1. Introduction
1. Introduction
Webshells are malicious scripts used by hackers to attack websites. Identifying webshell files or communication traffic can effectively prevent further attacks by hackers. Currently, the detection methods for webshells are mainly divided into three categories: static detection, dynamic detection, and log detection. Static detection analyzes webshell files and extracts their coding rules to detect webshell files; this is currently the most commonly used method. Domestic and international webshell identification software such as Kaspersky, D-Shield, Security Dog, and Hippo Webshell all use static detection methods. However, due to the continuous evolution of webshells to bypass detection, the biggest problem with static detection is its inability to combat obfuscated or encrypted webshells and to identify unknown webshells. Dynamic detection monitors the execution of sensitive functions in the code to detect whether webshell files exist, but it faces significant issues regarding performance loss and compatibility due to the involvement of extensions and hooking technology, making it difficult to promote large-scale applications. Log detection primarily judges based on the communication behavior of webshells, and compared to the above two detection methods, it not only has good detection results but also does not have compatibility issues.
Whether static or dynamic detection targets webshell files, ultimately, they are all aimed at detecting specific strings, which inevitably involves string obfuscation and encryption, leading to missed or false positives. Log detection is a type of traffic detection method, so this article mainly implements webshell detection based on traffic. Currently, traffic-based detection still faces some challenges. On one hand, existing webshell connection tools, such as IceScorpion, Godzilla, and AntSword, have all adopted obfuscation or encryption mechanisms to bypass traditional security device detection by encrypting communication traffic, making string matching detection methods difficult to apply in encrypted scenarios. On the other hand, as people’s awareness of network security increases, so does their awareness of data protection, leading to a growing trend of encrypted traffic. The proportion of HTTPS traffic on websites has been increasing year by year, yet there are still no good solutions for webshell detection in HTTPS.
In the article titled [Effective Research on Webshell Detection in HTTPS Encrypted Traffic], we explored the detection of webshells in HTTPS, particularly focusing on IceScorpion. This article further studies several common types of encrypted webshells based on HTTP and HTTPS traffic, extracting content features and statistical features to identify the communication traffic of webshell connection tools and propose feasible detection solutions.
2. Detection of Encrypted Webshells in HTTP
2. Detection of Encrypted Webshells in HTTP
Compared to normal website access traffic, the communication traffic of encrypted webshell clients in HTTP shows some differences, such as a relatively large feature index of webshells, higher information entropy, longer post_data length but lower overlap index, and partial strings being base64 encoded, etc. Based on these differences, we can extract corresponding features to detect the communication traffic of encrypted webshells from HTTP.
We collected communication traffic from webshell clients and normal access traffic through attack simulation targeting encrypted webshells in HTTP. After preprocessing, we extracted textual features and statistical features based on the characteristics of webshell communication traffic and input them into a random forest model for training. Finally, we used cross-validation to prove the model’s effectiveness.
2.1 Data Preprocessing

The sample data consists of three parts, each separated by a tab key. The first part indicates the classification of the current data, using 0 or 1, where a value of 1 indicates a webshell. The second part is the URI, and the third part is the post_data.
In order to obtain a more organized dataset, we performed invalid data filtering, URI decoding, and base64 decoding on post_data as preprocessing operations.
2.2 Feature Extraction
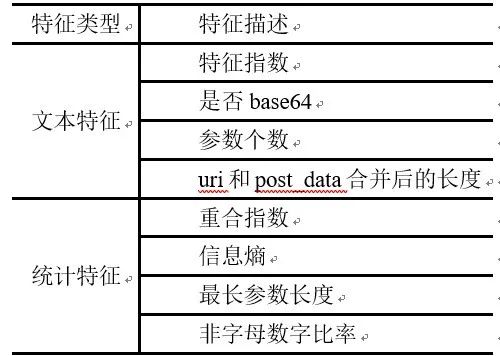
Using machine learning methods to construct a traffic-based detection model, one of the key steps is feature extraction. We selected 8-dimensional features, including 4 text features and 4 statistical features, based on the characteristics of traffic generated by webshell connections and expert knowledge, as shown in Table 1.
Table 1: Features Extracted for the Webshell Detection Model in HTTP
2.3 Model Training and Testing
After completing feature extraction from the samples, we used the feature matrix and labeling results as input and expected output to train the classifier. This article chose the random forest model to learn from the sample feature data. The random forest is a classification algorithm that utilizes multiple decision trees for training, has the ability to analyze complex features, exhibits good robustness to noisy data, provides certain interpretability, and has a fast learning speed.
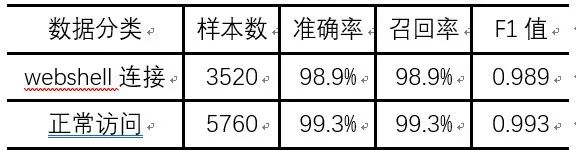
To verify the effectiveness of the random forest classification model, we used a three-fold cross-validation method for data simulation and evaluated the model’s performance using accuracy, recall, and F1 score. We conducted random forest classification experiments on 3520 webshell traffic samples and 5760 normal access traffic samples, and the experimental results are shown in Table 2.
Table 2: Cross-Validation Results of the Webshell Detection Model in HTTP
3. Detection of Encrypted Webshells in HTTPS
3. Detection of Encrypted Webshells in HTTPS
Observing the traffic generated by different types of webshell clients reveals certain characteristics and differences in packet length, bidirectional flow length, and timeout reconnections. For example, AntSword only generates traffic during operations, and each operation opens a new port, resulting in fewer packets in a single flow. However, IceScorpion 3.0 automatically initiates connections at intervals even without operations, and when operations are closely spaced, it does not open a new port.
For encrypted webshells in HTTPS, we first collected connection data from different types of webshell clients through a simulated target environment, as well as real data from normal access, and performed preprocessing operations. Then, based on the differences between black and white traffic and between different types of webshells, we extracted content features and statistical features, inputting them into the LightGBM traffic recognition classification model for training, and saved the trained model. Finally, we verified the model’s detection capability using a test set, and the experimental results demonstrated the effectiveness of the method.
3.1 Data Preprocessing
To train a good model, it is necessary to construct a dataset that reflects real environments as much as possible. Due to the difficulty of obtaining HTTPS webshell attack traffic, we built a target environment and designed automated simulation attack scripts, connecting using various types of webshell clients targeting JSP and PHP web backdoors, and collected communication traffic generated by various common attack operations and malicious commands on both Windows and Linux, ultimately collecting 2.6G of traffic data.
To effectively extract features from the data, we filtered the data and used Cisco’s open-source network traffic analysis tool, Joy, to parse the collected traffic, obtaining results in JSON format. Finally, the amount of black and white sample data we obtained is shown in Table 3, with the unit being the number of bidirectional network flows after parsing the data packets.
Table 3: Data Statistics List

3.2 Feature Extraction
Since the payload of encrypted traffic is random and encrypted, we extracted four main data elements that cannot be encrypted based on observed features and experience in feature extraction from encrypted traffic, comprising over four hundred dimensions of features, which are:
(1) Data stream element features;
(2) Packet length features;
(3) Packet time interval features;
(4) Packet byte distribution features.
3.3 Model Training and Testing
Using LightGBM as the webshell traffic recognition classification model, it is a lightweight learner based on gradient boosting algorithms, with advantages such as high training efficiency, low memory usage, high accuracy, support for parallel learning, and the ability to handle large-scale data.
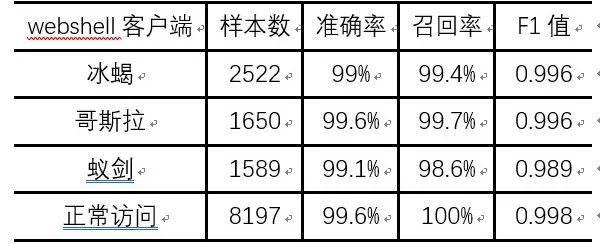
Because the data volume of different types of webshell clients varies greatly, we performed data balancing by removing a portion of the data for each type as a training set to ensure balance among types. This portion of the data can also be reserved as a test set. We randomly selected 20% of the dataset as the test set, another 20% as the validation set, and the remaining 80% as the training set. As shown in Table 4, the balanced data volume and the results of running on the test set are displayed.
Table 4: Results on the Test Set After Balancing
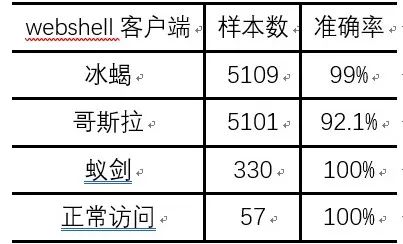
The trained model is saved, and the reserved portion of the data is tested. The testing results are shown in Table 5. It can be seen that the extracted features have good discriminability for different types of webshells and white traffic, indicating the effectiveness of the method. Among them, IceScorpion 3.0 data only participated in this test, while the training set only contained IceScorpion 2.0 data. The lower accuracy of Godzilla is because the malicious commands for Godzilla on Linux included in the test set did not appear in the training set, which only contained malicious commands on Windows. This indicates that the traffic characteristics generated by attack operations and malicious commands on Linux and Windows are not completely the same, so the training set needs to be enriched to improve the model’s generalization ability.
Table 5: Testing Results on the Reserved Dataset
4. Conclusion
4. Conclusion
This article proposes feasible detection solutions for encrypted webshells in both HTTP and HTTPS. In the future, the model will be optimized by enriching the training set and adding TLS features to continuously enhance the model’s detection capability and generalization ability, ultimately integrating with various products of the company for practical implementation.
References
Original source: Green Alliance Technology Research Communication
