reference implementation for cores without DSP extension */
uint16_t i;
for (i = 0; i < size; i++){
if (data[i] < 0)
data[i] = 0;
}
}
To enable vectorization, bitwise operations are used for Relu.
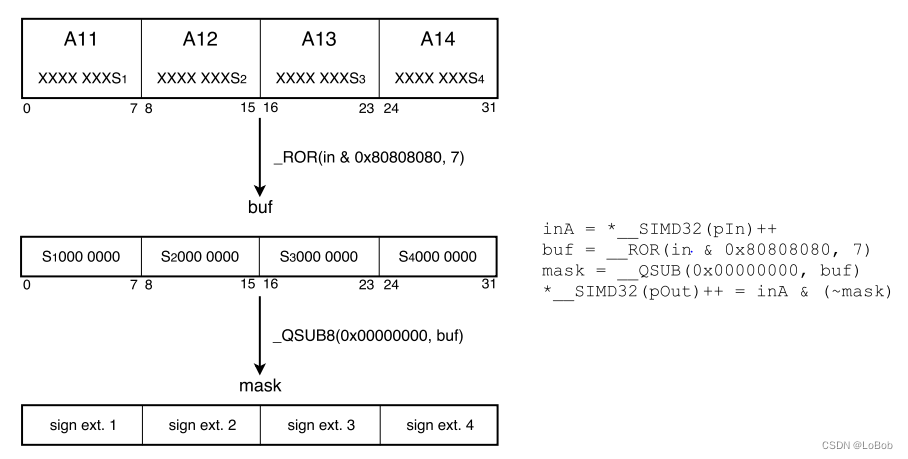
Steps:
1. Extract the highest bit of 4 numbers, i.e., the sign bit, so every number is ANDed with 0x80, then right-shifted by 7 bits, denoted as buf. 2. If the highest bit is 1, it indicates that the number is negative and should be masked to 0, using mask = 0 minus buf, assuming it’s negative, then mask will equal -1, i.e., 0xFF; if it’s positive, then mask = 0, i.e., 0x00; 3. Invert the mask, ~(0xFF) = 0x00, ~(0x00)=0xFF, so if the number is negative, the result will be 0, and if it’s positive, the value remains unchanged.
void arm_relu_q7(q7_t *data, uint16_t size) {
/* Run the following code for M cores with DSP extension */
uint16_t i = size >> 2;
q7_t *input = data;
q7_t *output = data;
q31_t in;
q31_t buf;
q31_t mask;
while (i)
{
in = arm_nn_read_q7x4_ia((const q7_t **)&input);
/* extract the first bit */
buf = (int32_t)__ROR((uint32_t)in & 0x80808080, 7);
/* if MSB=1, mask will be 0xFF, 0x0 otherwise */
mask = __QSUB8(0x00000000, buf);
arm_nn_write_q7x4_ia(&output, in & (~mask));
i--;
}
i = size & 0x3;
while (i) {
if (*input < 0) {
*input = 0;
}
input++; i--;
}
}
3.2 Sigmoid/Tanh
For these two activation functions, a lookup table approach is adopted, which is common, so I will skip it here.
4 Experiments and Results
Actually, CMSIS-NN is a work from 0 to 1. I dare not say it is pioneering because Caffe/TFLite may be the ancestors, but when ARM officially provided a feasible method based on the instruction situation of the Cortex-M series low-performance architecture/processor and open-sourced it, it is commendable. Regardless, it also benefits their market expansion. Open-source is commendable!!
Let’s look at the results:
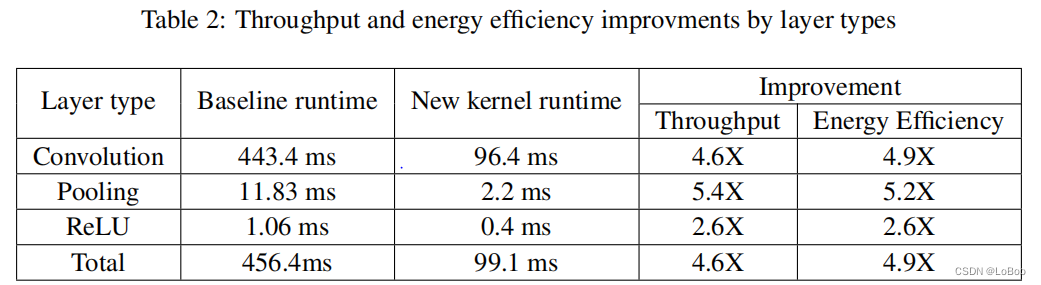
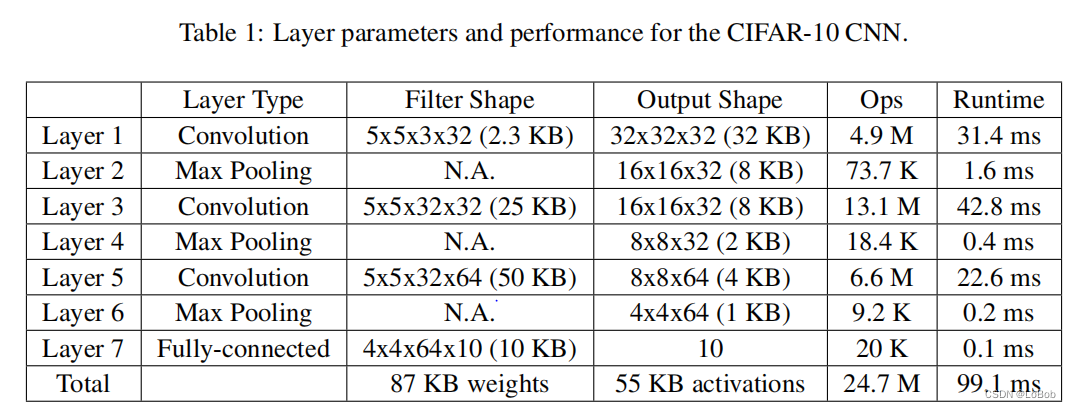
Finally, I summarized the optimization of conv, pool, and relu by CMSIS-NN:
| Layer | Speed Up |
|---|---|
| Convolution | - |
| Pool | 4.5X |
| Relu | 4X |