In 1966, Micheal Flynn classified computer architectures based on the concepts of instruction and data streams, known as Flynn’s taxonomy. Flynn categorized computers into four basic types as follows:
-
Single Instruction Single Data (SISD) systems
-
Single Instruction Multiple Data (SIMD) systems
-
Multiple Instruction Single Data (MISD) systems
-
Multiple Instruction Multiple Data (MIMD) systems
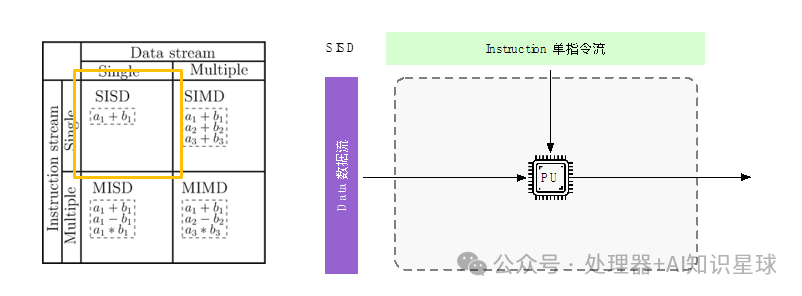
Single Instruction Single Data (SISD)
As the name suggests, there is only one processor and one memory, where each instruction unit decodes only one instruction at a time, and provides only one piece of data to the operation unit during execution. It performs serial computation, and the hardware does not support parallel computation; within a clock cycle, the CPU can only process one data stream. To improve speed:
-
Pipelining is used;
-
Multiple functional units are set up, making it a superscalar processor;
-
Memory is organized in a multi-module crossbar manner (low-order interleaved addressing of memory).
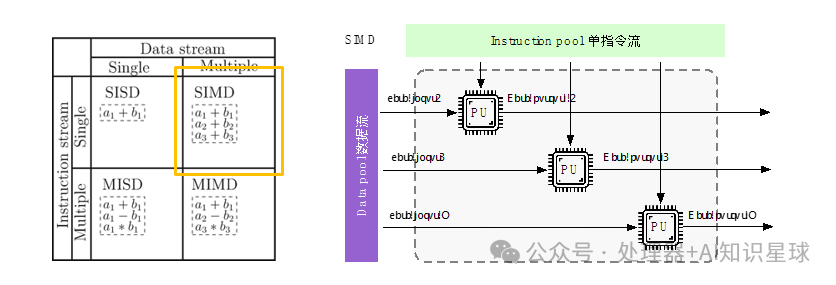
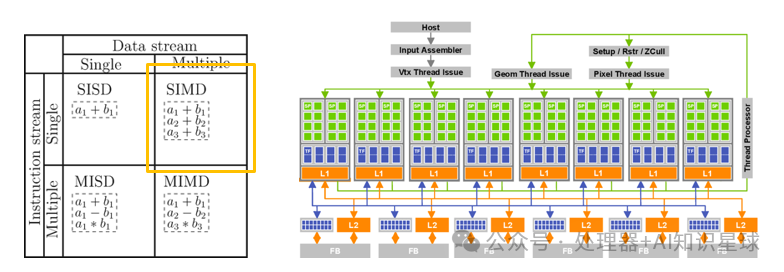
Single Instruction Multiple Data (SIMD)
The Single Instruction Multiple Data (SIMD) system uses one controller to control multiple processors, executing the same operation on each element of a set of data. SIMD primarily performs operations on vectors, matrices, and other arrays, with a fixed number of processing units, making it suitable for scientific computing. Its characteristic is that the number of processing units is large, but their speed is limited by the communication bandwidth of the computer. A single instruction stream processes multiple data streams simultaneously, known as data-level parallelism. Each instruction sequence can only be concurrent, not parallel. One instruction controls multiple processing units, with each execution unit having its own set of registers, local memory, and address registers.
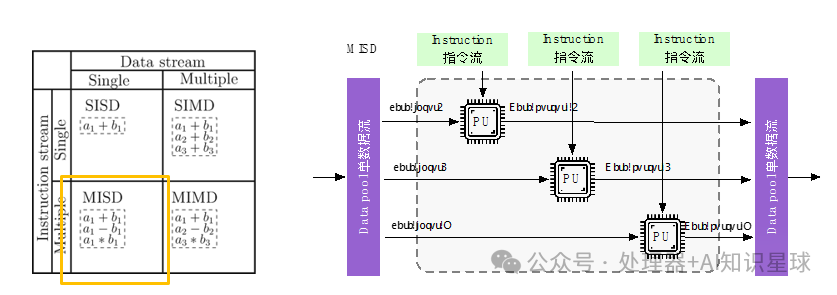
Multiple Instruction Single Data (MISD)
The Multiple Instruction Single Data machine uses multiple instruction streams to process a single data stream. This approach is unnecessary, so it only exists as a theoretical model and has not been implemented in practical applications.
Multiple Instruction Multiple Data (MIMD)
The Multiple Instruction Multiple Data (MIMD) system is a multiprocessor machine that executes multiple instructions on multiple data sets, with shared memory MIMD and distributed memory. Its characteristic is that processors can access the same main memory through LOAD/STORE instructions and can transfer data through the main memory. The hardware configuration consists of multiple processors and a single main memory within a computer. Multiple processors share a single physical address space.
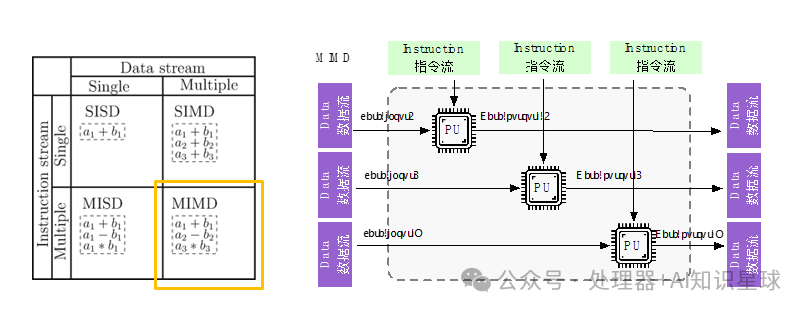
MIMD systems can be divided into shared memory systems and distributed memory systems. In shared memory systems, processors are connected to memory through an interconnect network, allowing implicit communication between processors and shared memory. In distributed memory systems, each processor has its own private memory space and communicates through an interconnect network (explicit communication), as shown in the figure below:
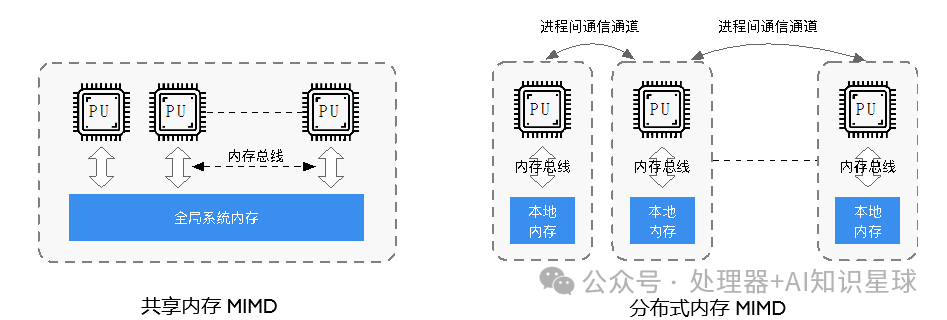
Single Instruction Multiple Threads (SIMT)
SIMT, translated as Single Instruction Multiple Threads, is primarily used in GPUs. From a hardware perspective, GPUs are essentially the same as the previously mentioned SIMD, both having a small number of instruction units driving a large number of computation units.
However, NVIDIA aims to address two pain points of SIMD. First, in the design of the instruction set, instructions still resemble SISD, where several operands represent a multi-operand operation, but during execution, the scheduler allocates many sets of computational elements and registers to this instruction.
The first benefit of this approach is that such executable code can be compiled from a programming model similar to high-level language multithreading, which is CUDA, thus addressing the first pain point. To the user, the aforementioned “set of computational elements and registers” appears like a thread, hence this model is referred to as SIMT.
Additionally, NVIDIA provides many modifiers for these instructions, such as a Bit Mask that can specify which threads perform work and which remain idle, allowing SIMT to effectively support branching statements, thus resolving the second pain point.
In summary, NVIDIA’s intention in proposing SIMT is to achieve hardware efficiency similar to SIMD while making programming as easy as multicore multithreading.
 (The above content is organized from the Bilibili expert ZOMI, welcome to follow!)
(The above content is organized from the Bilibili expert ZOMI, welcome to follow!)