
Hello everyone, I am Su San~~
Today I would like to discuss the SPI mechanisms of Java, Spring, and Dubbo, focusing on their principles and differences.
Actually, I have previously written a similar article, but that one mainly analyzed the source code of Dubbo’s SPI mechanism, only briefly introducing the SPI mechanisms of Java and Spring without going into depth. So, this article will delve into the principles and differences of these three.
What is SPI
SPI stands for Service Provider Interface. It is a mechanism for dynamic replacement discovery and an excellent decoupling idea. SPI allows the separation of interfaces and implementations flexibly, enabling API providers to only provide interfaces while third parties implement them. Configuration files can be used for replacement or extension, which is common in frameworks, improving the framework’s extensibility.
In simple terms, SPI is an excellent design concept centered around decoupling and ease of extension.
Java SPI Mechanism — ServiceLoader
ServiceLoader is a simple implementation of the SPI mechanism provided by Java. The implementation of Java’s SPI stipulates the following two things:
-
The file must be placed under the META-INF/services/directory. -
The file name must be the fully qualified name of the interface, and the content must be the fully qualified name of the interface implementation.
This allows the ServiceLoader to load the implementations of the interfaces from the files.
Let’s do a demo
Step one, we need an interface and its implementation class.
public interface LoadBalance {
}
public class RandomLoadBalance implements LoadBalance{
}
Step two, create a file under the META-INF/services/ directory named with the fully qualified name of LoadBalance, and the content should be the fully qualified name of RandomLoadBalance.

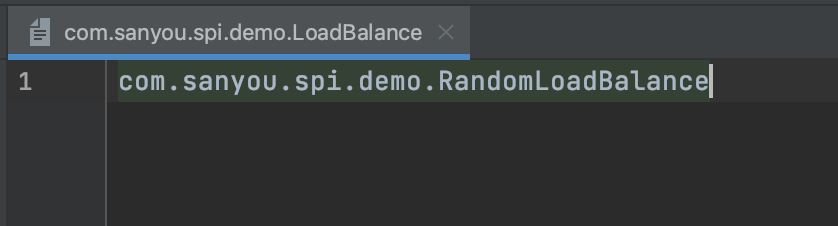
Test class:
public class ServiceLoaderDemo {
public static void main(String[] args) {
ServiceLoader<LoadBalance> loadBalanceServiceLoader = ServiceLoader.load(LoadBalance.class);
Iterator<LoadBalance> iterator = loadBalanceServiceLoader.iterator();
while (iterator.hasNext()) {
LoadBalance loadBalance = iterator.next();
System.out.println("Obtained load balancing strategy:" + loadBalance);
}
}
}
Test result:
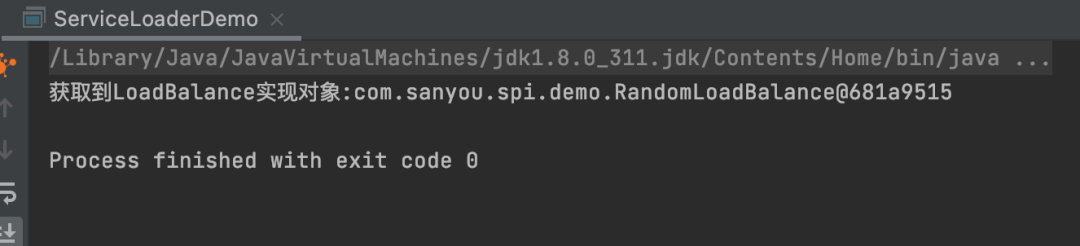
At this point, the implementation has been successfully obtained.
In actual framework design, the above test code is typically written by the framework author into the framework itself. For users of the framework, to customize the LoadBalance implementation and embed it into the framework, they only need to write the implementation of the interface and the SPI file.
Implementation Principle
Below is a core piece of code from ServiceLoader.
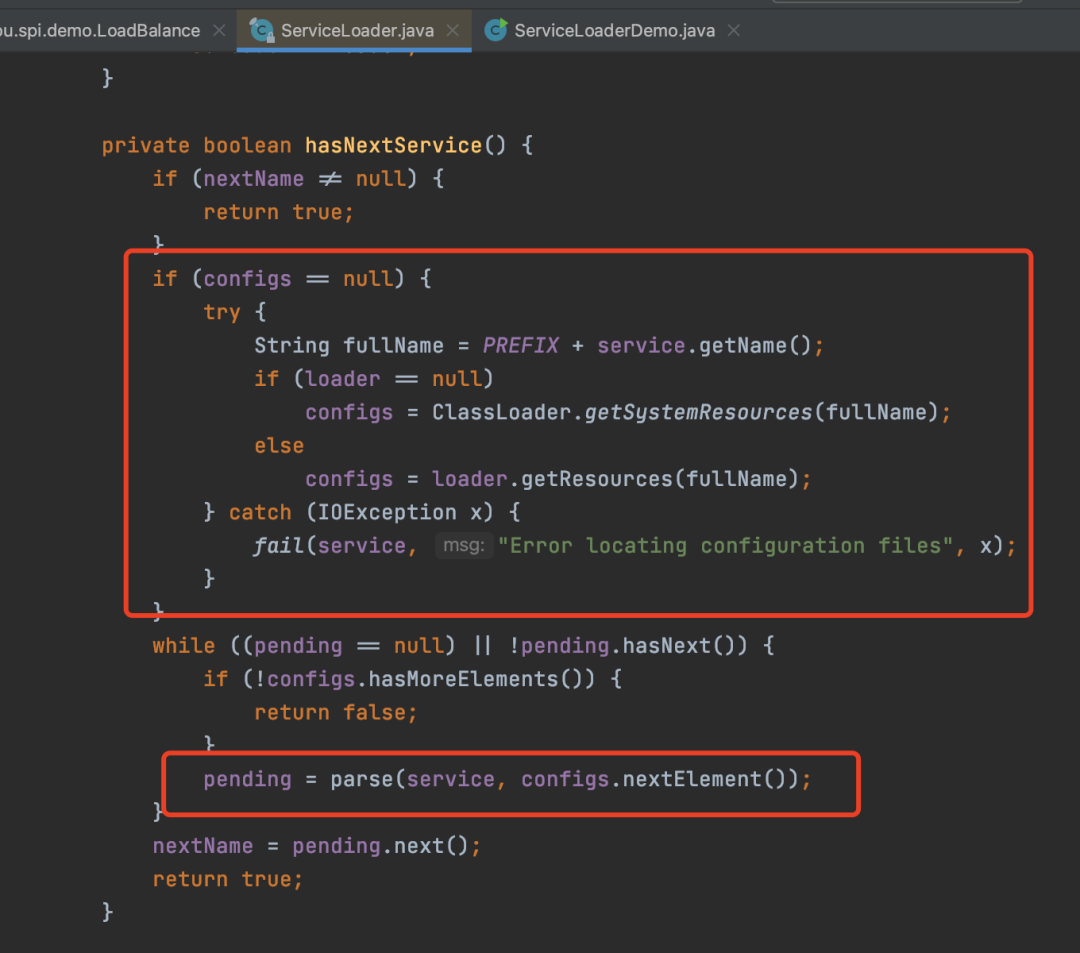
First, obtain a fullName, which is actually META-INF/services/fully qualified name of the interface.
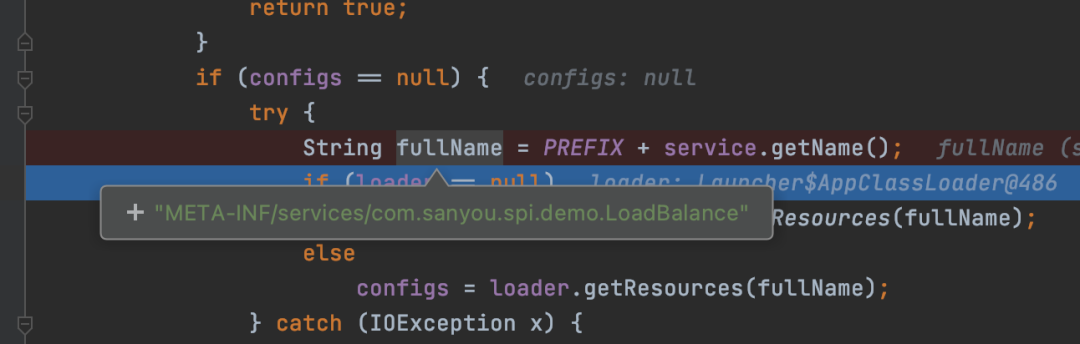
Then, use the ClassLoader to obtain the resource, which corresponds to the resource of the file with the fully qualified name of the interface, and hand it over to the parse method to parse the resource.
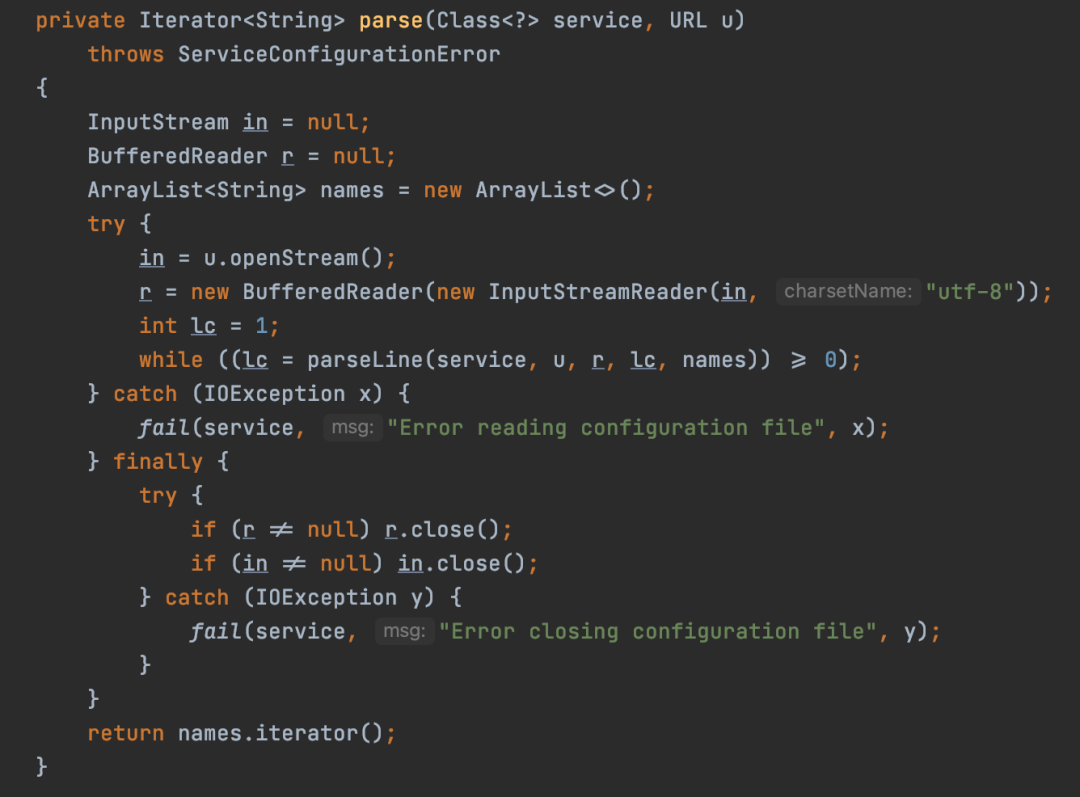
The parse method reads the content of the file through IO streams, allowing us to obtain the fully qualified names of the implementations of the interface.
Subsequently, it uses reflection to instantiate the objects, which will not be shown here.
Thus, it is not difficult to find that the implementation principle of ServiceLoader is relatively simple. In summary, it reads the content of the META-INF/services/fully qualified name of the interface file through IO streams and then instantiates objects via reflection.
Advantages and Disadvantages
Due to the simplicity of Java’s SPI mechanism, it also has some drawbacks.
The first point is resource waste. Although there is only one implementation class in the example, in reality, there may be many implementation classes, and Java’s SPI will instantiate all of them at once, even if not all of them are needed, thus wasting resources.
The second point is the inability to distinguish specific implementations. Given many implementation classes, which one should be used? If you want to determine which one to use, you can only rely on the design of the interface itself. For example, the interface can be designed as a strategy interface or can have priority, but no matter how it is designed, the framework author must write code to make the judgment.
In summary, ServiceLoader cannot achieve on-demand loading or on-demand retrieval of a specific implementation.
Usage Scenarios
Although ServiceLoader may have some drawbacks, it still has its usage scenarios, for example:
-
No need to select a specific implementation; each loaded implementation is required. -
While needing to select a specific implementation, it can be resolved through the design of the interface.
Spring SPI Mechanism — SpringFactoriesLoader
We are all familiar with Spring, which also provides an implementation of SPI called SpringFactoriesLoader.
The stipulations of Spring’s SPI mechanism are as follows:
-
The configuration file must be under the META-INF/directory, and the file name must be spring.factories. -
The file content is a key-value pair, where a key can have multiple values separated by commas. The keys and values must be fully qualified class names, and there can be no relationship between classes, although there can be an implementation relationship.
Thus, it can be seen that the file name and content stipulations of Spring’s SPI mechanism are different from those of Java.
Let’s do a demo
Create a spring.factories file in the META-INF/ directory, where LoadBalance is the key and RandomLoadBalance is the value.

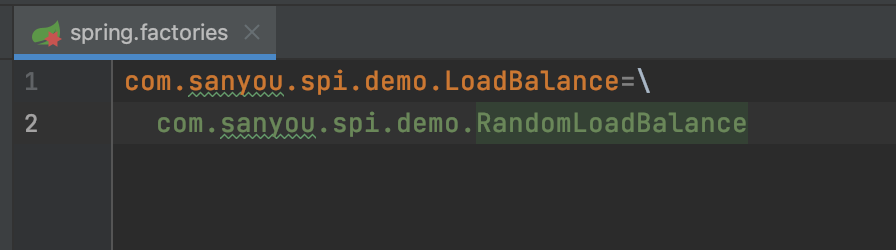
Testing:
public class SpringFactoriesLoaderDemo {
public static void main(String[] args) {
List<LoadBalance> loadBalances = SpringFactoriesLoader.loadFactories(LoadBalance.class, MyEnableAutoConfiguration.class.getClassLoader());
for (LoadBalance loadBalance : loadBalances) {
System.out.println("Obtained LoadBalance object:" + loadBalance);
}
}
}
Run result:

Successfully obtained the implementation object.
Core Principle
Below is a core piece of code from SpringFactoriesLoader.
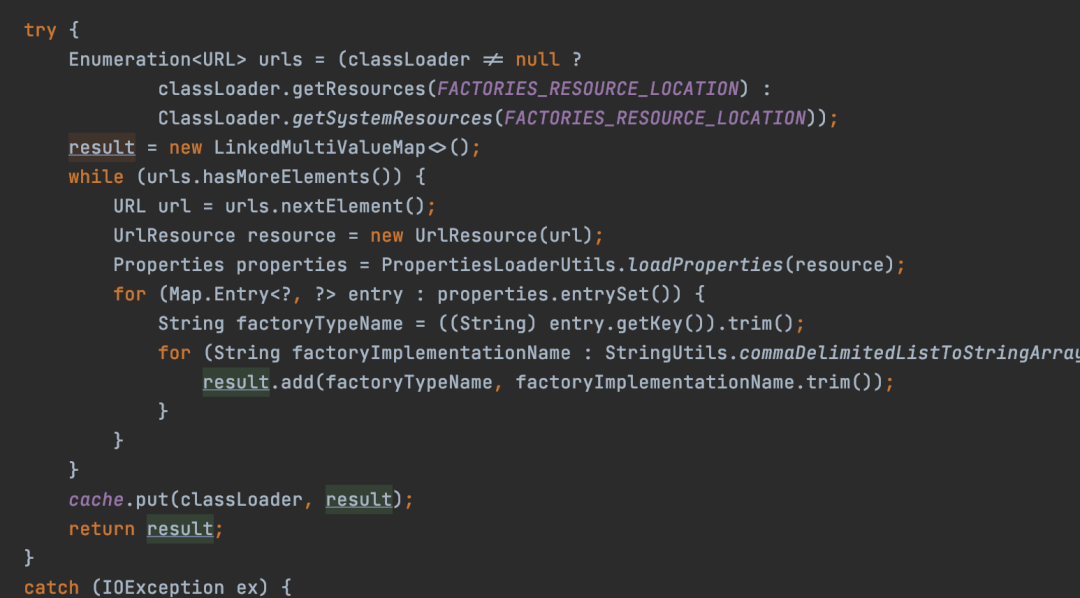
It can be seen that it is similar to the implementation of Java, but it reads the content of the spring.factories file in the META-INF/ directory and parses the key-value pairs.
Usage Scenarios
The Spring SPI mechanism is widely used internally, especially in Spring Boot, where many extension points are implemented through the SPI mechanism. Here are two examples:
1. Automatic Configuration
In versions of Spring Boot prior to 3.0, automatic configuration was loaded using SpringFactoriesLoader.
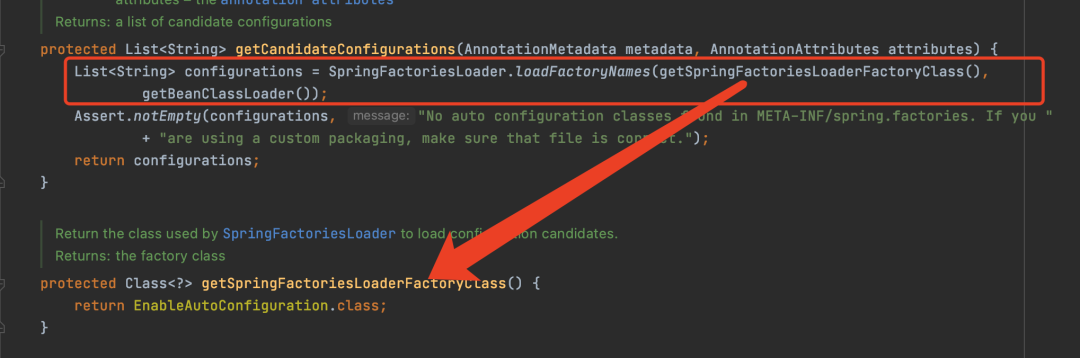
However, after Spring Boot 3.0, it no longer uses SpringFactoriesLoader but instead reads from META-INF/spring/ directory’s org.springframework.boot.autoconfigure.AutoConfiguration.imports file.
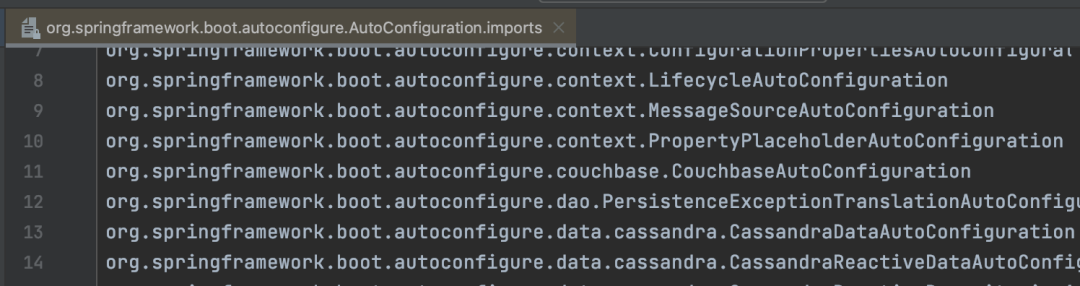
As for how it reads, it can be guessed that it is quite similar to the above SPI mechanism reading method, just with a different file path and name.
2. PropertySourceLoader Loading
PropertySourceLoader is used to parse application configuration files, and it is an interface.
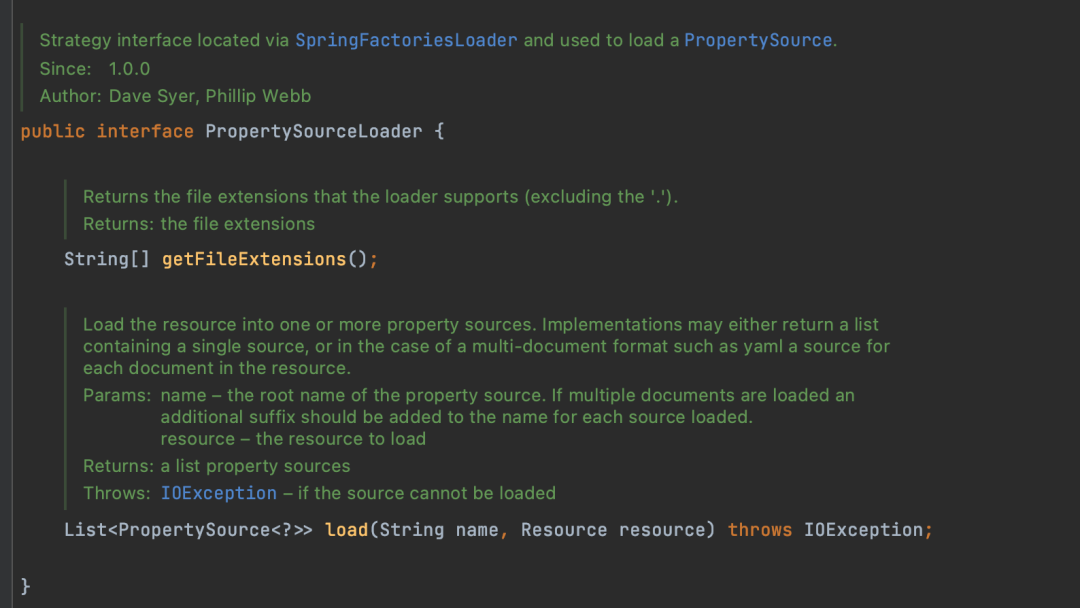
Spring Boot provides two implementations, PropertiesPropertySourceLoader and YamlPropertySourceLoader, corresponding to the parsing of properties and YAML file formats.
Spring Boot uses the SPI mechanism when loading PropertySourceLoader.
Comparison with Java SPI Mechanism
Firstly, Spring’s SPI mechanism simplifies Java’s SPI mechanism. Each interface in Java’s SPI needs a corresponding file, while Spring’s SPI only requires a single spring.factories file.
Secondly, regarding content, the file content of Java’s SPI mechanism must be the implementation classes of the interfaces, whereas Spring’s SPI does not require any relationship between key-value pairs, making it more flexible.
The third point is that Spring’s SPI mechanism provides a method for obtaining class qualified names loadFactoryNames, which Java’s SPI mechanism lacks. By obtaining the class qualified names through this method, these classes can be injected into the Spring container, loading these beans through Spring, rather than just through reflection.
However, Spring’s SPI also does not implement the function of obtaining a specific implementation class, so to find a specific implementation class, one still relies on the design of the specific interface.
So, have you noticed that PropertySourceLoader is actually a strategy interface, as indicated in the comments? Therefore, when your configuration file is in properties format, it can find the PropertiesPropertySourceLoader object that parses properties format to parse the configuration file.
Dubbo SPI Mechanism — ExtensionLoader
ExtensionLoader is the implementation class of Dubbo’s SPI mechanism. Each interface will have its own ExtensionLoader instance, which is similar to Java’s SPI mechanism.
Similarly, Dubbo’s SPI mechanism has the following stipulations:
-
The interface must be annotated with @SPI. -
The configuration files can be placed in META-INF/services/,META-INF/dubbo/internal/,META-INF/dubbo/, andMETA-INF/dubbo/external/, with the file name being the fully qualified name of the interface. -
The content is a key-value pair, where the key is a short name (which can be understood as the name of the bean in Spring), and the value is the fully qualified name of the implementation class.
Let’s do a demo
First, add the @SPI annotation on the LoadBalance interface.
@SPI
public interface LoadBalance {
}
Then, modify the content of the configuration file for Java’s SPI mechanism test to key-value pairs since Dubbo’s SPI mechanism can also read files from META-INF/services/ directory, so we won’t rewrite the file.
random=com.sanyou.spi.demo.RandomLoadBalance
Test class:
public class ExtensionLoaderDemo {
public static void main(String[] args) {
ExtensionLoader<LoadBalance> extensionLoader = ExtensionLoader.getExtensionLoader(LoadBalance.class);
LoadBalance loadBalance = extensionLoader.getExtension("random");
System.out.println("Obtained object corresponding to random key:" + loadBalance);
}
}
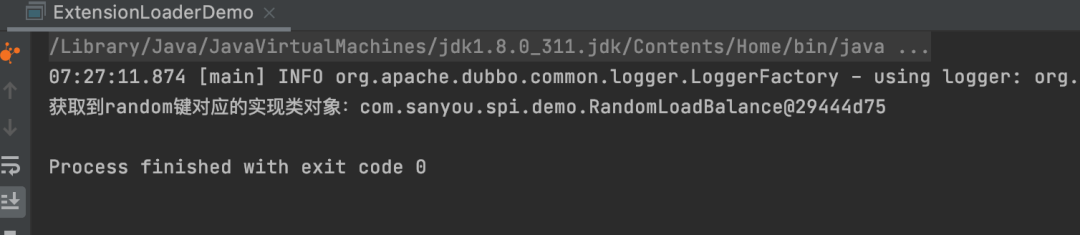
Through the getExtension method of ExtensionLoader, by passing in the short name, we can accurately find the implementation class corresponding to the short name.
Thus, it can be seen that Dubbo’s SPI mechanism resolves the previously mentioned issue of not being able to retrieve a specific implementation class.
Test result:
In addition to resolving the issue of not being able to obtain a specific implementation class, Dubbo’s SPI mechanism also provides many additional features, which are widely used internally in Dubbo. Let’s discuss them in detail next.
Core Mechanisms of Dubbo
1. Adaptive Mechanism
Adaptive, meaning that based on parameters, it dynamically selects the specific target class at runtime and executes it.
Each interface can have only one adaptive class. By using the getAdaptiveExtension method of ExtensionLoader, we can obtain an instance of this class, which can find the target implementation class based on runtime parameters and then call the methods of the target object.
For example, if the above LoadBalance has an adaptive object, after obtaining this adaptive object, if the key random is passed in during runtime, this adaptive object will find the implementation class corresponding to the key random and call its method. If a different key is dynamically passed in, it routes to another implementation class.
Adaptive classes can be generated in two ways. The first is to specify it yourself by adding the @Adaptive annotation on the implementation class of the interface, making it the adaptive implementation class.
@Adaptive
public class RandomLoadBalance implements LoadBalance{
}
In addition to self-specifying in code, Dubbo can also dynamically generate an adaptive class based on certain conditions, which is a complex process that will not be elaborated here.
The adaptive mechanism is widely used in Dubbo, and many are generated automatically. If you are not aware of Dubbo’s adaptive mechanism, you may not understand why the code can reach certain points when reading the source code.
2. IOC and AOP
When it comes to IOC and AOP, Spring immediately comes to mind. However, IOC and AOP are not unique concepts to Spring; Dubbo also implements these functionalities but in a lightweight manner.
2.1. Dependency Injection
Dubbo’s dependency injection is done through setter injection, where the injected object is by default the adaptive object mentioned above, and in a Spring environment, Spring Beans can be injected.
public class RoundRobinLoadBalance implements LoadBalance {
private LoadBalance loadBalance;
public void setLoadBalance(LoadBalance loadBalance) {
this.loadBalance = loadBalance;
}
}
In the above code, RoundRobinLoadBalance has a setLoadBalance method with LoadBalance as a parameter. When creating RoundRobinLoadBalance, in a non-Spring environment, Dubbo will find the LoadBalance adaptive object and inject it via reflection.
This method is also common in Dubbo; for example, in the RegistryProtocol, a Protocol is injected, which is actually an adaptive object.
2.2. Interface Callback
Dubbo also provides some callback functionalities similar to Spring’s interfaces. For instance, if your class implements the Lifecycle interface, several methods will be called back during creation or destruction.
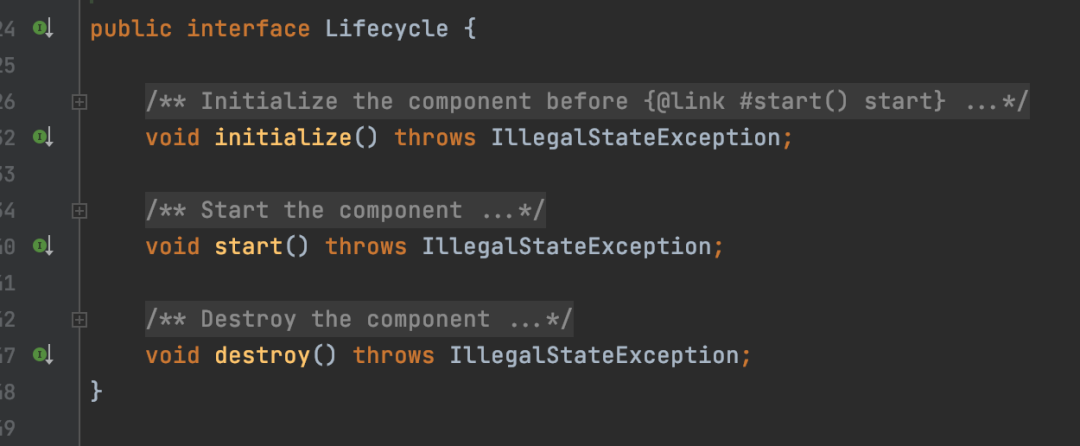
In some version of Dubbo 3.x, more interface callbacks were provided, such as ExtensionPostProcessor and ExtensionAccessorAware, which have similar names and functions to those in Spring.
2.3. Automatic Wrapping
Automatic wrapping is essentially the implementation of AOP functionality, which involves proxying the target object, and this AOP functionality is enabled by default.
In the implementation of SPI interfaces in Dubbo, there is a special class called the Wrapper class, which is used to implement AOP.
The only criterion for identifying a Wrapper class is that it must have a constructor with a single parameter of the interface type, as shown in the following code:
public class RoundRobinLoadBalance implements LoadBalance {
private final LoadBalance loadBalance;
public RoundRobinLoadBalance(LoadBalance loadBalance) {
this.loadBalance = loadBalance;
}
}
At this point, RoundRobinLoadBalance is a Wrapper class.
When obtaining the target object RandomLoadBalance through random, the actual object retrieved is RoundRobinLoadBalance, which internally references RandomLoadBalance.
If there are many wrapper classes, it will form a chain of responsibility, one wrapping another.
Thus, Dubbo’s AOP implementation is different from Spring’s AOP. Spring’s AOP is based on dynamic proxies, while Dubbo’s AOP is more like static proxies, where Dubbo automatically assembles this proxy, forming a chain of responsibility.
At this point, we have learned that there are two types of implementation classes for SPI interfaces in Dubbo:
-
Adaptive Classes -
Wrapper Classes
In addition to these two types, there is also a default class, which corresponds to the implementation class indicated by the value of the @SPI annotation. For example:
@SPI("random")
public interface LoadBalance {
}
Here, the key random corresponds to the default implementation, which can be obtained through the getDefaultExtension method.
3. Automatic Activation
Automatic activation means dynamically selecting a batch of implementation classes based on your input parameters.
The implementation class for automatic activation must be annotated with Activate, thus learning another classification of implementation classes.
@Activate
public interface RandomLoadBalance {
}
At this point, RandomLoadBalance is classified as an automatically activated class.
The method for obtaining automatic activation classes is getActivateExtension, thus allowing dynamic selection of a batch of implementation classes based on the parameters of this method.
The automatic activation mechanism is a core use case in Dubbo, particularly in the Filter chain.
Filter is an extension point in Dubbo that can intercept requests before they are sent or after a response is received, similar to Spring MVC’s HandlerInterceptor.
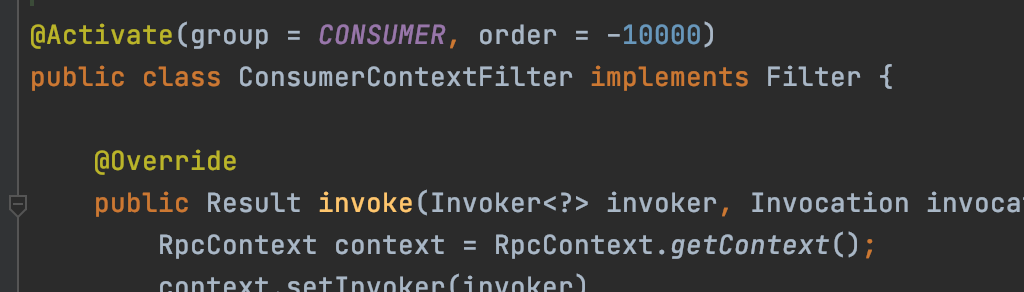
As shown above, there are many implementations of Filter, so to distinguish whether the Filter implementation applies to the provider or the consumer side, the automatic activation mechanism can dynamically select a batch of Filter implementations based on input parameters.
For instance, the ConsumerContextFilter applies to the Consumer side.

Finally, this article does not perform a source code analysis of Dubbo’s SPI mechanism. Interested readers can check out the two articles on commonly asked interview questions regarding Dubbo’s SPI mechanism.
Conclusion
From the above analysis, it can be seen that the core principle of implementing the SPI mechanism is to read the content of the specified file through IO streams, parse it, and then add some of its own features.
In summary, Java’s SPI implementation is relatively simple and lacks additional functionalities; Spring, benefiting from its IOC and AOP capabilities, has not implemented a very complex SPI mechanism, only simplifying and optimizing Java’s SPI; however, Dubbo’s SPI mechanism has implemented more functionalities to meet its framework usage requirements, integrating IOC and AOP functionalities into the SPI mechanism, and providing features such as adaptive injection and automatic activation.
Welcome everyone to join Su San's Knowledge Planet [Java Assault Team] to learn together.
The planet has a lot of exclusive content, such as: Java backend learning routes, sharing practical projects, source code analysis, designing million-level systems, pitfalls during system launch, MQ topics, and real interview questions. Daily responses to questions raised by everyone.
These days, the planet has opened three high-quality columns: Pain Points, High-Frequency Interview Questions, and Performance Optimization.
Each column addresses very concerned and valuable topics, and I believe you will learn a lot from them, worth the price.