
Before learning C++, we implemented sequential lists and linked lists using C, which are the foundation of learning data structures. It’s always good to have early exposure. After learning C++, we implemented them twice again, once using classes and once using template classes. Now, let’s move on to the first topic of C++—classes.
Classes
When talking about classes, I must mention structures, but not the C language structures, rather the structures in C++. Consider the differences between the two: In C++, structures can not only store data but also functions. However, we usually prefer to use another keyword—class.
Now, let’s review the definition of a class:
class ClassName { //……
};
The keyword class is used to define a class, ClassName is the name of the class, and the body of the class is enclosed in {}. Note that a semicolon is required after the class definition. The elements in the class are called members; the data in the class is referred to as properties or member data; the functions in the class are called methods or member functions.
When summarizing classes, I noted the various member functions of a class. Let’s review them:
The constructor, destructor, copy constructor, assignment operator overload, address operator overload, and const-qualified address operator overload. Let’s focus on the first few:
The Constructor: It is a special member function that has the same name as the class. It is automatically called by the compiler when creating an object of the class type and is called only once during the object’s lifecycle to ensure that each data member has an appropriate initial value.
Constructor Characteristics: 1. The function name is the same as the class name. 2. No return value. 3. There is an initialization list (optional). 4. A new object is created, automatically called by the compiler, and called only once during the object’s lifecycle. 5. Constructors can be overloaded, with the actual parameters determining which constructor is called. 6. If not explicitly defined, the compiler provides a default constructor. 7. Both no-argument constructors and constructors with default values are considered default constructors, and there can only be one default constructor.
The Destructor: It has the opposite function of the constructor and is automatically called by the compiler when an object is destroyed to perform resource cleanup and finalization tasks.
Destructor Characteristics: 1. The destructor has a tilde character (~) added to the class name. 2. The destructor has no parameters and no return value. 3. A class has only one destructor. If not explicitly defined, the system will automatically generate a default destructor. 4. The destructor is automatically called by the C++ compiler when the object’s lifecycle ends. 5. Note that the body of the destructor does not delete the object but performs some cleanup tasks.
The Copy Constructor: It has a single parameter, which is a reference to an object of the same class (commonly const-qualified). This constructor is called a copy constructor. The copy constructor is a special constructor that initializes an object using an existing object of the same class and is automatically called by the compiler.
In this module, an important point is the shallow copy issue, which I summarized before, so let’s briefly review it:
How does the shallow copy issue arise? How can we solve this problem?
A shallow copy occurs when two objects share the same memory space after copying, leading to memory leaks when one object is released. There are three solutions: a normal version of deep copy, a simplified version, and copy-on-write.
Deep copy and copy-on-write use different methods: Deep copy allocates a new space for the copied object, fundamentally solving the problem by ensuring that two objects do not share the same memory, thus avoiding memory leaks. Copy-on-write uses a counter to indicate how many objects are using the memory space, allowing the release to be determined by checking if the counter is zero.
Let’s look at some points through diagrams:

Memory Management
In C, memory is allocated using malloc, calloc, and realloc on the heap, and released using free. So what about C++?
In C++, we generally use new to allocate memory and delete to release it; to allocate an array of memory, we use new[], and the matching release is delete[].
Key Point: new and delete, new[] and delete[] must be used in pairs; otherwise, it may lead to memory leaks or even crashes.
Differences Between malloc/free and new/delete:
1. Both are entry points for dynamic memory management. 2. malloc/free are functions in the C/C++ standard library, while new/delete are C++ operators.
3. malloc/free only allocate or release memory space. In contrast, new/delete not only allocate space but also call constructors and destructors for initialization and cleanup (member cleanup). 4. malloc/free require manual calculation of type size and return void*, while new/delete automatically calculate the type size and return pointers of the corresponding type.
Placement new Expression: The placement new expression initializes an object by calling the constructor in already allocated raw memory.
Inheritance
1. First, let’s talk about what inheritance is: Inheritance is the most important means of reuse, allowing programmers to extend and enhance functionality while maintaining the original class’s characteristics. The new class created is called a derived class.
2. Next, let’s focus on the base class and derived class in the inheritance system. These two are in an inheritance relationship, which involves inheritance permissions. There are three types of inheritance permissions: public, private, and protected. Public is the most commonly used, and in practice, we primarily use public.
3. When learning classes, we also learned about access permissions, which are also three: public, private, and protected. Before learning inheritance, the latter two had no significant differences, but after learning inheritance, they do. In a way, protected exists for the inheritance system. Let’s look at their differences:
The private members of the base class cannot be accessed in the derived class. If a base class member should not be directly accessed from outside the class but needs to be accessed in the derived class, it should be defined as protected.
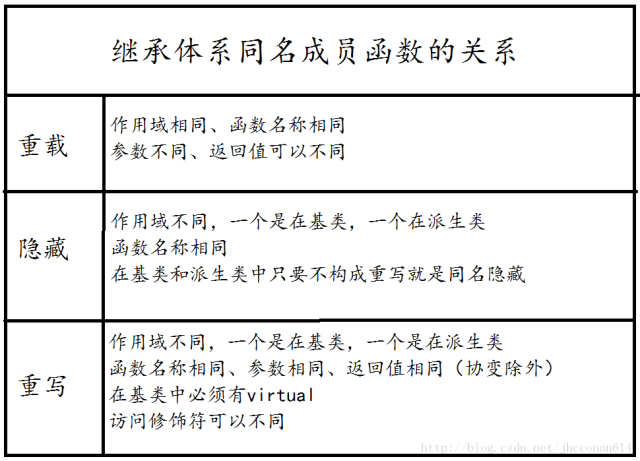
4. Next, let’s discuss a phenomenon we observed in base and derived classes: name hiding. This is similar to function overloading but different. One important difference is the scope. Name hiding occurs in the inheritance system when a member function of the base class has the same name as a function of the derived class. The base class’s member function will be hidden (it is just hidden, not deleted) when accessed.
Since the scopes of the two functions that are name hidden (redefined) are different, they will not constitute overloading.
5. Now we come to a key point in this module—Object Model.
The object model is essentially the layout of class members in memory. To understand how inheritance works, we must first know how each member is distributed in memory.
6. By the way, can friend relationships be inherited? The answer is no because friend functions are not member functions of the class.
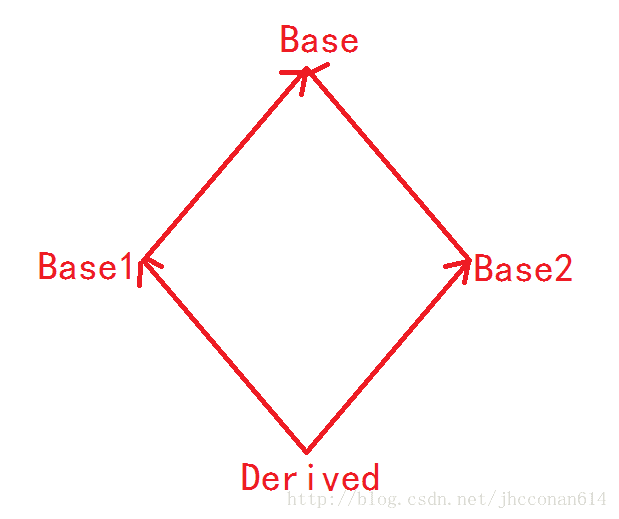
7. The above theories are based on single inheritance. There is also multiple inheritance, which brings us back to the object model. In multiple inheritance, there are multiple base classes, so how is their memory space laid out? Or what is the order of inheritance? Experimental verification shows that the order of inheritance is executed in the order written. Thus, the distribution in space is as follows.
8. Diamond inheritance: It is evident that the inheritance system presents a diamond shape, as shown in the figure:
Polymorphism
1. Types of Polymorphism: Polymorphism is divided into static polymorphism and dynamic polymorphism.
Static polymorphism is determined after compilation, such as function overloading and generic programming.
When discussing dynamic polymorphism, we must mention the conditions for dynamic binding:
First, there must be a virtual function in the base class, and it must be overridden in the derived class;
Second, virtual functions must be called through a pointer or reference of the base class type.
2. Regarding overriding, it simply means rewriting a function, but there are requirements: it must be a virtual function in the base class, and the overriding function must have the same prototype as the base function. However, there is a special case—covariant return type, which is a special case of overriding where the return type in the base class is a reference or pointer to the base class, while in the derived class, the return type can be a reference or pointer to the derived class.
At this point, we recall that in the inheritance system, there are also functions with the same prototype: one is function overloading, and the other is name hiding. Let’s look at their similarities and differences:
3. The virtual functions mentioned earlier are defined in ordinary member functions. Now, let’s look at some special member functions:
Can constructors be defined as virtual functions? Why?
We all know that the purpose of constructors is to create objects, while virtual functions are called through objects, which is contradictory. Therefore, constructors cannot be declared as virtual functions.
Can static member functions be defined as virtual functions? Why?
If defined as static member functions, they can be called using the class name and the scope resolution operator, meaning they can be called without creating an object. The use of a virtual table address must be accessed through the address of an object.
Can destructors be defined as virtual functions? Why?
If we define a variable of type Base* but call the constructor of Derived, what happens when we clean up resources?
We will find that when calling the destructor, only the destructor of the Base class will be invoked, and the destructor of the Derived class will not be called, leading to memory leaks. Therefore, we define the destructor as a virtual function to solve this problem.
4. Virtual table pointer -> Virtual table
Templates
1. Previously, when discussing static polymorphism, I gave two examples: function overloading and generic programming. We all know function overloading, and we’ve also summarized it along with redefinition and overriding, but what is generic programming?
Generic programming is writing logic code that is independent of types, and templates are the foundation of generic programming.
Templates consist of two parts: template functions and template classes.
First, let’s talk about template functions. The format is:
template<typename Param1, typename Param2,…> ReturnType FunctionName(ParameterList) {……}
2. Instantiation: When you write a generic addition function, if you treat the generic type as T, when you call the function, you achieve the purpose of calculating data of any type by instantiating the type. If you instantiate T as an int type, the result will also be int; similarly, if you instantiate it as float, char, etc., you will get results of the corresponding type.
During the template function instantiation process, implicit type conversion will not occur.
3. Template Parameters:
Template parameters can only appear once in the template parameter list. They can be either type parameters or non-type parameters, and all type parameters must be preceded by the class or typename keyword. The template parameter list cannot be empty when defining a template function. Template type parameters can be used as type specifiers in any part of the template, just like built-in or user-defined types, and can be used to specify function parameter types, return values, local variables, and forced type conversions. Default template arguments cannot be specified within the body of a function template, and explicitly specifying an empty template argument list tells the compiler that only templates can match this call, and all template parameters should be deduced from the actual arguments.
4. Template Function Specialization: Although template functions are powerful and can compute data of any type after writing the code, not all types are suitable. For example, our generic addition function template cannot compute strings. So how do we solve this? The answer is template function specialization, which has the following form:
1. The keyword template is followed by a pair of empty angle brackets <>. 2. The function name is followed by the template name and a pair of angle brackets, specifying the template parameters for this specialization. 3. The function parameter list. 4. The function body.
5. Template Classes:
-
When using class templates, we need to explicitly provide the template argument list; otherwise, the compiler cannot know the actual type.
-
Member functions of class templates can be defined within the class template definition (inline functions) or outside the class template definition (in which case the member function definition must be prefixed with template and template parameters).
-
Member functions of class templates themselves are also templates, and they are not automatically instantiated when the class template is instantiated; they are only instantiated when called or when their address is taken.
Exception Handling
1. Several Ways to Handle Exceptions in C:
1. Terminate the program (division by zero) 2. Return an error value with an error code (GetLastError()) 3. Return a valid value that puts the program in an invalid state (the problematic atoi()) 4. Call a pre-prepared function to handle “errors” (callback function). 5. A brute-force solution: abort() or exit() 6. Use of goto statement 7. Combination of setjmp() and longjmp()
2. Type-Catching: Exceptions are raised by throwing objects, and the type of that object determines which handling code is activated. The selected handling code is the one that matches the type and is closest to the thrown object in the call chain.
After an exception is thrown, local storage objects are released, so the thrown object is returned to the system. The throw expression initializes a special copy of the thrown exception object (an anonymous object), and the exception object is managed by the compiler. After passing the exception object to the corresponding catch handler, it is destroyed.
3. Stack Unwinding: Stack unwinding is the process of searching for a matching catch statement along the call chain.
When an exception is thrown, the execution of the current function is paused, and the search for a matching catch clause begins. First, it checks whether the throw is within a try block. If so, it looks for a matching catch clause. If found, it handles it; if not, it exits the current function stack and continues searching in the function stack. This process repeats until the main function’s stack is reached. If no match is found, the program terminates.
4. Sometimes a catch clause cannot handle an exception. In this case, the exception is rethrown to be handled by the outer call chain.
5. Exception Specifications:
The type of the exception object must exactly match the type specified in the catch clause. The following exceptions are allowed: 1. Conversion from non-const to const objects. 2. Conversion from derived types to base types. 3. Conversion of arrays to pointers to array types and functions to pointers to function types.
Do not throw exceptions in constructors and destructors, as this may lead to incomplete objects and resource leaks.
Smart Pointers
When we talk about smart pointers, we think of a few: auto_ptr, scoped_ptr, shared_ptr.
1. Let’s review these smart pointers. First, auto_ptr is discouraged in the library because it has issues:
First, if a pointer that has transferred ownership is used again, it will cause an error because the pointer is set to null after transferring resources. If you try to use it again, it will result in an error due to dereferencing.
Second, the copy operator accepts constants. We know that temporary objects are constant (i.e., they cannot be changed). If you use the copy operator and pass in a temporary object, as in the example, it will cause an error.
2. When discussing scoped_ptr, we must mention its characteristic: it is strict because it does not allow others to share the same memory space, meaning it does not allow copying. So, how do we prevent copying?
Previously, we provided three methods. Let’s look at them again:
-
Declare the overload of the assignment operator and the copy constructor in the class but do not provide definitions;
-
Provide definitions for the overload of the assignment operator and the copy constructor in the class but make them private;
-
Only declare the overload of the assignment operator and the copy constructor in the class and make them private.
To be honest, looking at these three solutions now, only the third one is feasible because the first two have obvious loopholes. The first one is public, so we can implement this function outside the class; the second one cannot prevent friends.
shared_ptr: Custom Deleters and Circular References
May Free Online Training Camp Early Reservation
▼

If you have any questions, quickly find Da Mei on WeChat: zdzc3087880280; Da Mei QQ: 3535503962.
Recommended Content:
What IT skills offer good salaries without educational restrictions?
Essential skills for various IT positions: A must-read for beginners!
Review! The Top 10 IT skills in recruitment rankings for 2019!
Darui Education offers free courses nationwide! (Apply in the text)
