FiS-VLA Team SubmissionQuantum Bit | WeChat Official Account QbitAI
Teaching robots to execute tasks intelligently, quickly, and accurately has always been a challenge in the field of robotic control.
To address this issue, The Chinese University of Hong Kong, Peking University, Zhi Square, and the Beijing Academy of Artificial Intelligence have collaboratively proposed the Fast-in-Slow (FiS-VLA), which is a unified dual-system VLA model.
It achieves the integration of fast and slow systems within a single model by reconstructing the last few layers of the Transformer module from the slow system 2 into an efficient execution module, serving as the fast system 1.

This innovative paradigm achieves the first-ever synergy of slow reasoning and fast execution within a single pre-trained model, breaking through the traditional bottleneck of dual-system separation.
From now on, system 1 is no longer a “novice”; it directly inherits the pre-trained knowledge of VLM, seamlessly understanding the “thought results” (intermediate layer features) of system 2, while its design ensures it can operate at high speed.
In real machine tests, the research team designed 8 tasks on two dual-arm robot platforms, AgileX and AlphaBot, such as “wiping a blackboard,” “pouring water,” and “folding towels.” FiS-VLA achieved success rates of 68% and 74%, respectively, improving over 10 percentage points compared to the Pi0 model.
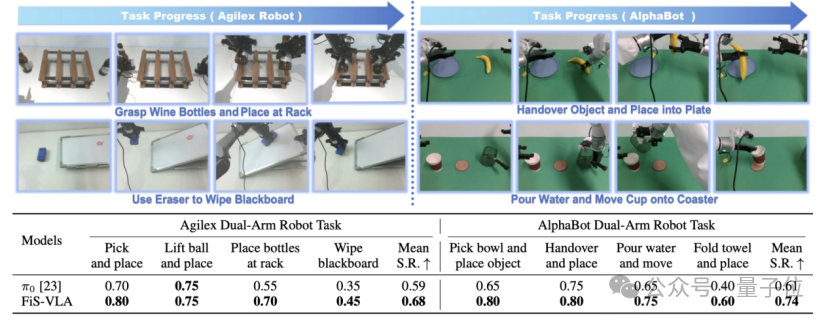
Moreover, FiS-VLA also demonstrates robust performance in generalization tasks. Whether faced with unseen new objects, complex background interference, or changes in lighting conditions, it maintains a success rate of over 50%, while other models generally experience significant performance drops.
Method: The First “Heterogeneous Input + Asynchronous Frequency” Dual-System VLA Model
Although recent visual-language-action models (VLA) have begun to enhance common-sense reasoning capabilities by leveraging internet-scale pre-trained visual-language models (VLMs), these models often have billions of parameters and rely on autoregressive action generation strategies, resulting in poor execution speed.
Inspired by psychologist Daniel Kahneman’s dual-system theory of the brain, the industry has introduced a “dual-system” design into VLA large models, utilizing the slow system 2 module based on VLM for high-level reasoning and an independent fast system 1 action module for real-time control.
However, existing designs keep the two systems as independent modules, limiting the fast system 1’s ability to fully utilize the rich pre-trained knowledge of the slow system 2, making it difficult for the “athlete” of system 1 to absorb the extensive knowledge of the “scholar” of system 2.
The proposed Fast-in-Slow (FiS-VLA) achieves the integration of fast and slow systems within a single model.
Considering the fundamental differences in roles between the two systems in FiS-VLA, the researchers introduced heterogeneous modal inputs and asynchronous operating frequency strategies, enabling the model to achieve both rapid responses and fine control capabilities.
Additionally, to enhance coordination between the two systems, the researchers proposed a dual-aware co-training strategy: on one hand, injecting action generation capabilities into system 1, and on the other hand, retaining the contextual reasoning capabilities of system 2.
This effectively addresses the issues of low execution frequency and the disconnection between reasoning and action in traditional VLA models, truly achieving “parallel planning and action”.

In model evaluation, compared to existing SOTA VLA methods, FiS-VLA improved the average success rate by 8% in simulated tasks and by 11% in real environments, achieving a control frequency of 117.7 Hz (with an action block size of 8).

Due to the fundamental differences in responsibilities between system 2 and system 1: system 2 is responsible for understanding, processing language instructions and 2D images, extracting task semantics at a slower pace; system 1 is responsible for execution, reading robot states, 3D point clouds, and current images, generating high-frequency control actions at a very fast pace.
Therefore, FiS-VLA is specifically designed for these two systems: they receive different modal inputs and operate at asynchronous frequencies.
Although the two systems have different tasks, their operational logic is coherent, and data is intercommunicated. System 1 uses the intermediate semantic representations of system 2 as guidance while combining its own inputs to achieve high-speed and precise action generation.
To handle point cloud data, the researchers designed a lightweight 3D tokenizer. It compresses complex spatial information into high-dimensional tokens and extracts local geometric features through a visual encoder. This approach is not only efficient but also endows system 1 with keen spatial perception capabilities.
In terms of system operational rhythm, FiS-VLA adopts an asynchronous frequency design. System 2 thinks slowly, while system 1 executes quickly. For example, for every run of system 2, system 1 can run four times consecutively. This mechanism ensures that reasoning does not become a bottleneck, and action responses are timely enough.
It is worth mentioning that the integration of fast and slow dual systems is becoming a consensus in the field of VLA large models, but in terms of breakthrough designs in asynchronous architecture, FiS-VLA is still leading the industry.
Training: “Dual-System” Co-training, Complementing Each Other
The training process is also quite meticulous.
The core goal of FiS-VLA is to generate precise and executable actions, thus adopting a “dual-aware co-training” strategy:
For the execution module (system 1), the characteristics of probability and continuity in diffusion modeling are utilized by injecting noisy actions into the embedding space of system 1 as latent variables to learn action generation, specifically as follows:
Given the initial action sequence ãτ, the researchers inject Gaussian noise η ∼ N(0, I) at a random time step τ ∼ U(1, T) (where τ ∈ Z, T = 100). The forward process adds noise in a closed form:
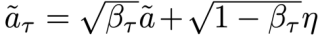
Where βτ is the noise scaling factor from a predefined schedule. To train system 1 (π_{θ_f}), the learning process is modeled as an optimization problem of the following objective:
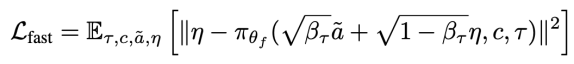
Where c represents the conditional source, including low-frequency latent features extracted by system 2 and high-frequency inputs from system 1. Since the execution module of system 1 is embedded in the VLM of system 2, if the training model is solely focused on diffusion action generation, it may lead to catastrophic forgetting of its autoregressive reasoning capabilities.
Therefore, the researchers proposed a joint training objective, retaining the high-dimensional reasoning capabilities for the reasoning module (system 2), using an autoregressive token-by-token prediction paradigm as the training objective to generate discrete language or actions, avoiding catastrophic forgetting in the slow system.
For discrete actions:

Where D_t is the total length of discrete action tokens, â_i is the i-th true action token, and P(â_i | context, θ) is the predicted probability of the LLM given the input context and parameters θ (θ_f ⊆ θ). The final overall training objective is:

As can be seen, the two systems have different objectives, but the training is conducted synchronously. System 1 learns “how to move,” while system 2 learns “to think clearly before moving.” This strategy prevents the model from forgetting the reasoning capabilities of system 2 and allows both systems to optimize together within a unified model.
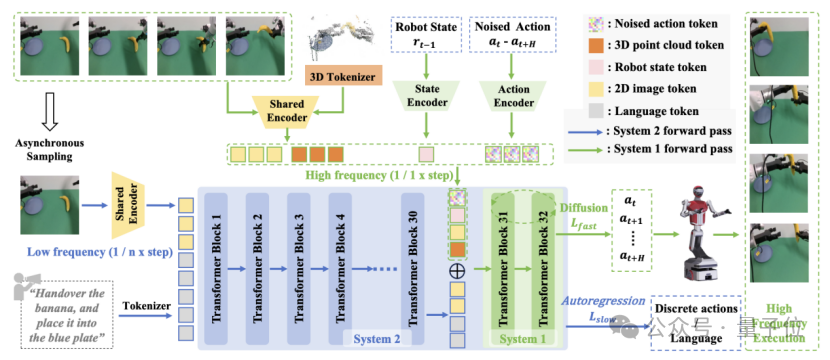
Additionally, during the pre-training phase, the researchers utilized over 860,000 robot task trajectories covering multiple robot platforms. The backbone of FiS-VLA employs the 7B parameter LLaMA2 large language model, while the visual component uses SigLIP and DINOv2 encoders, balancing semantic and spatial representations.
Results: Significant Improvement in Simulation & Real Machine Success Rates
In the RLBench simulation tasks, FiS-VLA achieved an average success rate of 69% across 10 tasks, significantly outperforming CogACT (61%) and Pi0 (55%). Notably, FiS-VLA excelled in 8 out of 10 tasks, highlighting its robustness in action generation.
Simultaneously, in terms of control frequency, FiS-VLA reached a control frequency of 21.9 Hz with an action block size set to 1, more than twice the speed of CogACT (9.8 Hz) and over 1.6 times faster than Pi0 (13.8 Hz).

Ablation Studies
To further validate the model design, the researchers conducted multiple rounds of ablation studies.
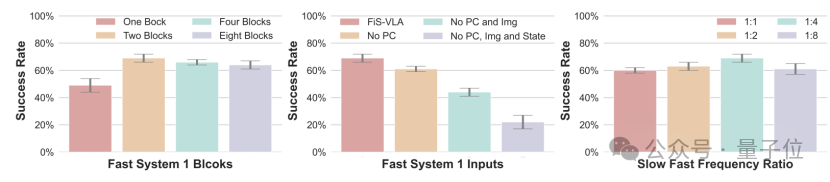
First, they tested the number of shared Transformer blocks between system 1 and system 2. The results showed that as the number of shared blocks increased, the control performance gradually improved, saturating when using two blocks.
Next, they examined the input modalities of system 1. The experiments indicated that robot state, 2D images, and 3D point clouds are all indispensable. Notably, the 3D point cloud plays a crucial role in fine action control.
They also investigated the ratio of operational frequencies between the systems. When the asynchronous operational frequency ratio between system 2 and system 1 was 1:4, FiS-VLA achieved optimal performance, striking an ideal balance between slow reasoning and fast action generation. This validates that the asynchronous coordination frequency design not only enhances action generation speed but also increases the richness of observational information passed to the execution module.
To further enhance control efficiency, FiS-VLA also introduced an “action chunking” mechanism. This means predicting multiple consecutive actions at once, rather than reasoning step by step. This approach reduces the risk of error accumulation while improving action continuity.
The results indicate that with the action block set to 8, the model’s success rate remains stable, while the control frequency soars to 117.7 Hz. The robot’s behavior becomes smoother, with fewer decisions and more stable execution.
Generalization Ability
Remarkably, FiS-VLA also demonstrates robust performance in generalization tasks. Whether faced with unseen new objects, complex background interference, or changes in lighting conditions, it maintains a success rate of over 50%. In contrast, other models generally experience significant performance drops.

This is due to the benefits brought by the integration of fast and slow systems: system 2 can understand semantics and identify the core of tasks; system 1 can respond quickly based on perception. The combination of both endows the model with strong generalization ability and robustness.
Currently, the structure of FiS-VLA remains static: the number of shared Transformer layers and the system frequency ratio need to be predetermined. The researchers plan to explore dynamic parameter adjustment mechanisms in the future, allowing the model to automatically adjust its operational strategy based on task complexity and environmental conditions.
This adaptive mechanism will further unleash the potential of FiS-VLA, bringing it closer to the core brain of a general intelligent robot.
In summary, FiS-VLA is not a simple optimization of existing models but a completely new architectural approach. It breaks down the barriers between thinking and action, semantics and physics, planning and execution.
It not only enables robots to “think” but also allows them to “move quickly”; not only to understand complex tasks but also to complete them at high frequency.
This may be the foundational form of future general intelligent robots—possessing both a cognitive brain and a dexterous body, unified within the same nervous system.
Paper link: https://arxiv.org/pdf/2506.01953Project homepage: https://fast-in-slow.github.io/Code link:https://github.com/CHEN-H01/Fast-in-Slow
One-click triple connection「Like」「Share」「Heart」
Feel free to leave your thoughts in the comments!
— The End —

🌟 Light up the star mark 🌟
Daily updates on cutting-edge technological advancements