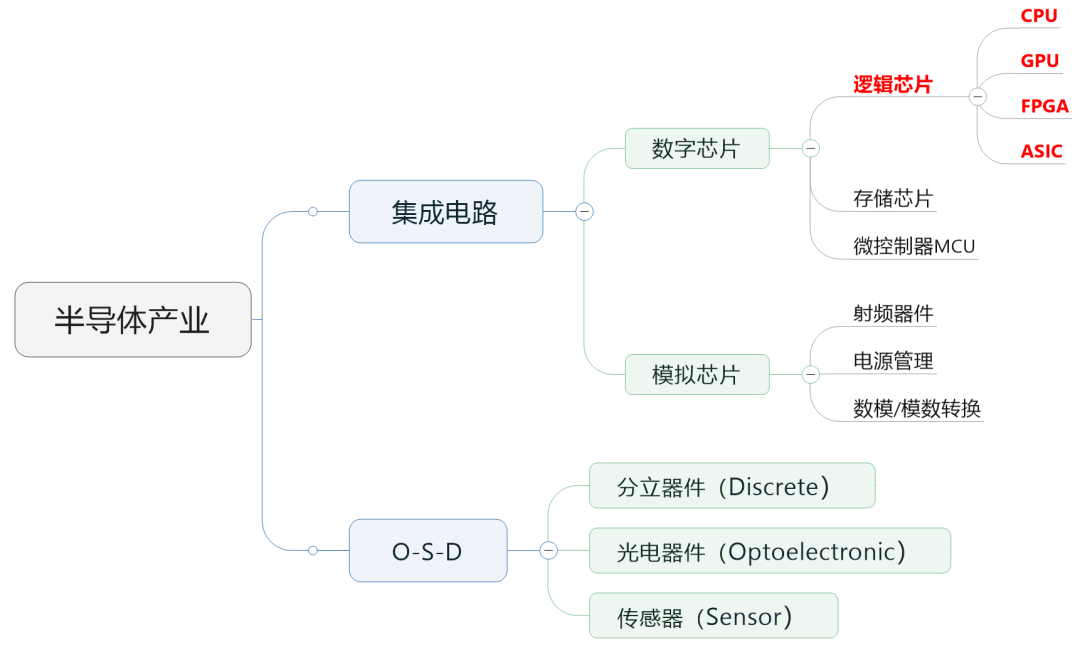
In a previous article, we mentioned that the semiconductor chips in the industry are typically divided into digital chips and analog chips. Among them, the market size of digital chips accounts for a large proportion, reaching about 70%.
Digital chips can be further subdivided into logic chips, memory chips, and microcontrollers (MCUs).
We will introduce memory chips and MCUs later, today we focus on logic chips.
Logic chips are essentially computing chips. They contain various logic gate circuits that can perform arithmetic and logical functions, making them one of the most common types of chips.
The commonly heard CPU, GPU, FPGA, and ASIC all belong to the category of logic chips. The so-called “AI chips” that are currently very popular mainly refer to these.
█ CPU (Central Processing Unit)
Let’s first talk about the most familiar CPU, which stands for Central Processing Unit.
Everyone knows that the CPU is the heart of a computer.
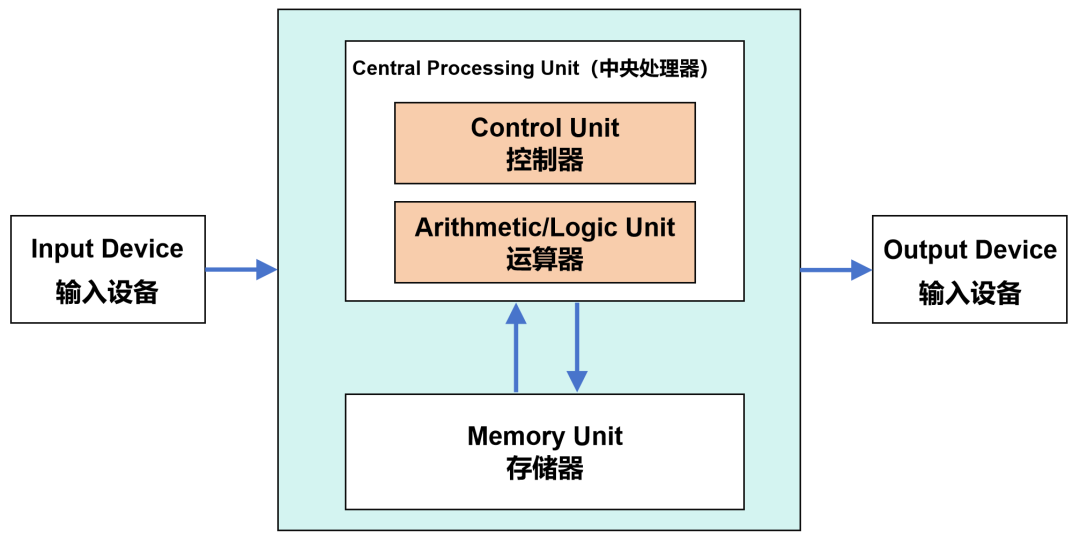
Modern computers are based on the von Neumann architecture developed in the 1940s. This architecture includes components such as the arithmetic logic unit (ALU), control unit (CU), memory, input devices, and output devices.
When data arrives, it is first placed into memory. Then, the control unit retrieves the corresponding data from memory and hands it over to the arithmetic logic unit for processing. After the computation is complete, the result is returned to memory.
This process has a more sophisticated name: “Fetch (Instruction Fetch) – Decode – Execute – Memory Access – Write Back”.
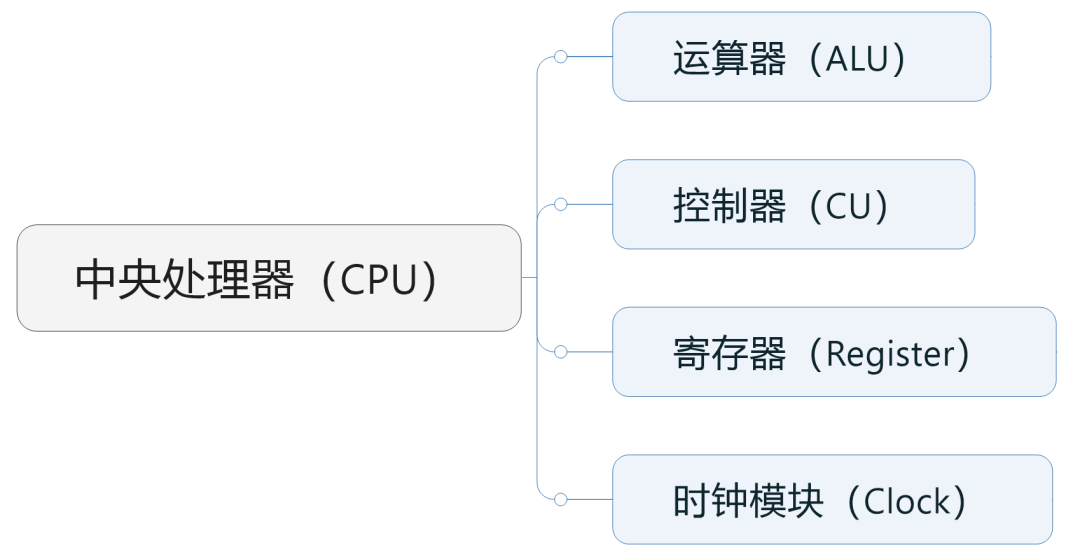
As we can see, the core functions of the arithmetic logic unit and control unit are both handled by the CPU.
Specifically, the arithmetic logic unit (which includes adders, subtractors, multipliers, and dividers) is responsible for performing arithmetic and logical operations, which is the real workhorse. The control unit is responsible for reading, decoding, and executing instructions from memory, directing the operations.
In addition to the arithmetic logic unit and control unit, the CPU also includes components like the clock module and registers (cache).
The clock module manages the time of the CPU, providing a stable time base. It issues signals periodically to drive all operations within the CPU, scheduling the work of various modules.
Registers are high-speed storage within the CPU used to temporarily hold instructions and data. They act as a “buffer” between the CPU and memory (RAM), operating faster than typical memory to avoid “dragging down” the CPU’s performance.
The capacity and access performance of registers can affect the CPU’s access frequency to memory, thereby impacting the overall system efficiency. We will discuss this further when we talk about memory chips.
CPUs are generally classified based on instruction set architecture, including x86 architecture and non-x86 architecture. x86 is primarily complex instruction set (CISC), while non-x86 is mainly reduced instruction set (RISC).
PCs and most servers use x86 architecture, dominated by Intel and AMD. Non-x86 architectures are diverse and have risen rapidly in recent years, including ARM, MIPS, Power, RISC-V, and Alpha, which will be introduced separately later.
█ GPU (Graphics Processing Unit)
Next, let’s look at the GPU.
The GPU is the core component of the graphics card, officially known as the Graphics Processing Unit.
The GPU should not be equated with the graphics card. A graphics card includes not only the GPU but also video memory, VRM voltage regulator module, MRAM chips, buses, fans, and peripheral device interfaces.
In 1999, NVIDIA was the first company to propose the concept of the GPU.
The reason for proposing the GPU was due to the rapid development of gaming and multimedia in the 1990s. These applications demanded higher 3D graphics processing and rendering capabilities from computers, which traditional CPUs could not handle, thus the introduction of GPUs to share this workload.
GPUs can be categorized based on form into discrete GPUs (dGPU) and integrated GPUs (iGPU), commonly referred to as dedicated and integrated graphics.
GPUs are also computing chips. Like CPUs, they consist of arithmetic logic units, control units, and registers.
However, because GPUs primarily handle graphics processing tasks, their internal architecture differs significantly from that of CPUs.
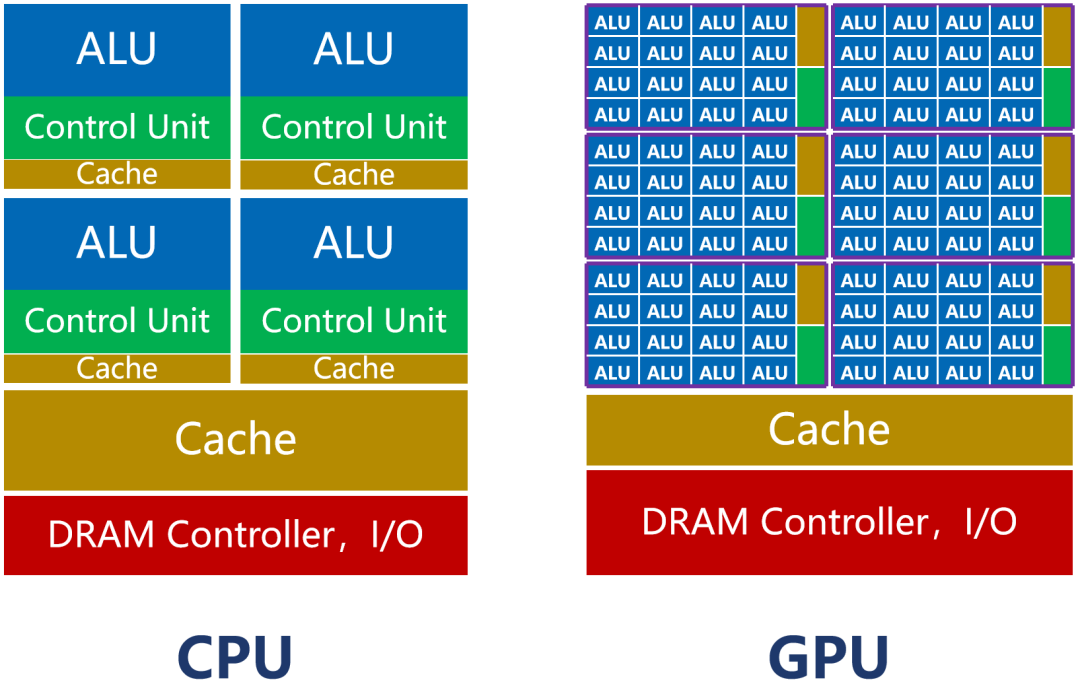
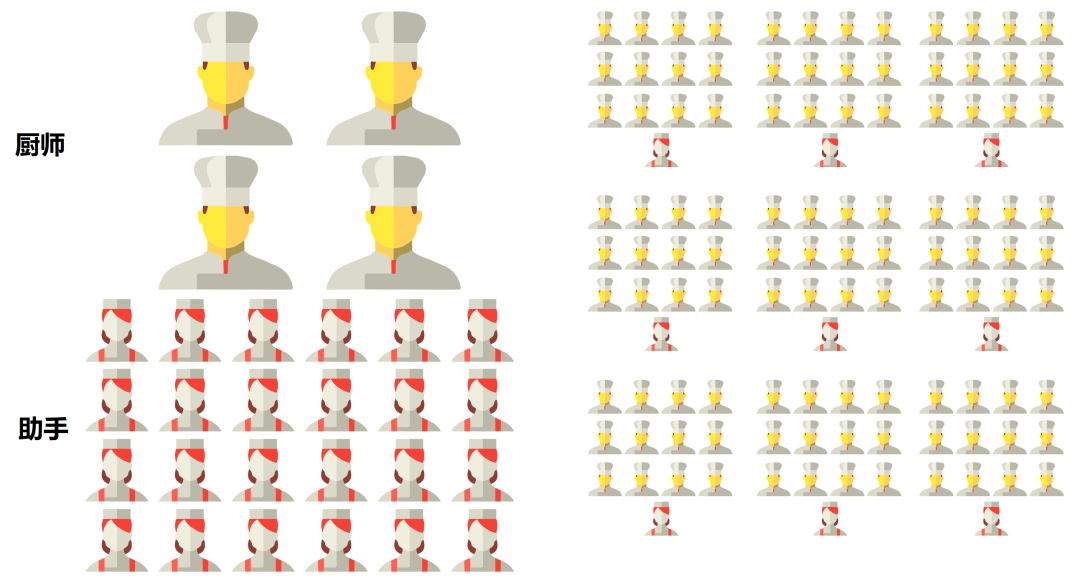
As shown in the previous image, the number of cores in a CPU (including the ALU) is relatively small, typically only a few dozen at most. However, CPUs have a large amount of cache (Cache) and complex control units (CU).
This design is because the CPU is a general-purpose processor. As the main core of the computer, its tasks are very complex, needing to handle various types of data computations and respond to human-computer interactions.
Complex conditions and branches, along with synchronization between tasks, lead to a significant amount of branch jumps and interrupt handling work. It requires larger caches to store various task states to reduce latency during task switching. It also needs more complex control units for logical control and scheduling.
The CPU excels in management and scheduling. However, its actual workload capabilities are not as strong (the ALU accounts for about 5%~20%).
If we consider a processor as a restaurant, the CPU is like a versatile restaurant with dozens of senior chefs. This restaurant can prepare any cuisine, but because of the variety, it takes a long time to coordinate and prepare, resulting in slower service.
On the other hand, the GPU is entirely different.
GPUs are designed for graphics processing, with very clear and singular tasks. Their job is to render graphics. Graphics are composed of a massive number of pixels, which are highly uniform types of large-scale data that are independent of each other.
Thus, the task of the GPU is to complete massive parallel computations of homogeneous data in the shortest time possible. The so-called scheduling and coordination “housekeeping” tasks are minimal.
Parallel computing, of course, requires more cores.
As shown in the previous image, the number of cores in a GPU far exceeds that of a CPU, reaching thousands or even tens of thousands (hence referred to as “many-core”).
RTX4090 has 16384 streaming processors.
The cores of the GPU are called Streaming Multi-processors (SM), which are independent task processing units.
Within the entire GPU, multiple streaming processing areas are defined. Each processing area contains hundreds of cores. Each core is akin to a simplified version of a CPU, capable of integer and floating-point operations, as well as queuing and result collection functions.
The control unit of the GPU is simple, and it has relatively little cache. Its ALU can account for more than 80%.
Although the processing capability of a single GPU core is weaker than that of a CPU, the sheer number makes it very suitable for high-intensity parallel computing. Under the same transistor scale conditions, its computing power is actually greater than that of a CPU.
Using the restaurant analogy again, the GPU resembles a restaurant with thousands of junior chefs specializing in a single type of cuisine. It can only prepare a specific type of dish. However, because there are so many chefs and the preparation is simple, they can cook and serve quickly.
█ ASIC (Application-Specific Integrated Circuit)
As mentioned in the previous article, while GPUs have strong parallel computing capabilities, they also have drawbacks: high power consumption, large size, and high cost.
Entering the 21st century, the demand for computing power has shown two significant trends: first, the application scenarios for computing power have begun to diversify; second, users’ requirements for computing performance have increased. General-purpose computing chips can no longer meet user needs.
As a result, more and more companies have begun to strengthen their research and investment in specialized computing chips. ASIC (Application Specific Integrated Circuit) is a chip designed specifically for particular tasks.
The official definition of ASIC is: integrated circuits designed and manufactured specifically to meet the requirements of a particular user or specific electronic system.
ASIC began in the 1970s-1980s. In the early days, it was used in computers. Later, it became mainly used for embedded control.In recent years, as mentioned earlier, it has risen to be used in AI inference, high-speed searching, and visual and image processing.
Speaking of ASIC, we must mention Google’s famous TPU.
TPU, or Tensor Processing Unit, is a processing unit designed specifically for tensor operations. A tensor is a mathematical entity that contains multiple numbers (multi-dimensional arrays).
Currently, almost all machine learning systems use tensors as their basic data structure. Therefore, we can simply understand the tensor processing unit as an “AI processing unit.”
In 2015, to better accomplish its deep learning tasks and enhance AI computing power, Google launched a chip specifically for neural network training, known as TPU v1.
Compared to traditional CPUs and GPUs, TPU v1 can achieve a performance improvement of 15-30 times in neural network computing, with energy efficiency improvements reaching 30-80 times, causing a significant impact on the industry.
In 2017 and 2018, Google continued to improve, launching the more powerful TPU v2 and TPU v3 for AI training and inference. In 2021, they released TPU v4, which uses a 7nm process with 22 billion transistors, achieving a tenfold performance improvement over the previous generation, outperforming NVIDIA’s A100 by 1.7 times.
Besides Google, many large companies have also been developing ASICs in recent years.
In late 2019, Intel acquired the Israeli AI chip company Habana Labs, and in 2022, it launched the Gaudi 2 ASIC chip. IBM Research released the AI ASIC chip AIU at the end of 2022.
Samsung also developed ASICs a few years ago, initially for mining machines. Many people recognize ASICs from Bitcoin mining. Compared to mining with GPUs and CPUs, ASIC miners are more efficient and consume less power.
In addition to TPU and mining machines, two other well-known types of ASIC chips are DPU and NPU.
DPU stands for Data Processing Unit, mainly used in data centers. I previously introduced it specifically; you can find it here: What is DPU, which has become popular online?
NPU, or Neural Processing Unit, simulates human neurons and synapses at the circuit level and processes data using deep learning instruction sets.
NPU is specifically used for neural network inference, enabling efficient operations like convolution and pooling. It is often integrated into mobile chips.
Speaking of mobile chips, it is worth mentioning that the main chip in our mobile phones, commonly referred to as SoC chips, is also a type of ASIC chip.
What are the advantages of ASIC as a customized chip? Is it just for exclusive use by companies, with unique logos and names?
Customization means tailoring to specific needs. Based on the specific tasks the chip is designed for, the chip’s computing power and efficiency are strictly matched to the task algorithms. The number of cores, the ratio of logical computing units to control units, and cache, as well as the entire chip architecture, are all precisely customized.
Therefore, custom ASICs can achieve extreme compactness and power efficiency. The reliability, confidentiality, computing power, and energy efficiency of such chips are generally superior to general-purpose chips (CPUs, GPUs).
You will notice that the ASIC companies mentioned earlier are all large firms like Google, Intel, IBM, and Samsung.
This is because custom chip design requires a very high level of R&D technology from a company and involves substantial costs.
Developing an ASIC chip involves a complex design process, including code design, synthesis, backend processing, and several months of manufacturing and packaging testing before the chip can be obtained for system construction.
You may have heard of “tape-out.” Like a production line, manufacturing a chip through a series of processes is called tape-out. In simple terms, it refers to trial production.
The R&D process of ASIC requires tape-out. For 14nm processes, a tape-out costs around $3 million. For 5nm processes, it can go as high as $47.25 million.
If a tape-out fails, all the money is wasted, along with a significant amount of time and effort. Generally, small companies cannot afford this.
So, does this mean that small companies cannot customize chips?
Of course not. Next, we introduce another powerful tool: FPGA.
█ FPGA (Field Programmable Gate Array)
FPGA stands for Field Programmable Gate Array.
FPGA has been very popular in the industry in recent years, even surpassing ASIC in momentum, and is often referred to as the “universal chip.”
In simple terms, an FPGA is a reconfigurable chip. It can be repeatedly programmed after manufacturing to achieve desired digital logic functions according to user needs.
The reason FPGA can achieve DIY is due to its unique architecture.
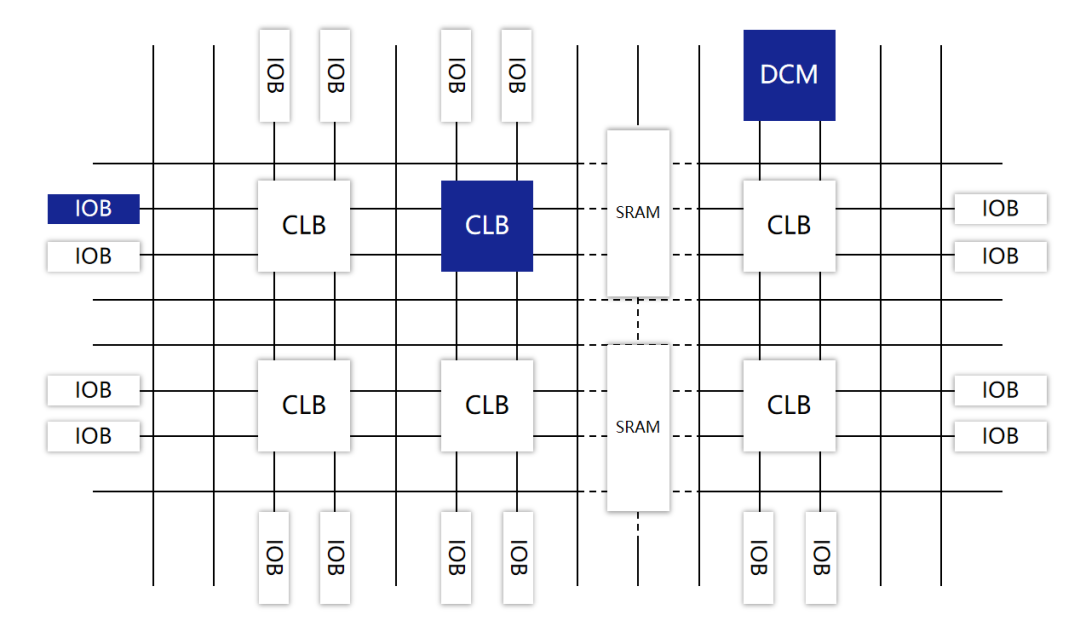
FPGAs consist of three types of programmable circuits: Configurable Logic Blocks (CLB), Input/Output Blocks (IOB), Programmable Interconnect Resources (PIR), and static RAM (SRAM).
CLB is the most crucial part of the FPGA, serving as the basic unit for implementing logical functions, carrying the main circuit functions.
They are typically arranged in an array (Logic Cell Array, LCA) scattered throughout the chip.
IOB mainly interfaces the chip’s logic with external pins, usually arranged around the chip’s perimeter.
PIR provides abundant wiring resources, including horizontal and vertical mesh wiring, programmable switch matrices, and programmable connection points. They serve to connect and form circuits for specific functions.
Static RAM (SRAM) is used to store programming data for the internal IOB, CLB, and PIR, controlling them to complete the system’s logical functions.
CLB itself primarily consists of Look-Up Tables (LUT), multiplexers, and flip-flops. They are used to implement individual logical “gates” in circuits, enabling complex logical functions.
In simple terms, we can think of a LUT as RAM that stores computation results. When a user describes a logic circuit, the software calculates all possible results and writes them into this RAM. Each signal’s logical operation is equivalent to inputting an address to look up the table. The LUT finds the content corresponding to the address and returns the result.
This “hardware-based” computation method clearly offers faster computation speed.
When using FPGA, users can complete circuit design using hardware description languages (Verilog or VHDL) and then “program” (burn) the FPGA, loading the design onto the FPGA to achieve the desired functionality.
Upon powering up, the FPGA reads data from the EEPROM (Electrically Erasable Programmable Read-Only Memory) into SRAM, and once configured, the FPGA enters operational mode. Upon power loss, the FPGA reverts to a blank state, and the internal logic relationships disappear. This cycle repeats, achieving “on-site” customization.
FPGA’s capabilities are significant. In theory, if the scale of gate circuits provided by an FPGA is large enough, it can implement any logic function of an ASIC through programming.
FPGA Development Kit, the FPGA chip is in the middle.
Let’s take a look at the development history of FPGA.
FPGA is a product developed based on programmable devices like PAL (Programmable Array Logic) and GAL (Generic Array Logic), belonging to a type of semi-custom circuit.
It was invented in 1985 by Xilinx. Later, companies like Altera, Lattice, and Microsemi also entered the FPGA field, eventually forming a landscape dominated by four giants.
In May 2015, Intel acquired Altera for a staggering $16.7 billion, integrating it into its PSG (Programmable Solutions Group) division.
In 2020, Intel’s competitor AMD also made a move, acquiring Xilinx for $35 billion.
Thus, the four major players became Xilinx (under AMD), Intel, Lattice, and Microsemi (same game, different names).
As of 2021, the market shares of these four companies were 51%, 29%, 7%, and 6%, collectively accounting for 93% of the global total.
Recently, in October 2023, Intel announced plans to spin off the PSG division for independent business operations.
Domestic FPGA manufacturers include Fudan Microelectronics, Unisoc, Anlu Technology, Dongtu Technology, Gaoyun Semiconductor, Jingwei Qili, Jingwei Yoga, Zhiduojing, and Aoge Core, among others. While there seem to be many, the technological gap is significant.
█ Differences Between ASIC and FPGA
Next, we focus on the differences between ASIC and FPGA, as well as their distinctions from CPUs and GPUs.
ASIC and FPGA are essentially chips. ASIC is a fully customized chip with fixed functions that cannot be modified. FPGA is a semi-custom chip with flexible functions and high playability.
We can still illustrate the differences between the two through an example.
ASIC is like making toys using molds. It requires mold opening beforehand, which is quite labor-intensive. Moreover, once the mold is opened, it cannot be modified. If you want to make a new toy, you must open a new mold.
FPGA, on the other hand, is like building toys with LEGO bricks. You can start building right away, and with a little time, you can complete it. If you’re not satisfied or want to build a new toy, you can take it apart and rebuild it.
Many design tools for ASIC and FPGA are similar. In terms of the design process, FPGA is less complex than ASIC, removing some manufacturing processes and additional design verification steps, typically only 50%-70% of the ASIC process. The most complex tape-out process is not required for FPGA.
This means that developing an ASIC can take several months or even over a year, while FPGA only takes a few weeks or months.
As mentioned, since FPGA does not require tape-out, does it mean that FPGA’s costs are always lower than ASIC?
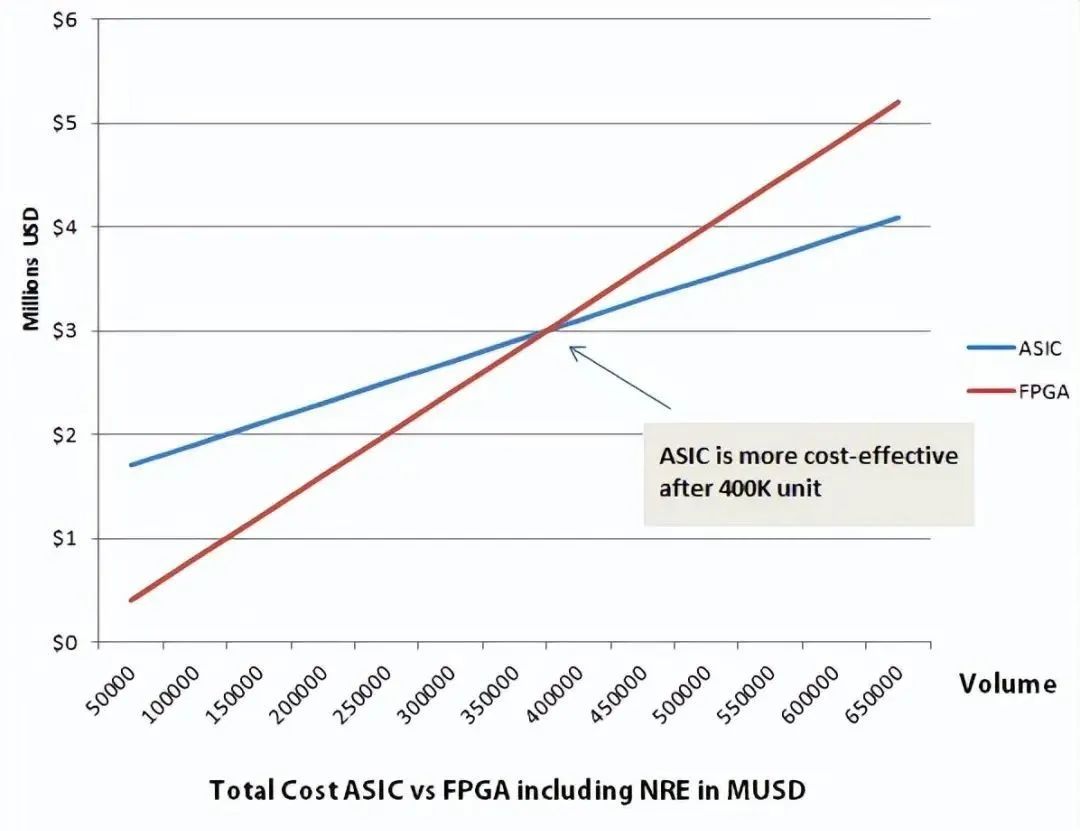
FPGAs can be prefabricated and programmed in laboratories or on-site without incurring non-recurring engineering (NRE) costs. However, as a “universal toy,” its cost is ten times that of ASIC (the molded toy).
If production volumes are low, FPGA will be cheaper. If production volumes are high, the one-time engineering costs of ASIC are spread out, making ASIC cheaper.
This is like the cost of opening a mold. Opening a mold is expensive, but if the sales volume is large, it becomes cost-effective.
As shown in the diagram, 40W chips are a dividing line for the costs of ASIC and FPGA. If the volume is less than 40W, FPGA is cheaper. If more than 40W, ASIC is cheaper.
From the perspective of performance and power consumption, as a dedicated custom chip, ASIC is stronger than FPGA.
FPGA is a general-purpose editable chip with more redundant functions. No matter how you design it, some components will be surplus.
As mentioned earlier, ASIC is tailored and has no waste, using hard wiring. Thus, it has stronger performance and lower power consumption.
FPGA and ASIC are not in a simple competitive or substitutive relationship, but have different positioning.
FPGA is now mainly used for product prototyping, design iteration, and some low-volume specific applications. It is suitable for products that require short development cycles. FPGA is also often used for ASIC validation.
ASIC is used for designing large-scale, complex chips or mature products with high production volumes.
FPGA is particularly suitable for beginners to learn and participate in competitions. Many universities with electronic majors now use FPGA for teaching.
From a commercialization perspective, the primary application fields for FPGA include communications, defense, aerospace, data centers, medical, automotive, and consumer electronics.
FPGA has been used early in the communications field. Many processing chips in base stations (baseband processing, beamforming, antenna transceivers, etc.) use FPGAs. Core network encoding and protocol acceleration also utilize them. Data centers previously used them in components like DPUs.
Later, as many technologies matured and stabilized, communication equipment manufacturers began to replace them with ASICs to reduce costs.
It is worth noting that the recently popular Open RAN often employs general-purpose processors (Intel CPUs) for computation. This approach’s energy consumption is far inferior to that of FPGAs and ASICs. This is one of the main reasons why equipment manufacturers like Huawei are reluctant to follow Open RAN.
In the automotive and industrial sectors, the advantages of FPGA in terms of latency are valued, making it useful in ADAS (Advanced Driver Assistance Systems) and servo motor drives.
FPGA is used in consumer electronics because product iterations are too fast. The development cycle of ASICs is too long; by the time a product is ready, it may no longer be relevant.
█ Which is the Most Suitable AI Chip: FPGA, ASIC, or GPU?
Finally, let’s return to the topic of AI chips.
In the previous issue, I dropped a hint that AI computation is divided into training and inference. Training is where GPUs are in an absolute leading position, while inference is not. I did not explain the reason.
First, remember that purely from a theoretical and architectural perspective, the performance and cost of ASICs and FPGAs are definitely superior to CPUs and GPUs.
CPUs and GPUs follow the von Neumann architecture, where instructions must go through storage, decoding, execution, etc., and share memory, requiring arbitration and caching during use.
In contrast, FPGAs and ASICs do not follow the von Neumann architecture (they utilize Harvard architecture). Taking FPGA as an example, it is essentially an instruction-free architecture that does not require shared memory.
The functional units of FPGA are determined during programming, essentially using hardware to implement software algorithms. For state retention needs, the registers and on-chip memory (BRAM) in FPGA belong to their respective control logic, eliminating the need for arbitration and caching.
From the perspective of the proportion of ALU operation units, GPUs have a higher proportion than CPUs, and FPGAs, having almost no control modules, have an even higher proportion of ALU operation units than GPUs.
Thus, considering all angles, the computational speed of FPGAs will be faster than that of GPUs.
Now, let’s look at power consumption.
GPUs are notorious for their high power consumption, with a single chip consuming up to 250W or even 450W (RTX4090). In contrast, FPGAs typically consume only 30-50W.
This is mainly due to memory access. The memory interfaces of GPUs (GDDR5, HBM, HBM2) have very high bandwidth, approximately 4-5 times that of traditional DDR interfaces for FPGAs. However, in terms of the chip itself, the energy consumed to read DRAM is over 100 times that of SRAM.
Moreover, FPGAs operate at lower work frequencies (below 500MHz) compared to CPUs and GPUs (1-3GHz), which further reduces their power consumption. The low operating frequency of FPGAs is mainly limited by wiring resources. Some connections need to be routed longer, and if the clock frequency is too high, it cannot keep up.
Finally, let’s consider latency.
GPUs generally have higher latency than FPGAs.
GPUs typically need to divide different training samples into fixed-size “Batches” to maximize parallelism, requiring several Batches to be gathered before processing them together.
FPGA’s architecture is batch-less. As soon as a data packet is processed, it can be output immediately, providing an advantage in latency.
So, the question arises: if GPUs are inferior to FPGAs and ASICs in several aspects, why have they become the current hot topic in AI computation?
It’s simple: in the extreme pursuit of computing power performance and scale, the entire industry simply does not care about costs and power consumption.
Thanks to NVIDIA’s long-term efforts, the number of cores and operating frequency of GPUs has been continuously improved, and the chip area has also increased, focusing on raw computing power. Power consumption is managed through manufacturing processes and passive cooling methods, as long as it doesn’t catch fire.
In addition to hardware, in the previous article, I mentioned that NVIDIA has been very strategic in software and ecosystem development.
They have developed CUDA, which is a core competitive advantage for GPUs. Based on CUDA, beginners can quickly get started with GPU development. They have cultivated a strong user base over the years.
In contrast, FPGA and ASIC development are still too complex and not suitable for widespread adoption.
In terms of interfaces, while GPUs have relatively simple interfaces (mainly PCIe) and are not as flexible as FPGAs (FPGA’s programmability allows it to easily interface with any standard and non-standard interface), they are sufficient for servers, allowing for plug-and-play use.
In addition to FPGAs, the reason ASICs have not been able to compete with GPUs in AI is largely due to their high costs, long development cycles, and significant development risks. AI algorithms are changing rapidly, making ASIC’s development cycles very critical.
Considering all these reasons, GPUs have achieved their current favorable position.
In AI training, the computing power of GPUs is strong, significantly enhancing efficiency.
In AI inference, the input is usually a single object (like an image), so the requirements are lower, and parallelism is not as necessary, making the computing power advantage of GPUs less pronounced. Many companies will start adopting cheaper and more energy-efficient FPGAs or ASICs for computation.
Other computing scenarios are similar. For those focusing on absolute computing performance, GPUs are the first choice. For scenarios where computing performance requirements are not as high, FPGAs or ASICs can be considered to save costs.
This concludes our discussion on the knowledge of CPUs, GPUs, FPGAs, and ASICs.
They are typical representatives of computing chips. Currently, all computing power scenarios are primarily handled by them.
As the times change, computing chips are also evolving with new trends. For example, different computing chips are mixed and matched to leverage each other’s advantages. We refer to this approach as heterogeneous computing.Additionally, IBM is leading the development of brain-like chips that simulate the brain’s neural synapses and processing processes, achieving breakthroughs and gaining popularity.In the future, I will introduce this topic separately.
I hope this series of articles on chips by Xiaozhao has been helpful to everyone. If you like it, please follow, share, and like.
1. “Understanding the Concept and Working Principle of GPU,” Open Source LINUX;
2. “Overview of AI Chip Architecture,” Zhihu, Garvin Li;
3. “What Are the Differences Between GPU, FPGA, and ASIC?” Zhihu, Hu Shuo Mantan;
4. “In-Depth Understanding of GPU, FPGA, and ASIC,” Automotive Industry Frontline Observation;
5. “Why GPU Is the Core of Computing Power in the AI Era,” Muxi Integrated Circuits;
6. “An Overview of the Three Main Chip Architectures for Autonomous Driving,” Digital Transformation;
7. “AI Computing Power Landscape and Trend Report,” Quantum Bit;
8. Baidu Encyclopedia, Wikipedia.