Reflecting on a long-overdue blog post about “High-Performance Network Programming in Linux,” I spent the weekend coding to organize this article that implements 22 high-concurrency models using C++11.
GitHub code repository: https://github.com/linkxzhou/mylib/tree/master/c%2B%2B/concurrency_server
concurrency_server/
├── base/ # Base component directory
│ └── server_base.h # Base class for the server, providing common socket operations
├── benchmark/ # Performance testing tools directory
├── main.cpp # Main program entry, supports switching between various server models
├── Makefile # Compilation configuration file
├── README.md # Project documentation
│
├── Basic Concurrency Models
├── single_process_server.h # Single-process model - serial processing, suitable for learning
├── multi_thread_server.h # Multi-threaded model - one thread per connection
├── multi_process_server.h # Multi-process model - one process per connection
├── thread_pool_server.h # Thread pool model - fixed number of worker threads
├── process_pool1_server.h # Process pool model 1 - pre-created process pool
├── process_pool2_server.h # Process pool model 2 - improved process pool implementation
│
├── I/O Multiplexing Models
├── select_server.h # Select model - cross-platform I/O multiplexing
├── poll_server.h # Poll model - improved select implementation
├── epoll_server.h # Epoll model - high-performance I/O multiplexing in Linux
├── kqueue_server.h # Kqueue model - high-performance I/O multiplexing in BSD/macOS
│
├── Advanced Concurrency Architectures
├── reactor_server.h # Reactor pattern - event-driven architecture
├── proactor_server.h # Proactor pattern - asynchronous I/O architecture
├── event_loop_server.h # Event loop model - single-threaded event-driven
├── half_sync_async_server.h # Half-synchronous half-asynchronous model - layered processing
├── leader_follower_server.h # Leader-Follower model - dynamic role switching
├── producer_consumer_server.h # Producer-Consumer model - decoupled processing
├── pipeline_server.h # Pipeline model - assembly line processing
├── work_stealing_server.h # Work stealing model - load balancing
├── hybrid_server.h # Hybrid model - combination of various technologies
│
├── Modern Concurrency Technologies
├── coroutine_server.h # Coroutine model - user-space lightweight threads
├── fiber_server.h # Fiber model - cooperative multitasking
├── actor_server.h # Actor model - message-passing concurrency1. SingleProcess (Single-Process Model)
- File:
<span>single_process_server.h</span> - Characteristics: Serial processing of client requests, simple but limited performance
- Applicable Scenarios: Learning and debugging, low-concurrency scenarios
- Advantages: Simple implementation, low resource consumption
- Disadvantages: Cannot utilize multi-core, one blocking request affects all subsequent requests
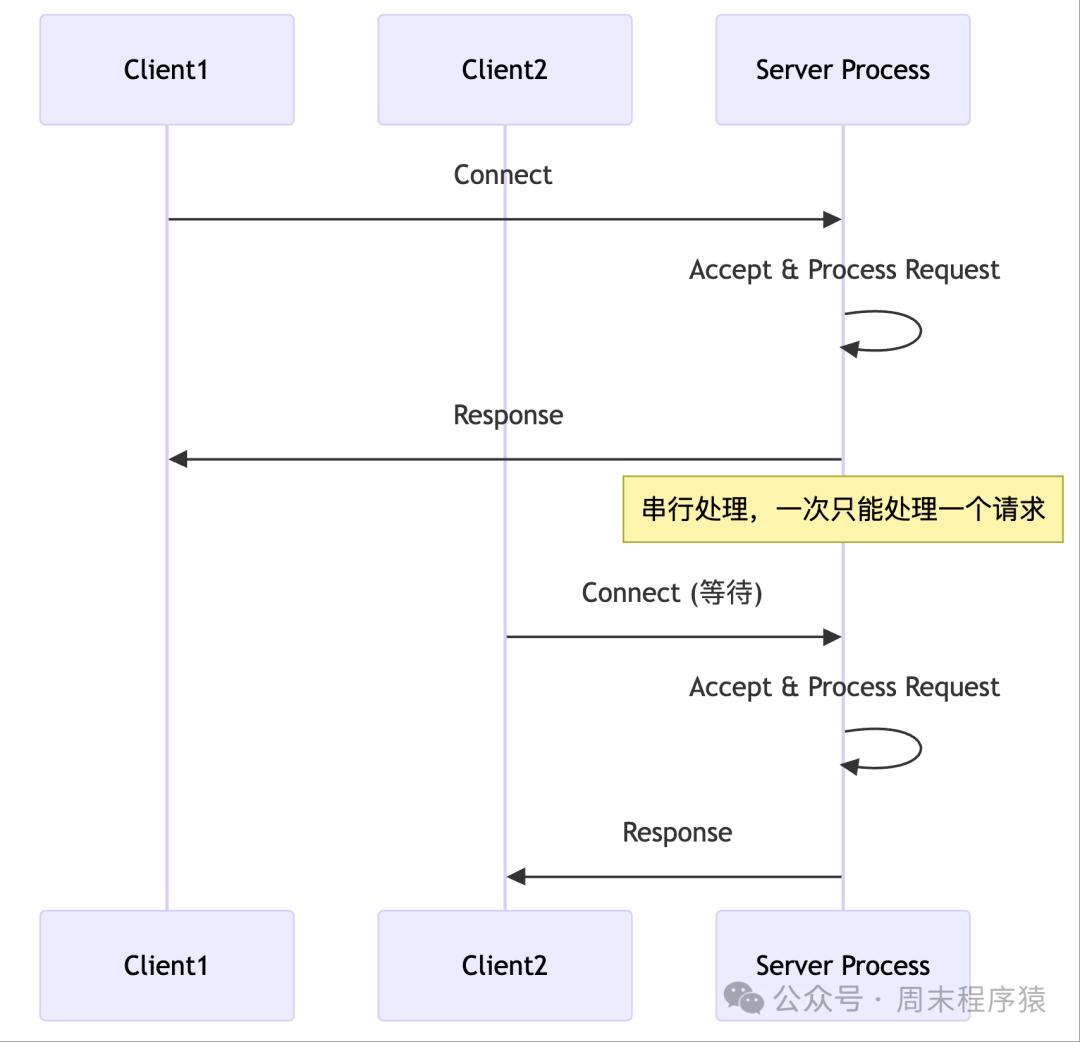
Detailed Introduction: The single-process model is the simplest server architecture, using traditional blocking I/O to handle client requests. The server runs in a single process, using a main loop to process each client connection sequentially. When a new connection arrives, the server calls accept() to accept the connection, then synchronously reads client data, processes the request, and sends a response. The entire process is serial, handling only one client at a time.
Implementation Architecture:
- The core implementation is based on traditional socket programming patterns.
- The server creates a listening socket and binds it to a specified port, then enters an infinite loop waiting for connections.
- Whenever accept() returns a new client socket, the server immediately processes all I/O operations for that connection, including reading HTTP requests, parsing protocols, generating responses, and sending data.
- Due to the use of blocking I/O, each operation waits to complete before proceeding to the next step.
2. MultiProcess (Multi-Process Model)
- File:
<span>multi_process_server.h</span> - Characteristics: Creates an independent process for each client connection
- Applicable Scenarios: Scenarios requiring process isolation
- Advantages: Process isolation, one process crash does not affect others
- Disadvantages: High overhead for process creation, high memory consumption
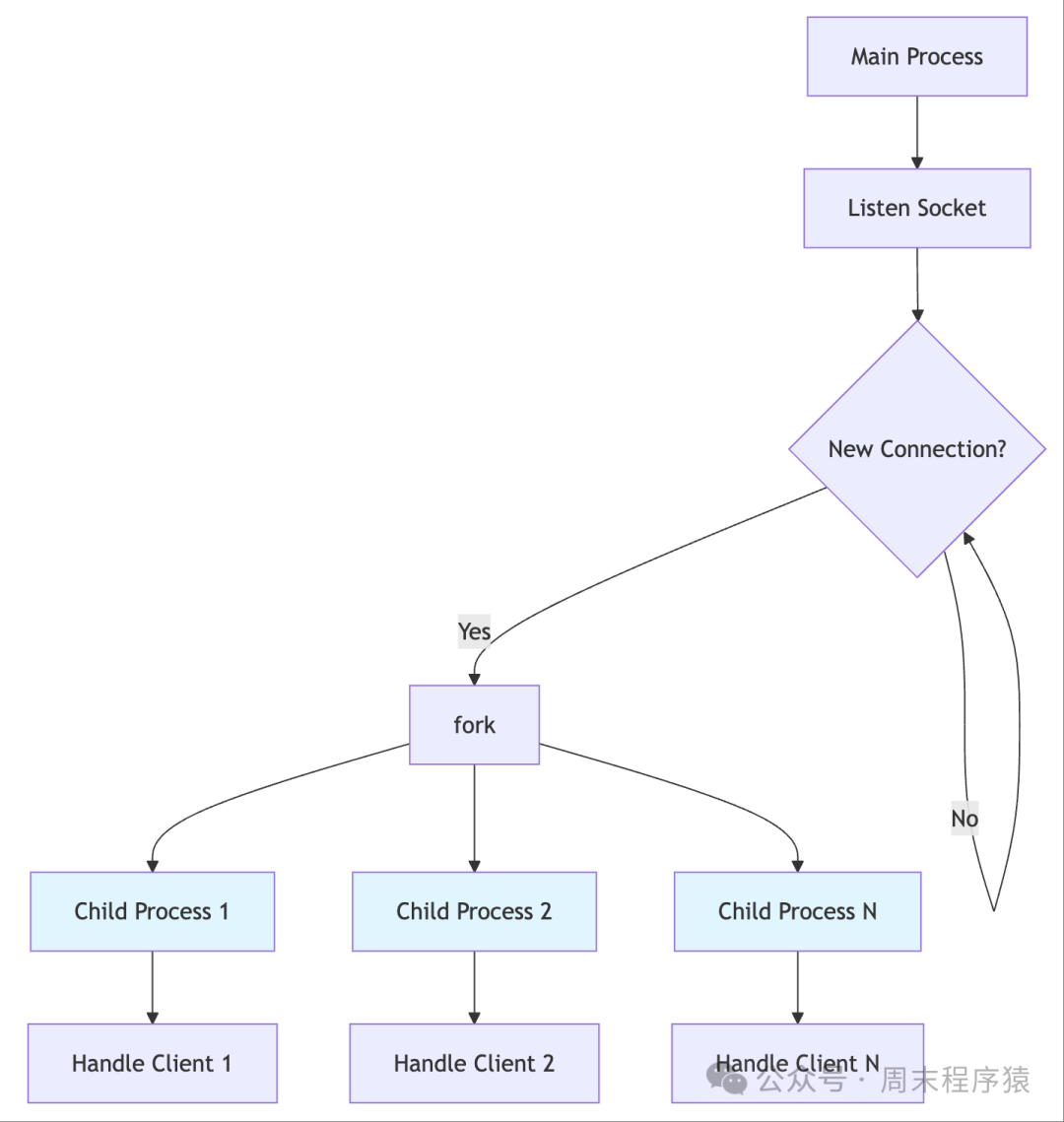
Detailed Introduction: The multi-process model achieves concurrent processing by creating independent child processes for each client connection. The main process is responsible for listening for new connections, and when accept() receives a new client, it immediately calls fork() to create a child process to handle that connection, while the main process continues to listen for the next connection. Each child process has its own memory space and resources, allowing for parallel processing of different client requests. This model provides the strongest isolation; a crash in one process does not affect other processes or the main server.
Implementation Architecture:
- The architecture adopts the classic fork-per-connection model.
- The main process creates a listening socket and enters an accept loop, immediately forking a child process each time a new connection is accepted.
- The child process closes the listening socket and exclusively handles the assigned client connection, exiting after completing all I/O operations.
- The main process closes the client socket, continues to listen for new connections, and recycles zombie processes through signal handling or waitpid().
3. MultiThread (Multi-Threaded Model)
- File:
<span>multi_thread_server.h</span> - Characteristics: Creates a new thread for each client connection
- Applicable Scenarios: Medium concurrency scenarios
- Advantages: Thread creation is faster than process creation, shared memory space
- Disadvantages: Too many threads when there are many connections, high context-switching overhead
Detailed Introduction: The multi-threaded model achieves concurrent processing by creating independent threads for each client connection. The main thread is responsible for listening and accepting new connections, and when a new client connects, it creates a worker thread to handle all I/O operations for that connection. All threads share the same process memory space, making it easy to share data and resources. Compared to the multi-process model, thread creation and switching overhead is smaller, and memory usage is more efficient. However, special attention must be paid to thread safety issues to avoid race conditions and data competition.
Implementation Architecture:
- The architecture is based on the thread-per-connection model.
- The main thread creates a listening socket and enters an accept loop, calling pthread_create() or std::thread to create a worker thread for each new connection accepted.
- The worker thread receives the client socket descriptor as a parameter, independently handling the read and write operations for that connection, and automatically exits after completion.
- To avoid thread leaks, detached threads or joining in the main thread are typically used.
- Shared resources (such as logs, statistics) need to be protected using mutexes.

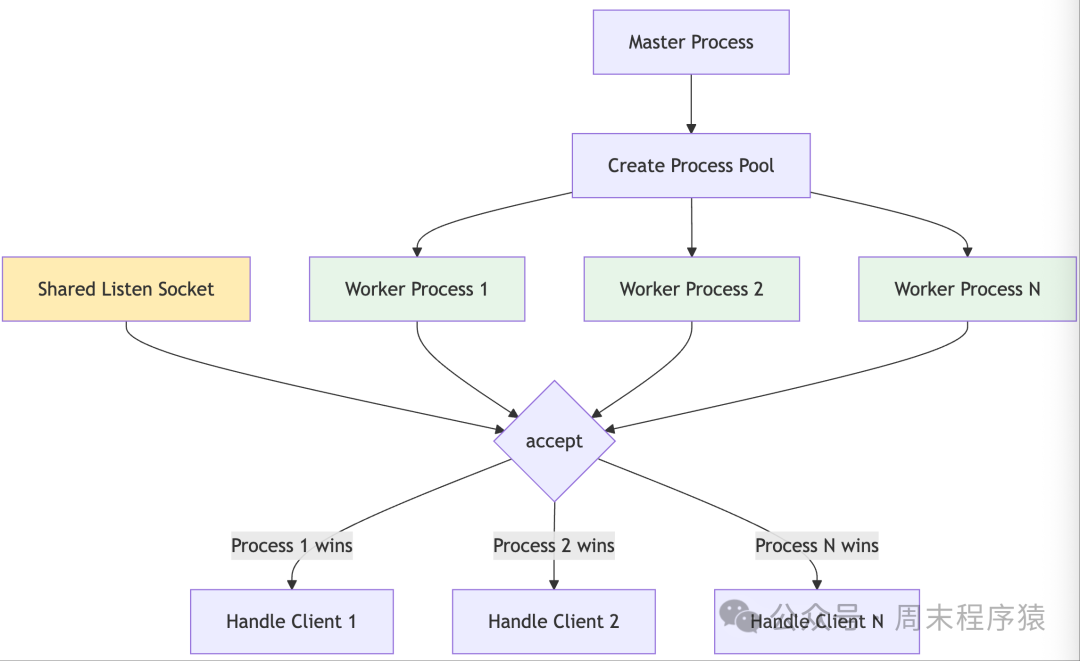
4. ProcessPool1 (Process Pool Model 1)
- File:
<span>process_pool1_server.h</span> - Characteristics: Pre-creates a fixed number of worker processes, sharing the listening socket
- Applicable Scenarios: High concurrency scenarios requiring process isolation
- Advantages: Avoids frequent process creation, high resource utilization
- Disadvantages: Process competition for accept may be uneven
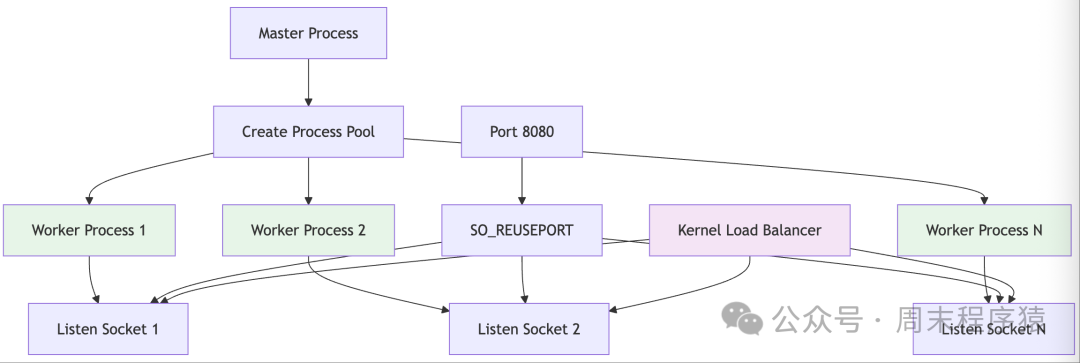
5. ProcessPool2 (Process Pool Model 2 – SO_REUSEPORT)
- File:
<span>process_pool2_server.h</span> - Characteristics: Uses the SO_REUSEPORT option, each process independently listens on the same port
- Applicable Scenarios: High concurrency scenarios in Linux environments
- Advantages: Kernel load balancing, avoids the thundering herd effect
- Disadvantages: Dependent on operating system features, limited portability
6. ThreadPool (Thread Pool Model)
- File:
<span>thread_pool_server.h</span> - Characteristics: Pre-creates a fixed number of worker threads
- Applicable Scenarios: High concurrency web servers
- Advantages: Avoids frequent thread creation, high resource utilization
- Disadvantages: Fixed number of threads, may not adapt to load changes
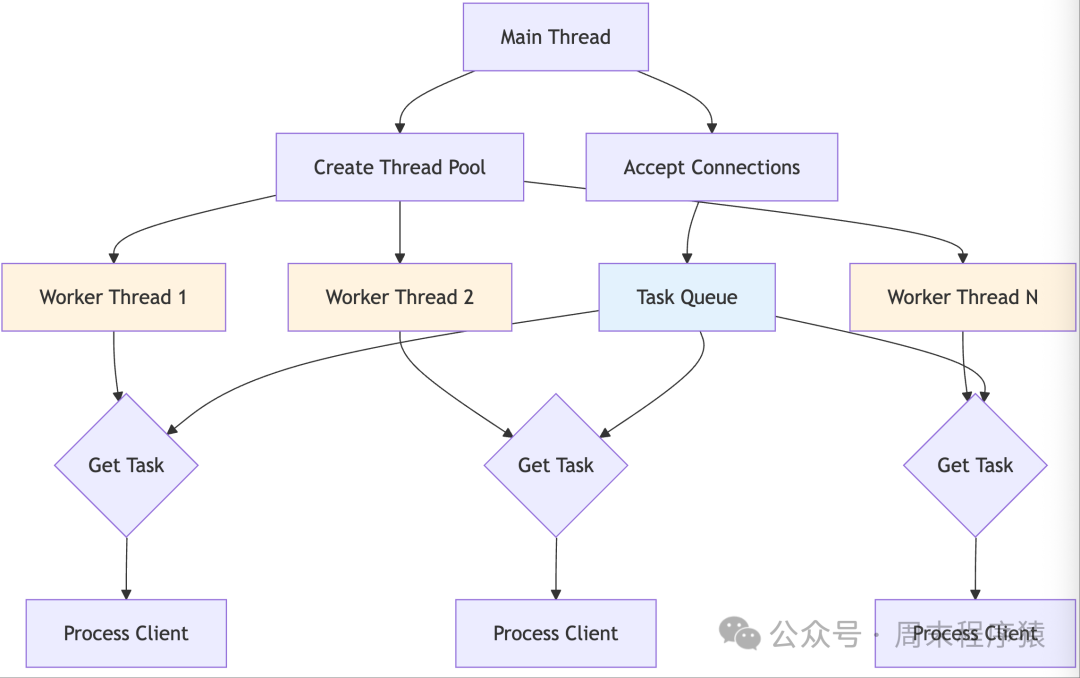
Detailed Introduction: The thread pool model processes client requests by pre-creating a fixed number of worker threads, avoiding the overhead of dynamically creating threads for each connection. The main thread is responsible for accepting new connections and placing them into a task queue, while worker threads take tasks from the queue for processing. This model effectively controls system resource usage, preventing an unlimited increase in the number of threads that could lead to system crashes. The size of the thread pool is usually set based on the number of CPU cores and expected load, achieving better resource management and performance optimization.
Implementation Architecture:
- The architecture adopts a producer-consumer model.
- At system startup, a specified number of worker threads are pre-created, waiting on the task queue.
- The main thread accepts new connections and encapsulates the client socket into a task object, placing it into a thread-safe task queue.
- Worker threads wait for tasks using condition variables, processing the complete client interaction flow once a task is received. The task queue is typically implemented using mutexes and condition variables for synchronization.
- After processing a task, the worker thread rejoins the thread pool, waiting for the next task.
7. LeaderAndFollower (Leader-Follower Model)
- File:
<span>leader_follower_server.h</span> - Characteristics: A variant of the thread pool, one thread acts as the leader listening for connections
- Applicable Scenarios: Scenarios requiring precise control over thread behavior
- Advantages: Reduces competition between threads, improves cache locality
- Disadvantages: Complex implementation, difficult to debug
Detailed Introduction: The leader-follower model is a high-performance concurrency pattern that optimizes thread utilization through dynamic role switching. At any moment, only one thread acts as the leader, responsible for listening and accepting new connections or events, while other threads remain in a follower state waiting to be activated. When the leader receives an event, it demotes itself to a follower to handle that event, while electing a new leader from the followers to continue listening. This model avoids the scheduling overhead of traditional thread pool models, reduces competition between threads, and improves CPU cache locality, making it particularly suitable for high-concurrency, low-latency network service scenarios.
Implementation Architecture:
- The architecture is built around a thread pool and role management mechanism.
- The system maintains a thread pool, with one thread acting as the leader and the others as followers.
- The leader thread is responsible for waiting for I/O events on an event multiplexer (such as epoll).
- When an event occurs, the leader first selects a thread from the followers to promote to the new leader, then demotes itself to a worker thread to handle that event, with role switching implemented through condition variables and mutexes.
- To avoid the thundering herd effect, only the leader thread waits on the event multiplexer.
- Threads that finish processing an event rejoin the follower queue, waiting to be selected as the leader again.

8. Select (Select I/O Multiplexing)
- File:
<span>select_server.h</span> - Characteristics: Uses the select system call to monitor multiple file descriptors
- Applicable Scenarios: Cross-platform medium concurrency scenarios
- Advantages: Good cross-platform compatibility
- Disadvantages: Limited number of file descriptors, performance decreases linearly with the number of connections
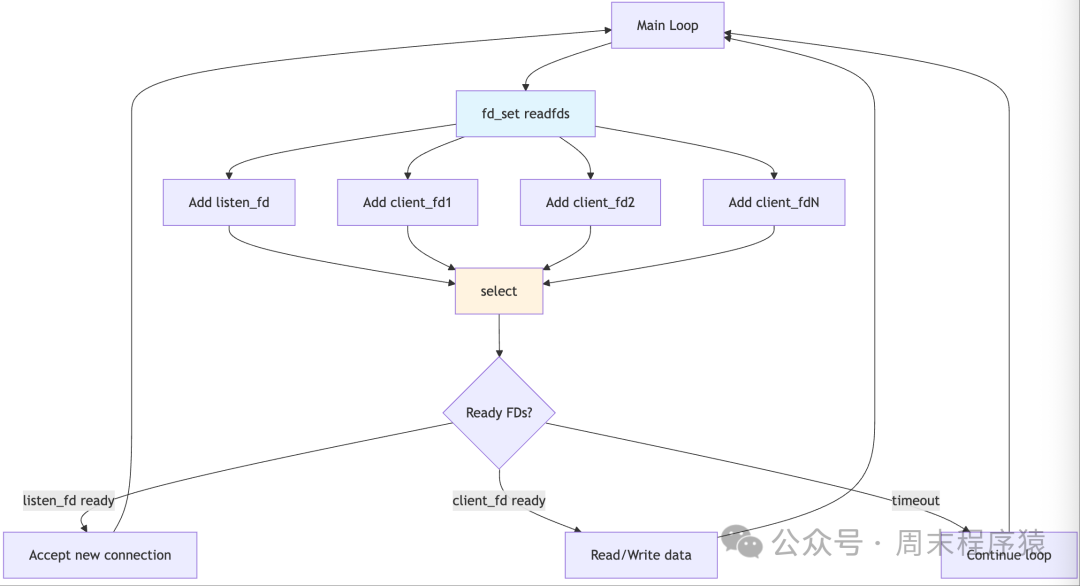
Detailed Introduction: The select model is the most classic I/O multiplexing technology, using the select() system call to monitor the state changes of multiple sockets in a single thread. The server maintains three sets of file descriptors for reading, writing, and exceptions, and select() blocks waiting until at least one descriptor is ready. When select() returns, the server traverses the descriptor sets to handle all ready I/O operations. This model avoids the complexity of multi-threading, allowing a single thread to handle multiple concurrent connections, forming the basis of event-driven programming.
Implementation Architecture:
- The architecture is based on an event loop pattern.
- When initializing, the server adds the listening socket to the read descriptor set, then enters the main loop calling select() to wait for events.
- When a new connection arrives, after accept(), the client socket is added to the monitored set; when the client socket is readable, it reads and processes the request; when writable, it sends response data.
- Each loop iteration requires resetting the descriptor set, as select() modifies the input set.
9. Poll (Poll I/O Multiplexing)
- File:
<span>poll_server.h</span> - Characteristics: Uses the poll system call, improving the limitations of select
- Applicable Scenarios: Medium concurrency scenarios
- Advantages: No limit on the number of file descriptors
- Disadvantages: Performance still decreases linearly with the number of connections
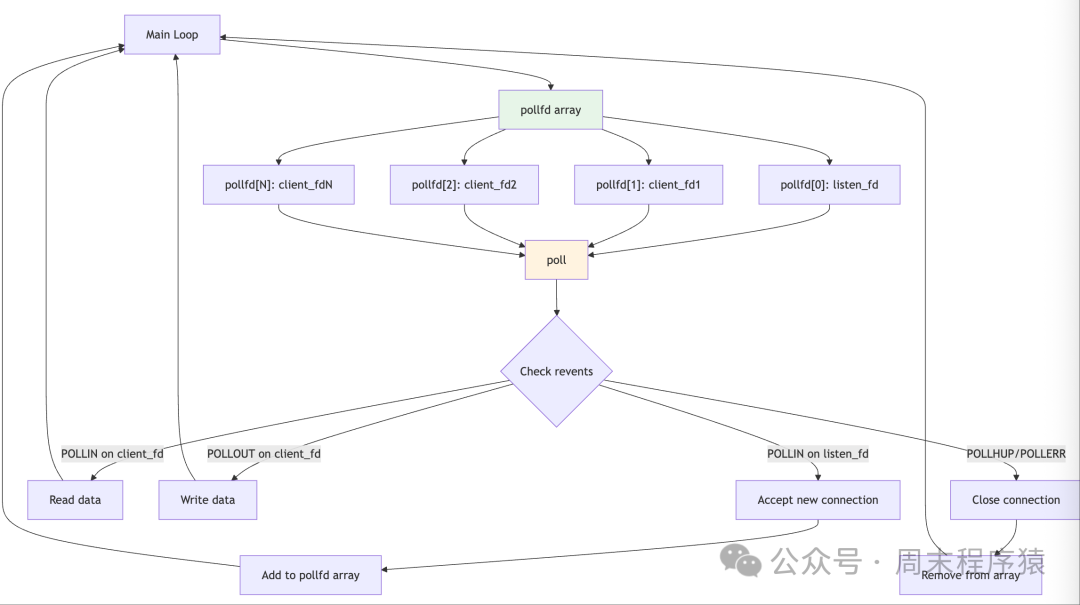
Detailed Introduction: The poll model is an improved version of the select model, using the poll() system call to monitor I/O events of multiple file descriptors. Unlike select, poll uses an array of pollfd structures to describe the file descriptors to monitor and the event types, without the FD_SETSIZE limitation, allowing monitoring of any number of descriptors. When poll() returns, it checks the revents field of each pollfd structure to determine which descriptors are ready. This model retains the single-threaded advantage of select while solving the descriptor count limitation issue.
Implementation Architecture:
- The architecture is also based on an event loop but uses a more flexible data structure.
- The server maintains a dynamic array of pollfd structures, each containing a file descriptor, the events of interest, and the returned events.
- The main loop calls poll() to wait for events, and after returning, traverses the array to check the revents field.
- When a new connection arrives, the pollfd array is dynamically expanded; when a connection closes, the corresponding element is removed from the array.
- Compared to select, poll’s interface is clearer, and there is no need to repeatedly set the descriptor set.
10. Epoll (Epoll I/O Multiplexing)
- File:
<span>epoll_server.h</span> - Characteristics: A high-efficiency I/O multiplexing mechanism unique to Linux
- Applicable Scenarios: High concurrency scenarios in Linux environments
- Advantages: Excellent performance, supports edge-triggered notifications
- Disadvantages: Limited to Linux systems
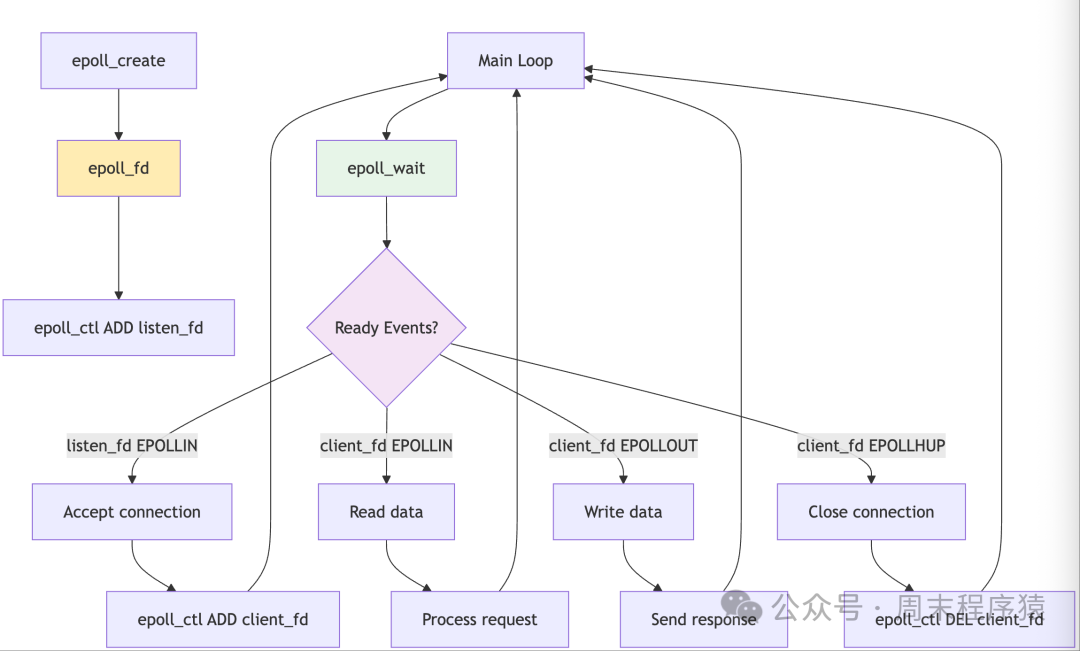
Detailed Introduction: Epoll is a high-performance I/O multiplexing mechanism provided by the Linux kernel, specifically designed to solve the C10K problem. Unlike select/poll, epoll uses an event-driven approach, returning only the ready file descriptors, avoiding linear scanning. Epoll internally uses a red-black tree to manage file descriptors and a ready list to store active events, achieving O(1) event notification efficiency. It supports both level-triggered (LT) and edge-triggered (ET) modes, providing great flexibility for high-performance servers.
Implementation Architecture:
- The architecture is based on three core system calls of epoll: epoll_create to create an epoll instance, epoll_ctl to manage monitored file descriptors, and epoll_wait to wait for events.
- When the server starts, it creates an epoll instance and adds the listening socket to the monitoring set. The main loop calls epoll_wait to wait for events, processing only the returned ready descriptors without traversing all connections.
- New connections are added to the monitoring set through epoll_ctl, and when connections are closed, they are removed.
- Supports various event types such as EPOLLIN, EPOLLOUT, EPOLLET, etc.
11. Kqueue (Kqueue I/O Multiplexing)
- File:
<span>kqueue_server.h</span> - Characteristics: A high-efficiency I/O multiplexing mechanism unique to BSD/macOS
- Applicable Scenarios: High concurrency scenarios in BSD/macOS environments
- Advantages: Excellent performance, rich functionality
- Disadvantages: Limited to BSD/macOS systems
Detailed Introduction: Kqueue is a high-performance event notification mechanism provided by FreeBSD and macOS, similar to Linux’s epoll but more powerful. Kqueue supports not only network I/O events but also file system changes, signals, timers, and various other event types. It manages all events through the kevent() system call, providing a consistent programming interface. Kqueue uses a kernel event queue, notifying only the events that have changed, avoiding polling overhead. Its design philosophy is to provide a unified event handling framework, allowing applications to efficiently respond to various system events.
Implementation Architecture:
- The architecture is built around the two core system calls kqueue() and kevent().
- When the server starts, it calls kqueue() to create an event queue, then uses kevent() to register events of interest (such as read events on the listening socket).
- The main loop calls kevent() to wait for events, which is used both for registering events and for retrieving ready events.
- When an event occurs, kevent() returns an array of events, containing event types, file descriptors, data, and other information. Supports various filters such as EVFILT_READ, EVFILT_WRITE, EVFILT_TIMER, etc.
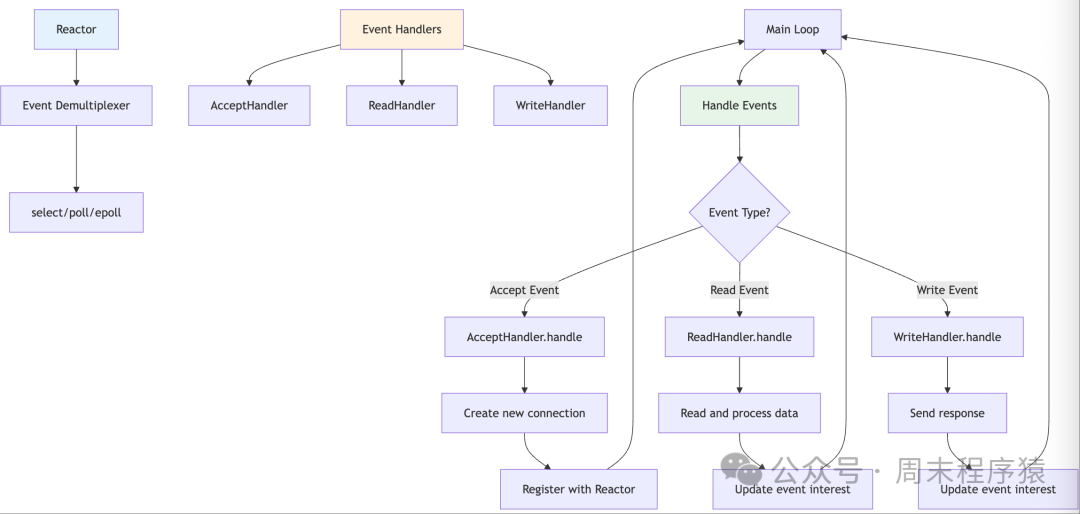
12. Reactor (Reactor Pattern)
- File:
<span>reactor_server.h</span> - Characteristics: An event-driven network programming pattern
- Applicable Scenarios: Scenarios requiring precise control over event handling
- Advantages: Clear structure, easy to extend
- Disadvantages: Higher implementation complexity
Detailed Introduction: The Reactor pattern is an event-driven design pattern that separates event detection from event handling, providing a highly extensible architecture. This pattern defines an event loop responsible for listening for various I/O events, dispatching them to the corresponding event handlers when they occur. The core idea of the Reactor pattern is “don’t call us, we will call you”; applications register event handlers, and the Reactor is responsible for calling them at the appropriate time. This pattern is widely used in network programming frameworks, such as Java NIO, Node.js, etc., providing an elegant asynchronous programming model.
Implementation Architecture:
- The architecture includes several core components: the Reactor responsible for the event loop and dispatching, the Demultiplexer responsible for I/O event detection (such as epoll/select), the EventHandler defining the event handling interface, and the ConcreteHandler implementing specific business logic.
- When the server starts, various handlers are registered with the Reactor, specifying the types of events they are interested in.
- The Reactor enters the event loop, calling the Demultiplexer to wait for events, and when events are ready, it finds the corresponding handler and calls its handling method.
- Supports AcceptHandler for handling new connections, ReadHandler for handling read events, WriteHandler for handling write events, etc.
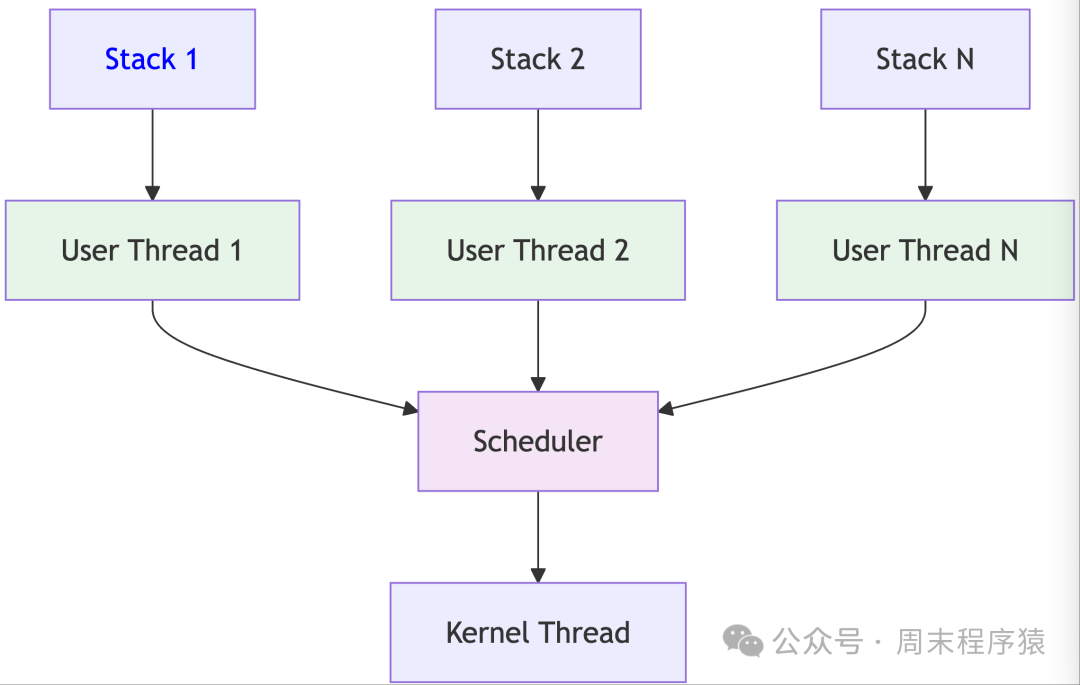
13. Coroutine (Coroutine Model)
- File:
<span>coroutine_server.h</span> - Characteristics: Simulates coroutine behavior using state machines (C++11 compatible)
- Applicable Scenarios: Asynchronous processing scenarios
- Advantages: Low memory consumption, fast context switching
- Disadvantages: Complex implementation, difficult to debug
Detailed Introduction: The coroutine model simulates coroutine behavior using state machines, implementing asynchronous programming in a C++11 environment. Unlike traditional callback methods, coroutines allow functions to pause during execution and resume later, making asynchronous code look like synchronous code. This implementation uses state machines to track the processing state of each connection, yielding control when encountering blocking I/O operations, and resuming execution once I/O is ready. This model is particularly suitable for handling a large number of concurrent connections, as coroutines have much lower memory overhead than threads, allowing thousands of coroutines to be created without exhausting system resources.
Implementation Architecture:
- The architecture is built around state machines and event loops.
- Each client connection corresponds to a coroutine object, containing the current state, context data, and state transition logic. The coroutine scheduler maintains a list of all active coroutines, polling I/O events in the event loop.
- When a socket is ready, the scheduler resumes the execution of the corresponding coroutine.
- Coroutines internally use state machines: INIT state initializes the connection, READING state handles reading, PROCESSING state handles business logic, WRITING state sends responses, and DONE state cleans up resources.
- Each state may yield due to I/O blocking, and the scheduler checks and resumes during the next loop.
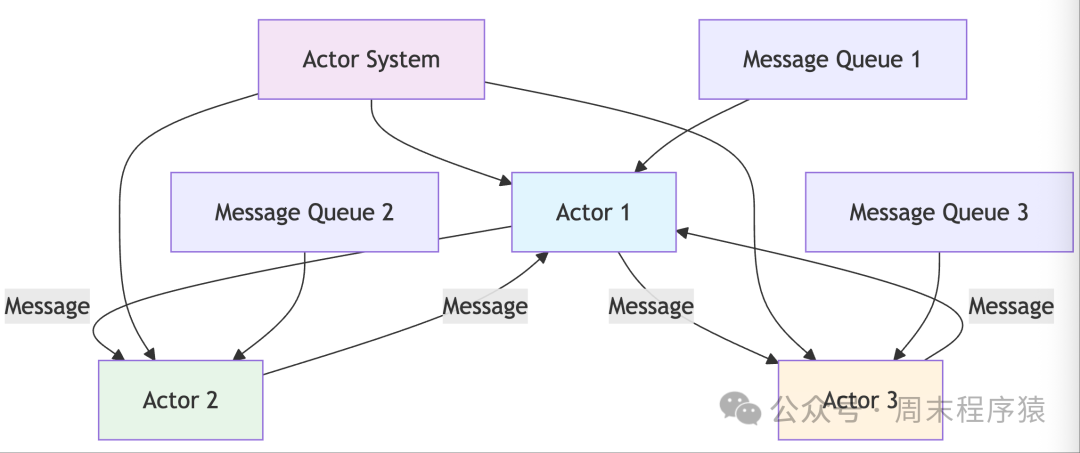
14. Actor Model
- File:
<span>actor_server.h</span> - Characteristics: Each Actor is an independent computing unit communicating via message passing
- Applicable Scenarios: Distributed systems, high-concurrency message processing
- Advantages: No shared state, naturally avoids race conditions
- Disadvantages: Complex implementation, message passing overhead
- Implementation: Can be implemented based on thread pools + message queues
Detailed Introduction: The Actor model is a concurrency computing model based on message passing, where each Actor is an independent computing unit with its own state and behavior. Actors do not share memory and can only communicate through asynchronous messages. When an Actor receives a message, it can perform three operations: process the message and update its internal state, send messages to other Actors, or create new Actors. This model naturally avoids the lock and race condition issues found in traditional concurrent programming, providing a safer way to handle concurrency. The Actor model is particularly suitable for building distributed systems, as Actors can be distributed across different machines and communicate via network messages.
Implementation Architecture:
- The architecture is built around Actors, message queues, and a scheduler.
- Each Actor contains a mailbox (message queue), state data, and message processing logic.
- At system startup, multiple Worker Actors are created to handle client requests, and one Acceptor Actor is responsible for accepting new connections.
- When a new connection arrives, the Acceptor sends a message to the Worker with the lightest load.
- Once the Worker Actor receives the connection message, it is responsible for the entire lifecycle of that connection.
- The Actor scheduler is responsible for retrieving messages from each Actor’s mailbox and executing the corresponding processing functions.
- Message passing is implemented through thread-safe queues, supporting both local and remote messages.
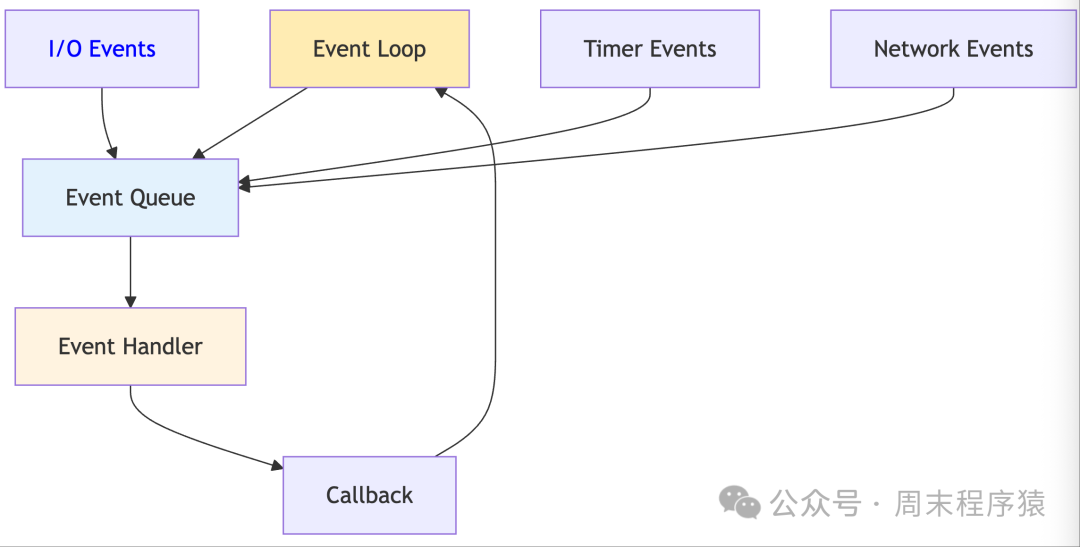
15. Event Loop Model
- File:
<span>event_loop_server.h</span> - Characteristics: Single-threaded event loop, similar to Node.js implementation
- Applicable Scenarios: I/O-intensive applications
- Advantages: Avoids thread switching overhead, low memory usage
- Disadvantages: Single-threaded limitation, CPU-intensive tasks will block
- Implementation: Based on epoll/kqueue + callback functions
Detailed Introduction: The event loop model is a single-threaded asynchronous programming pattern that processes all I/O events and callback functions through an infinite loop. The event loop continuously checks the event queue, executing the corresponding callback functions when events are ready. The core idea of this model is to convert all blocking operations into non-blocking asynchronous operations, using an event notification mechanism to handle I/O completion. The event loop model is widely used in high-performance servers like Node.js and Redis, particularly suitable for I/O-intensive applications. By adopting a single-threaded design, it avoids the locks and synchronization issues found in multi-threaded programming, greatly simplifying programming complexity.
Implementation Architecture:
- The architecture is built around the event loop, event queue, and callback functions.
- The event loop is the core of the system, responsible for listening to file descriptors, timers, and other event sources.
- When an event occurs, the corresponding callback function is added to the event queue, and the event loop processes all callbacks in the queue during each iteration, then waits for new events.
- For network I/O, efficient I/O multiplexing mechanisms like epoll/kqueue are used.
- Timers are implemented using a min-heap, supporting high-precision timing tasks.
- All I/O operations are non-blocking; if an operation cannot be completed immediately, a callback function is registered to wait for event notification.
16. Fiber/Green Thread
- File:
<span>fiber_server.h</span> - Characteristics: User-space scheduled lightweight threads
- Applicable Scenarios: Scenarios requiring a large number of concurrent connections
- Advantages: Extremely low creation cost, can create tens of thousands
- Disadvantages: Requires complex scheduler and stack management
- Implementation: Requires implementing a user-space scheduler and stack switching
Detailed Introduction: Fibers are user-space lightweight threads, also known as green threads or cooperative threads. Unlike operating system threads, fibers are created, destroyed, and scheduled entirely in user space without kernel involvement. Fibers use cooperative scheduling, where switching occurs only when a fiber voluntarily yields control, avoiding the overhead and complexity of preemptive scheduling. Each fiber requires very little memory (usually a few KB of stack space), allowing the creation of hundreds of thousands of fibers without exhausting system resources. Fibers are particularly suitable for I/O-intensive applications, as they can quickly switch to other fibers when encountering blocking operations.
Implementation Architecture:
- The architecture is built around a user-space scheduler and context switching mechanism.
- Each fiber contains its own stack space, register state, and execution context.
- The fiber scheduler maintains ready and blocked queues, responsible for creating, scheduling, and destroying fibers.
- When a fiber encounters an I/O operation, it adds itself to the blocked queue and yields to the scheduler, which selects the next ready fiber to continue execution.
- When I/O is complete, the corresponding fiber is moved back to the ready queue for scheduling.
- Context switching is implemented through assembly code, saving and restoring CPU register states.
- To support asynchronous I/O, it is usually combined with mechanisms like epoll, waking up the corresponding fiber when I/O is ready.
17. Work Stealing Model
- File:
<span>work_stealing_server.h</span> - Characteristics: Each thread has its own task queue, stealing tasks from other threads when idle
- Applicable Scenarios: Load balancing for CPU-intensive tasks
- Advantages: Automatic load balancing, reduces idle threads
- Disadvantages: Complex implementation, potential cache consistency issues
- Implementation: Based on lock-free queues and thread pools
Detailed Introduction: The work stealing model is a dynamic load balancing parallel computing pattern where each worker thread maintains its own task queue. When a thread completes its tasks, it attempts to “steal” tasks from other threads’ queues to execute. This model can automatically adapt to the uneven execution times of tasks, avoiding situations where some threads are idle while others are overloaded. The work stealing algorithm was initially proposed by the Cilk project and has since been widely used in parallel computing frameworks like Java’s ForkJoinPool and Intel TBB. This model is particularly suitable for handling recursive divide-and-conquer algorithms and scenarios with significant task execution time differences.
Implementation Architecture:
- The architecture is built around multiple worker threads and double-ended queues (deque).
- Each worker thread has a deque, with new tasks added from the front, and threads taking tasks from the front to execute (LIFO order, utilizing cache locality).
- When a thread’s queue is empty, it randomly selects another thread’s queue to steal tasks from the back (FIFO order, reducing conflicts).
- To reduce lock contention, a lock-free double-ended queue is typically used.
- Tasks can generate new subtasks during execution, which are added to the current thread’s queue.
- The system also includes a global task queue for receiving externally submitted tasks.

18. Producer-Consumer Model
- File:
<span>producer_consumer_server.h</span> - Characteristics: Dedicated producer threads receive connections, consumer threads process requests
- Applicable Scenarios: Scenarios with clearly defined reception and processing logic
- Advantages: Responsibility separation, easy to optimize
- Disadvantages: The queue may become a bottleneck
- Implementation: Based on thread pools + blocking queues
Detailed Introduction: The producer-consumer model is a classic concurrent design pattern that decouples the processes of data production and consumption through a buffer. The producer is responsible for generating data and placing it into the buffer, while the consumer takes data from the buffer for processing. This model is particularly suitable for scenarios where the production and consumption speeds do not match, with the buffer acting to smooth out peaks and valleys. In a network server, receiving connections can be seen as the production process, while processing requests is the consumption process, decoupled through a task queue. This model improves system throughput and responsiveness while simplifying system design.
Implementation Architecture:
- The architecture is built around producer threads, consumer threads, and a shared buffer. The buffer is typically implemented using a thread-safe queue, supporting concurrent access by multiple producers and consumers.
- The producer thread is responsible for receiving client connections, encapsulating the connection information into a task object, and placing it into the queue.
- The consumer thread takes tasks from the queue and executes the specific business logic.
- To avoid buffer overflow or underflow, condition variables are typically used for synchronization: when the buffer is full, the producer waits; when the buffer is empty, the consumer waits.
- Multiple producer and consumer threads can be configured to improve concurrency. The buffer size needs to be tuned based on production and consumption speeds.

19. Half-Sync/Half-Async Model
- File:
<span>half_sync_async_server.h</span> - Characteristics: The synchronous layer handles protocols, while the asynchronous layer handles I/O
- Applicable Scenarios: Complex protocol handling
- Advantages: Combines the advantages of synchronous and asynchronous
- Disadvantages: Complex architecture, inter-layer communication overhead
- Implementation: Layered architecture, asynchronous I/O + synchronous business logic
Detailed Introduction: The half-sync/half-async model is a hybrid architecture pattern that divides the system into synchronous processing and asynchronous processing layers, combining the advantages of both modes. The asynchronous layer is responsible for efficient I/O processing, using an event-driven approach to handle network events; the synchronous layer handles business logic processing using traditional synchronous programming models. Communication between the two layers occurs through queues, with the asynchronous layer placing received requests into the queue, and the synchronous layer’s worker threads taking requests from the queue for processing. This model ensures high efficiency in I/O processing while maintaining simplicity in business logic, making it a commonly used architectural pattern in practical projects.
Implementation Architecture:
- The architecture consists of three main components: the asynchronous I/O layer, the synchronous processing layer, and the queue layer.
- The asynchronous I/O layer uses a single-threaded event loop, based on epoll/kqueue and other mechanisms to handle all network I/O events, including accepting connections, reading data, and sending responses.
- Once a complete request is received, the request data is encapsulated into a task object and placed into the queue.
- The synchronous processing layer contains multiple worker threads that take tasks from the queue and process business logic using traditional synchronous methods, such as database access and file operations.
- After processing is complete, the response data is sent back through the queue to the asynchronous layer for sending.
- The queue layer is responsible for communication between the two layers, typically implemented using a thread-safe queue.
20. Proactor Pattern
- File:
<span>proactor_server.h</span> - Characteristics: Notifies the application after asynchronous I/O completion
- Applicable Scenarios: Windows IOCP, asynchronous I/O scenarios
- Advantages: True asynchronous I/O
- Disadvantages: Strong platform dependency, complex implementation
- Implementation: Based on the operating system’s asynchronous I/O mechanism
Detailed Introduction: The Proactor pattern is a design pattern based on asynchronous I/O, corresponding to the Reactor pattern. In the Reactor pattern, the application is notified when I/O is ready and performs I/O operations itself, while in the Proactor pattern, the application initiates asynchronous I/O operations, and the operating system notifies the application of the results after completing the I/O. This pattern truly achieves asynchronous I/O operations, allowing the application to continue processing other tasks without blocking for I/O completion. The Proactor pattern is particularly suitable for I/O-intensive applications, fully utilizing system resources and providing higher concurrency performance.
Implementation Architecture:
- The architecture is built around asynchronous I/O operations and completion notifications.
- Core components include: Proactor responsible for managing asynchronous operations and dispatching completion events, AsynchronousOperationProcessor handling asynchronous I/O operations, and CompletionHandler processing I/O completion events.
- When the application initiates asynchronous read/write operations, it submits the operation to the operating system while registering a completion handler. The operating system performs the I/O operation in the background and places the results in a completion queue.
- The Proactor retrieves events from the completion queue and calls the corresponding completion handler.
- On Windows, IOCP (I/O Completion Ports) can be used, while on Linux, io_uring or simulated implementations can be used.

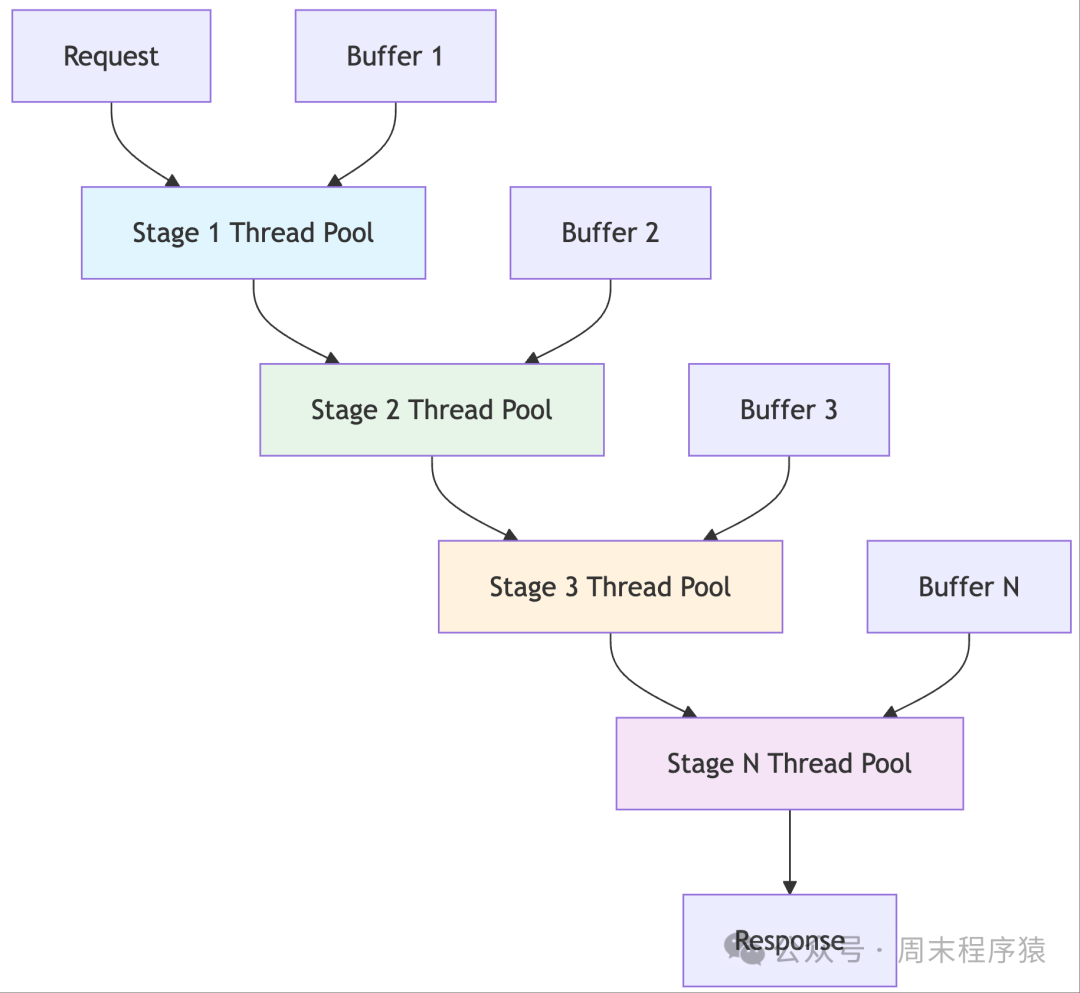
21. Pipeline Model
- File:
<span>pipeline_server.h</span> - Characteristics: Request processing is divided into multiple stages, each handled by different threads
- Applicable Scenarios: Complex request processing flows
- Advantages: Pipeline processing improves throughput
- Disadvantages: Inter-stage synchronization is complex, potential bottleneck stages
- Implementation: Multiple thread pools, each handling one stage
Detailed Introduction: The pipeline model decomposes the request processing process into multiple consecutive stages, each handled by dedicated threads or thread pools, forming a pipeline processing architecture. Requests pass through each stage in order, with each stage focusing on specific processing tasks, such as parsing, validation, business logic, response generation, etc. This model is similar to a factory assembly line, significantly improving system throughput, as multiple requests can be processed in parallel at different stages. The pipeline model is particularly suitable for handling complex business processes that can be decomposed into fixed steps, widely used in data processing, image processing, compilers, etc.
Implementation Architecture:
- The architecture consists of multiple processing stages and inter-stage buffer queues, with each stage containing one or more worker threads dedicated to specific processing tasks.
- Stages are connected through thread-safe queues, with the output of the previous stage serving as the input for the next stage.
- Requests start from the first stage, passing through all stages, ultimately producing a response.
- Each stage can be independently tuned, including thread count, queue size, and other parameters.
- To avoid any stage becoming a bottleneck, resources need to be allocated reasonably based on the processing capabilities of each stage.
- Dynamic scaling of stages can be implemented, adjusting the number of threads based on load conditions.
22. Hybrid Model
- File:
<span>hybrid_server.h</span> - Characteristics: Combines the advantages of multiple models
- Examples:
- Reactor + Thread Pool
- Epoll + Coroutine
- Multi-Process + Multi-Thread
- Applicable Scenarios: Scenarios requiring a balance of various performance metrics
- Advantages: High flexibility, targeted optimization
- Disadvantages: Complex implementation, difficult to debug
Detailed Introduction: The hybrid model is a comprehensive concurrency architecture that combines multiple concurrency models in the same system based on different business needs and performance requirements. It can use the Reactor model for efficient event handling at the I/O processing layer, the thread pool model to ensure processing capacity at the business logic layer, and asynchronous I/O models to improve database access efficiency at the data access layer. This model allows developers to choose the most suitable concurrency strategy for different parts of the system, achieving optimal overall performance. The hybrid model is widely used in large enterprise applications, microservice architectures, and distributed systems, making it a mainstream architectural choice for modern high-performance servers.
Implementation Architecture:
- The architecture adopts a layered design, with each layer selecting the most suitable concurrency model based on its characteristics.
- The network access layer typically uses event-driven models (such as Epoll/Reactor) to handle a large number of concurrent connections, ensuring efficient I/O processing.
- The request routing layer may use the Actor model to implement request dispatching and load balancing.
- The business processing layer selects appropriate models based on business characteristics, such as using thread pools for CPU-intensive tasks and asynchronous models for I/O-intensive tasks.
- The data access layer may combine connection pools and asynchronous I/O to optimize database access.
- Communication between layers can be achieved through message queues, event buses, or direct calls.
- The system requires a unified monitoring and management mechanism to coordinate the operation of various models.

Compilation and Running
Compilation
make
Running the Server
# Basic usage
./concurrency_server <model> [port]
# Examples
./concurrency_server thread_pool 8080
./concurrency_server epoll 9000
./concurrency_server reactor 8888
Performance Comparison
Performance comparisons of some <span>servers</span> were conducted using the <span>https://github.com/linkxzhou/http_bench</span> tool (with logging enabled):
| Model Name | QPS |
|---|---|
| single_process_server | 19075.400 |
| multi_process_server | 6904.800 |
| multi_thread_server | 18137.834 |
| process_pool1_server | 18337.299 |
| process_pool2_server | 18589.268 |
| thread_pool_server | 18483.166 |
| leader_follower_server | 20180.701 |
| poll_server | 18817.867 |
| kqueue_server | 19096.133 |
| reactor_server | 18945.467 |
| event_loop_server | 19442.801 |
| work_stealing_server | 8903.566 |
| actor_server | 18681.500 |
| fiber_server | 18994.268 |
| producer_consumer_server | 18208.633 |
| proactor_server | 18130.533 |