Previous Articles
How Quantitative Models Connect to Real Trading Interfaces
The Truth About Free Level-2 (L2) Depth Data in Quantitative Trading
The Only Free Compliant Real Trading Quantitative Trading API in China – miniQMT
Click the blue text · to follow us
Focusing on research in the quantitative trading industry, sharing trading technologies and industry knowledge, providing systematic quantitative trading solutions, and online applications for opening miniQMT and PTrade real trading permissions. Contact WeChat: stock527
1.Why So Fast?
“Latency is the new leverage.” When hardware design embeds “time” into silicon, strategy design can convert “probability” into profit.
In traditional time perception, 1 second is fleeting; however, in modern electronic trading, 1 microsecond is enough to complete a market data distribution, matching, and even strategy decision-making and profit writing back. For high-frequency trading (HFT), which is the most profit-driven, latency is the hardest column on the balance sheet:
Profit ∝ 1/Latency — with the same strategy quality, halving the delay can nearly double the theoretical capture of price difference opportunities.
Risk ∝ Latency² — the greater the delay, the pricing deviation accumulates quadratically during volatility amplification, increasing slippage and order rejection risks.
Therefore, from communication layer protocols to NUMA topology, CPU cache behavior, and even the clock tree inside FPGAs, every nanosecond of optimization amplifies profits or reduces risks. For seasoned quants, “microsecond thinking” has long been embedded in the R&D process, similar to early aerospace engineering treating weight as gold — what is being quantified is time itself.
2.Market Depth and Time Depth
Ten-level market data solves the “visibility” issue — providing the top ten price levels for orders; thousand-level and even holographic order books solve the “understandability” issue — allowing algorithms to quantify liquidity gradients and queue elasticity at deeper price levels.
① Information entropy increase: thousand-level depth ≈ log-level increase in information compared to ten-level depth;
② Shortened prediction half-life: the richer the depth, the more frequent the updates, with typical Level-2 thousand-level clusters refreshing every 30–50 µs;
③ Improved model granularity: traditional order-book imbalance can be expanded from two dimensions to three dimensions (price level × time × lateral).
④ But the premise is: decoding, computing, and ordering must be completed before the depth data becomes invalid. This gives rise to two main technical lines:
Hardware acceleration: FPGA/ASIC solidifies FIX-FAST decoding, TCP stack, book-building, and other logic into gate-level pipelines, eliminating jitter;
Parallel heterogeneity: FPGA is responsible for deterministic latency, while CPU/GPU handles complex nonlinear factor calculations, and CXL shared memory pools reduce copying.
3.“Latency Budget” and Profit Elasticity
Breaking down the micro trading process, we typically allocate a strict Latency Budget (µs) for each hop:

Profit elasticity formula (simplified)
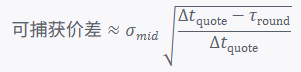
Where:
σmid is the mid-price volatility,
Δtquote is the average lifespan of quotes,
τround is our round-trip latency.
When τround is reduced from 3 ms to 60 µs, the ideal capture of price differences can increase by about 7–8 times; considering the reduction in risk exposure and capital utilization, the IR (Information Ratio) can often increase by an order of magnitude.
4. Three Stages of Low Latency
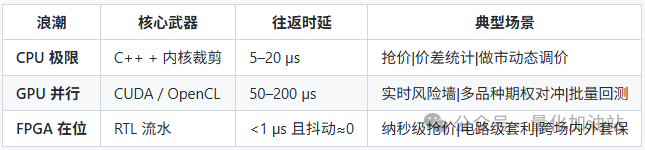
Stage One: CPU Single-Thread Limit
① C++ + Kernel Optimization
Zero-copy + Inline Assembly: Handwriting SIMD in while(true){} understands registers better than the compiler.
IRQ Binding / Kernel Trimming: Eliminate all interrupts and process scheduling unrelated to matching, making Linux preempt-rt and Tickless kernels a must-learn.
Ring Buffer & Memory Pool: Completely eliminate malloc/free, writing the order book in L1 Cache.
② UMA, HugePage, Polling IO
By aligning NUMA and using 2 MB HugePage, TLB misses are reduced to statistical noise, and replacing epoll with polling IO (Busy-Polling) achieves a one-way latency of 5–8 µs.
Ceiling: Cache coherence, L3 sharing & trailing interrupt noise (OS Noise) prevent single-core performance from increasing exponentially. Microstructures do not benefit from instruction-level parallelism; further latency reduction can only be achieved by “changing the physical stack.”
Stage Two:GPU / Many-Core Parallelism
① CUDA / OpenCL
GPUs have thousands of cores that can simultaneously handle a large number of parallel tasks.Perform linear algebra on the market characteristics of thousands of stocks at once, returning volatility matrices in seconds.
Decomposing anomaly detection, VaR risk walls, and derivative sequence backtesting into multiple steps, each executed at different time points, improves overall processing efficiency.
②After data is transported to the GPU via the PCIe bus, it still needs to go through GPU queuing, kernel execution, and returning to memory, each step adding to the total round-trip time, usually reaching 50–200 microseconds. This latency may be acceptable for risk control and pre-trade calculations that require immediate response, but for high-frequency trading (like price sniper positions) that demands extremely low latency, it is not fast enough.
Limitations: Throughput and latency cannot be achieved simultaneously; for the few nanoseconds of opportunity in order book matching, even the fastest GPU feels like a high-speed train running to the wrong ticket gate.
Stage Three: FPGA Hardware In-Place Computing
① TL Level Parallel Pipeline
Embedding TCP/UDP protocols and FIX/FAST decoding into hardware for ultra-fast processing, with latency less than 150 nanoseconds. In the order book pipeline, secondary market depth information is stored in high-speed memory, completing matching in each clock cycle through operations like placing orders, canceling orders, and executing trades. The end-to-end determinism of the link means that the transmission jitter of each data packet is only 4 nanoseconds, with a very stable statistical distribution, like two parallel straight lines.
② The Dawn of the “Circuit-Level Arbitrage” Era
With the collaboration of soft-core CPUs and FPGA SoCs, it is possible to run hot update instructions similar to Python scripts within the chip while maintaining the pipeline logic’s line-speed processing capability. Through 100 GbE fiber direct connection, trading instructions can be completed in one hop from the switch to the FPGA, with the server only responsible for monitoring, achieving sub-microsecond round-trip latency and zero jitter. This architecture can truly decompose “trend + noise” into “trend + remaining noise,” enabling high-precision trading.
This marks a paradigm shift: when decision-making and order placement are statically arranged on the same RTL pipeline, trading speed becomes a hard threshold; strategy development shifts from “writing code” to “drawing data paths.” In low-latency racing, core competitiveness is no longer about the amount of computation but about the immediacy and lead time of the computation.
CPU as the brain, GPU as the muscle, FPGA as the reflex.
5. FPGA-CPU Heterogeneous L2 Market System
In L2 market data, it is outdated to compete on who calculates accurately; the new king’s way is to compete on who calculates early and steadily. FPGA-CPU heterogeneity means embedding “early” and “steady” into hardware, letting the CPU be the strategy brain.
① Logic Splitting

② Data Flow Path
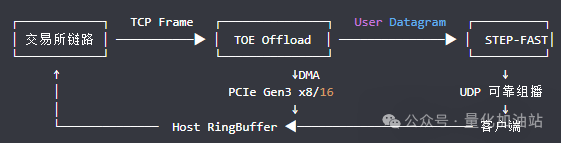
TCP Input: TOE, server CPU load ≈ 0.
TOE Offload: FPGA hardware state machine performs three-way handshake, retransmission, and sliding window.
STEP-FAST Decoding: Custom RTL pipeline + LUT dictionary reduces 450 bytes of Level-2 to 0.5 µs.
UDP Reliable Multicast: FPGA directly wraps the book snapshot packet into multicast, with packet loss handled by NACK feedback.
Client: Downstream strategy/risk control/book rewriting share a 64 byte Cacheline RingBuffer.
③ Kernel Advantages


When measuring network performance, simply looking at total bandwidth (e.g., Gbps) does not fully reflect actual application performance, especially in high-frequency trading or other scenarios requiring extremely low latency.Even if a device has high bandwidth, if it can only process a limited number of packets per second, its ability to handle small packets will become a bottleneck.For long packets, the transmission time from the first byte to the last byte (head-to-tail latency) is crucial. This relates to the delay throughout the entire process from sending to receiving data.Therefore, focusing on Mpps and the transmission latency of individual packets is more effective in improving price-sniping success rates than merely focusing on bandwidth.
6.STEP-FAST Solution
LDDS/FAST, due to its variable-length fields, message compression, and frequent upgrades by exchanges, presents significant challenges in processing. Traditional methods rely on CPU segment memcopy and software dictionaries, which are inefficient and carry the risk of downtime for version changes. By introducing parallel and fully pipelined micro-architecture design, serial operations are transformed into pipelined operations, combined with multi-instantiation, multi-clock domains, and BRAM full memory optimizations, achieving linear calculability of frame-to-book latency, with peak throughput reaching 24 Mpps and jitter less than 50 ns. Additionally, using configurable XML templates and polling load balancing mechanisms makes protocol changes and load distribution more flexible and efficient. Ultimately, the STEP-FAST solution, through hardware acceleration and reconfigurability, far exceeds traditional solutions in decoding latency, end-to-end link latency, throughput, and jitter performance metrics.
7. Innovations in Quantitative Strategies Under Low Latency
① Calendar Spread
Slippage tolerance: Dynamically set ±2σqueue width based on contract depth to avoid order clusters splitting.
Risk hedging: Real-time valuation of inventory value — near-leg γ hedged with options, far-leg γ locked with interest rate swaps.
On-exchange / Off-exchange hedging (Exchange ⇄ OTC)
Exchange matching delay < 5 µs, with OTC RFQ delay > 500 µs creating an “oscillating” arbitrage window.
② Quote-driven model:
High-frequency legs use FPGA, while “slow legs” commission banks for electronic RFQ, synchronized to nanosecond-level timestamps, performing oscillating linear regression for slippage management.
③ Sub-microsecond micro-alpha
Order Cluster Detection
Using Bloom Filter + Count-Min Sketch for streaming detection of short-term accumulations in the order book at N_{±dP}.
Clustering threshold:
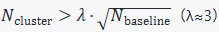
Microstructure Modeling
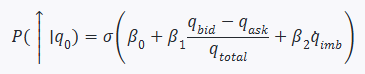
Goal: Predict the next jump direction within 50 µs before the “quote beep,” achieving 55% accuracy to enter the top 3% of TICK-rank.
④ Dynamic Queue of Thousand Levels and Market Depth Distribution
Heat function H(p,t): Weighted density of order activity at a price level.
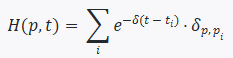
Visualization: Compressing thousand levels into 128 bins, GPU texture mapping for real-time rendering; a sudden red shift in the heat color bar indicates a “wall” collapse.
When H shows a same-direction surge of 3σ within -3 ticks, it’s a signal to jump; otherwise, cancel the order to give way to the “hot dogs” to take over.
⑤ Adaptive Slippage Control (ASC)
Traditional VWAP / TWAP struggles to handle nonlinear shocks; ASC reassesses the price-impact curve every 2 ms:
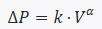
Slippage budget dynamically adjusts order splitting based on real-time k, α.
For synthetic spreads, slippage is broken down to legs, with the upper limit of impact on a single leg set at 35% of the combined ΔP.
⑥ Order Book Elasticity (Real-time)
Elasticity indicator
E=∂Q/∂P, smoothed in real-time using Kalman Filter.
Simulate “virtual shocks” before execution; if
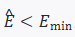
, automatically downgrade — switch the I algorithm to the P algorithm, sacrificing some speed for overall profit and loss.
Focusing on research in the quantitative trading industry, sharing trading technologies and industry knowledge, providing systematic quantitative trading solutions, and online applications for opening miniQMT and PTrade real trading permissions. Contact WeChat: stock527
 Disclaimer: This is only a knowledge compilation and some personal viewpoints. This public account does not guarantee the accuracy and completeness of this information. Investment involves risks, and one should be cautious when entering the market. This material does not constitute any investment advice; please carefully choose products and services that match your risk tolerance and investment goals.
Disclaimer: This is only a knowledge compilation and some personal viewpoints. This public account does not guarantee the accuracy and completeness of this information. Investment involves risks, and one should be cautious when entering the market. This material does not constitute any investment advice; please carefully choose products and services that match your risk tolerance and investment goals.