[Help on how to add a table of contents]
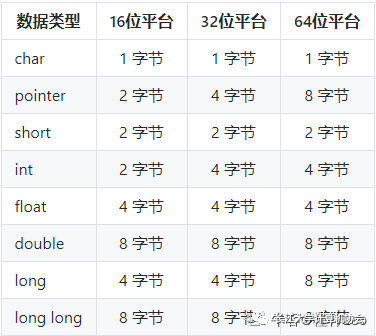
Data Type Explanation
Differences Between C and C++
C is a structured language that focuses on algorithms and data structures. The primary consideration in designing C programs is how to process input to produce output through a process.
On the other hand, C++ adds classes on top of C, with the primary focus being on constructing an object model that fits the corresponding problem domain, allowing for output to be obtained by accessing the object’s state information.
Understanding Encapsulation, Inheritance, and Polymorphism
Encapsulation
Encapsulation hides implementation details, making code modular; it surrounds processes and data, allowing access to the data only through defined interfaces. Object-oriented computing begins with this basic concept, that the real world can be depicted as a series of fully autonomous, encapsulated objects that access other objects through a protected interface. In object-oriented programming, this can be understood as: encapsulating objective things into abstract classes, where classes can restrict access to their data and methods to trusted classes or objects, hiding information from untrusted ones. I believe that modular design is the essence of encapsulation. In software design or other engineering designs, especially in complex projects, modular design is generally used. The benefit of modular design is that it allows a complex system to be broken down into different modules, each of which can be designed and debugged independently, making it feasible for multiple people to work on a complex project together. To achieve modular design, encapsulation is an indispensable part. A good module, like an Intel CPU chip, has powerful functionality; although we do not know how it works internally, we can use it effectively.
Polymorphism + Example
Polymorphism refers to the same entity having multiple forms simultaneously. It is one of the three major characteristics of object-oriented programming.
Add the virtual keyword before the base class function, and override that function in the derived class. At runtime, the appropriate function will be called based on the actual type of the object. If the object type is derived class, the derived class’s function is called; if the object type is base class, the base class’s function is called.
In C++, polymorphism can be achieved through the following methods: virtual functions, abstract classes, overriding, templates, with the condition that there must be overriding and inheritance, where the parent class points to the child class.
Inheritance
If a category A “inherits from” another category B, A is referred to as “the subclass of B,” while B is called “the superclass of A” or “B is A’s superclass.” Inheritance allows subclasses to possess various attributes and methods of the superclass without having to rewrite the same code. While allowing the subclass to inherit from the superclass, certain attributes can be redefined, and some methods can be overridden, i.e., overriding the original attributes and methods of the superclass to provide different functionality from the superclass. Additionally, it is common to add new attributes and methods to subclasses. The concept of inheritance can be implemented in three ways: implementation inheritance, interface inheritance, and visual inheritance.
-
Implementation inheritance refers to the ability to use the attributes and methods of the base class without extra coding;
-
Interface inheritance refers to using only the names of attributes and methods, but the subclass must provide implementations;
-
Visual inheritance refers to the ability of a subclass to use the appearance and implementation code of the base class.
The Role of Virtual Functions and Their Implementation Principles
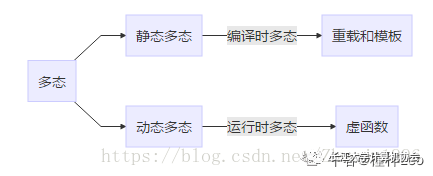
The Role of Virtual Functions: Virtual functions implement the mechanism of polymorphism. When a base class defines a virtual function, the subclass can override this function, and at runtime, the base class pointer will dynamically call the corresponding function belonging to the subclass based on the different subclass pointers assigned to it. This type of function call cannot be confirmed during compilation but is confirmed at runtime, also known as late binding.
Implementation Principles: It involves two tools. When a class declares a virtual function or inherits a virtual function, this class will have its own virtual function table. The virtual function table is essentially an array of function pointers; some compilers use a linked list. Each element in the virtual function table array corresponds to a function pointer pointing to a virtual function of that class, and each object of that class will contain a pointer to the virtual function table, which points to the address of that virtual function table. Therefore, when a class has virtual functions, it occupies memory equal to the size of one pointer. The virtual function table is organized in the order of declaration. If the subclass overrides the virtual function of the superclass, it will overwrite the original position of the superclass’s virtual function in the virtual function table. If the derived class has multiple parent classes, the member functions of the subclass are stored in the table of the first parent class.
Deep Copy and Shallow Copy (Value Copy and Bit Copy)
Deep copy refers to reallocating object resources during copying, resulting in different memory for the two objects; releasing the resources of one object will not affect the other. Shallow copy means both objects point to the same memory space; releasing the resources of one object will also remove the resources of the other, causing dangling pointers.
How to Implement Virtual Functions and Pure Virtual Functions
1: Functions declared with the virtual keyword are called virtual functions, which must be member functions of a class.
2: Classes with virtual functions have a one-dimensional virtual function table called a vtable, and the objects of the class have a virtual pointer pointing to the start of the vtable. The vtable corresponds to the class, and the vtable pointer corresponds to the object.
3: Polymorphism is an interface with multiple implementations and is the core of object-oriented programming, divided into class polymorphism and function polymorphism.
4: Polymorphism is implemented using virtual functions, combined with dynamic binding.
5: A pure virtual function is a virtual function with = 0;
6: An abstract class is a class that includes at least one pure virtual function. A pure virtual function: virtual void fun()=0; indicates an abstract class! An abstract base class cannot define objects. This function must be implemented in the subclass, meaning it has a name but no content, with the content implemented in the derived class.
Why Have Pure Virtual Functions
1. To facilitate the use of polymorphic features, we often need to define virtual functions in the base class. 2. In many cases, it is unreasonable for the base class itself to instantiate objects. For example, animals as a base class can derive subclasses like tigers and peacocks, but it is clearly unreasonable for animals to instantiate objects. To solve this problem, the concept of pure virtual functions is introduced, defining the function as a pure virtual function (method: virtual ReturnType Function()= 0;), requiring the compiler to override it in the derived class to achieve polymorphism. At the same time, classes containing pure virtual functions are called abstract classes, which cannot instantiate objects. This effectively solves the above two problems.
Pure Virtual Function: (1) Pure virtual functions have no function body; (2) The “=0” at the end does not indicate that the function returns 0; it serves a formal purpose, informing the compiler “this is a virtual function”; (3) This is a declaration statement, ending with a semicolon.
Why Have Virtual Destructors
In C++, a base class uses a virtual destructor to prevent memory leaks. Specifically, if memory is allocated in the derived class and released in its destructor, if the base class uses a non-virtual destructor, deleting a derived class object pointed to by a base class pointer will not trigger dynamic binding, hence only the base class destructor will be called, and the derived class destructor will not be called. In such cases, the memory allocated in the derived class will not be released, resulting in a memory leak. Therefore, to prevent this situation, the base class destructor in C++ should be a virtual destructor.
Can Constructors Be Virtual Functions?
No
When constructing an object, it is necessary to know the actual type of the object, while virtual functions determine the actual type at runtime. When constructing an object, since the object has not yet been successfully constructed, the compiler cannot know whether the actual type is the class itself, a derived class, or another.
The execution of virtual functions depends on the virtual function table, which is initialized during the constructor, i.e., initializing the virtual table pointer (vptr) to correctly point to the virtual function table. However, during the construction of the object, the virtual function table (vtable) has not yet been initialized, making it impossible to execute.
Can Constructors Return Values in C++?
1. Constructors do not return values; they only describe the behavior of class initialization. 2. However, creating a class instance with new does return a value, as new returns a pointer to the class instance.
Can Constructors and Destructors Be Inherited?
No
Not all functions can be automatically inherited from the base class to the derived class. Constructors and destructors are used to handle the creation and destruction of objects, and they only know what to do with the objects at their specific levels.
Therefore, all constructors and destructors in the entire hierarchy must be called, meaning that constructors and destructors cannot be inherited. The subclass’s constructor will explicitly call the parent class’s constructor or implicitly call the default constructor of the parent class for the parent class’s initialization.
The same applies to destructors. They are things that every class has, and if they could be inherited, there would be no way to initialize them.
Differences Between Overload, Overwrite, and Override in C++
Overload: In a C++ program, several functions with similar semantics or functions can be represented by the same name, but with different parameters or return values (including different types or orders), i.e., function overloading. (1) Same scope (within the same class); (2) Same function name; (3) Different parameters; (4) The virtual keyword can be present or absent.
Override: Refers to the derived class function overriding the base class function, characterized by: (1) Different scopes (located in the derived class and base class); (2) Same function name; (3) Same parameters; (4) The base class function must have the virtual keyword.
Overwrite: Refers to the derived class function hiding the base class function with the same name, with the following rules: (1) If the derived class function has the same name as the base class function but different parameters, then regardless of the presence of the virtual keyword, the base class function will be hidden (note to avoid confusion with overloading). (2) If the derived class function has the same name and parameters as the base class function, but the base class function does not have the virtual keyword, then the base class function will be hidden (note to avoid confusion with overriding).
What is in an Empty Class?
-
Constructor
-
Copy Constructor
-
Destructor
-
Assignment Operator Overload
-
Address Operator Overload (this pointer)
-
Const-qualified Address Operator Overload
Why is the Size of an Empty Class 1 Byte in C++?
This is due to instantiation reasons (an empty class can also be instantiated); each instance has a unique address in memory. To achieve this, the compiler often implicitly adds one byte to an empty class, so that after instantiation, the empty class has a unique address in memory, hence the memory size of the empty class is 1 byte.
How Much Memory Does a Struct with an int, a char, and a static int Occupy? (Involving Memory Alignment Mechanism)
Assuming the operating system environment of this struct is 64-bit, the int occupies four bytes, the char aligns to 4 bytes, and static is not counted; the struct occupies a total of 8 bytes of memory.
It is particularly important to note: static variables are not allowed to be defined in C structs; C++ structs can define static variables, but they are not counted during sizeof, though initialization format must be noted. 
 Same type data is stored in contiguous memory.
Same type data is stored in contiguous memory.
Differences Between Structs and Unions
Struct Each member has its own memory, coexisting independently while following memory alignment principles. The total length of a struct variable equals the sum of the lengths of all members.
Union All members share a memory space, and only one member can use this memory at a time (for reading and writing), with all variables sharing the same starting memory address. Thus, unions are more memory-efficient than structs.
Differences Between Functions and Macros
-
Macros do simple string replacements without considering data types; functions pass parameters with data types.
-
Macro parameter replacement is processed directly without calculation, while function calls pass the actual parameter values to the formal parameters, which are calculated.
-
Macros occupy compile time, while functions occupy execution time.
-
Macro parameters do not occupy memory space, as they only do string replacements; formal parameters in functions are local variables that occupy memory.
-
Function calls incur some time and space overhead, as the system must preserve the scene during function calls, transfer to the called function, execute, return to the main function, and restore the scene, which is not the case with macros.
Similarities and Differences Between Macro Functions and Inline Functions
1. Inline functions are expanded at compile time, while macros are expanded at preprocessing time.
2. During compilation, inline functions are directly embedded into the target code, whereas macros are simple text replacements.
3. Inline functions can perform checks such as type safety and statement correctness during compilation, while macros do not have such functionality.
4. Macros are not functions, while inline functions are functions.
5. Macros must be carefully handled when defining macro parameters, generally wrapped in parentheses; inline functions do not have this ambiguity.
6. Inline functions can choose not to expand, while macros must expand. This is because inline is merely a suggestion to the compiler, which can choose to ignore it and not expand the function.
7. Macro definitions are formally similar to functions, but when used, they merely perform simple replacements in the preprocessor symbol table, so they cannot perform parameter validity checks, and thus do not enjoy the strict type checks provided by the C++ compiler. Additionally, their return values cannot be forcibly converted to suitable types, leading to a series of hidden dangers and limitations in their use.
Differences Between #define and typedef
(1) Different Principles: #define is a syntax defined in the C language, a preprocessing directive that performs simple and mechanical string replacements during preprocessing without correctness checks; typedef is a keyword processed during compilation and has type-checking functionality. It gives an existing type an alias within its scope but cannot be used within a function definition. Using typedef to define arrays, pointers, structures, etc., greatly simplifies programming and enhances readability.
(2) Different Functions: typedef is used to define type aliases, making types easier to remember. Another function is to define machine-independent types. For example, defining a REAL floating-point type can achieve maximum precision on the target machine: typedef long double REAL; on machines that do not support long double, it looks like this: typedef double REAL; on machines that do not support double, it looks like this: typedef float REAL. #define can define not only type aliases but also constants, variables, compilation switches, etc.
(3) Different Scopes: #define has no scope limitations; any previously defined macro can be used in subsequent programs, while typedef has its own scope.
(4) Different Pointer Operations: #define INTPTR1 int* typedef int* INTPTR2;
Differences Between #include “” and #include <> in Standard C++
#include<> directly searches for files in the compiler’s built-in function library.
#include”” first looks for custom files (usually in the folder of the current source file); if not found, it searches the function library.
If it is a self-written header file, it is recommended to use #include””.
C++ Memory Management Mechanism
In C++, memory is divided into five areas: heap, stack, free storage area, global/static storage area, and constant storage area. The stack creates storage units for local variables in a function, which are automatically released when the function execution ends. Stack memory allocation operations are built into the processor’s instruction set, making it very efficient, but the allocated memory capacity is limited. The heap consists of memory blocks allocated by new, and their release is not managed by the compiler but controlled by our applications; generally, one new corresponds to one delete. If the programmer does not release it, the operating system will automatically reclaim it after the program ends. The free storage area consists of memory blocks allocated by malloc, which is very similar to the heap, but it ends its life with free. The global/static storage area is where global and static variables are allocated in the same memory block; in previous C languages, global variables were divided into initialized and uninitialized, but in C++, this distinction has been eliminated, and they occupy the same memory area. The constant storage area is a special storage area where constants are stored and cannot be modified.
Differences and Connections Between malloc/free in C and new/delete in C++
Similarities: They both manage memory.
Difference 1: Type: malloc/free are functions, while new/delete are keywords/operators.
Difference 2: Purpose: malloc/free simply allocate and release memory; new/delete not only allocate and release memory but also call the constructor and destructor of the object for space initialization and cleanup.
Difference 3: Parameters and Return Values: malloc/free require manual calculation of the size of the allocated memory, and the return value is void*, which needs to be converted to the required type; new/delete can calculate the size of the type automatically and return a pointer of the corresponding type.
Differences Between Iteration and Recursion
Recursion and iteration are both based on control structures: iteration uses repetition structures, while recursion uses selection structures. Both involve repetition: iteration explicitly uses repetition structures, while recursion achieves repetition through repeated function calls. Both involve termination tests: iteration terminates when the loop condition fails, while recursion terminates when it encounters a base case.
Non-operable Operators
Scope operator: :: Conditional operator: ?: Dot operator: . Pointer-to-member operator: ->* ,.* Preprocessing symbol: #
The Role of the mutable Keyword in C++
In C++, mutable is set to break the limitations of const. Variables modified by mutable will always be mutable, even in a const function, and even if the structure variable or class object is const, its mutable members can be modified.
Mutable can only modify non-static data members in a class. The use of mutable data members may seem like a trick because it allows const functions to modify the object’s data members. However, wisely using the mutable keyword can improve code quality because it allows you to hide implementation details from users without using uncertain things. We know that if a class’s member function does not change the object’s state, it is generally declared as const. However, sometimes, we need to modify some data members unrelated to class state within a const function, and such data members should be modified by mutable.
What Are the Differences Between References and Pointers?
1. A reference must be initialized, while a pointer does not have to. 2. Once a reference is initialized, it cannot be changed, while a pointer can change the object it points to. 3. There is no reference that points to a null value, but there are pointers that can point to a null value. 4. A reference is an alias for a variable, and its internal implementation is a read-only pointer.
What Are Black Box Testing and White Box Testing?
White box testing: Testing is conducted through the source code of the program without using the user interface. This type of testing needs to discover internal code flaws or errors in algorithms, overflow, paths, conditions, etc., from the code syntax and correct them.
Black box testing: Strictly testing the entire software or certain software functions without checking the source code of the program or clearly understanding how the software’s source code is designed. Testers input their data and observe the output results to understand how the software works. During testing, the program is viewed as a black box that cannot be opened; the tester tests at the program interface without considering the internal structure and characteristics of the program, only checking whether the program can receive inputs appropriately and produce correct outputs.
What Class Templates Do You Know?
vector, string, list, queue, map, set, stack
Can new Be Used with free? Why?
Yes, but it is unsafe. Using free to release memory allocated by new does not always correctly release all allocated memory. This is because using free does not call the destructor of the instance; if the instance has dynamically allocated memory, it will not be released due to the destructor not being called, leading to memory leaks. Usually, you cannot always know whether dynamic memory is used in the class, so the best practice is to use new with delete.
Do You Understand C++ Exceptions? What to Do When Catching Exceptions?
How to Check for Memory Leaks?
C/C++
-
Valgrind: Debugging and profiling Linux programs, aimed at programs written in C and C++
-
ccmalloc: A simple memory leak and malloc debugging library for C and C++ programs under Linux and Solaris
-
LeakTracer: Tracks and analyzes memory leaks in C++ programs under Linux, Solaris, and HP-UX
-
Electric Fence: A malloc() debugging library written by Bruce Perens in Linux distributions
-
Leaky: A program that detects memory leaks under Linux
-
Dmalloc: Debug Malloc Library
-
MEMWATCH: An open-source C language memory error detection tool written by Johan Lindh, mainly through gcc’s preprocessor
-
KCachegrind: A visualization tool for the profiling data generated by Cachegrind and Calltree
Solutions to Memory Leaks
First: Good coding habits, detect memory leaks in program segments involving memory as much as possible. Detecting memory leaks after the program is stable undoubtedly increases the difficulty and complexity of exclusion. When using memory allocation functions, remember to use the corresponding function to release it once it is used.
Second: Manage allocated memory pointers in the form of linked lists, delete from the list after use, and check the list at the end of the program. Prevent dangling pointers.
Third: Three smart pointers from Boost.
What is Memory Overflow?
Memory overflow refers to the presence of unrecoverable memory or excessive use of memory in the application system, ultimately causing the memory required for program operation to exceed the maximum memory that the virtual machine can provide. Many reasons can cause memory overflow, the most common of which are: 1. A large amount of data loaded into memory, such as retrieving too much data from the database at once; 2. Collection classes have references to objects that are not cleared after use, preventing the JVM from recovering them; 3. The code contains infinite loops or loops generating too many duplicate object entities; 4. Bugs in third-party software; 5. Memory values set too small in startup parameters;
Solutions to Memory Overflow
Step 1: Modify JVM startup parameters to directly increase memory. (Do not forget to add -Xms, -Xmx parameters.) Step 2: Check error logs to see if there are other exceptions or errors before the “OutOfMemory” error. Step 3: Walk through and analyze the code to find potential memory overflow locations. Focus on the following points: 1. Check whether there is a query in the database that retrieves all data at once. Generally, if you retrieve 100,000 records into memory at once, it may cause memory overflow. This problem is relatively hidden; before going online, the data in the database is small, making it difficult to have problems. After going online, as the database has more data, a single query may cause memory overflow. Therefore, it is best to use paging for database queries. 2. Check if there are infinite loops or recursive calls in the code. 3. Check if there are large loops repeatedly generating new object entities. 4. Check for queries in the database that retrieve all data at once. Generally, if you retrieve 100,000 records into memory at once, it may cause memory overflow. This problem is relatively hidden; before going online, the data in the database is small, making it difficult to have problems. After going online, as the database has more data, a single query may cause memory overflow. Therefore, it is best to use paging for database queries. 5. Check whether List, MAP, and other collection objects have not been cleared after use. List, MAP, and other collection objects will always hold references to objects, preventing these objects from being garbage collected.
Step 4: Use memory viewing tools to dynamically check memory usage.
What Are Function Pointers and Pointer Functions?
A pointer function is essentially a function whose return value is a pointer. int *fun(int x,int y);
A function pointer is essentially a pointer pointing to a function. int (*fun)(int x,int y);
Do You Understand the New Features of C++11?
1. New container std::array is stored in stack memory, allowing more flexible access to its elements compared to std::vector in heap memory, resulting in higher performance. 2. The keywords auto and decltype achieve type inference. 3. nullptr replaces NULL. 4. Three smart pointers help manage memory (mention their names). 5. C++11 introduces range-based iteration syntax, such as range-based for loops, allowing for simpler loop statements similar to Python.
Differences Between Interfaces and Abstract Classes
-
All methods in an interface are implicitly abstract, while an abstract class can contain both abstract and non-abstract methods.
-
A class can implement multiple interfaces, but can only inherit from one abstract class.
-
If a class wants to implement an interface, it must implement all methods declared in the interface. However, a class can choose not to implement all methods declared in an abstract class; in this case, the class must also be declared as abstract.
-
An abstract class can implement an interface without providing method implementations.
-
Member functions in Java interfaces are public by default. The member functions of abstract classes can be private, protected, or public.
Differences Between Struct and Class
Struct, as the implementation of a data structure, has a default data access control of public; while class, as the implementation of an object, has a default member variable access control of private.
What Does Precompilation Do?
Precompilation, also known as preprocessing, performs code text replacement tasks. It mainly handles directives starting with #, such as copying the code of included files from #include, replacing macro definitions from #define, conditional compilation, etc. It is the preparatory phase for compilation.
Compilation Process of Executable Files
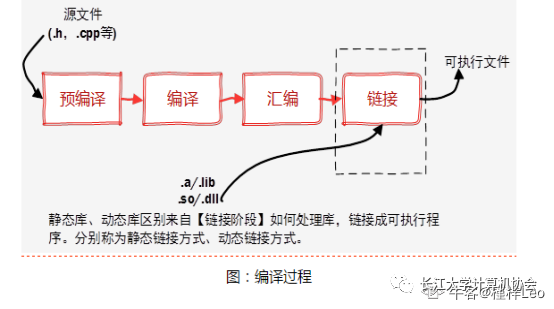
Dynamic Libraries and Static Libraries?
Characteristics of static libraries: Linking to function libraries is completed at compile time. The program has no further connection to the function library at runtime, making it convenient for portability. It wastes space and resources because all related object files and involved function libraries are linked into one executable file. The file suffix is usually (.a, .lib).
Characteristics of dynamic libraries: Linking to some library functions is delayed until the program runs. It allows resource sharing between processes and makes upgrading programs simple by directly modifying the dynamic library. The file suffix is usually (.so, .dll).
Differences Between Heap and Stack, and Why the Stack is More Efficient
The heap expands from low addresses to high addresses; the stack expands from high addresses to low addresses. Memory in the heap needs to be manually allocated and released; memory in the stack is automatically allocated and released by the OS, storing parameters, local variables, and other memory. Frequent calls to malloc and free in the heap can create memory fragmentation, reducing program efficiency; while the stack, due to its last-in-first-out characteristic, does not create memory fragmentation. Heap allocation efficiency is lower, while stack allocation efficiency is higher.
The reason the stack is efficient is that it is a data structure provided by the operating system, with the computer’s lower layer providing a series of support: allocating dedicated registers to store the stack address, with dedicated instructions for pushing and popping; while the heap is provided by C/C++ function libraries, with a complex mechanism requiring a series of algorithms for memory allocation, merging, and releasing, thus being less efficient.
Why Are Function Parameters Pushed onto the Stack from Right to Left?
Because C++ supports variable-length function parameters. This is the reason that the C language’s function parameter push order is from right to left. The specific reason is that the C way of pushing parameters onto the stack from right to left allows for a dynamic change in the number of parameters. The bottom of the C program stack is high address, and the top is low address. The position of the leftmost determined parameter on the stack must be certain; otherwise, it means that already determined parameters cannot be located and found, making it impossible to ensure correct function execution. The position of already determined parameters on the stack should not depend on the specific number of parameters because the number of parameters is unknown! Therefore, only the last determined parameter can be pushed onto the stack to ensure its position on the stack is determined.
Can You Talk About Smart Pointers in C++?
There are four smart pointers in C++: auto_ptr, shared_ptr, weak_ptr, unique_ptr, of which the latter three are supported in C++11, and the first one has been deprecated in C++11.
The function of smart pointers is to manage a pointer because of situations like forgetting to release allocated space at the end of a function, causing memory leaks. Using smart pointers can greatly avoid this problem because a smart pointer is a class that automatically calls the destructor to release resources when it goes out of scope. Therefore, the principle of smart pointers is to automatically release memory space at the end of the function without manual memory release.
1. auto_ptr (the C++98 solution, deprecated in C++11) adopts an ownership model. The downside is: it has potential memory crash issues!
| 123 | auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));auto_ptr <string> p2;p2 = p1;//auto_ptr will not report an error. At this point, it does not report an error, p2 deprives p1 of its ownership, but accessing p1 when the program runs will report an error. Thus, the downside of auto_ptr is: it has potential memory crash issues! |
2. unique_ptr (replaces auto_ptr) implements the concept of exclusive ownership, ensuring that only one smart pointer can point to that object at any one time. It is particularly useful for avoiding resource leaks (for example, forgetting to call delete after creating an object with new due to an exception). It adopts an ownership model.
| 1234 | unique_ptr<string> p3 (new string ("auto"));unique_ptr<string> p4;p4 = p3;//This will report an error!!//The compiler considers p4=p3 illegal, preventing p3 from no longer pointing to valid data. Therefore, unique_ptr is safer than auto_ptr. |
3. shared_ptr implements the concept of shared ownership. Multiple smart pointers can point to the same object, and that object and its related resources will be released when “the last reference is destroyed.” As the name suggests, resources can be shared by multiple pointers, and it uses a counting mechanism to indicate how many pointers share the resource. The member function use_count() can be used to check the number of resource owners. In addition to being constructed with new, it can also be constructed by passing in auto_ptr, unique_ptr, or weak_ptr. When we call release(), the current pointer releases resource ownership and the count decreases. When the count reaches 0, the resource will be released. shared_ptr was introduced to solve the limitations of auto_ptr regarding object ownership (auto_ptr is exclusive), providing a smart pointer that allows for shared ownership using a reference counting mechanism.
4. weak_ptr is a smart pointer that does not control the object’s lifecycle; it points to an object managed by a shared_ptr. The memory management of that object is handled by the strong reference shared_ptr. weak_ptr only provides a means to access the managed object. weak_ptr was designed to work with shared_ptr, and it can only be constructed from a shared_ptr or another weak_ptr. Its construction and destruction do not increase or decrease the reference count.
weak_ptr is used to solve the deadlock problem when shared_ptrs reference each other; if two shared_ptrs reference each other, their reference counts can never decrease to 0, and the resources will never be released. It is a weak reference to an object, which does not increase the reference count of the object, and can be converted between shared_ptr and weak_ptr; shared_ptr can be directly assigned to it, and it can obtain shared_ptr by calling the lock function.
Can Private Member Functions in a Base Class Be Declared as Virtual Functions?
Yes, but it contradicts the original intention of creating private members, and it is not recommended.
Can Const Functions and Non-Const Functions Be Overloaded?
When Function A Calls Function B, What Needs to Be Pushed onto the Stack?
The parameters of the function, with the push order being from right to left. Also, the variables defined within function B.
Differences Between Arrays and Pointers? Differences Between Arrays and Linked Lists? Differences Between Doubly Linked Lists and Singly Linked Lists?
Differences Between Arrays and Pointers: 1. When passing an array as a parameter, it degenerates into a pointer. 2. The array name can be treated as a pointer constant. 3. An array allocates a contiguous block of memory, and the array’s identifier represents the entire array, allowing for the use of sizeof to obtain the actual size; pointers only allocate memory the size of a pointer and can point to a valid memory space.
Differences Between Arrays and Linked Lists: Different:
-
Linked lists are a chain-stored structure; arrays are a sequentially stored structure.
-
Linked lists connect elements through pointers, while arrays store all elements sequentially.
-
Inserting and deleting elements in linked lists is relatively simple compared to arrays, which require moving elements and are more complex to implement length expansion; searching for an element in linked lists is more challenging; searching for an element in arrays is simpler, but inserting and deleting are more complex because the maximum length must be specified at the beginning, making it less convenient for expansion when the maximum length is reached.
Similarities: Both structures can achieve sequential storage of data, and the constructed models present a linear structure.
Differences Between Doubly Linked Lists and Singly Linked Lists:Singly linked lists contain two fields, one for information and another for the pointer. This means that the nodes of a singly linked list are divided into two parts, one part storing information about the node, and the second part storing the address of the next node, while the last node points to a null value.
Doubly linked lists have two links for each node, one pointing to the previous node (when this link is the first link, it points to a null value or an empty list), and the other pointing to the next node (when this link is the last link, it points to a null value or an empty list). This means that doubly linked lists have two pointers, one pointing to the previous node and the other pointing to the next node.
Underlying Implementation of Vector?
The underlying data structure is a dynamic array. The default constructed size is 0, and subsequent insertions follow a doubling pattern of 1, 2, 4, 8, 16. Note (GCC uses double expansion, while VS13 uses 1.5 times expansion. The reason can be considered memory fragmentation and buddy system, which leads to memory waste). After expansion, a new memory space is created, and all elements in the old memory space must be copied to the new memory space before continuing to insert new elements in the new memory space, while simultaneously releasing the old memory space. Due to the reconfiguration of vector space, all iterators of the old vector become invalid.
The initial expansion method of vector incurs a high cost; initial expansion efficiency is low, requiring frequent growth, which not only reduces operational efficiency but also frequently requests memory from the operating system, leading to excessive memory fragmentation. Therefore, it is necessary to reasonably use the resize() and reserve() methods to improve efficiency and reduce memory fragmentation.
resize():void resize (size_type n);void resize (size_type n, value_type val);1. The resize method is used to change the number of elements in the vector, effectively changing the size of the container and creating objects within the container; 2. If the specified n is less than the current number of elements in the vector, it will delete excess elements, making the size of the vector n; 3. If the specified n is greater than the current number of elements in the vector, it will insert the appropriate number of elements at the end of the vector, making the size of the vector n. If a second parameter is specified for resize, the newly inserted elements will be initialized to that specified value; if no second parameter is specified, new positions will be filled with default values, generally 0; 4. If the specified n exceeds the current number of elements and the current capacity of the vector, it will automatically reallocate storage space for the vector.
reserve(): Avoids frequent memory allocation, causing excessive memory fragmentationvoid reserve (size_type n);1. The reserve function changes the capacity of the vector, ensuring that it can accommodate at least n elements. 2. If n exceeds the current capacity of the vector, reserve will expand the vector. In other cases, it will not reallocate storage space for the vector. 3. The reserve method does not affect the size of the vector’s elements; it does not create objects.
Data access efficiency in vector is very high, with a time complexity of O(1) for random access, but random insertion of elements in a vector requires moving a large number of elements, leading to lower efficiency.
Differences Between Vector and List?
Vector has a contiguous block of memory, thus supporting random access. If efficient random access is required without caring about insertion and deletion efficiency, use vector. Vector is similar to arrays, having a contiguous block of memory, and its starting address remains unchanged, thus supporting random access very well (using the [] operator to access its elements). However, due to its contiguous memory space, inserting and deleting in the middle will cause memory blocks to be copied (complexity is O(n)). Additionally, when the memory space after the array is insufficient, it needs to reallocate a sufficiently large memory block and copy the memory. These affect the efficiency of vector.
List has a non-contiguous memory space, thus does not support random access. If a lot of insertions and deletions are needed without caring about random access, use list. List is implemented by a doubly linked list in data structures, so its memory space can be non-contiguous. Therefore, data access must be done through pointers, making random access highly inefficient, requiring traversal of intermediate elements, with a search complexity of O(n). Thus, it does not overload the [] operator. However, due to the characteristics of linked lists, it can efficiently support deletion and insertion anywhere.
