
New Intelligence Report
Source: GoogleAI Editors: Xiao Qin, Da Ming
[New Intelligence Overview] Making robot research accessible to the public. Researchers from the University of California, Berkeley, and Google Brain have jointly developed the low-cost robot learning platform ROBEL, which supports the expansion of robot experiments and reinforcement learning, while ensuring robustness, flexibility, and reproducibility. This platform has now been released to the open-source community. Join the New Intelligence AI circle for discussions!
Learning-based methods for solving robot control problems have seen significant advancements recently, driven by the widespread availability of simulation benchmarks (such as dm_control or OpenAI-Gym) and improvements in flexible, scalable reinforcement learning techniques (such as DDPG, QT-Opt, or Soft Actor-Critic).While learning through simulation is effective, these simulated environments often encounter difficulties when deployed on real robots due to factors such as inaccurate modeling of physical phenomena or system delays. This has sparked a demand for developing robot control solutions directly on real-world physical hardware.Currently, most robot research on physical hardware is conducted on high-cost, industrial-grade robots (such as PR2, Kuka-arms, ShadowHand, Baxter, etc.), aimed at precise, monitored operations in controlled environments. Moreover, these robots are designed around traditional control methods that emphasize precision, reproducibility, and ease of characterization.This contrasts sharply with learning-based methods, which are robust to imperfect sensing and actuation and require (a) high adaptability to allow for trial-and-error learning in the real world, (b) low cost and ease of maintenance to achieve scalability through replication, and (c) reliable reset mechanisms to alleviate stringent human monitoring requirements.Researchers from the University of California, Berkeley, and Google Brain have addressed this issue by proposing an open-sourcelow-cost robot learning platform “ROBEL” (Robotics Benchmarks for Learning with Low-Cost Robots), designed to encourage rapid experimentation and hardware reinforcement learning. ROBEL also provides benchmark tasks primarily aimed at facilitating research and development on real-world physical hardware. ROBEL is a fast experimental platform that supports a wide range of experimental needs and the development of new reinforcement learning and control methods.ROBEL consists ofD’Claw and D’Kitty, where D’Claw is a robotic arm with three arms that can assist in learning dexterous manipulation tasks.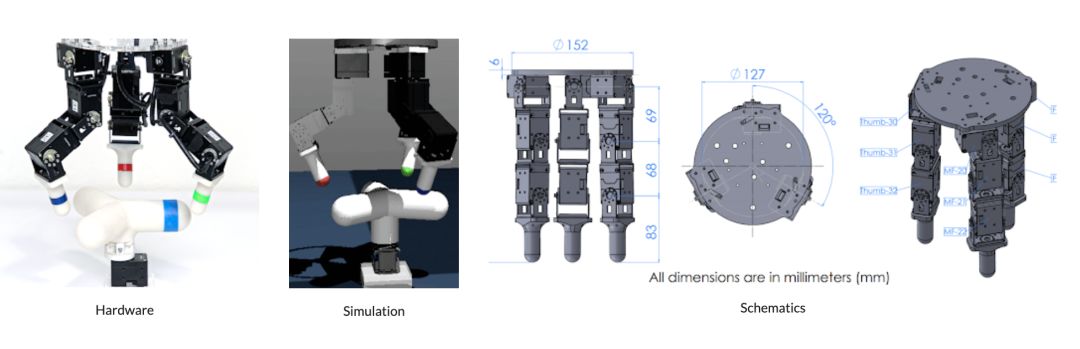 D’ClawD’Kitty is a four-legged robot that can assist in learning flexible leg movement tasks.
D’ClawD’Kitty is a four-legged robot that can assist in learning flexible leg movement tasks.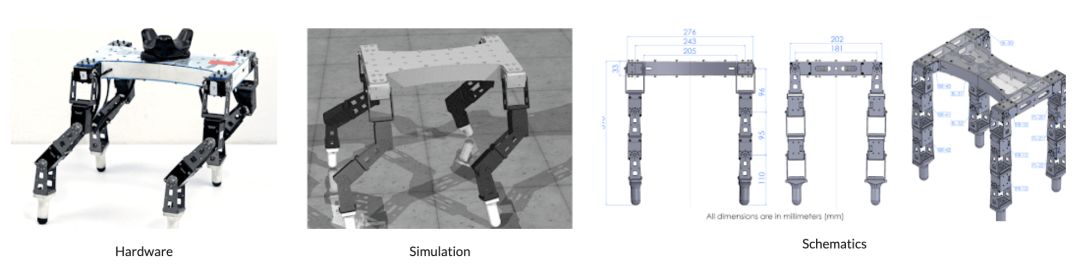 D’KittyThis robot platform is low-cost, modular, easy to maintain, and powerful enough to support hardware reinforcement learning from scratch.Left: Twelve degrees of freedom D’Kitty; Middle: 9 degrees of freedom D’Claw; Right: Fully functional D’Claw device D’Lantern.To make the robots cost-effective and easy to build, the researchers designed ROBEL based on off-the-shelf components and common prototyping tools (3D printing or laser cutting). The design is easy to assemble and can be built in just a few hours.ROBEL benchmarks Google has designed a set of tasks applicable to both D’Claw and D’Kitty platforms for benchmarking real-world robot learning.ROBEL’s task definitions include dense and sparse task objectives and introduce hardware safety metrics in the task definitions, such as indicating whether joints exceed “safe” operational limits or force thresholds. ROBEL also provides simulators for all tasks to facilitate algorithm development and rapid prototyping. D’Claw tasks primarily revolve around three common manipulation behaviors: Pose, Turn, and Screw.
D’KittyThis robot platform is low-cost, modular, easy to maintain, and powerful enough to support hardware reinforcement learning from scratch.Left: Twelve degrees of freedom D’Kitty; Middle: 9 degrees of freedom D’Claw; Right: Fully functional D’Claw device D’Lantern.To make the robots cost-effective and easy to build, the researchers designed ROBEL based on off-the-shelf components and common prototyping tools (3D printing or laser cutting). The design is easy to assemble and can be built in just a few hours.ROBEL benchmarks Google has designed a set of tasks applicable to both D’Claw and D’Kitty platforms for benchmarking real-world robot learning.ROBEL’s task definitions include dense and sparse task objectives and introduce hardware safety metrics in the task definitions, such as indicating whether joints exceed “safe” operational limits or force thresholds. ROBEL also provides simulators for all tasks to facilitate algorithm development and rapid prototyping. D’Claw tasks primarily revolve around three common manipulation behaviors: Pose, Turn, and Screw.

Left: Pose – assume a shape that fits the environment. Middle: Turn – rotate the object to a specified angle. Right: Screw – continuously rotate the object, such as screwing a screw.D’Kitty’s tasks primarily revolve around three common movement behaviors – Stand, Orient, and Walk. Left: Stand – upright. Middle: Adjust orientation – align direction with the target. Right: Walk – move to the target point.For these benchmark tasks, the researchers evaluated several deep reinforcement learning methods (on-policy, off-policy, demo-accelerated, supervised), and the evaluation results and final policies were included as baselines in the package for comparison. For specific task details and baseline performance, please refer to the paper.Reproducibility and RobustnessROBEL platform has powerful capabilities to support direct hardware training, having accumulated over 14,000 hours of real-world experience to date. Over the past year, these platforms have matured significantly. Due to the modular design, system maintenance has become very simple, requiring almost no domain expertise. To ensure the reproducibility of the platform and benchmark methods, two different research laboratories have independently studied ROBEL. This research only used software distribution and documentation. No in-person access was allowed. Using ROBEL’s design documentation and assembly instructions, both were able to replicate the two hardware platforms. Benchmark tasks were trained on robots built in both laboratories.The two D’Claw robots built at two different locations, as shown in the figure below, not only had similar training progress but also converged to the same performance, demonstrating the good reproducibility of the ROBEL benchmarks.
Left: Stand – upright. Middle: Adjust orientation – align direction with the target. Right: Walk – move to the target point.For these benchmark tasks, the researchers evaluated several deep reinforcement learning methods (on-policy, off-policy, demo-accelerated, supervised), and the evaluation results and final policies were included as baselines in the package for comparison. For specific task details and baseline performance, please refer to the paper.Reproducibility and RobustnessROBEL platform has powerful capabilities to support direct hardware training, having accumulated over 14,000 hours of real-world experience to date. Over the past year, these platforms have matured significantly. Due to the modular design, system maintenance has become very simple, requiring almost no domain expertise. To ensure the reproducibility of the platform and benchmark methods, two different research laboratories have independently studied ROBEL. This research only used software distribution and documentation. No in-person access was allowed. Using ROBEL’s design documentation and assembly instructions, both were able to replicate the two hardware platforms. Benchmark tasks were trained on robots built in both laboratories.The two D’Claw robots built at two different locations, as shown in the figure below, not only had similar training progress but also converged to the same performance, demonstrating the good reproducibility of the ROBEL benchmarks.
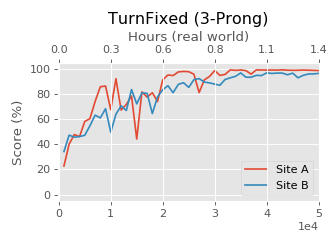
Training performance of two real D’Claw robots developed in different laboratories executing tasks
Experimental Results and Performance DemonstrationSo far, ROBEL has been very useful in various reinforcement learning studies. Below we highlight some key results, the D’Claw platform is fully autonomous, capable of maintaining experimental reliability over extended periods, and can utilize various reinforcement learning paradigms and tasks with rigid and flexible objects to improve experiments.



Top image: High flexibility target: Hardware training using DAPG effectively learned how to rotate flexible targets. The experiment observed the robot manipulating the more rigid center part of the valve. D’Claw shows high robustness to hardware training, which helps achieve success in tasks that are difficult to simulate.Middle image: Anti-interference: Sim2Real policies trained in MuJoCo simulation, where object disturbances (and others) were tested on hardware. We observed the fingers working together to resist external disturbances.Bottom image: Removing a finger: Sim2Real policies trained in MuJoCo simulation and tested on hardware for external and other disturbances). The robot filled the position of the missing finger with a free finger. Importantly, the D’Claw platform is highly modular and exhibits high reproducibility, facilitating extended experiments. Through extended setups, we found that multiple D’Claws could collectively learn tasks faster by sharing experiences. By sharing the distributed version of the SAC hardware training process, arbitrary combinations of multiple target tasks can be achieved at any angle. In multi-task customization, completing five tasks only requires twice the experience of a single task. In the video, five D’Claw robots rotate different objects 180 degrees (for visual presentation, the actual policy can achieve rotation at any angle). We have also successfully deployed robust mobility policies on the D’Kitty platform. The following images show D’Kitty walking stably on indoor and outdoor terrains under “blind” conditions, demonstrating gait robustness under the “invisible” disturbance condition.
By sharing the distributed version of the SAC hardware training process, arbitrary combinations of multiple target tasks can be achieved at any angle. In multi-task customization, completing five tasks only requires twice the experience of a single task. In the video, five D’Claw robots rotate different objects 180 degrees (for visual presentation, the actual policy can achieve rotation at any angle). We have also successfully deployed robust mobility policies on the D’Kitty platform. The following images show D’Kitty walking stably on indoor and outdoor terrains under “blind” conditions, demonstrating gait robustness under the “invisible” disturbance condition.



Top image: Walking in a cluttered indoor environment: Sim2Real policies trained through natural policy gradients in MuJoCo simulation allow the robot to walk under random disturbances and step over obstacles. Middle image: Outdoor environment: gravel and branches – Sim2Real policies trained in MuJoCo simulation with random height fields can learn to walk in outdoor environments scattered with gravel and branches. Bottom image: Outdoor – slopes and grass: Sim2Real policies trained in MuJoCo simulation with random height fields allow the robot to learn to walk on gentle slopes. When D’Kitty receives information about its torso and targets in the scene, it can learn to interact with targets exhibiting complex behaviors.  Left: Avoiding moving obstacles: Strategies trained through Hierarchical Sim2Real can learn to avoid moving obstacles and reach target locations. Middle: Pushing one target towards a moving target. Strategies trained through Hierarchical Sim2Real learn to push a target towards a moving target (marked by a controller in hand). Right: Dual robot collaboration – Strategies trained through Hierarchical Sim2Real can learn to coordinate two D’Kitty robots to push heavy obstacles to target locations (marked by two + signs on the floor). In summary, the ROBEL platform is low-cost, powerful, and highly reliable, meeting the demands of emerging learning-based paradigms that require high scalability and flexibility. We have released ROBEL to the open-source community, believing it will enhance the diversity of related research and experimentation. To use the ROBEL platform and ROBEL benchmarks, please visit roboticsbenchmarks.orgReference link:https://ai.googleblog.com/2019/10/robel-robotics-benchmarks-for-learning.html
Left: Avoiding moving obstacles: Strategies trained through Hierarchical Sim2Real can learn to avoid moving obstacles and reach target locations. Middle: Pushing one target towards a moving target. Strategies trained through Hierarchical Sim2Real learn to push a target towards a moving target (marked by a controller in hand). Right: Dual robot collaboration – Strategies trained through Hierarchical Sim2Real can learn to coordinate two D’Kitty robots to push heavy obstacles to target locations (marked by two + signs on the floor). In summary, the ROBEL platform is low-cost, powerful, and highly reliable, meeting the demands of emerging learning-based paradigms that require high scalability and flexibility. We have released ROBEL to the open-source community, believing it will enhance the diversity of related research and experimentation. To use the ROBEL platform and ROBEL benchmarks, please visit roboticsbenchmarks.orgReference link:https://ai.googleblog.com/2019/10/robel-robotics-benchmarks-for-learning.html
