1 TCP/IP
1.1 Definition of TCP/IP
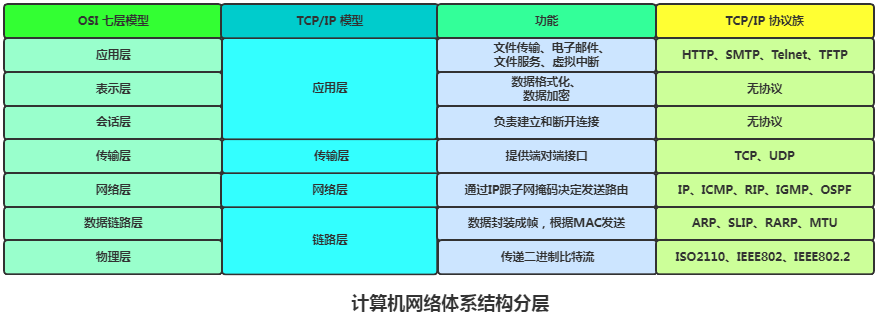
TCP/IP is a suite of protocols, also known as the Internet Protocol Suite. Computers can only communicate by adhering to these rules. TCP and IP are just two of the important protocols, which is why the suite is named TCP/IP. It actually consists of four layers of protocols.
1.2 Functions of TCP/IP
As mentioned earlier, TCP/IP is broadly divided into four layers. Next, we will discuss the specific functions of these four layers.
1.2.1 Application Layer
The application layer provides various network service protocols directly to users, such as HTTP, Email, FTP, etc. These protocols are created to address different needs in real life. Most of the time, users operate and assemble data at this layer, which essentially involves socket programming! The actual data transmission over the network is handled by the three layers below.
1.2.2 Transport Layer
The transport layer provides communication services to the application layer and is the highest layer focused on communication. It provides logical communication for application processes that communicate with each other. It mainly includes the TCP protocol and the UDP protocol.
-
TCP provides connection-oriented data stream support, reliability, flow control, multiplexing, and other services.
-
UDP does not provide complex control mechanisms.
Functions of the Transport Layer:
-
Segmentation and encapsulation of data sent from the application layer.
-
Providing end-to-end transport services.
-
Establishing logical communication between the sending host and the receiving host.
1.2.3 Network Layer
The function of the network layer is to implement routing and forwarding of data packets. Wide area networks typically use many hierarchical routers to connect dispersed hosts or local area networks. Therefore, the two communicating hosts are generally connected through multiple intermediate node routers. The task of the network layer is to select these intermediate nodes to determine the communication path between the two hosts. It also hides the details of the network topology from the upper layer protocols, making it appear to the transport layer and network applications that the two communicating parties are directly connected.
The IP protocol operates at this layer, providing routing and addressing functions that allow two terminal systems to interconnect and determine the best path, while also having some congestion control and flow control capabilities.
1.2.4 Link Layer
The data link layer implements the network driver for the network card interface to handle data transmission over physical media. Two commonly used protocols at the data link layer are ARP (Address Resolution Protocol) and RARP (Reverse Address Resolution Protocol). They facilitate the conversion between IP addresses and physical MAC addresses of machines.
1.2.5 Data Transmission
-
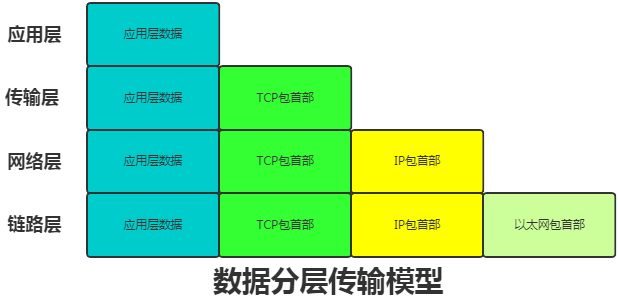
When using the TCP/IP protocol suite for network communication, communication occurs in a layered order. The sender moves down from the application layer, while the receiver moves up from the link layer.
-
As data is transmitted between layers, each layer adds a header specific to that layer. Conversely, the receiving end removes the corresponding header as data is transmitted between layers.
-
This method of wrapping data information is called encapsulation.
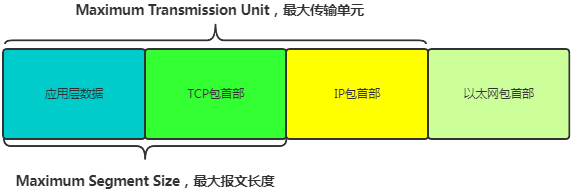
However, it is important to note that the IP layer has a Maximum Transmission Unit (MTU) limitation, and similarly, the TCP layer has a Maximum Segment Size (MSS) limitation during data transmission.
The Ethernet MTU is 1500, the basic IP header length is 20, and the TCP header is 20, so the maximum value of MSS can reach 1460 (MSS does not include protocol headers, only application data).
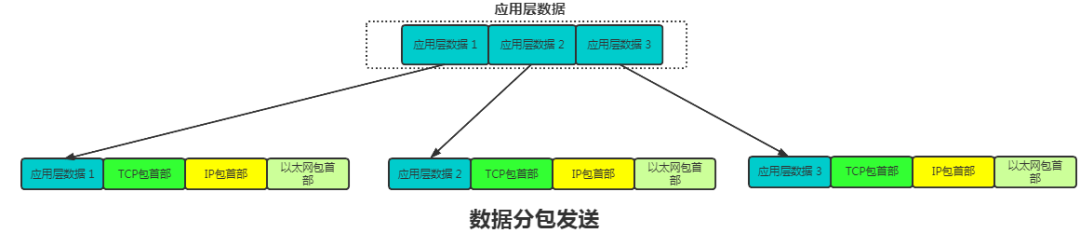
Therefore, a large application layer message may be split into several pieces and transmitted one by one. The receiving party assembles the application layer data from each received packet, and only when all packets are received is the request considered complete. This is also the significance of the Content-Length field.
1.3 OSI and TCP/IP
OSI
-
OSI, also known as the Open Systems Interconnection Reference Model, is a conceptual model proposed by the International Organization for Standardization (ISO) that attempts to standardize the necessary functions of communication protocols to interconnect various computers worldwide.
TCP/IP
-
In real life, TCP/IP is the actual network transmission communication protocol, focusing on what kind of programs should be developed to implement the protocol on computers.
Differences between OSI and TCP/IP
-
OSI introduces the concepts of services, interfaces, protocols, and layering, while TCP/IP borrows these concepts from OSI to establish the TCP/IP model.
-
OSI has a model first and then protocols, establishing standards before practice.
-
TCP/IP has protocols and applications first, then proposes a model, which is based on the OSI model.
-
OSI is a theoretical model, while TCP/IP has been widely used and has become the de facto standard for network interconnection.
After introducing the macro view of the TCP/IP protocol suite, let us now dive into the network world from top to bottom.

2 Application Layer: HTTP
2.1 A Brief Overview of HTTP
2.1.1 Definition of HTTP
HyperText Transfer Protocol, also known as the Hypertext Transfer Protocol. HTTP is a convention and specification for transmitting hypertext data such as text, images, audio, and video between any two points in the computer world.
2.1.2 URI, URN, URL
URI: Uniform Resource Identifier, represents every available resource on the web. URI is just a concept, and how it is implemented does not matter; the focus is on identifying a resource.
URN: Universal Resource Name, identifies a resource through a unique name or ID in a specific namespace.
URL: Universal Resource Locator, URL is actually a subset of URI, which not only identifies a resource but also tells you how to access it. A standard URL must include: protocol, host, port, and path.

-
protocol: The protocol used for communication, such as HTTP, FTP, file, etc.
-
IP: The actual IP address of the server.
-
Port: The port exposed by the service resource on the IP machine.
-
path: The storage path of the resource on the server, usually a file or access directory.
-
query: Optional configuration, separated by &, parameters stored in KV format.
Example of the relationship among the three:
-
If you want to find a person, that person is a resource, which is a URI.
-
If you use an ID number + name to find them, that is a URN; the ID number + name only identifies the resource but does not confirm the address of the resource.
-
If you use an address: XX Province, XX City, XX District, XX Unit, XX Room, that is a URL, which not only identifies the resource but also locates its address.
2.2 HTTP Message Format
Both request and response messages consist of start line, header, empty line, and body, with slight differences in the start line.
2.2.1 Request
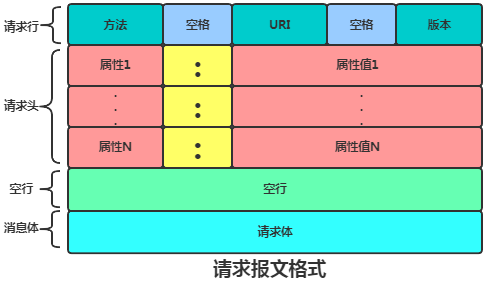
2.2.1.1 Request Line
The request line contains three parts: request method, URL, and protocol version. They are separated by spaces, and the request line ends with a carriage return + line feed.
Request Method: Indicates what operation is to be performed on the target resource. HTTP 1.1 defines eight request methods listed in the table below, with the most commonly used being GET and POST.
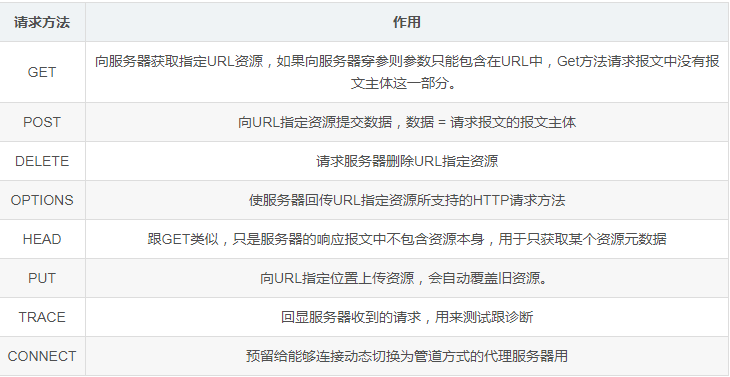
URL: Specifies the target address for this access.
Protocol Version: Specifies the HTTP version currently supported by the client. The commonly used versions of HTTP are 1.1, 2.0, and 3.0. If the requester specifies 1.1, the responder will also use HTTP 1.1 to reply.
2.2.1.2 Request Header
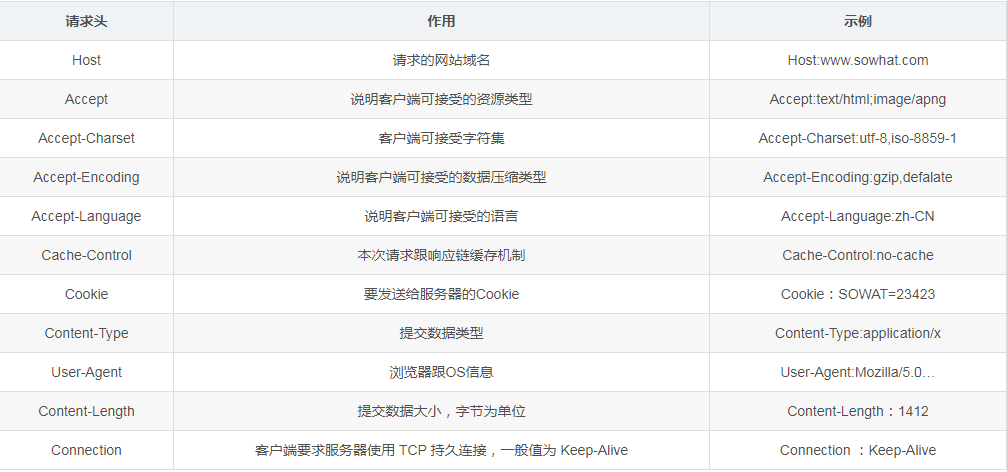
The request header provides the server with additional information about the request and the client itself. Each request header is a key-value pair, separated by a colon. Each request header forms a separate line, ending with a carriage return and line feed. Among all request headers, only Host is required; other request headers are optional. Here are some common request headers:
2.2.1.3 Empty Line
This line contains only a carriage return and line feed, with no other content. This empty line marks the end of the request header and is mandatory.
2.2.1.4 Request Body
This is generally the user-defined body, which can be specified in the message header using Content-Type.
2.2.1.5 Request Example
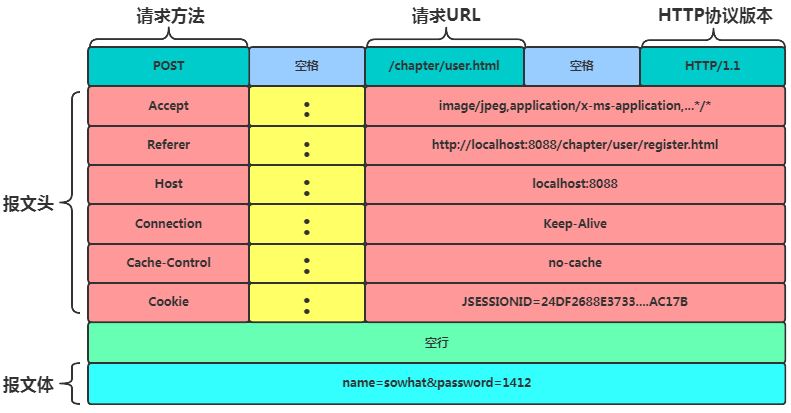
2.2.2 Response
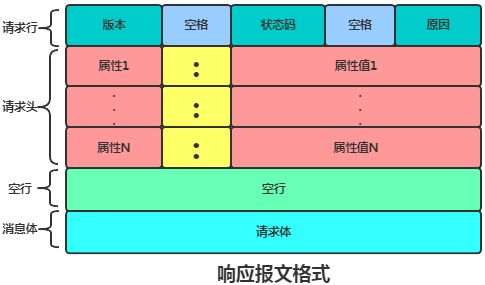
2.2.2.1 Response Line
Specifies the HTTP version, response status code, and a brief reason for the response.
2.2.2.2 Response Header
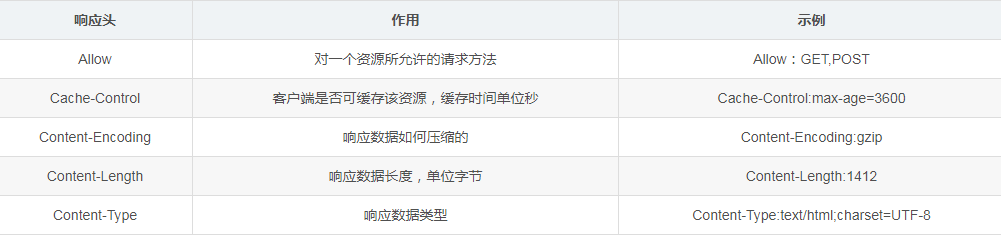
The empty line and message body are almost similar to the request, while the message body type is specified by Content-Type.
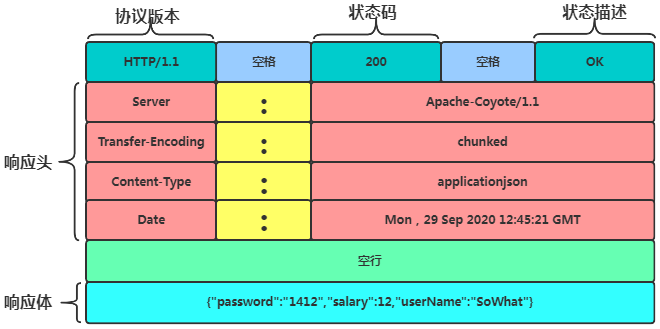
2.2.2.4 Response Example
2.3 HTTP Header Fields
The HTTP protocol specifies many header fields that can implement various functions, but they can generally be divided into the following four categories:
-
General Fields: Can appear in both request and response headers.
-
Request Fields: Can only appear in request headers, providing further information about the request or additional conditions.
-
Response Fields: Can only appear in response headers, providing additional information about the response message.
-
Entity Fields: These actually belong to general fields but specifically describe additional information about the body.
By setting HTTP header fields, HTTP provides several important functions:
-
Content Negotiation: The client and server agree on the content of the response resource, such as language, character set, encoding method, and compression type.
-
Cache Management: Resources can be cached on the client based on resource characteristics, noting the differences between max-age, no-cache, no-store, and must-revalidate.
-
Entity Type: The MIME type of the request and response can be obtained by parsing Content-Type.
-
Connection Management: Long and short connections can be managed by reading configuration parameters.
2.4 HTTPS vs. HTTP
HTTP transmits data in plaintext, which poses several risks:
-
Eavesdropping Risk: Information confidentiality, such as the ability to obtain communication content over the communication link.
-
Tampering Risk: Information integrity, such as forced insertion of spam advertisements.
-
Impersonation Risk: Identity verification, such as counterfeit websites impersonating shopping sites like Taobao.
2.4.1 Overview of SSL/TLS
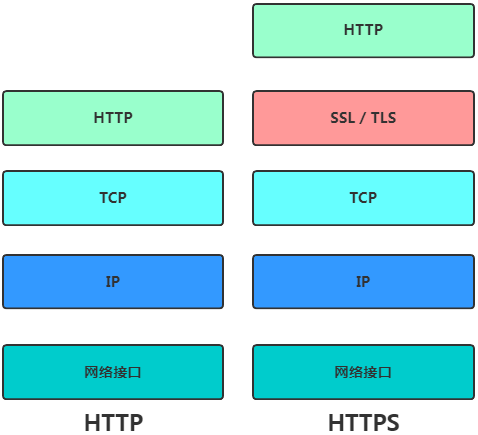
To ensure security, HTTPS was developed, which adds the SSL/TLS encryption protocol between HTTP and TCP layers, addressing the three aforementioned issues.
-
Confidentiality of information is achieved through
hybrid encryption. -
Integrity is ensured through
hash algorithms, which generate a unique sequence number for the data. -
The server’s
public keyis placed in adigital certificateto mitigate theimpersonationrisk.
It is important to note that HTTP defaults to port 80, while HTTPS defaults to port 443.
2.4.2 Encryption Algorithms
Encryption algorithms are divided into symmetric encryption and asymmetric encryption.
-
Symmetric Encryption: Uses one key for both encryption and decryption, is fast, but the key must be kept secret, making secure key exchange difficult. Common encryption algorithms include AES, DES, RC4, BlowFish, etc.
-
Asymmetric Encryption: Uses public key and private key, where the public key can be distributed freely while the private key remains confidential, solving the key exchange problem but is slower. The derivation process from private key to public key is one-way, ensuring the security of the private key. Common encryption algorithms include RSA, DSA, Diffie-Hellman, etc.
HTTPS employs a hybrid encryption method combining symmetric encryption and asymmetric encryption:
-
Asymmetric encryption is used to exchange keys before establishing communication, after which asymmetric encryption is no longer used.
-
During communication, all plaintext data is encrypted using the symmetric encryption session key.
2.4.3 Hash Algorithms
The main feature of hash algorithms is that the encryption process does not require a key, and the encrypted data cannot be decrypted. Currently, only the CRC32 algorithm can be reversed. Only identical plaintext data processed through the same hash algorithm can yield the same ciphertext.
Hash algorithms are mainly used in the digital signature field as a summary algorithm for plaintext. Notable hash algorithms include the MD5 algorithm and SHA-1 algorithm from RSA, along with many variants.
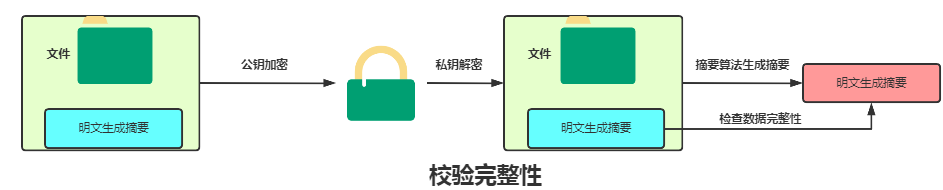
-
The client generates a hash of the plaintext data using a specified hash algorithm.
-
The plaintext data + hash algorithm is encrypted with the public key and transmitted.
-
The server receives the information and uses the private key to decrypt it, obtaining the plaintext + hash.
-
The server generates a hash of the plaintext using the same hash algorithm.
-
By comparing the two hashes generated by the client and server, it can be determined whether the data is complete.
2.4.4 CA Certificates
In asymmetric encryption, the client retains the public key, but ensuring the accuracy of the public key is a challenge. If someone intercepts the server’s public key, the entire data transmission process between the client and server would be unaware of the third party’s presence, leading to information leakage!
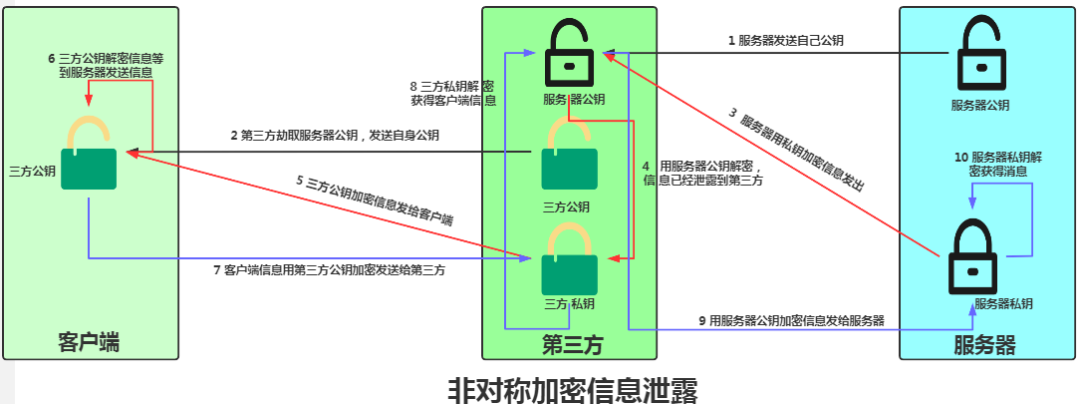
The key issue is how to ensure that the client receives the server’s public key! This is where the digital certificate comes into play, which is based on the previously mentioned private key encryption data and public key decryption to verify identity.
-
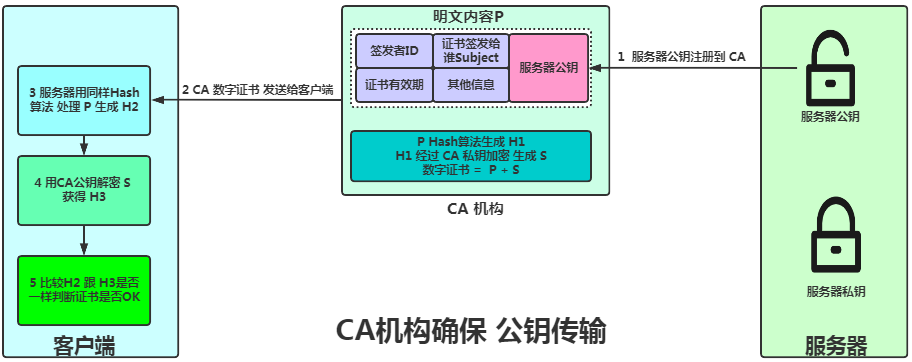
CA is a
trustedcertificate issuing authority, with only a few globally recognized companies. This authority generates a pair of public and private keys using RSA. -
The content of the server’s public key + issuer ID + certificate subject + validity period + other information = plaintext content P.
-
The plaintext content P is hashed to generate H1, and H1 is encrypted with the CA’s private key to obtain S.
-
P + S = digital certificate.
-
The client receives the digital certificate and hashes P using the same hash algorithm to obtain H2.
-
We use the CA’s public key to decrypt S to obtain H3.
-
By comparing H2 and H3, if they are the same, the certificate is valid. If they differ, it indicates that P has been modified or the certificate was not issued by the CA.
-
If they match, the server’s public key can be correctly extracted, and that’s it!
2.4.5 SSL/TLS Establishment Process
First, a TCP three-way handshake is performed, followed by the preparation for encrypted communication. Before starting encrypted communication, the client and server must first establish a connection and exchange parameters, a process known as the handshake HandShake. What is the main workflow of the SSL/TLS module? You can think of it as ClientHello, ServerHello, Finish.

-
Client Request
The client initiates an encrypted communication request to the server: the client provides the SSL/TLS protocol version + a randomly generated number
Random1+ the encryption methods supported by the client.
-
Server Response
The server confirms whether the SSL/TLS version is supported, verifies the encryption algorithm to be used, generates a random number
Random2(used to generate the session key), and generates the server’s digital certificate.
-
Client Certificate Verification
The client verifies the authenticity of the server’s digital certificate using the CA’s public key and retrieves the server’s public key.
The client generates a random number
Random3, encrypts it with the server’s public key to generatePreMaster Key, and sends it to the server, along with the agreed encryption algorithm.The server decrypts the
PreMaster Keyusing its private key to obtainRandom3. At this point, both the server and client use the same encryption algorithm to encryptRandom1 + Random2 + Random3 = <code>Session Key, which will be used for subsequent encrypted communication.The client generates a hash of the previous handshake messages and encrypts it with the negotiated key. This is the first encrypted message sent by the client. The server will decrypt it upon receipt, confirming that the negotiated key is consistent.
-
Server Final Response
The server receives
Random3+ the final encryption algorithm, finalizing theSession Key.The server informs the client that the encryption algorithm has changed, and subsequent messages will be encrypted using the Session Key.
The server will also generate a hash of the handshake messages and encrypt it, which is the first encrypted message sent by the server. The client will decrypt it upon receipt, confirming that the negotiated key is consistent.
-
Normal Data Transmission
At this point, both parties have securely negotiated the same key, and the SSL/TLS handshake phase is complete. All application layer data will be encrypted with this key and transmitted reliably via TCP.
2.4 History of HTTP Development
Currently, there are three versions of HTTP: HTTP/1.1, HTTP/2, and HTTP/3, with the first two being the most widely used.
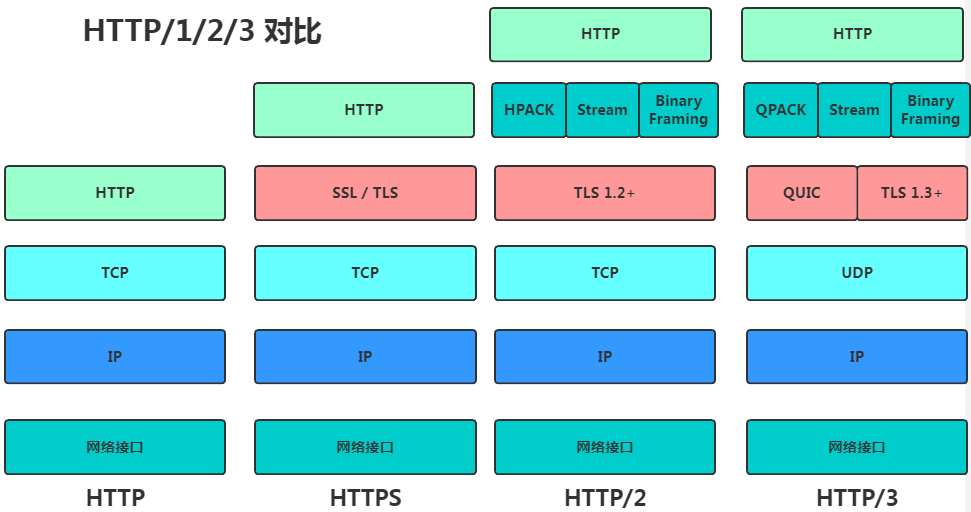
2.4.1 HTTP/1.1
HTTP/1.1 has the following advantages and disadvantages compared to older versions:
Advantages:
TCP began using long connections instead of short ones to avoid unnecessary performance overhead.
For example, when sending ABC, the sending of B does not need to wait for A to finish sending before starting.
Disadvantages:
Request/response headers are sent without compression, only the body can be compressed.
Redundant configuration information is sent back and forth.
Can lead to head-of-line blocking.
FIFO mode, with no concept of priority.
Only client requests and server responses are allowed.
2.4.1 HTTP/2
HTTP/2 is based on HTTPS, maintaining backward compatibility while also optimizing as follows:
-
Header Compression: Introduces the
HPACKalgorithm, where both the client and server maintain a header information table, storing all fields in this table. Repeated header information is no longer sent as original values but as index numbers. -
Binary Transmission: The new version uses a binary mode of transmission that is more computer-friendly, transmitting data in frames.
-
Stream Priority Transmission: Different request/response data packets are distinguished by Stream, with each Stream having an independent number. Priority can also be specified.
-
Multiplexing: Multiple streams can simultaneously send and receive request-response data frames within a single connection, with data packets in each stream transmitted and assembled in order. Each stream is independent, so whoever processes the request first can send the response back through the connection.
-
Server Push: The server can proactively push potentially needed static variables like JS and CSS.
Disadvantages:
-
Blocking Issues: HTTP/2’s frame transmission occurs at the application layer, and the final data must go through TCP transmission, which is a reliable connection with packet loss and retransmission capabilities. If a packet is lost, all HTTP requests will wait for the lost packet to be retransmitted.
2.4.1 HTTP/3
HTTP/3 replaces the TCP protocol with UDP, as UDP does not care about order or packet loss. Additionally, Google has added TCP’s connection management, congestion window, and flow control mechanisms on top of UDP, which we refer to as the QUIC protocol. Overall, the optimizations of HTTP/3 are as follows:
-
QUIChas a unique mechanism to ensure transmission reliability. When a stream experiences packet loss, only that stream is blocked, and other streams are unaffected. -
The TLS algorithm has been upgraded from 1.2 to 1.3, and the header compression algorithm has been upgraded to QPack.
-
Before HTTP/3, communication required three TCP handshakes + three TLS encryption interactions. QUIC combines these six steps into three.
-
QUIC is a protocol that combines TCP + TLS + HTTP/2 multiplexing on top of UDP.
2.5 Features of HTTP
-
Flexible Extension
The strength of HTTP lies in its specification of only the basic framework of header + body, allowing users to customize the specific content. Additionally, its underlying components are pluggable, such as the addition of SSL/TLS, binary frame transmission, and replacing TCP with UDP, etc.
-
Reliable Transmission
Whether using TCP or QUIC, data transmission reliability is guaranteed.
-
Request-Response Model
HTTP implements data transmission based on the request-response model.
-
Stateless
Each request-response in HTTP is stateless, meaning each message sent and received is completely independent. To implement some chained reactions, the Session and Cookie mechanisms are required.
-
Application Layer Protocol
HTTP is merely a transmission protocol defined at the application layer, with its underlying data transmitted using the TCP protocol.
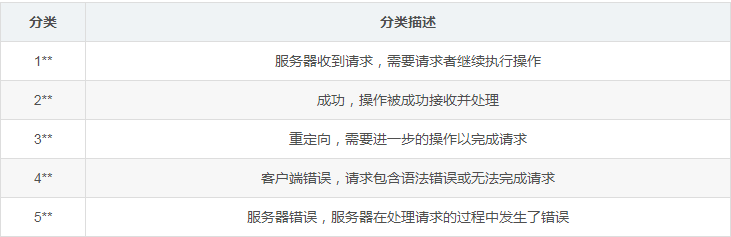
2.6 Common HTTP Status Codes
Common HTTP status codes can be categorized into five types.
3 Appendix
This article has only briefly explained the application layer and transport layer of the TCP/IP protocol. The next part will cover the network layer in more detail, so stay tuned for a more comprehensive version of the TCP/IP protocol.
4 References
-
SSL/TLS: https://www.bilibili.com/read/cv1003133
-
HTTP Comprehensive Guide: https://t.1yb.co/gcKW
-
Xiao Lin Network Special: https://t.1yb.co/fQG3
-
HTTP Status Codes: http://tools.jb51.net/table/http_status_code
-
TCP/IP Explanation: https://developer.51cto.com/art/201906/597961.htm
Why is Kafka so powerful!
2021-02-01
20 Images to Take You into the World of HBase
2021-01-20
Interviewer: Ask these 13 questions about Spring
2021-01-06
Java Concurrency Twelve Moves, Can You Catch Them?
2020-12-28
Redis: From Application to Underlying, One Article to Help You Solve It
2020-12-14