1. Overview of HTTP
In the early 1990s, a major emerging application known as the World Wide Web took the stage. The Web is an Internet application that has captured public attention. The application layer protocol of the Web is Hypertext Transfer Protocol (HTTP), which is at the core of the Web. HTTP is implemented by two programs: a client program and a server program. The client and server programs run on different end systems and engage in sessions by exchanging HTTP messages. The HTTP session defines the structure of these messages and how the client and server exchange them.
Web pages (also called documents) are composed of objects. An object is simply a file, such as an HTML file, a JPEG image, a Java applet, or a video clip, and they can be addressed via a URL. Most Web pages contain a basic HTML file and several referenced objects. For example, if a Web page includes a basic HTML file and 5 JPEG images, then this Web page consists of 6 objects: one HTML basic file plus 5 images. The basic HTML file references other objects in the page via the URL addresses of those objects. Each URL address consists of two parts: the hostname of the server storing the object and the pathname of the object. Web browsers implement the HTTP client, while Web servers implement the HTTP server side, which is used to store Web objects, each addressed by a URL.
HTTP defines how Web clients request Web pages from Web servers and how servers deliver Web pages to clients. The basic idea is that when a user requests a Web page (for example, by clicking a hyperlink), the browser sends an HTTP request message to the server for the objects contained in that page. The server receives the request and responds with an HTTP response message that contains those objects.
HTTP uses TCP as its transport protocol (rather than running on UDP). The HTTP client first initiates a TCP connection with the server. Once the connection is established, the browser and server processes can access TCP through socket interfaces. The client sends the HTTP request message to its socket interface and receives the HTTP response message from its socket interface. Similarly, the server receives the HTTP request message from its socket interface and sends the HTTP response message to its socket interface. Once the client sends a request message to its socket interface, that message is out of the client’s control and under TCP’s control. TCP provides reliable data transmission services for HTTP. This means that every HTTP request message sent by a client process will eventually arrive intact at the server; similarly, every HTTP response message sent by the server process will eventually arrive intact at the client.
It is important to note the following phenomenon: the server sends the requested file to the client without storing any state information about that client. If a specific client requests the same object twice within a few seconds, the server will not refrain from responding just because it recently provided that object to that client; instead, it will resend the object as if it has completely forgotten what it did just moments ago. Because HTTP servers do not retain any information about clients, we say that HTTP is a stateless protocol.
2. Non-Persistent Connections and Persistent Connections
In many Internet applications, clients and servers communicate over a considerable period, during which clients issue a series of requests and the server responds to each request. Depending on the application and how it is used, this series of requests can be sent periodically at regular intervals or intermittently one after another. When this client-server interaction occurs over TCP, the application developer must make an important decision: should each request/response pair be sent over a separate TCP connection, or should all requests and their responses be sent over the same TCP connection? The former method is called a non-persistent connection, while the latter method is called a persistent connection. HTTP can use both non-persistent and persistent connections. Although HTTP uses persistent connections by default, HTTP clients and servers can also be configured to use non-persistent connections.
1. HTTP Using Non-Persistent Connections
Let’s look at the steps for transmitting a Web page from the server to the client in the case of non-persistent connections. Assume that the page contains a basic HTML file and 10 JPEG images, and these 11 objects are located on the same server. The URL for the HTML file is: http://www.someSchool.edu/someDepartment/home.index。 Let’s see what happens:
-
The HTTP client process initiates a TCP connection to the server www.someSchool.edu on port number 80, which is the default port for HTTP. A socket is associated with this connection on both the client and server sides.
-
The HTTP client sends an HTTP request message to that server via its socket. The request message contains the pathname /someDepartment/home.index.
-
The HTTP server process receives the request message via its socket, retrieves the object http://www.someSchool.edu/someDepartment/home.index from its memory (RAM or disk), encapsulates the object in an HTTP response message, and sends the response message to the client through its socket.
-
The HTTP server process instructs TCP to close that TCP connection. (However, it will not actually break the connection until TCP confirms that the client has completely received the response message).
-
The HTTP client receives the response message, and the TCP connection is closed. The message indicates that the encapsulated object is an HTML file; the client extracts that file from the response message, examines the HTML file, and obtains references to the 10 JPEG images.
-
The first four steps are repeated for each referenced JPEG image object.
The steps above illustrate the use of non-persistent connections, where each TCP connection closes after the server sends one object, meaning that the connection does not persist for other objects. It is worth noting that each TCP connection only transmits one request message and one response message.
In the steps described above, we deliberately did not specify whether the client obtained the 10 JPEG image objects using 10 serial TCP connections or whether some JPEG objects used some parallel TCP connections. In fact, users can configure modern browsers to control parallelism. By default, most browsers open 5 to 10 parallel TCP connections, with each connection handling one request-response transaction. If the user wishes, the maximum number of parallel connections can be set to 1, causing all 10 connections to be established serially.
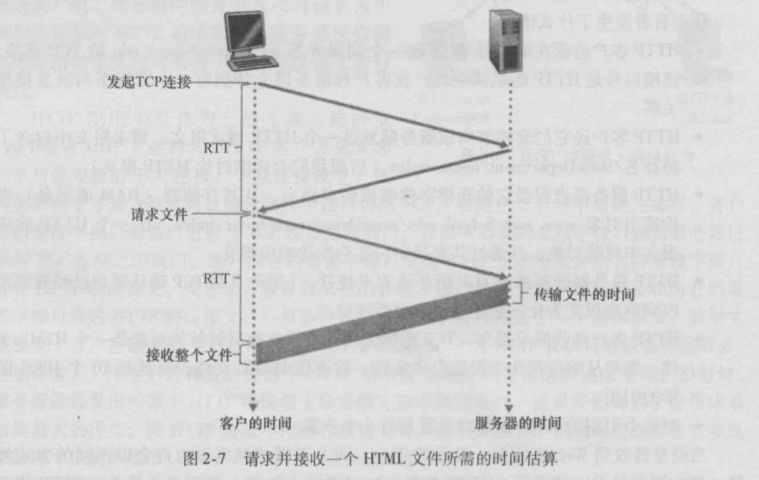
Let’s roughly estimate the time taken from the client requesting the basic HTML file to the client receiving the entire file. For this, we provide the definition of Round-Trip Time (RTT), which is the time taken for a short packet to travel from the client to the server and back to the client. RTT includes packet propagation delays, queuing delays at intermediate routers and switches, and packet processing delays. Now consider what happens when a user clicks a hyperlink. As shown in Figure 2-7, this causes the browser to initiate a TCP connection between it and the Web server; this involves a “three-way handshake” process. The client sends a small TCP segment to the server, the server responds with a small TCP segment to acknowledge, and finally, the client returns the acknowledgment to the server. The time for the first two parts of the three-way handshake occupies one RTT. After completing the first two parts of the handshake, the client sends an HTTP request message to that TCP connection along with the third part of the handshake (the acknowledgment). Once that request message reaches the server, the server sends the HTML file over that TCP connection. The HTTP request/response takes another RTT. Therefore, roughly speaking, the total response time is two RTTs plus the time the server takes to transmit the HTML file.
2. HTTP Using Persistent Connections
Non-persistent connections have some drawbacks. First, a brand new connection must be established and maintained for each requested object. For each such connection, TCP buffers and TCP variables must be allocated in both the client and server, which places a significant burden on the Web server, as a single Web server may serve hundreds of different client requests simultaneously. Second, as we have just described, each object experiences a delivery delay of two RTTs, with one RTT for creating TCP and another RTT for requesting and receiving an object.
When using persistent connections, the server keeps the TCP connection open after sending the response. Subsequent request and response messages between the same client and server can be sent over the same connection. In particular, a complete Web page (the basic HTML file plus the 10 images in the previous example) can be transmitted using a single persistent TCP connection. Moreover, multiple Web pages located on the same server can be sent to the same client over a single persistent TCP connection. Requests for these objects can be sent one after the other without waiting for responses to pending requests (pipelining). Generally, if a connection has not been used for a certain period (a configurable timeout), the HTTP server will close that connection. The default mode of HTTP is to use persistent connections with pipelining.
3. HTTP Message Format
HTTP messages come in two types: request messages and response messages.
1. HTTP Request Message
Below is a typical HTTP request message:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
By closely examining this simple request message, we can learn a lot. First, we see that the message is written in plain ASCII text, and it consists of 5 lines, each ending with a carriage return and line feed. An additional carriage return and line feed follow the last line. A request message can have more lines or at least one line. The method field of the request line can take several different values, including GET, POST, HEAD, PUT, and DELETE. When the browser requests an object, it uses the GET method, with the URL field carrying the identifier of the requested object; in this case, the browser is requesting the object /somedir/page.html. Its version field is self-explanatory; in this case, the browser implements HTTP/1.1. Now let’s look at the header lines in this example. The header line Host: www.someschool.edu indicates the host where the object is located. You might think that this header line is unnecessary since there is already a TCP connection in that host, but the information provided by this header line is required by Web proxy caches. By including the Connection: close header line, the browser tells the server that it does not wish to use a persistent connection and requests the server to close the connection after sending the requested object. The User-agent: header line specifies the user agent, which is the type of browser sending the request to the server. Here, the browser type is Mozilla/5.0, which is Firefox. This header line is useful because servers can effectively send different versions of the same object to different types of user agents (each version addressed by the same URL). Finally, the Accept-language: header line indicates that the user wants the French version of the object. If the server does not have such an object, it should send its default version.
Next, let’s take a look at the general format of a request message as shown in Figure 2-8. You may notice that after the header line (and the additional carriage return and line feed), there is an “entity body”. The entity body is empty when using the GET method, while it is used when the POST method is employed. When users submit forms, HTTP clients often use the POST method. For example, when users provide search keywords to a search engine, they use the POST method. When using a POST message, users can still request a Web page from the server, but the specific content of the Web page depends on the values entered in the form fields. If the value of the method field is POST, then the entity body contains the input values from the form fields.

Of course, it would be remiss not to mention that “request messages generated by forms do not have to use the POST method”. HTML forms often use the GET method and include the input data in the requested URL (in the form fields). For example, a form using the GET method with two fields filled with “monkeys” and “bananas” would result in a URL structure of www.somesite.com/animalsearch? monkeys&bananas.
HEAD method is similar to GET method. When the server receives a request using the HEAD method, it will respond with an HTTP message but will not return the requested object. Application developers often use the HEAD method for debugging purposes. The PUT method is often used in conjunction with Web publishing tools, allowing users to upload objects to specified paths (directories) on the specified Web server. PUT is also used by applications that need to upload objects to the Web server. The DELETE method allows users or applications to delete objects on the Web server.
2. HTTP Response Message
Below is a typical HTTP response message. This response message could be a response to the request message we just discussed.
HTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data …)
Let’s take a closer look at this response message. The entity body part is the main part of the message, which contains the requested object itself (represented as data data data data data …). Now let’s look at the header lines. The server uses the Connection: close header line to inform the client that it will close the TCP connection after sending the message. The Date: header line indicates the date and time the server generated and sent the response message. It is worth noting that this time does not refer to when the object was created or last modified; rather, it is the time the server retrieved the object from its file system, inserted it into the response message, and sent the response message. The Server: header line indicates that the message was generated by an Apache Web server, similar to the User-agent: header line in the HTTP request message. The Last-Modified: header line indicates the creation or last modification date and time of the object. The Last-Modified: header line is very important for caching of the object, which may exist both locally on the client and on network cache servers (proxy servers). Content-Length: header line indicates the number of bytes in the object being sent. Content-Type: header line indicates that the object in the entity body is HTML text. (The type of the object should be indicated formally by the Content-Type: header line rather than by the file extension.)

After looking at one example, let’s check the general format of the response message (as shown in Figure 2-9). We should also mention the status codes and their corresponding phrases. Status codes and their associated phrases indicate the result of the request. Some common status codes and their related phrases include:
-
200 OK: The request was successful, and the information is in the returned response message.
-
301 Moved Permanently: The requested object has been permanently moved, with the new URL defined in the Location: header line of the response message. **Client software will automatically fetch the new URL.
-
400 Bad Request: A general error code indicating that the request cannot be understood by the server.
-
404 Not Found: The requested document is not on the server.
-
505 HTTP Version Not Supported: The server does not support the HTTP protocol version used by the request message.
Would you like to see a real HTTP response message? It’s easy to do. First, log in to your favorite Web server using Telnet, then enter a single line request message to request some objects stored on that server.
After entering telnet www.baidu.com 80 in the Linux terminal, you will see something like this:

Then press ctrl + ] to bring up the telnet command line, and you will see something like this:
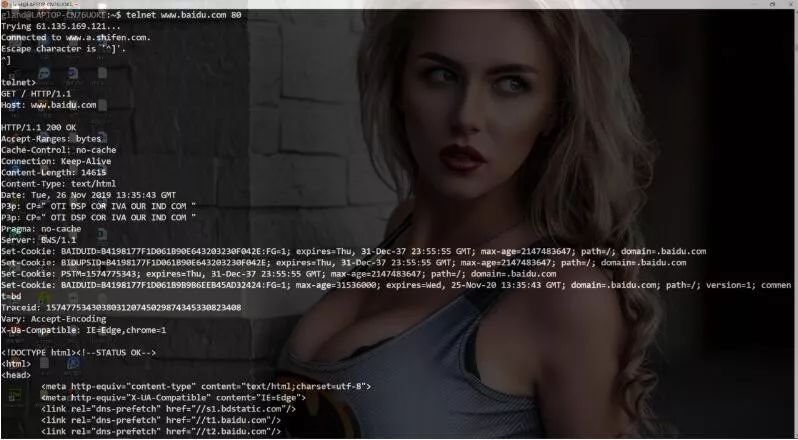
Press the enter key, then enter the HTTP request, and you will finally receive the HTTP response as follows:
In the telnet command line, enter quit to exit telnet, as shown in the following image:
