HTTP Protocol
<span>HTTP</span> protocol (HyperText Transfer Protocol) is an application layer protocol based on TCP. In simple terms, it is a set of rules for data transmission between clients and servers.-
Hypertext: Refers to text that exceeds simple text, including images, audio, video, and other files. -
Transmission Protocol: Refers to the use of a common agreed-upon fixed format to transmit hypertext content converted into strings. -
Default Port Number: 80
-
SSL encrypts the content being transmitted (hypertext, which is the request body or response body).
Requests
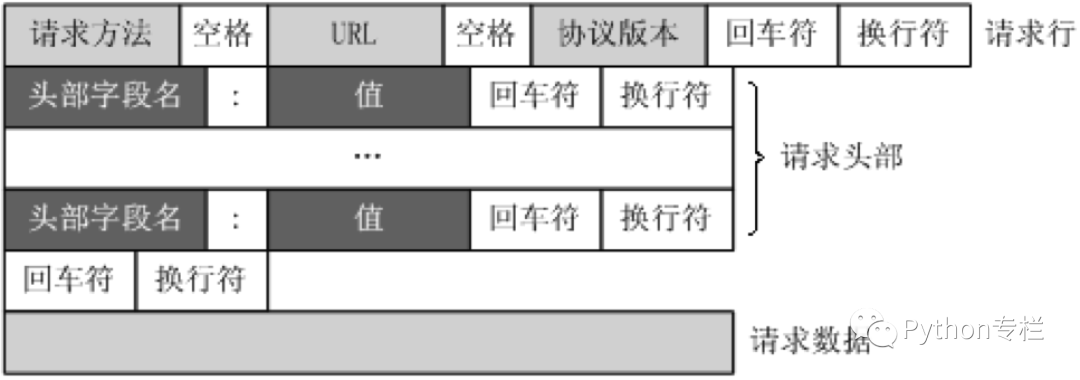
The methods in the HTTP protocol are: GET: Request to retrieve the resource identified by the Request-URI.<span>POST</span>: Add new data to the resource identified by the Request-URI.HEAD: Request to retrieve the response headers for the resource identified by the Request-URI.<span>PUT</span>: Request the server to store or modify a resource identified by the Request-URI.<span>DELETE</span>: Request the server to delete the resource identified by the Request-URI.<span>TRACE</span>: Request the server to return the received request information, mainly for testing or diagnostics.<span>CONNECT</span>: Reserved for future use.<span>OPTIONS</span>: Request to query the server’s performance or options and requirements related to the resource.
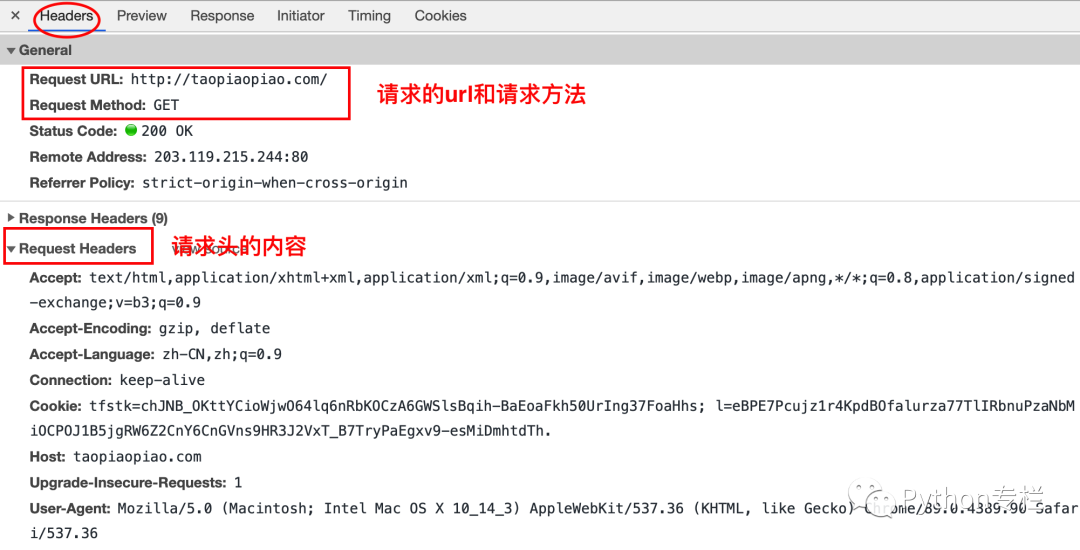
Request Headers Particularly Important for Web Scraping

-
Content-Type -
Host (host and port number) -
Connection (connection type) -
Upgrade-Insecure-Requests (upgrade to HTTPS request) -
User-Agent (browser name) -
Referer (the page where the request originated) -
Cookie (cookie) -
Authorization (for representing authentication information required for resources in the HTTP protocol, such as JWT authentication used in previous web courses)
The bolded request headers are commonly used and are most frequently employed by servers to identify web scrapers. Compared to other request headers, they are more important. However, it is important to note that this does not mean the others are unimportant, as some website administrators or developers may use less common request headers to identify web scrapers.
Responses

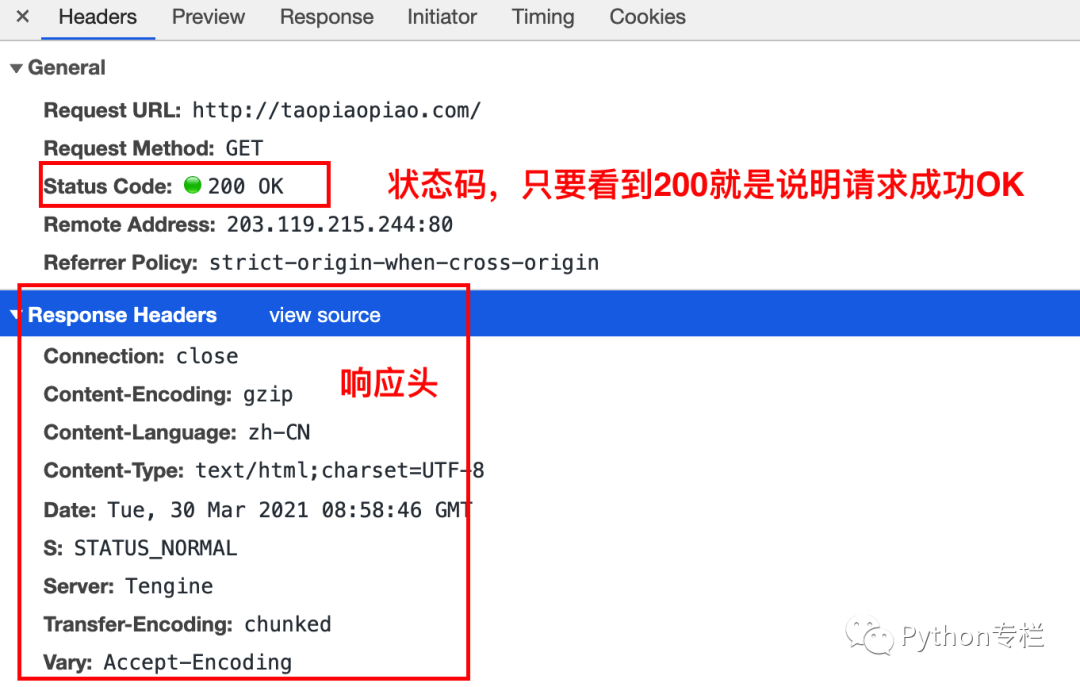
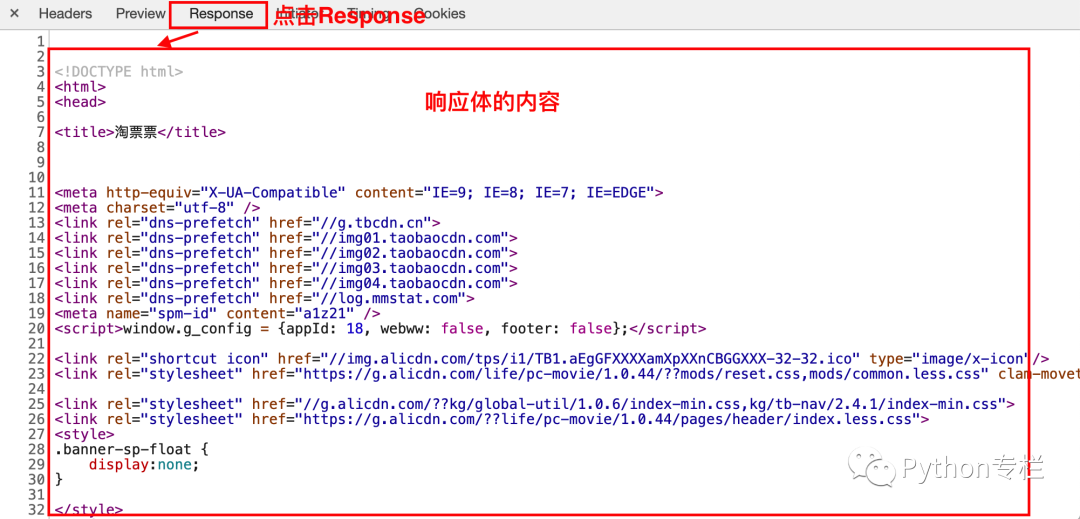
Status codes consist of three digits, with the first digit defining the category of the response, which can have five possible values: 1xx: Informational – indicates that the request has been received and is continuing to process.<span>2xx</span>: Success – indicates that the request has been successfully received, understood, and accepted.3xx: Redirection – indicates that further action is needed to complete the request.<span>4xx</span>: Client Error – indicates that there is a syntax error in the request or the request cannot be fulfilled.<span>5xx</span>: Server Error – indicates that the server failed to fulfill a legitimate request.Common status codes: <span>200</span>: OK – client request succeeded.<span>400</span>: Bad Request – client request has syntax errors and cannot be understood by the server.<span>401</span>: Unauthorized – request is unauthorized; this status code must be used with the<span>WWW-Authenticate</span>header field.<span>403</span>: Forbidden – the server received the request but refuses to provide the service.<span>404</span>: Not Found – the requested resource does not exist, e.g., an incorrect URL was entered.<span>500</span>: Internal Server Error – the server encountered an unexpected error.<span>503</span>: Server Unavailable – the server cannot currently handle the client’s request; it may recover after some time.
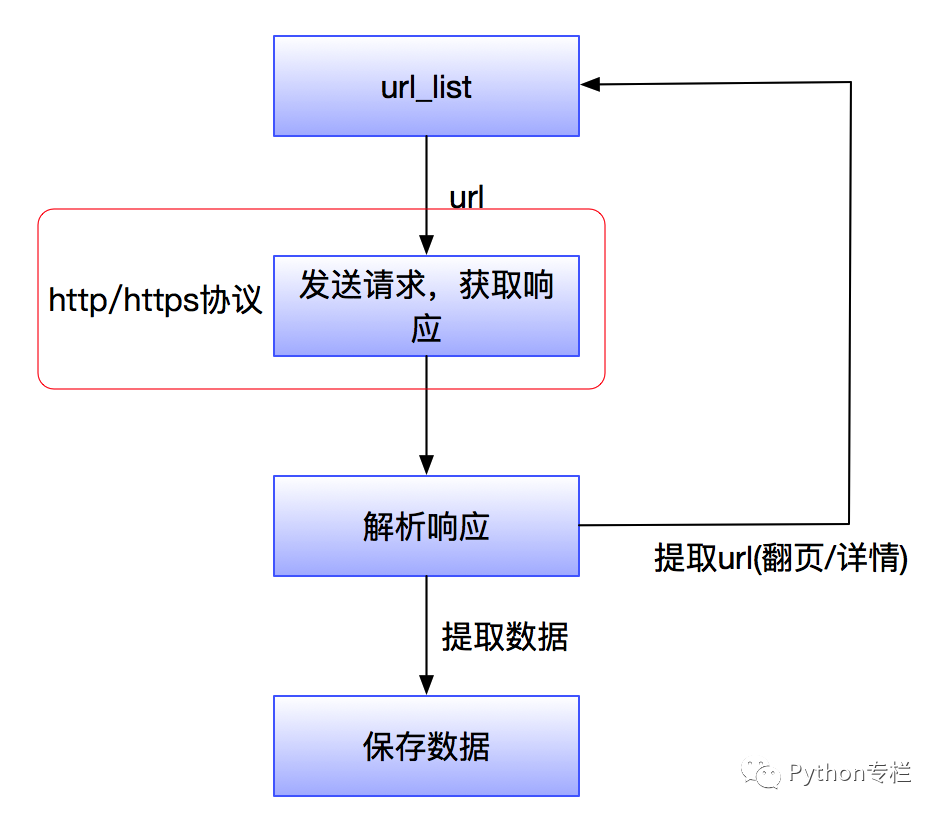
Thus, when the browser makes a request, the process is as follows:
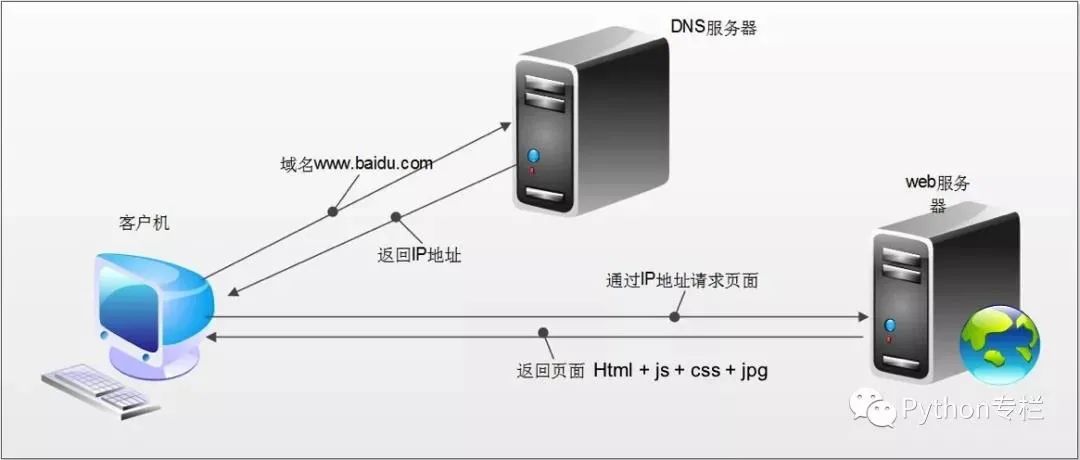
Process of HTTP requests:
1. Whenever we visit any website, we enter the domain name in the browser’s address bar, such as: http://www.baidu.com. Because domain names are easier to remember! We never remember Baidu’s IP address. However, the identification process is completed by the DNS domain name resolution server, which can find the matching IP address based on the entered domain name and inform you of the IP address.
2. After the browser obtains the IP corresponding to the domain name, it begins to make requests and obtain responses.
3. The returned response content (HTML) will include URLs for CSS, JS, images, etc., as well as AJAX code. The browser will sequentially send other requests based on the order in the response content and obtain corresponding responses.
4. The browser adds (loads) the results displayed for each response obtained. JS, CSS, and other content can modify the page content, and JS can also send requests again to obtain responses.
5. From obtaining the first response and displaying it in the browser until all responses are finally obtained, this process is called browser rendering.