Click belowCard to follow “Machine Vision and AI Deep Learning“
Visual/Image processing insights delivered promptly!
 This project is named SPEED-SAM-C++-TENSORRT, a high-performance implementation of the Segment Anything Model (SAM), utilizing NVIDIA’s TensorRT for efficient inference and optimizing GPU utilization with CUDA. Below is a detailed introduction to how this implementation works, how to compile it, and its key components.
This project is named SPEED-SAM-C++-TENSORRT, a high-performance implementation of the Segment Anything Model (SAM), utilizing NVIDIA’s TensorRT for efficient inference and optimizing GPU utilization with CUDA. Below is a detailed introduction to how this implementation works, how to compile it, and its key components.
https://github.com/hamdiboukamcha/SPEED-SAM-C-TENSORRT Project Structure and Overview The directory structure of the project is as follows:
Project Structure and Overview The directory structure of the project is as follows: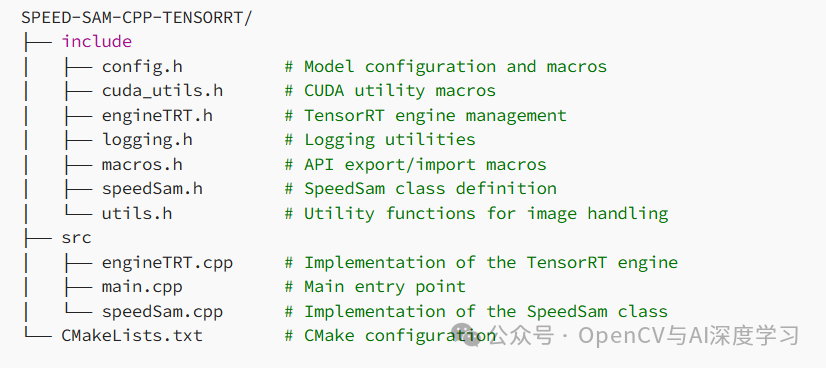 This project is designed for fast image segmentation tasks, allowing segmentation of images based on selected points or bounding boxes. It uses TensorRT to build an optimized inference engine from ONNX models, enabling efficient deep learning inference on NVIDIA GPUs.Key Component Descriptions Building the TensorRT Engine: The EngineTRT::build() method parses the ONNX model and builds the TensorRT engine. If dynamic shape support is needed (for different input sizes), the optimization profile is configured accordingly. The EngineTRT::saveEngine() function allows the serialized engine to be saved to a file for quick loading in future sessions. Image Segmentation Process: The SpeedSam class is responsible for coordinating the segmentation process. First, the image is encoded using a pre-trained encoder model. Next, the decoder model generates masks based on the input points or bounding boxes. Two main segmentation methods are provided: Point-based segmentation (segmentWithPoint): The user clicks on the image to specify the point to segment. Bounding box segmentation (segmentBbox): The user draws a bounding box to define the segmentation area. Memory Optimization: This implementation uses CUDA streams to overlap data transfer and computation, thereby reducing latency. FP16 precision is used whenever possible to accelerate inference without significantly sacrificing accuracy.Compilation and Setup Prerequisites: CUDA: NVIDIA’s parallel computing platform. TensorRT: A library for high-performance deep learning inference. OpenCV: For image processing. C++17: Required for compilation. Compilation Steps: Clone the repository and navigate to the project directory:
This project is designed for fast image segmentation tasks, allowing segmentation of images based on selected points or bounding boxes. It uses TensorRT to build an optimized inference engine from ONNX models, enabling efficient deep learning inference on NVIDIA GPUs.Key Component Descriptions Building the TensorRT Engine: The EngineTRT::build() method parses the ONNX model and builds the TensorRT engine. If dynamic shape support is needed (for different input sizes), the optimization profile is configured accordingly. The EngineTRT::saveEngine() function allows the serialized engine to be saved to a file for quick loading in future sessions. Image Segmentation Process: The SpeedSam class is responsible for coordinating the segmentation process. First, the image is encoded using a pre-trained encoder model. Next, the decoder model generates masks based on the input points or bounding boxes. Two main segmentation methods are provided: Point-based segmentation (segmentWithPoint): The user clicks on the image to specify the point to segment. Bounding box segmentation (segmentBbox): The user draws a bounding box to define the segmentation area. Memory Optimization: This implementation uses CUDA streams to overlap data transfer and computation, thereby reducing latency. FP16 precision is used whenever possible to accelerate inference without significantly sacrificing accuracy.Compilation and Setup Prerequisites: CUDA: NVIDIA’s parallel computing platform. TensorRT: A library for high-performance deep learning inference. OpenCV: For image processing. C++17: Required for compilation. Compilation Steps: Clone the repository and navigate to the project directory:
git clone https://github.com/hamdiboukamcha/SPEED-SAM-C-TENSORRT.git cd SPEED-SAM-CPP-TENSORRTCreate a build directory and compile using CMake:
mkdir build && cd buildcmake ..make -j$(nproc)Note: Update the CMakeLists.txt with the correct paths for TensorRT and OpenCV if necessary.
Running the Application
 Point-based Segmentation: The program displays the image and waits for the user to select a point. Once a point is selected, the model segments the image based on the specified location and overlays the mask. Bounding Box Segmentation: The user can draw a bounding box around the desired area. The model then segments the image within the defined area and displays the results. Output: The segmented image is saved to the specified output path, and performance metrics such as inference time are logged.Performance and Optimization
Point-based Segmentation: The program displays the image and waits for the user to select a point. Once a point is selected, the model segments the image based on the specified location and overlays the mask. Bounding Box Segmentation: The user can draw a bounding box around the desired area. The model then segments the image within the defined area and displays the results. Output: The segmented image is saved to the specified output path, and performance metrics such as inference time are logged.Performance and Optimization
- Inference Speed: The image encoder and mask decoder achieve fast inference times, completing the entire pipeline in approximately 12 milliseconds.
- Memory Management: Efficient use of GPU memory and CUDA streams minimizes latency and maximizes throughput.
- Precision Settings: Options using FP16 precision allow for trade-offs between speed and accuracy.
Conclusion The SPEED-SAM-C++-TENSORRT project demonstrates the optimized implementation of the Segment Anything model using TensorRT and CUDA. By leveraging NVIDIA’s powerful libraries, this project achieves real-time segmentation performance, making it suitable for applications requiring fast and accurate image analysis. The flexible code structure and comprehensive logging also make it a valuable resource for developers performing deep learning inference on GPUs.