Machine Heart Column
Machine Heart Editorial Team
As we enter the era of Industry 4.0, the introduction of digitalization and automation has made production environments more efficient. At the same time, the potential value of the massive data generated by smart devices has garnered attention. However, how to efficiently store the data produced by smart devices and how to better analyze the vast amounts of data have become challenges. Traditional database models and storage methods are evidently unable to meet such demands. This led to the emergence of time-series databases, which aim to achieve efficient data storage and querying, helping to better uncover the potential value of data.
In response to this situation, Tsinghua University initiated the development of IoTDB in 2015. On September 23, 2020, Apache IoTDB graduated to become an Apache Top-Level Project, making it the only top-level project initiated by a Chinese university within the Apache Foundation, and the only open-source project in the field of IoT data management under the Apache Foundation. In October 2021, the core team of Apache IoTDB founded Tianmou Technology to continue operating IoTDB and assist industrial users in solving the challenges of data storage, querying, and usage.
Regarding the core technologies developed for Apache IoTDB, several participants jointly published a review paper that provides a detailed and comprehensive explanation of the design of IoTDB. The article begins with an industrial company that needs to manage thousands of excavators, describing the requirement: “Data is first packaged into devices and then sent to servers via 5G mobile networks. On the server, the data is written into a time-series database for OLTP queries. Finally, data scientists can load the data from the database into a big data platform for complex analysis and prediction, i.e., OLAP tasks.”

-
Paper link: https://dl.acm.org/doi/abs/10.1145/3589775
-
Project link: https://github.com/apache/iotdb
The paper focuses on the following key aspects:
1. Design of the Data Model: The logical organization of time series and their storage in the physical schema;
2. TsFile File Format: A self-developed columnar storage file format that meets the efficiency requirements for writing and querying;
3. IoTDB Engine: Mainly includes storage engine, query engine, etc.;
4. Distributed Solutions.
Next, we will provide a more detailed interpretation of these key parts.
Detailed Interpretation
1. Data Model Design
(1) As shown in the figure below, a tree structure is adopted to meet the extremely high intensity of write operations and effectively handle the common issue of delayed data arrival in IoT scenarios.
In the tree, each leaf node corresponds to a sensor, and each sensor has its corresponding parent device, as shown in the bottom two layers of the figure, and similarly upwards.
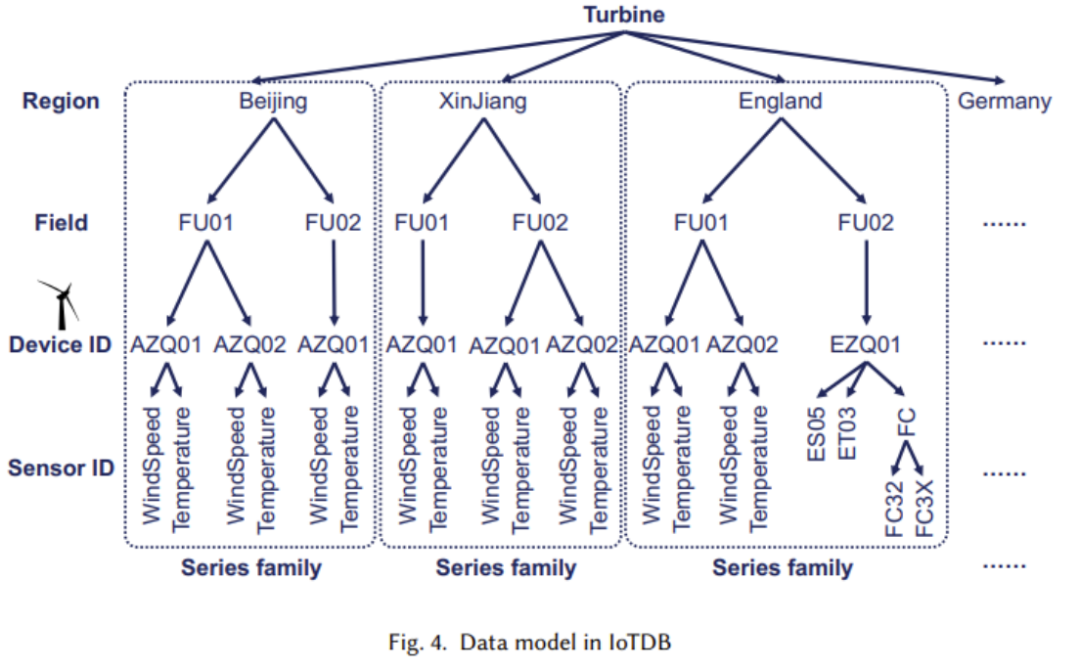
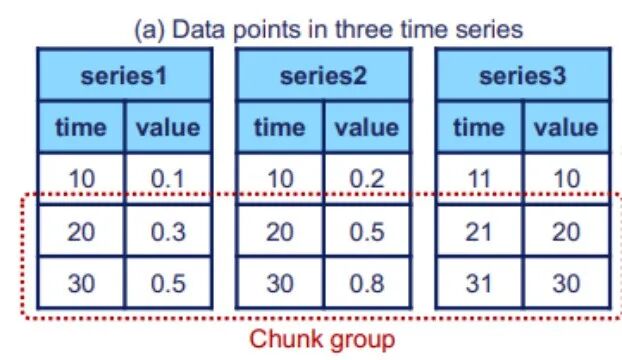
(2) The logical structure described earlier is now implemented in the physical structure, mainly consisting of time series and series families. The figure below shows that each time series consists of two attributes: time and value, and the time series is located through the complete path from the root node to the leaf node. The above figure illustrates the concept of a series family, which may contain multiple devices, and their data will be stored together in TsFile (a file structure that will be explained later).
2. Design of the TsFile File Format
TsFile is Apache IoTDB’s self-developed columnar storage file format. The structure is shown in the figure below:
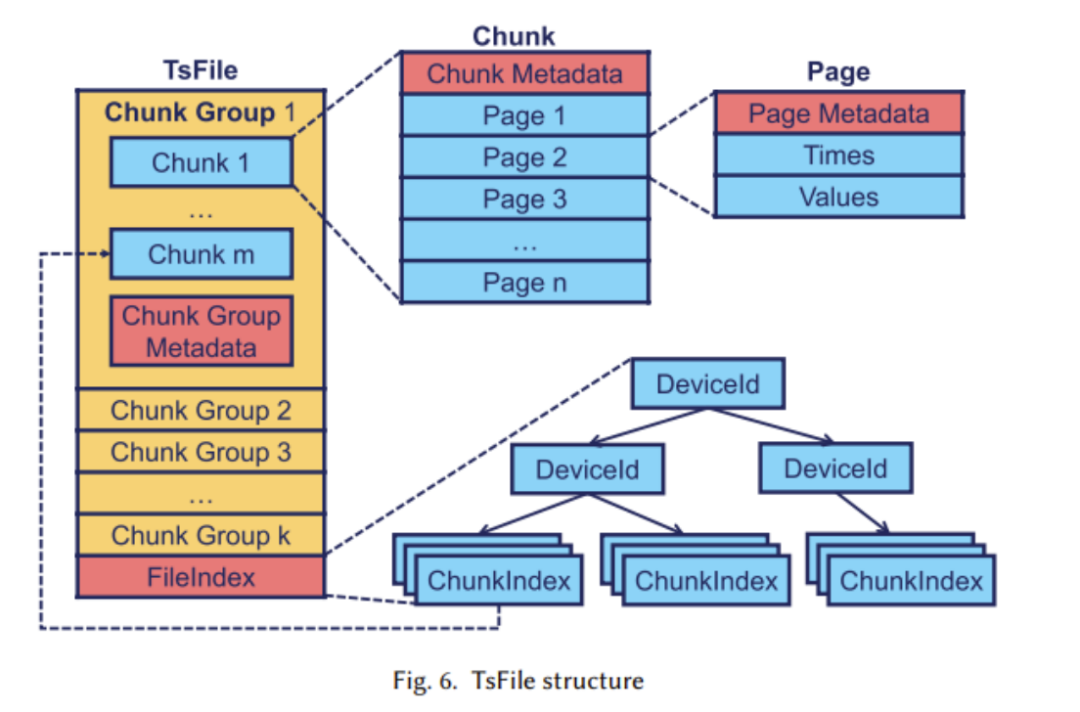
During the design process of TsFile, the research team mainly addressed the following issues:
-
Saving space by compressing data as much as possible
-
Reducing the number of files
-
Physical proximity of time series that will be queried together
-
Reducing disk fragmentation
-
Efficient access
The main solutions provided include:
-
Columnar storage: Eliminates null values, saving disk space; data access locality
-
Time series encoding: Utilizes the unique characteristics of time series in IoT scenarios
-
Frequency domain encoding: Widely used in signal processing for frequency domain analysis of time series
-
Specific structural analysis: Pages are the basic storage unit, a chunk contains multiple pages, and pages within a chunk belong to the same time series with variable sizes; a chunk group contains multiple chunks, and multiple chunks in a group belong to one or more series of devices written within the same time period, placed in contiguous disk space because they are often queried together; blocks are in memory, and written block groups are first buffered in memory, and when the memory reaches a threshold, all block groups are flushed to TsFile; the index (FileIndex) records information at the end of the file for data access.
3. IoTDB Engine
In this section, researchers mainly considered delayed arrival in IoT scenarios, efficient query processing, and the design of SQL-like queries. The structure of the IoTDB engine is shown in the figure below:
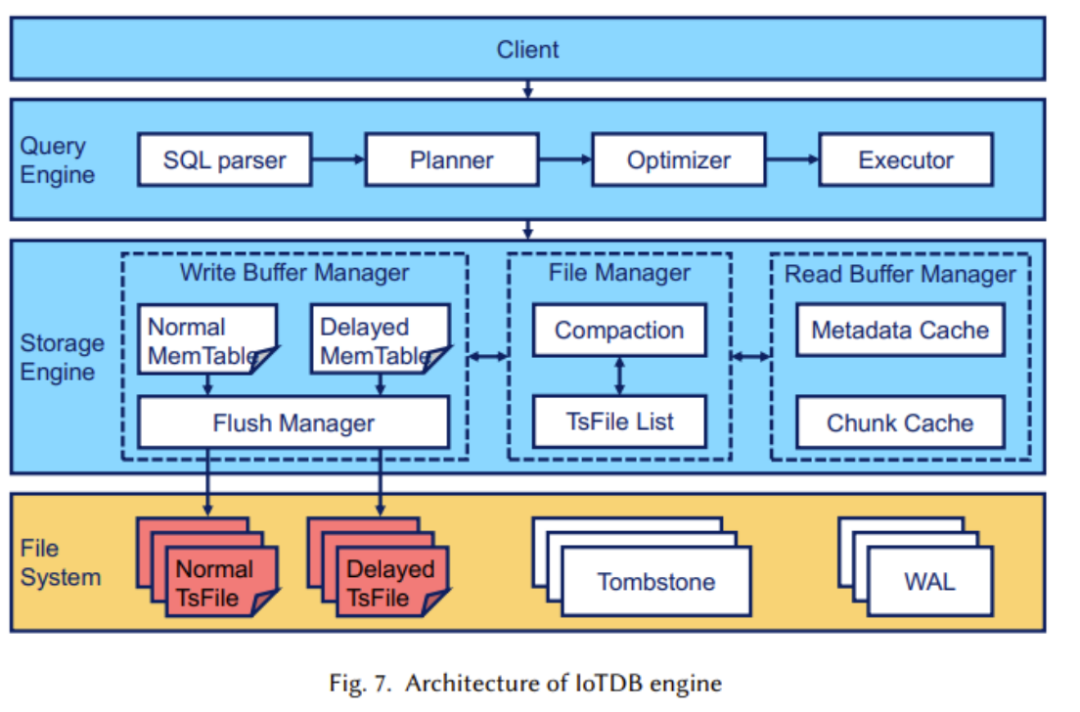
In the figure, we can see that it is mainly used for handling the writing, reading, and management of TsFile, and this part employs automatic delay separation technology (as shown in the figure below):
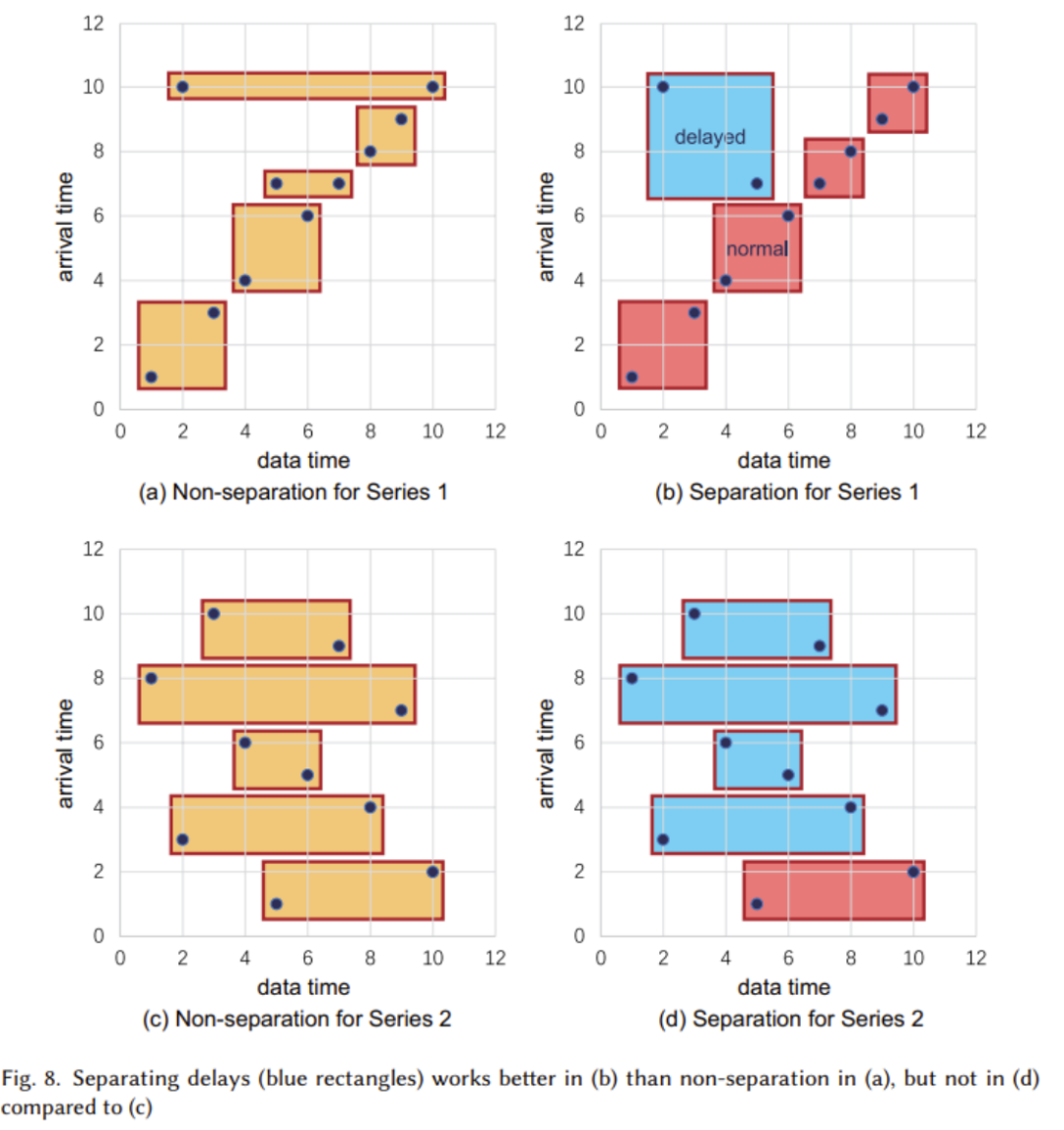
For most cases where there is no time range overlap in normal TsFile, it is recommended to use delayed data separation; for cases where most data is unordered, delayed data separation is not recommended.
Another important component is the query engine, which is responsible for converting SQL queries into operators that can be executed in the database. Additionally, to adapt to industrial IoT scenarios, Apache IoTDB has designed rich queries for time series data.
4. Distributed Solutions
TsFile can be distributed in HDFS and operated by Spark. Additionally, it provides better native solutions for data distribution and query processing, mainly including partition replication, NB-Raft replication, and DYNAMIC read consistency.
Comparison Results
The paper provides comparison results of TsFile and IoTDB against widely used state-of-the-art file formats and time-series databases in the industry, showcasing the advantages of Apache IoTDB in multiple aspects, as shown in the figures below:
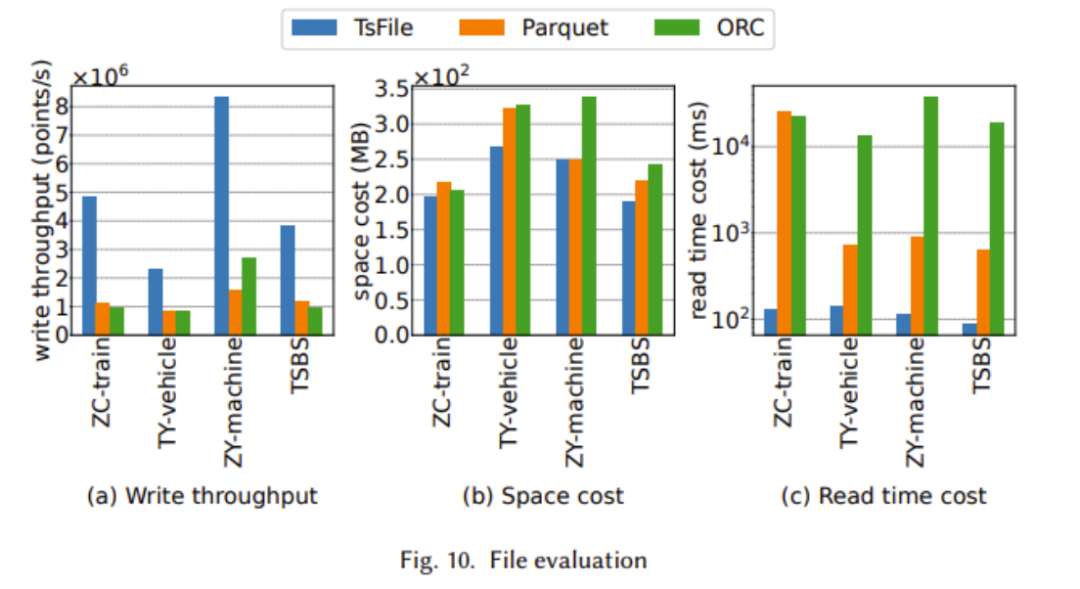
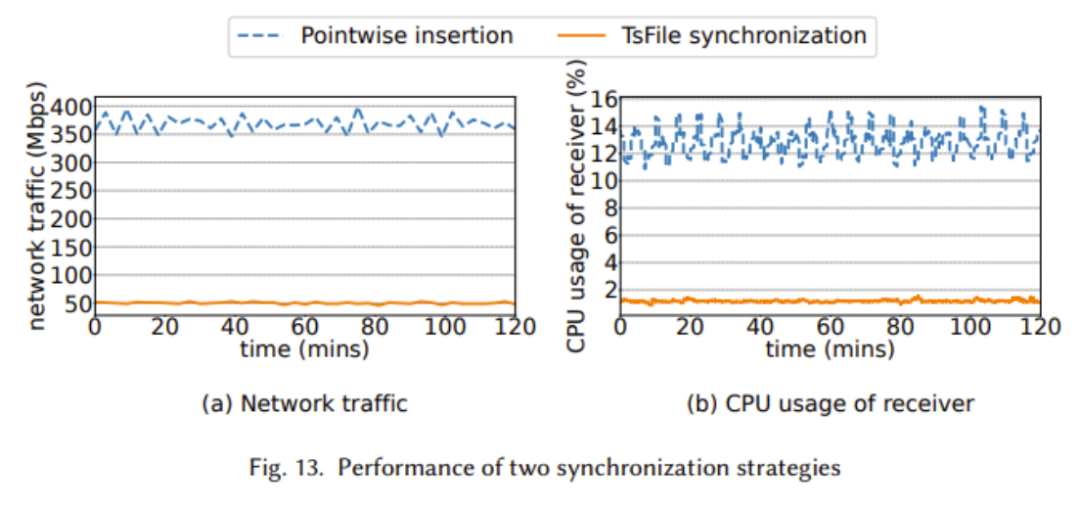
The above two figures show that TsFile outperforms currently widely used solutions in terms of write throughput, read time cost, and synchronization performance. This is mainly due to the IoT-aware structural design of TsFile, which avoids storing redundant information such as deviceId. The reason for the lack of significant advantages in disk usage is that a more refined index has been constructed, leading to more space usage; however, this sacrifice can bring extraordinary improvements in query time, as we can see the significant advantage in read time cost.
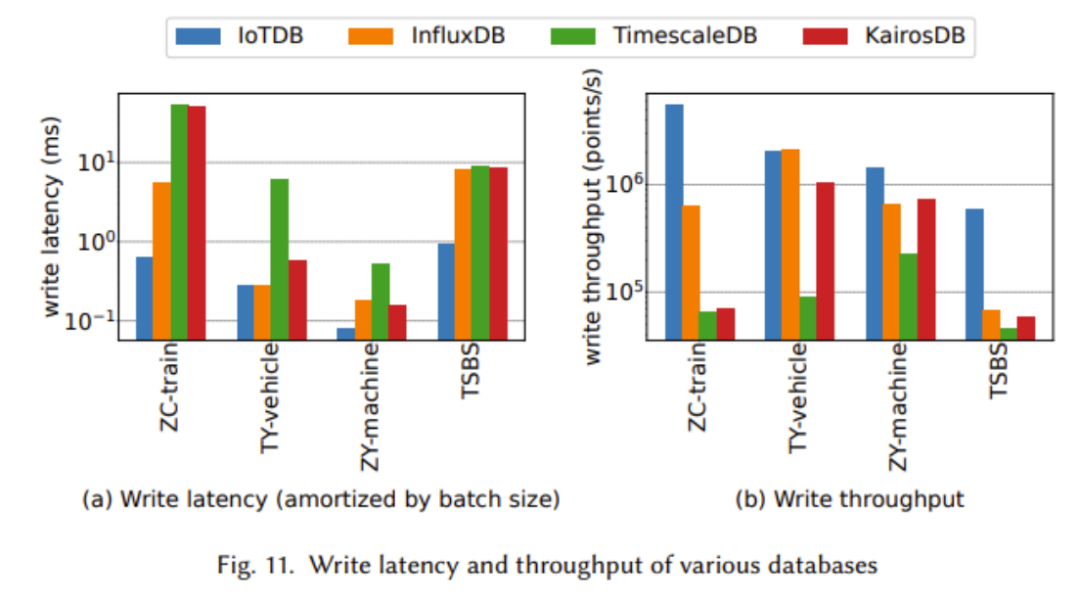
In the figure above, we can see that IoTDB demonstrates better performance in almost all tests, with higher write throughput and lower write latency.
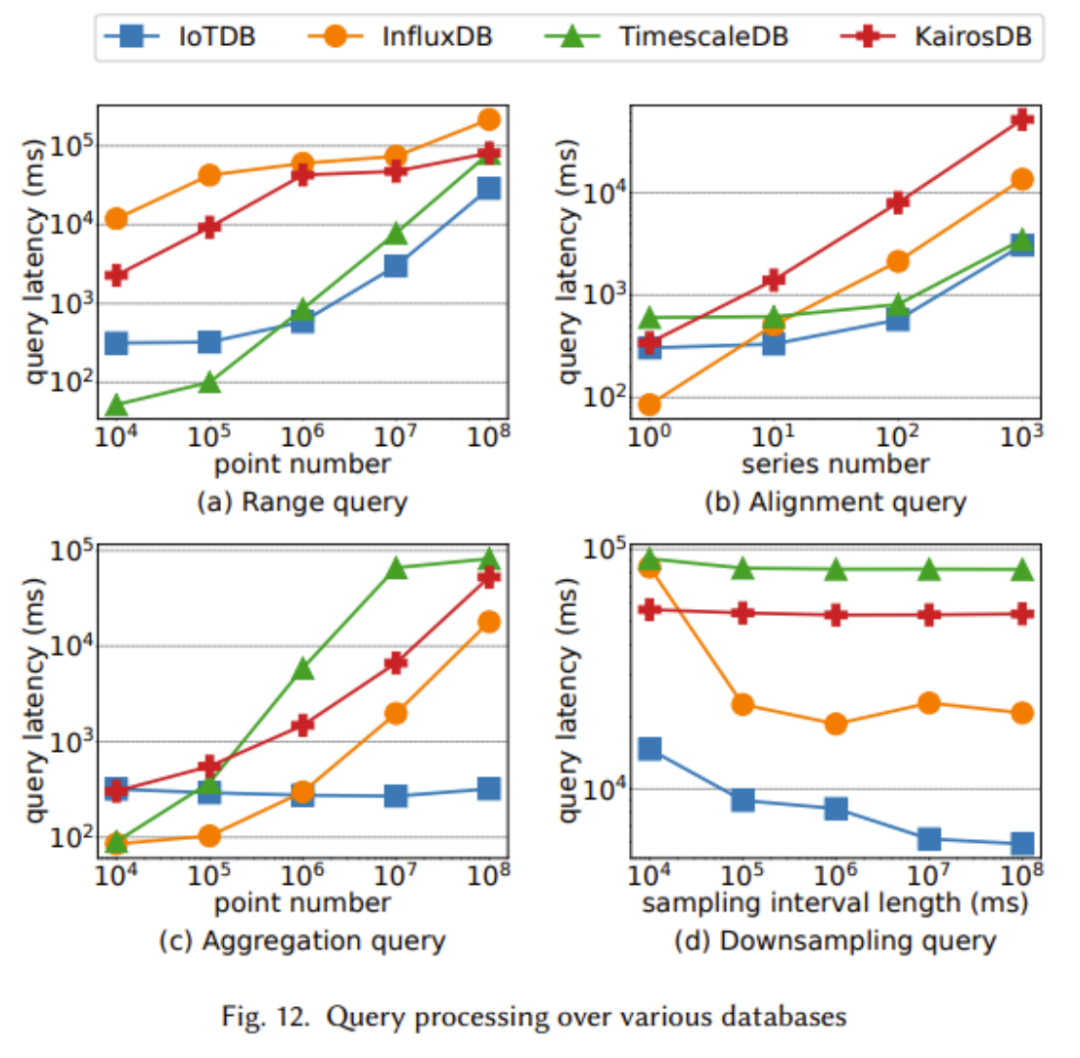
In the experiments shown in the figure above, we can see that when querying large data sets, IoTDB exhibits better performance, and its advantages are particularly significant in large-scale data aggregation.
Conclusion
This paper introduces a new time-series data management system, Apache IoTDB, whose open architecture is specifically designed to support real-time queries and big data analysis for IoT applications. The system includes a new time-series file format, TsFile, which stores time and value in a columnar manner to avoid null values and achieve effective compression. Based on TsFile, the IoTDB engine employs a strategy similar to LSM trees to handle extremely high-intensity writes and address the common issue of delayed data arrival in IoT scenarios. Rich scalable queries, along with pre-computed statistical information in TsFile, enable IoTDB to achieve efficient processing in both OLTP and OLAP tasks.
Based on these technologies, IoTDB has become a new type of database that can better address the challenges of industrial IoT scenarios.

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]