Follow our public account to discover the beauty of CV technology
The top international conference in the field of reconfigurable computing, FPGA 2025, has announced that this year’s Best Paper Award goes to Wuwen Xinqiong and the collaborative work on video generation large model inference IP, FlightVGM, from Shanghai Jiao Tong University and Tsinghua University. This is the first time the FPGA conference has awarded this honor to research led entirely by a research team from mainland China, and it is also the first time a team from an Asia-Pacific country has received this accolade.

This work achieves efficient inference of video generation models (Video Generation Models, VGMs) on FPGA for the first time, and is the latest in a series of works following the team’s acceleration of the large language model FlightLLM on FPGA last year (FPGA’24). Compared to the NVIDIA 3090 GPU, FlightVGM achieves a 1.30 times performance improvement and a 4.49 times energy efficiency improvement on the AMD V80 FPGA (with a peak computing power gap exceeding 21 times).

- Paper link: https://dl.acm.org/doi/10.1145/3706628.3708864
The first author of the paper, Liu Jun, is a PhD student at Shanghai Jiao Tong University, and the co-first author, Zeng Shulin, is a postdoctoral researcher at Tsinghua University. The corresponding authors are Wang Yu and Dai Guohao. Wang Yu is an IEEE Fellow, a professor and department head of the Department of Electronic Engineering at Tsinghua University, and the initiator of Wuwen Xinqiong. Dai Guohao is an associate professor at Shanghai Jiao Tong University and a co-founder and chief scientist of Wuwen Xinqiong.
The last related work from Tsinghua’s Department of Electronics included in the FPGA international conference dates back to 2016 with “Going Deeper with Embedded FPGA Platform for Convolutional Neural Network” and 2017’s “ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA.” The former catalyzed the founding of Deep Vision Technology, while the latter was awarded the only Best Paper of that year by the FPGA international conference, leading to Deep Vision Technology’s acquisition by programmable chip manufacturer Xilinx for $300 million in 2018.
In the context of ongoing industry debates about the cost of deploying large models, using flexible programmable hardware such as FPGA and ASIC, along with dedicated task integrated circuits, to enhance hardware operational efficiency may become the key factor in improving the efficiency and reducing the costs of large model implementations.
In 2024, Wuwen Xinqiong was highly praised for its large language model custom inference IP FlightLLM, and this year it again won the Best Paper Award with the VGM model custom inference IP FlightVGM, both achieved through innovative hardware architecture to enhance efficiency.
It is reported that this series of research results has now been integrated into Wuwen Xinqiong’s self-developed large model inference IP LPU (Large-model Processing Unit) and has begun collaborative verification with partners. Below is an interpretation of the core content of the paper for readers to enjoy.
Background
In the field of video generation, the diffusion Transformer (DiT) has gradually become an important framework. The DiT model generates video through a diffusion process, gradually restoring noisy images to clear video frames, demonstrating strong generative capabilities.
Initially, DiT was proposed to explore scalability in large-scale data processing. With continuous technological advancements, the architecture of DiT has been optimized, progressively improving the quality and resolution of generated videos, making them clearer and more detailed.
However, this method has very high computational demands, especially when generating high-resolution and longer-duration videos, leading to significant increases in required computation and memory consumption. Therefore, how to enhance generation efficiency and optimize the computation process has become one of the key issues in this field.
Core Insights: From Video Compression to Video Generation
Video compression technologies (such as H.264, H.265) identify and eliminate redundant information between and within video frames through techniques like discrete cosine transform (DCT), achieving compression rates of up to 1000 times. The core idea here is that video data contains a large number of repetitive patterns in both time and space dimensions, such as the background remaining almost unchanged between adjacent frames or similar textures within the same frame. By detecting and skipping this redundant information, compression algorithms can significantly reduce data volume while maintaining video quality.
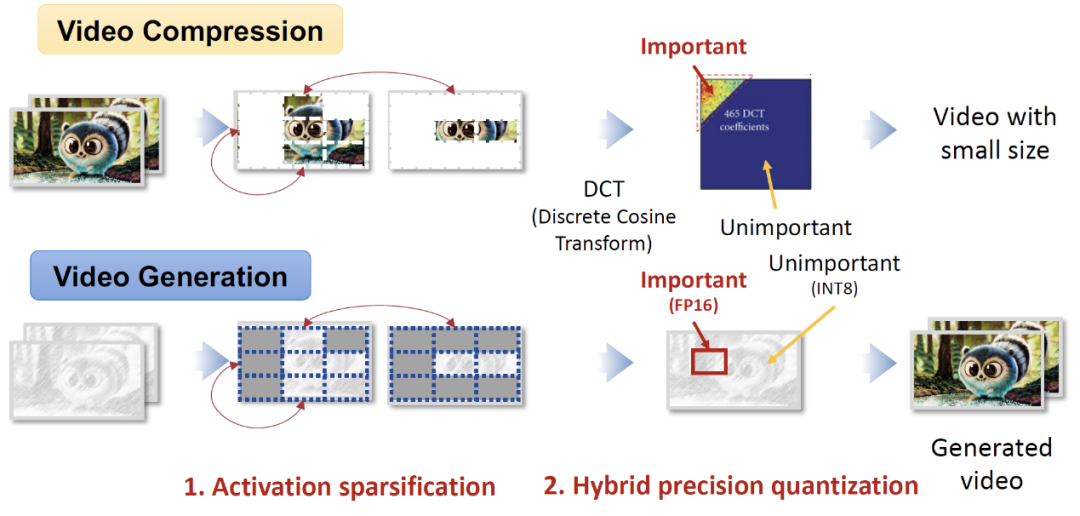
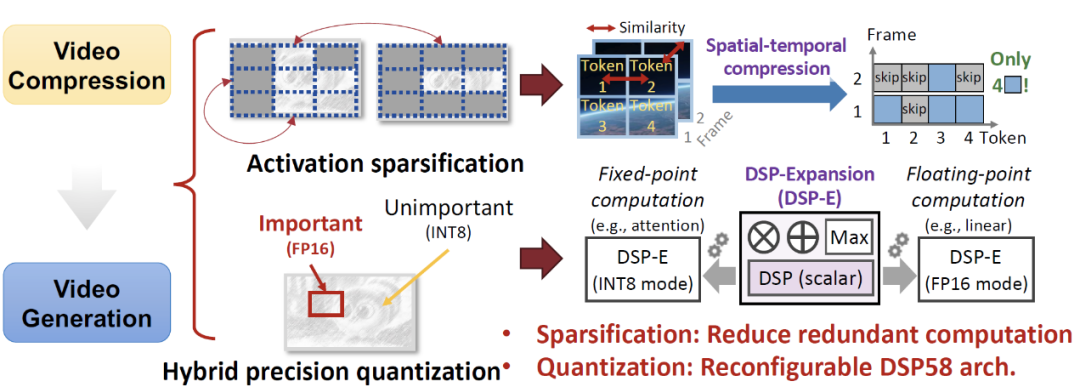
FlightVGM innovatively introduces this idea into the acceleration of video generation models. Video generation models (VGMs) also exhibit significant spatiotemporal redundancy during inference. For example, tokens between adjacent frames are semantically highly similar, and different regions within the same frame may share the same visual features. However, existing GPU architectures cannot fully exploit this redundancy. While FPGA has advantages in sparse computation, its peak computing power is far lower than that of GPUs, and its traditional design of computing units (such as DSP58 in V80) cannot dynamically adapt to mixed precision requirements, limiting its application in video generation acceleration. FlightVGM addresses these challenges through the following three technologies:
- “Time-Space” Online Activation Value Sparsification Method: Based on the similarity detection idea in video compression, FlightVGM designs a redundancy activation sparsification mechanism for inter-frame and intra-frame. By calculating cosine similarity, it dynamically skips the computation of similar parts, significantly reducing the computational load.
- “Floating-Point-Fixed-Point” Mixed Precision DSP58 Expansion Architecture: Drawing on the block processing idea in video compression, FlightVGM performs precision stratification on different modules of the video generation model. Key modules (such as attention mechanisms) retain FP16 precision, while non-key modules (such as linear layers) are quantized to INT8, maximizing hardware utilization.
- “Dynamic-Static” Adaptive Scheduling Strategy: To address the load imbalance caused by online activation value sparsification, FlightVGM adaptively adjusts the execution order of different operation loads based on actual workloads, thereby improving computational utilization.
Technical Highlights
“Time-Space” Online Activation Value Sparsification Method
We propose a “time-space” online activation value sparsification method that considers both inter-frame and intra-frame similarities. The core idea of activation sparsification is: if two tokens are highly similar, only one token needs to be computed, and the result can be shared with the other token. Specifically, the input activation is a 3D tensor processed from noisy video by the tokenizer. Therefore, the input activation can be represented as , where represents the number of frames, represents the number of tokens per frame, and represents the hidden dimension. For simplicity, we denote the first token of the first frame as (). For the input activation , we use and to represent the reference vector and input vector. We use cosine similarity as the metric.
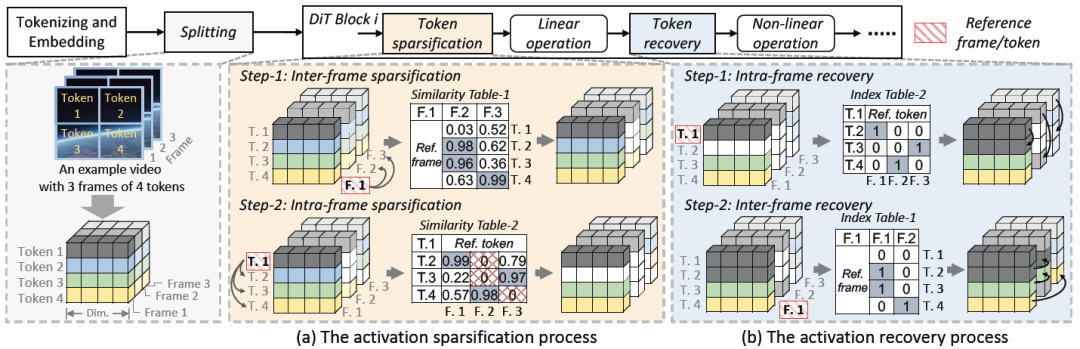
Activation sparsification consists of two steps: inter-frame sparsification and intra-frame sparsification.
- Inter-frame Sparsification: We divide the input activation into G consecutive groups and select the middle frame as the reference frame. The tokens of the remaining frames are compared with the tokens of the reference frame one by one for similarity. If the similarity exceeds a threshold, the result computed using the reference frame’s token is used to replace the current token.
- Intra-frame Sparsification: We divide the tokens of each frame into K blocks, selecting the middle token as the reference token, and calculate the similarity of other tokens with the reference token. If the similarity exceeds a threshold, the reference token is used to replace the computation. If a token has already been pruned in inter-frame sparsification, its similarity is 0.
From a computational perspective, similarity calculation requires one inner product and two norm calculations, resulting in a computational load of 3d, where d is the hidden dimension. For example, in a linear operation, if the size of the input activation is and the size of the weight matrix W is , the computational load of the original operation is . For the sparse operation, considering the additional computation brought by inter-frame and intra-frame sparsification, if the sparsity is s, the total computational load for the sparse operation is:
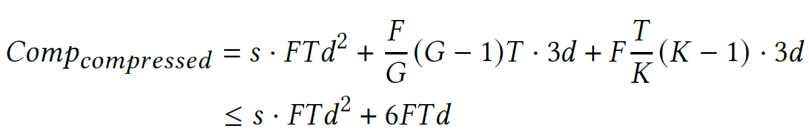
Since the original computational load includes a quadratic term of d, while the additional computation introduced by sparsification is only a linear term of d (with a typical value of d=1152), the extra overhead introduced by sparsification can be almost ignored.
“Floating-Point-Fixed-Point” Mixed Precision DSP58 Expansion Architecture
The AMD V80 FPGA is equipped with hardware IP DSP58, supporting various computation modes such as scalar, vector, and floating-point configurations. However, since these configurations cannot be dynamically switched at runtime, this conflicts with the mixed precision requirements of video generation models, preventing us from fully utilizing the computational potential of DSP58.
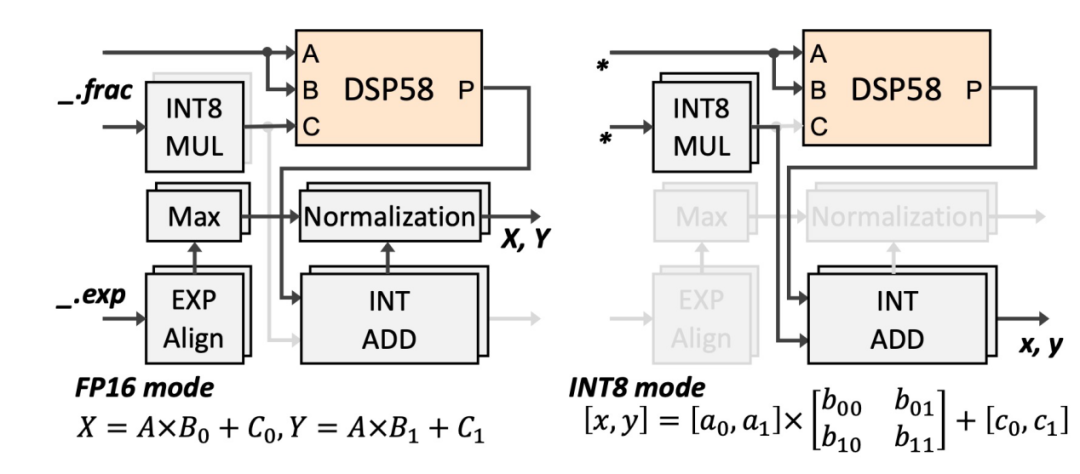
To address this issue, we propose an innovative FP16-INT8 mixed precision hardware architecture based on DSP58—DSP-Expansion (DSP-E). This architecture allows for runtime configuration, supporting two FP16 multiply-accumulate units (MAC) or four INT8 multiply-accumulate units.
Our core idea is to resolve the data confusion issue when one DSP58 executes two FP16 fractional multiplications by introducing additional multipliers that can also be reused in INT8 mode. In FP16 mode, DSP58 performs two MAC fractional multiplications and obtains the correct intermediate computation result by subtracting the result of the INT8 multipliers. The exponent part of the intermediate result is computed using INT adders, and the final result is obtained through addition, normalization, and rounding after exponent alignment and adjustment unit alignment of the decimal point.
In INT8 mode, DSP-E maximizes computational performance by reusing DSP58, two INT8 multipliers, and two INT adders. By inputting related data into different ports, additional logic units can reuse hardware resources, effectively increasing computational throughput.
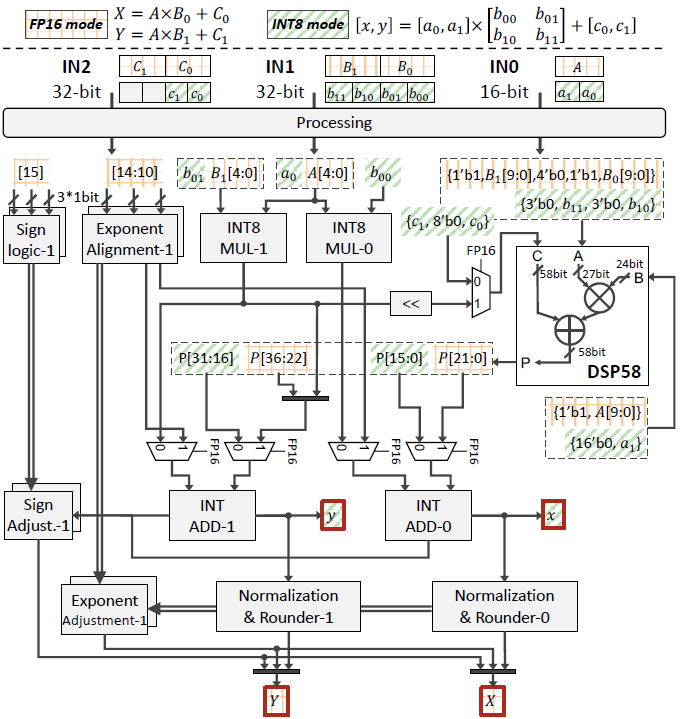
To achieve maximum throughput under constraints of computational precision and hardware resources, we propose a heterogeneous DSP58 array design to accommodate different computational needs. We evaluate based on the resource consumption of different designs (including DSP, LUT, REG, RAM, etc.) and ensure optimal computational performance through resource constraints. Additionally, we consider the ratio of INT8 to FP16 computational performance to measure the improvement in computational capability.
Experimental Results
Algorithm Evaluation
Compared to the baseline model, FlightVGM has a negligible impact on model accuracy (with an average loss of only 0.008), while using full INT8 quantization results in an average loss of 0.042. Moreover, in terms of actual video generation effects, the videos generated by FlightVGM still maintain good fidelity to the original model.

Performance Evaluation
For the NVIDIA 3090 GPU, the peak computing power gap with the AMD V80 FPGA exceeds 21 times under FP16 precision. However, FlightVGM implemented on the V80 FPGA still surpasses the GPU in both performance and energy efficiency.
This is because FlightVGM fully exploits the inherent sparse similarity and mixed precision data distribution characteristics of VGMs, and through software-hardware collaboration, opens up a new optimization space of “algorithm-software-hardware” and successfully finds a sufficiently good solution within it. In contrast, due to hardware architecture limitations, GPUs struggle to achieve the same acceleration effects and lack support for sparse and customized computational data flow optimization.

Outlook and Future Work
As the computational demands of VGMs grow, FlightVGM demonstrates how to achieve higher energy efficiency in video generation large model inference through FPGA’s software-hardware collaborative innovation. In the future, by exploring a new FPGA architecture with AIE (AI Engine) + HBM (High Bandwidth Memory), FPGAs are expected to provide more efficient computational support for video generation tasks, becoming an important choice for future computing platforms.
For the latest AI progress reports, please contact: [email protected]

END
Welcome to join the “Video Generation“ discussion group👇 Please note:Generation
