
Researchers from the University of the Emirates, New York University Abu Dhabi, and the National University of Sciences and Technology in Pakistan have jointly launched an efficient memory replay method called Replay4NCL to address the challenges of continuous learning in embedded AI systems within dynamic environments.
It is worth mentioning that this research has been approved for presentation at the 62nd Design Automation Conference (DAC), which will be held in June 2025 in San Francisco.

With the rapid iteration and development of AI technology, embedded AI systems are playing an increasingly important role in various application scenarios, such as mobile robots, autonomous driving, and drones. These systems need to possess continuous learning capabilities to adapt to dynamically changing environments while avoiding catastrophic forgetting.
However, traditional continuous learning methods face significant issues of latency, energy consumption, and memory usage in embedded systems. Replay4NCL provides an efficient neuromorphic continuous learning solution for embedded AI systems by optimizing the memory replay process.
Introduction to the Core Architecture of Replay4NCL
The first core innovation module of Replay4NCL is temporal optimization. In spiking neural networks, timing is a critical parameter that determines the frequency at which neurons process information at each time step.
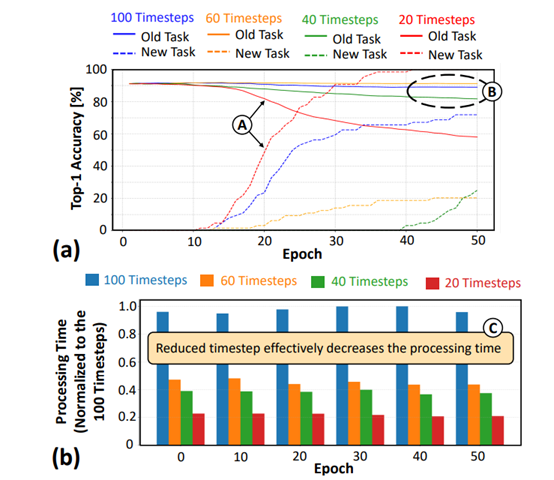
Traditional SNN models typically use longer timing to ensure that the network can adequately process input data and achieve high accuracy. However, long timing also introduces significant processing delays, which are unacceptable for embedded AI systems that require rapid responses.
Replay4NCL experimentally studied the impact of different timing settings on network accuracy and latency. Researchers found that reducing the timing from the traditional 100 to 40 resulted in a slight decrease in accuracy, but it remained within an acceptable range while significantly reducing processing time. This finding provides a theoretical basis for optimizing timing. Additionally,
Replay4NCL also introduces a data compression-decompression mechanism based on reduced timing, further reducing the memory footprint of potential data (old knowledge). Through this mechanism, potential data is compressed during storage and decompressed during use, significantly reducing the storage space of potential data without losing information.
While reducing timing decreases latency and memory usage, it also presents new challenges. With reduced timing, the number of spikes received by neurons decreases, which may make it difficult for the neuron’s membrane potential to reach the threshold potential, thereby affecting network performance. To address this issue, Replay4NCL proposes a parameter adjustment module that compensates for information loss by adjusting the neuron’s threshold potential and learning rate.
Researchers lowered the threshold potential Vthr value, making it easier for neurons to fire spikes, even with fewer spikes, thus maintaining spike activity similar to the original pre-trained model. At the same time, the learning rate was also reduced to slow down the network’s learning speed. This adjustment ensures that during the training phase, the network can update weights more cautiously, especially when the number of spikes is low, thereby enhancing the network’s ability to retain old knowledge and learn new knowledge.
Another core innovation of Replay4NCL is its dynamic training strategy, which organically combines timing optimization, parameter adjustment, and potential replay data insertion strategies to form an efficient training mechanism.
During the pre-training phase, the SNN model is first trained to learn all pre-training tasks. When preparing the network for the continuous learning training phase, the model generates LR data activation and splits the network into two parts based on selected layers: frozen layers and learning layers. The frozen layers are responsible for passing input spikes to the learning layers, while the learning layers are updated during the training of new tasks.
In the continuous learning training phase, the network dynamically adjusts the threshold potential and learning rate. In this way, the network can still maintain efficient weight updates and learning capabilities while processing fewer spikes.
Experimental Data
To test the performance of Replay4NCL, researchers conducted comprehensive evaluations on Spiking Heidelberg Digits and Class-Incremental Learning to assess key parameters such as accuracy, processing latency, and memory usage.
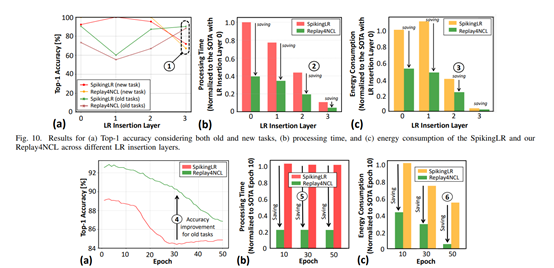
The experimental results show that Replay4NCL performs excellently in retaining old knowledge, achieving a Top-1 accuracy of 90.43%, which is an improvement of 4.21 percentage points compared to the existing state-of-the-art method SpikingLR. Meanwhile, when learning new tasks, the Replay4NCL method also demonstrated good performance, with accuracy comparable to the SpikingLR method.
In terms of processing latency, the Replay4NCL method achieved significant improvements. Compared to the SpikingLR method with a timing of 100, the Replay4NCL method reduced processing latency by 4.88 times by adopting a timing setting of 40. This improvement enables embedded AI systems to respond more quickly to input signals, enhancing the system’s real-time performance.
In terms of potential data memory usage, the Replay4NCL method also achieved significant savings. By employing a data compression-decompression mechanism based on reduced timing, the Replay4NCL method reduced the memory usage of potential data by 20%. This saving is crucial for resource-constrained embedded AI systems, as it can significantly reduce the system’s storage requirements, thereby lowering hardware costs and power consumption.
In terms of energy consumption, the Replay4NCL method also performed excellently. Experimental results indicate that compared to the SpikingLR method, the Replay4NCL method reduced energy consumption by 36.43%. This energy-saving effect is primarily due to the reduced timing settings, which decrease the number of spikes generated and processed, thereby lowering the system’s energy consumption.
Source of this article: Replay4NCL, please contact for removal if there is any infringement.
END




