

1. Introduction
1. Origin
Today, our ability to navigate the web is thanks to the vision of a computer scientist, Tim Berners-Lee. On August 6, 1991, Tim Berners-Lee officially launched the world’s first website (http://info.cern.ch) on a NeXT computer at the European Organization for Nuclear Research (CERN), establishing the basic concepts and technical framework of the Internet, thus ushering in the information age.

-
Proposed HTTP (Hypertext Transfer Protocol), allowing users to access resources by clicking on hyperlinks;
-
Proposed using HTML (Hypertext Markup Language) as the standard for creating web pages;
-
Created the Uniform Resource Locator (URL) as the website address system, which continues to use the http://www URL format today;
-
Created the first Web browser, called the World Wide Web browser, which also served as a web editor;
-
Created the first Web server (http://info.cern.ch) and the first web page describing the project itself.
2. Features
-
Supports client/server model.
-
Simple and fast: The client only needs to send the request method and path to the server when requesting services.
-
Flexible: HTTP allows for the transfer of any type of data object. The type being transferred is marked by the Content-Type (which indicates the content type in the HTTP packet).
-
Connectionless: Connectionless means that each connection only processes one request. After the server has processed the client’s request and received the client’s response, it disconnects. This method saves transmission time.
-
Stateless: Stateless means that the protocol has no memory for transaction processing; the server does not know the client’s state. After we send an HTTP request to the server, the server sends us data based on the request, but after sending, it does not record any information (Cookies and Sessions were created later, which we will discuss later).
2. TCP/IP Protocol
We often hear the phrase: HTTP is a protocol that transmits data based on the TCP/IP protocol suite.
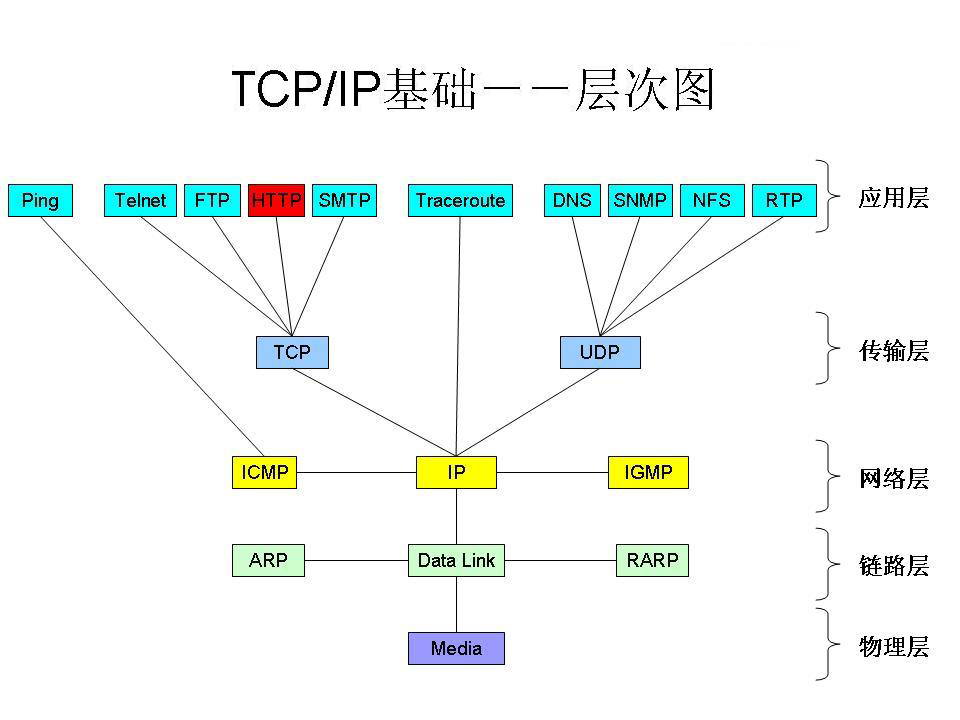
From the above diagram, we can clearly see that the transport layer protocol used by HTTP is TCP, while the network layer uses the IP protocol (of course, many other protocols are also used), so HTTP is a protocol that transmits data based on the TCP/IP protocol suite.
We can also see that ping uses the ICMP protocol, which is why sometimes we can access the internet with a VPS but cannot ping Google, as they use different protocols.
So how does the TCP/IP protocol suite generally work? Let’s take a look at the following diagram:
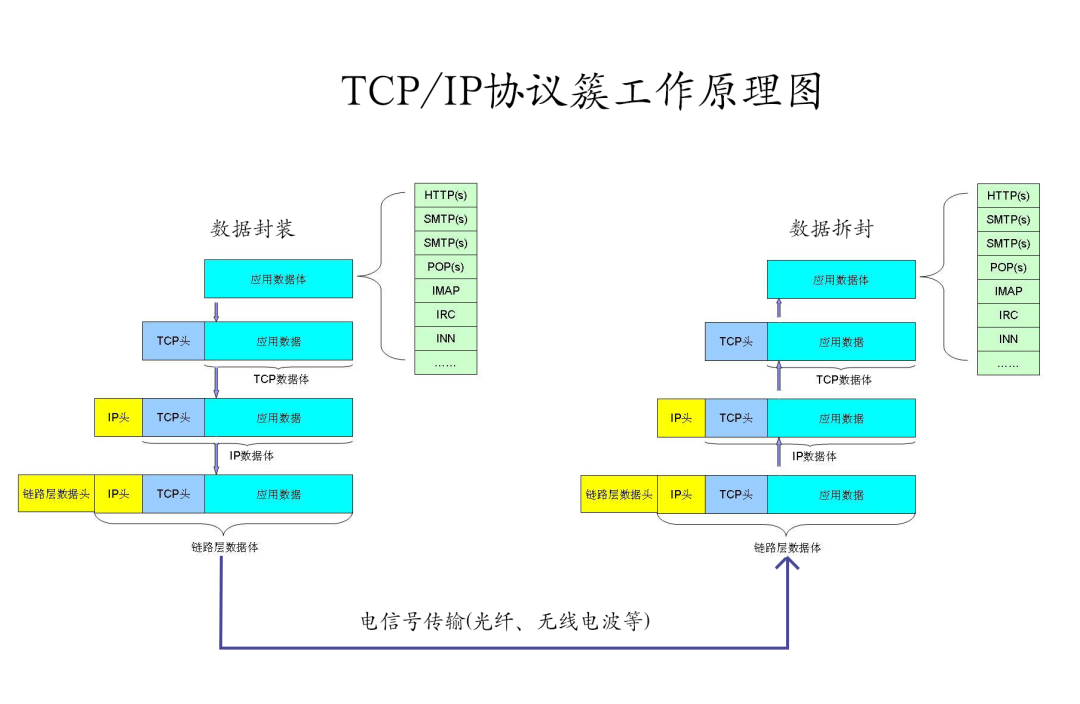
We can see that at the data sending end, data is encapsulated layer by layer, and at the data receiving end, data is unpacked layer by layer, finally reaching the application layer.
After understanding the general working principle of the TCP/IP protocol suite, let’s see how HTTP establishes a connection.
1. TCP Header Information
As we mentioned earlier, HTTP is a protocol that transmits data based on the TCP/IP protocol suite, so establishing an HTTP connection is essentially establishing a TCP connection. Let’s take a look at the structure of the TCP packet information.
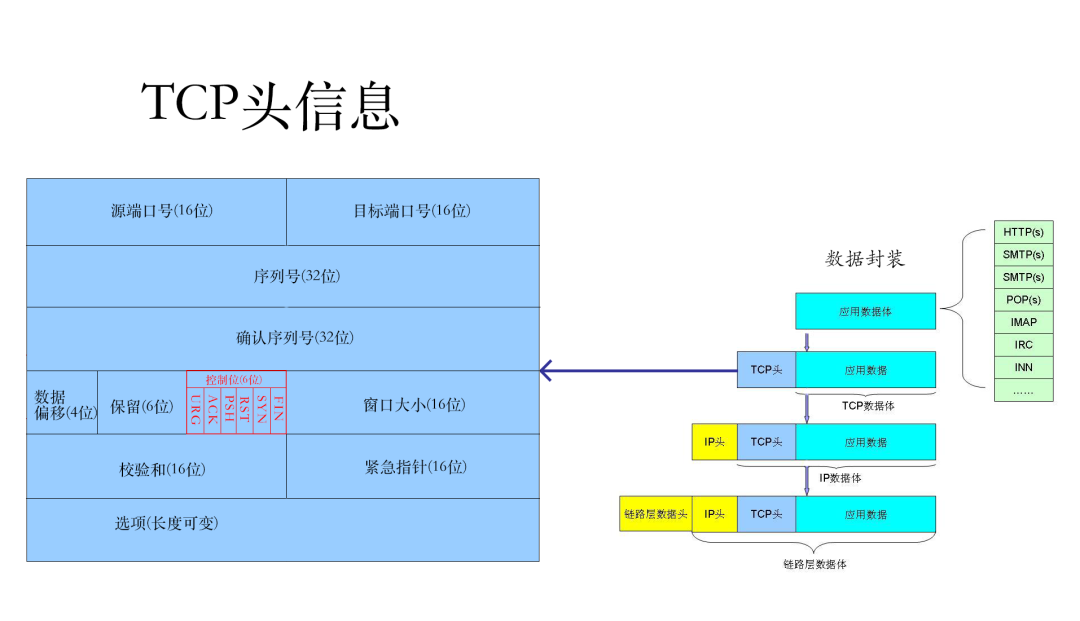
TCP Packet = TCP Header Information + TCP Data Body, and the TCP header information contains six control bits (shown in the red box in the image above), which represent the state of the TCP connection:
URG: Urgent Data (urgent data) — this is an urgent message
ACK: Acknowledgment received
PSH: Indicates that the receiving application should immediately read data from the TCP receive buffer
RST: Indicates a request to re-establish the connection
SYN: Indicates a request to establish a connection
FIN: Indicates that the sender is notifying the other party that it will close the connection
2. Connection Establishment Process
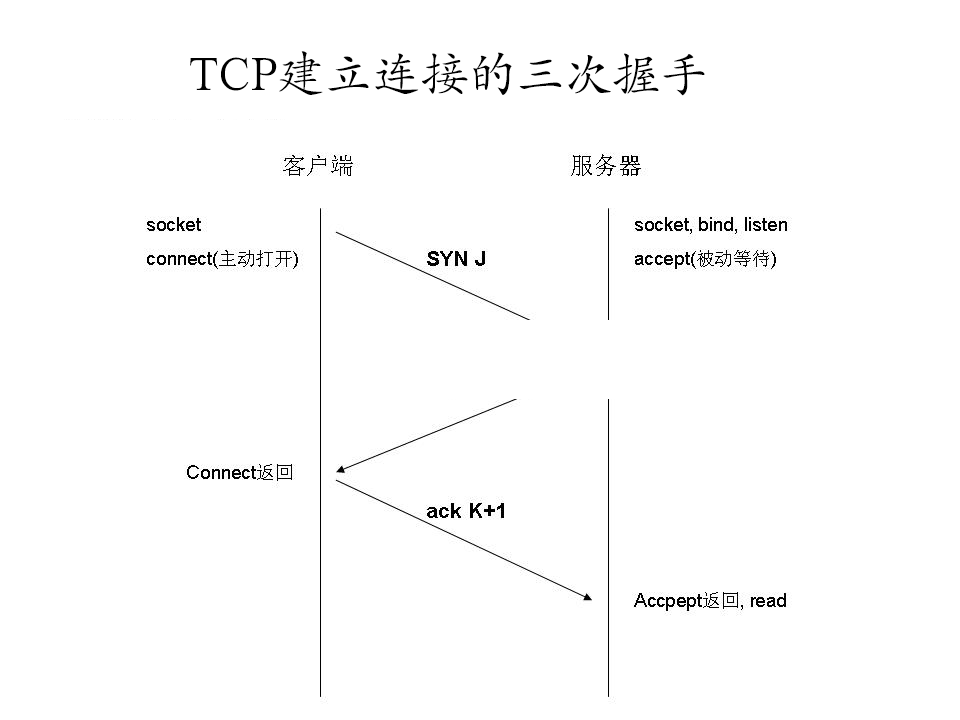
After understanding the TCP header information, we can formally look at the three-way handshake for establishing a TCP connection.
-
1 The client sends a packet with SYN=1 and a randomly generated seq number=1234567 to the server. The server knows that the client wants to establish a connection from SYN=1 (Client: I want to connect to you)
-
The server receives the request and confirms the connection information by sending a packet to A with ack number=(client’s seq+1), SYN=1, ACK=1, and a randomly generated seq=7654321 (Server: Okay, you can connect).
-
The client checks whether the ack number is correct, which is the first sent seq number +1, and whether the ACK bit is 1. If correct, the client will send ack number=(server’s seq+1), ACK=1. Once the server receives this, it confirms the seq value and ACK=1, and the connection is successfully established. (Client: Okay, I’m here)
Interviewer: Why does establishing an HTTP connection require three-way handshake, and not two or four?
Answer: Three is the minimum safe number; two is not safe, and four wastes resources.
Once the client is connected to the server, it can start requesting resources and send HTTP requests.
1. HTTP Request Message Structure
We previously mentioned that TCP Packet = TCP Header Information + TCP Data Body. Now we will discuss the TCP Data Body, which is our HTTP request message.

Let’s take a look at an actual HTTP request example:
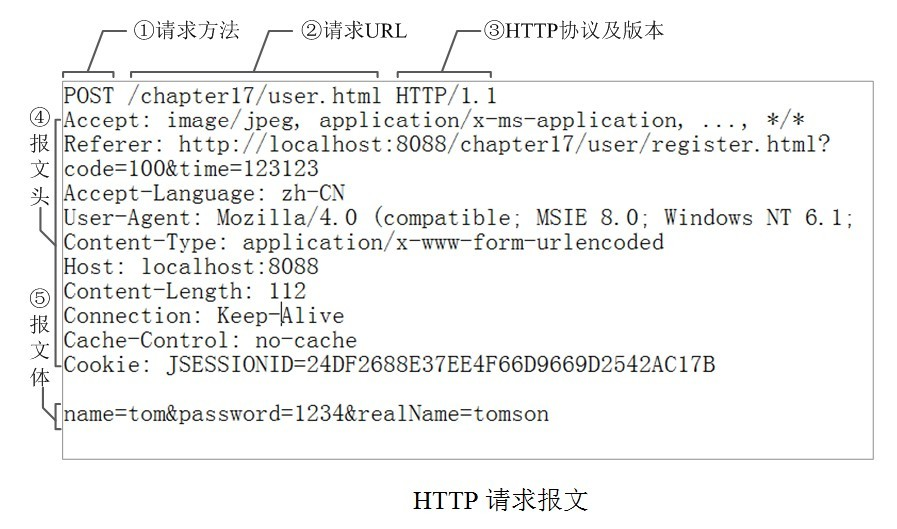
-
① This is the request method. The HTTP/1.1 defined request methods include eight types: GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, TRACE. The two most common are GET and POST. If it’s a RESTful interface, GET, POST, DELETE, and PUT are generally used.
-
② This is the corresponding URL address for the request, which, along with the Host attribute in the message header, forms a complete request URL.
-
③ This is the protocol name and version number.
-
④ This is the HTTP message header, which contains several attributes in the format of “attribute name: attribute value”. The server uses this to obtain information about the client.
-
⑤ This is the message body. It encodes the component values from a page form into a formatted string using key-value pairs like param1=value1¶m2=value2. It carries multiple request parameters. Not only can the message body transmit request parameters, but the request URL can also pass parameters in a similar manner, like “/chapter15/user.html?param1=value1¶m2=value2”.
There are many request header parameters, and I won’t explain them all; I will only mention the common ones:
-
User-Agent: The name and version of the operating system and browser used by the client. Some websites restrict requests from certain browsers. For example, WeChat refuses to process requests without a
User-Agent. -
Referer: The address of the previous webpage, indicating where this request comes from. Some websites restrict requests based on the source.
-
Accept: This is a request header indicating the file types that the current browser can accept, e.g., application/json.
-
Content-Type: This is an entity header representing the entity data type sent by the sender (client/server), e.g., application/json.
After the server receives and processes the client’s request, it needs to respond and return to the client. The structure of the HTTP response message is consistent with that of the request.
1. HTTP Response Message Structure

2. HTTP Response Example

3. Response Status Codes
In the response message, we should pay special attention to the server’s response status code, which is often asked in interviews. Below, I will only list the categories; you can find detailed status codes online to learn more.

6. Disconnecting
After the server has finished responding, one session ends. Will the connection disconnect at this point?
1. Long and Short Connections
-
In the HTTP/1.0 version, the client disconnects the previously established TCP connection after completing one request/response. When making the next request, a new TCP connection must be established again, which is known as a short connection.
-
Only half a year after the release of HTTP/1.0 (January 1997), HTTP/1.1 was released, bringing a new feature: after the client and server complete a request/response, it allows the TCP connection to remain open. This means that the next request can directly use the existing TCP connection without needing to re-establish it, which is known as a long connection.
As early as 1999, HTTP/1.1 was widely promoted, so browsers now carry a parameter in the request header: Connection: keep-alive, indicating that the browser requests a long connection with the server, which the server can also set whether it is willing to establish a long connection.
2. Advantages and Disadvantages of Long Connections
For servers, establishing long connections has both advantages and disadvantages:
-
Advantage: When a website has a large number of static resources (images, CSS, JS, etc.), long connections can be enabled, allowing multiple images to be sent through one TCP connection.
-
Disadvantage: When the client makes a request but does not request again, while the server keeps the long connection open, it occupies resources, which is a serious waste of resources.
PS: Don’t underestimate a single TCP connection; in a complete client HTTP request (DNS addressing, establishing TCP connection, requesting, waiting, parsing the webpage, disconnecting TCP connection), the time taken to establish a TCP connection is quite significant.
3. Disconnecting Process
The establishment of a TCP connection involves a three-way handshake, while disconnecting a TCP connection involves a four-way handshake!
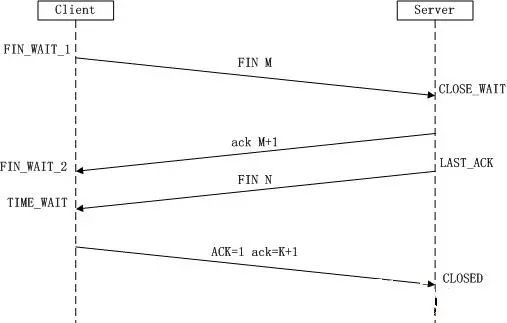
Earlier, when discussing the TCP/IP protocol, we mentioned the flag: FIN indicates that the sender is notifying the other party that it will close the connection. **Why does disconnecting require four-way handshake?** This is a homework assignment for you; feel free to leave your understanding in the comments to see if it is correct.
7. Side Notes
1. Must-know Interview Question: Three-way Handshake and Four-way Handshake of HTTP
Interviewer: Why does establishing a connection require three-way handshake while closing it requires four-way handshake? This is a homework assignment for you; please leave your insights in the comments!
HTTP/1.1 has served us for 20 years, and HTTP/2.0 was actually released in 2015, but it has not been widely adopted. You can find more information about the new features of HTTP/2.0 online.
Due to the slow response of HTTP and the large size of request headers, in the microservices era, RPC is often used to call services. Interested students can learn about RPC concepts online.
HTTP has two major drawbacks: it is in plaintext and cannot guarantee integrity, which is why it is gradually being replaced by HTTPS. I will explain HTTPS in the next issue.
