In May 2022, PyTorch officially announced support for model acceleration on Mac with M1 chip. Official comparison data shows that the training speed on M1 can be accelerated by an average of 7 times compared to CPU.
Wow, without needing a separate GPU, I couldn’t wait to get my hands on an M1 MacBook to try it out, and I have organized what I believe to be important information into this article.
Reply with the keyword: M1 in the WeChat public account to obtain the source code of this article’s Jupyter notebook.
1. Acceleration Principle
- Question 1: Why can the Mac M1 chip be used to accelerate PyTorch?
Because the Mac M1 chip is not just a simple CPU chip, but an integrated chip that includes a CPU (Central Processing Unit), GPU (Graphics Processing Unit), NPU (Neural Processing Unit), and unified memory units among many other components. Since the Mac M1 chip integrates a GPU component, it can be used to accelerate PyTorch.
- Question 2: How much video memory does the GPU on the Mac M1 chip have?
The CPU and GPU of the Mac M1 chip use unified memory units. Therefore, the available video memory size on the Mac M1 chip is the same as the memory size of the Mac computer.
- Question 3: Do I need to install the CUDA backend to accelerate PyTorch on the Mac M1 chip?
No, CUDA is designed for NVIDIA GPUs. The GPU in the Mac M1 chip uses the MPS acceleration backend, which is already available in the corresponding operating system and does not require separate installation. You only need to install the compatible version of PyTorch.
- Question 4: Why are some software that can be installed on Mac Intel chip computers not installable on Mac M1 chip computers?
The Mac M1 chip uses a simplified instruction set architecture called ARM architecture for high performance and energy efficiency, which is different from the x86 architecture used by common CPU chips like Intel. Therefore, some software developed based on the x86 instruction set cannot be used directly on Mac M1 chip computers.

2. Environment Configuration
0. Check Mac model
Click the Mac icon in the upper left corner of the desktop -> About This Mac -> Overview, confirm that it is an M1 chip, and check the memory size (preferably more than 16GB, 8GB may not be sufficient).

1. Download Miniforge3 (Miniforge3 can be understood as the community version of Miniconda/Anaconda, providing more stable support for M1 chip).
https://github.com/conda-forge/miniforge/#download
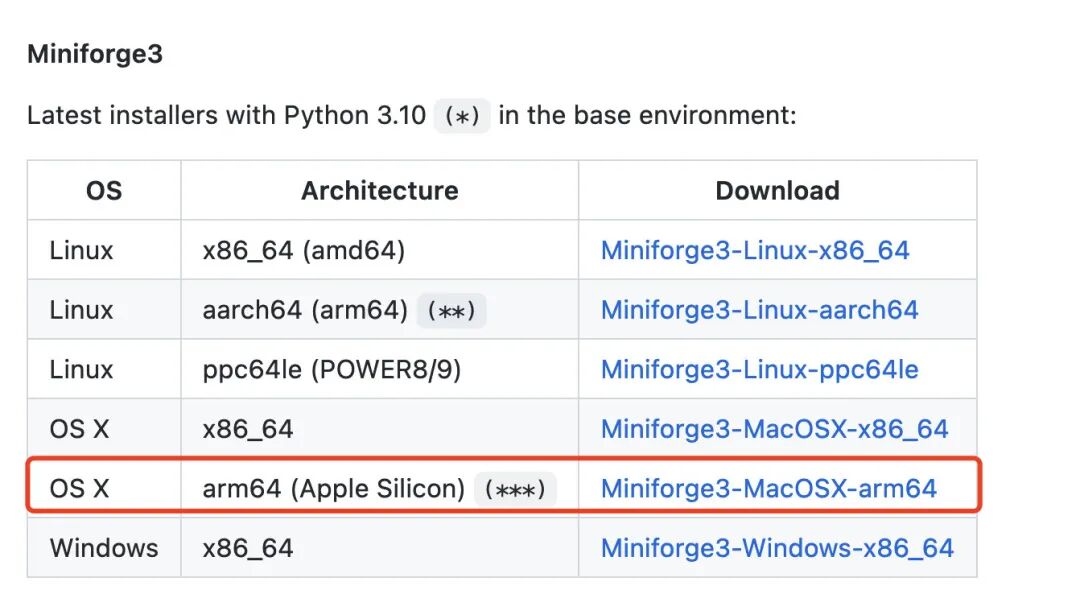
Note: Anaconda officially released support for Mac M1 chip in May 2022, but the community-released Miniforge3 is still recommended for its open-source and more stable performance.
2. Install Miniforge3
chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
source ~/miniforge3/bin/activate
3. Install PyTorch (version 1.12 officially supports the MPS backend for GPU acceleration on Mac M1 chip).
pip install torch>=1.12 -i https://pypi.tuna.tsinghua.edu.cn/simple
4. Test the environment
import torch
print(torch.backends.mps.is_available())
print(torch.backends.mps.is_built())
If both outputs are True, congratulations, you have successfully configured it.
3. Example Code
Below is an example of using the MNIST handwritten digit recognition to demonstrate the complete process of accelerating PyTorch using the MPS backend on the Mac M1 chip.
The core operation is very simple, similar to using CUDA; before training, just move the model and data to torch.device(“mps”).
import torch
from torch import nn
import torchvision
from torchvision import transforms
import torch.nn.functional as F
import os,sys,time
import numpy as np
import pandas as pd
import datetime
from tqdm import tqdm
from copy import deepcopy
from torchmetrics import Accuracy
def printlog(info):
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"========="*8 + "%s"%nowtime)
print(str(info)+"\n")
#================================================================================
# 1. Prepare Data
#================================================================================
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="mnist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=128, shuffle=False, num_workers=2)
#================================================================================
# 2. Define Model
#================================================================================
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=64,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=64,out_channels=512,kernel_size = 3))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(512,1024))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(1024,10))
return net
net = create_net()
print(net)
# Evaluation Metrics
class Accuracy(nn.Module):
def __init__(self):
super().__init__()
self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)
self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)
def forward(self, preds: torch.Tensor, targets: torch.Tensor):
preds = preds.argmax(dim=-1)
m = (preds == targets).sum()
n = targets.shape[0]
self.correct += m
self.total += n
return m/n
def compute(self):
return self.correct.float() / self.total
def reset(self):
self.correct -= self.correct
self.total -= self.total
#================================================================================
# 3. Train Model
#================================================================================
loss_fn = nn.CrossEntropyLoss()
optimizer= torch.optim.Adam(net.parameters(),lr = 0.01)
metrics_dict = nn.ModuleDict({"acc":Accuracy()})
# ========================= Move Model to MPS ===============================
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
net.to(device)
loss_fn.to(device)
metrics_dict.to(device)
# ====================================================================
epochs = 20
ckpt_path='checkpoint.pt'
# Early stopping related settings
monitor="val_acc"
patience=5
mode="max"
history = {}
for epoch in range(1, epochs+1):
printlog("Epoch {0} / {1}".format(epoch, epochs))
# 1. Train -------------------------------------------------
net.train()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_train), total =len(dl_train),ncols=100)
train_metrics_dict = deepcopy(metrics_dict)
for i, batch in loop:
features,labels = batch
# ========================= Move Data to MPS ===============================
features = features.to(device)
labels = labels.to(device)
# ====================================================================
# Forward
preds = net(features)
loss = loss_fn(preds,labels)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Metrics
step_metrics = {"train_"+name:metric_fn(preds, labels).item()
for name,metric_fn in train_metrics_dict.items()}
step_log = dict({"train_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_train)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = total_loss/step
epoch_metrics = {"train_"+name:metric_fn.compute().item()
for name,metric_fn in train_metrics_dict.items()}
epoch_log = dict({"train_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in train_metrics_dict.items():
metric_fn.reset()
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 2. Validate -------------------------------------------------
net.eval()
total_loss,step = 0,0
loop = tqdm(enumerate(dl_val), total =len(dl_val),ncols=100)
val_metrics_dict = deepcopy(metrics_dict)
with torch.no_grad():
for i, batch in loop:
features,labels = batch
# ========================= Move Data to MPS ===============================
features = features.to(device)
labels = labels.to(device)
# ====================================================================
# Forward
preds = net(features)
loss = loss_fn(preds,labels)
# Metrics
step_metrics = {"val_"+name:metric_fn(preds, labels).item()
for name,metric_fn in val_metrics_dict.items()}
step_log = dict({"val_loss":loss.item()},**step_metrics)
total_loss += loss.item()
step+=1
if i!=len(dl_val)-1:
loop.set_postfix(**step_log)
else:
epoch_loss = (total_loss/step)
epoch_metrics = {"val_"+name:metric_fn.compute().item()
for name,metric_fn in val_metrics_dict.items()}
epoch_log = dict({"val_loss":epoch_loss},**epoch_metrics)
loop.set_postfix(**epoch_log)
for name,metric_fn in val_metrics_dict.items():
metric_fn.reset()
epoch_log["epoch"] = epoch
for name, metric in epoch_log.items():
history[name] = history.get(name, []) + [metric]
# 3. Early Stopping -------------------------------------------------
arr_scores = history[monitor]
best_score_idx = np.argmax(arr_scores) if mode=="max" else np.argmin(arr_scores)
if best_score_idx==len(arr_scores)-1:
torch.save(net.state_dict(),ckpt_path)
print("<<<<<< reach best {0} : {1} >>>>>>".format(monitor,
arr_scores[best_score_idx]),file=sys.stderr)
if len(arr_scores)-best_score_idx>patience:
print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(
monitor,patience),file=sys.stderr)
break
net.load_state_dict(torch.load(ckpt_path))
dfhistory = pd.DataFrame(history)
4. Using TorchKeras to Support Mac M1 Chip Acceleration
I have introduced support for the Mac M1 chip in the latest version 3.3.0 of TorchKeras. When a Mac M1 chip/GPU is available, it will be used for acceleration by default without any configuration.
Here is an example of usage. 😋😋😋
!pip install torchkeras>=3.3.0
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader
import torchkeras # Attention this line
#================================================================================
# 1. Prepare Data
#================================================================================
import torchvision
from torchvision import transforms
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="mnist/",train=True,download=True,transform=transform)
ds_val = torchvision.datasets.MNIST(root="mnist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=2)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=128, shuffle=False, num_workers=2)
for features,labels in dl_train:
break
#================================================================================
# 2. Define Model
#================================================================================
def create_net():
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=64,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=64,out_channels=512,kernel_size = 3))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(512,1024))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(1024,10))
return net
net = create_net()
print(net)
# Evaluation Metrics
class Accuracy(nn.Module):
def __init__(self):
super().__init__()
self.correct = nn.Parameter(torch.tensor(0.0),requires_grad=False)
self.total = nn.Parameter(torch.tensor(0.0),requires_grad=False)
def forward(self, preds: torch.Tensor, targets: torch.Tensor):
preds = preds.argmax(dim=-1)
m = (preds == targets).sum()
n = targets.shape[0]
self.correct += m
self.total += n
return m/n
def compute(self):
return self.correct.float() / self.total
def reset(self):
self.correct -= self.correct
self.total -= self.total
#================================================================================
# 3. Train Model
#================================================================================
model = torchkeras.KerasModel(net,
loss_fn = nn.CrossEntropyLoss(),
optimizer= torch.optim.Adam(net.parameters(),lr=0.001),
metrics_dict = {"acc":Accuracy()}
)
from torchkeras import summary
summary(model,input_data=features);
# if gpu/mps is available, will auto use it, otherwise cpu will be used.
dfhistory=model.fit(train_data=dl_train,
val_data=dl_val,
epochs=15,
patience=5,
monitor="val_acc",mode="max",
ckpt_path='checkpoint.pt')
#================================================================================
# 4. Evaluate Model
#================================================================================
model.evaluate(dl_val)
#================================================================================
# 5. Use Model
#================================================================================
model.predict(dl_val)[0:10]
#================================================================================
# 6. Save Model
#================================================================================
# The best net parameters have been saved at ckpt_path='checkpoint.pt' during training.
net_clone = create_net()
net_clone.load_state_dict(torch.load("checkpoint.pt"))
5. Speed Comparison of M1 Chip with CPU and Nvidia GPU
Using the above code as an example, run it on CPU, Mac M1 chip, and Nvidia GPU respectively.
The running speed screenshots are as follows:
Pure CPU performance 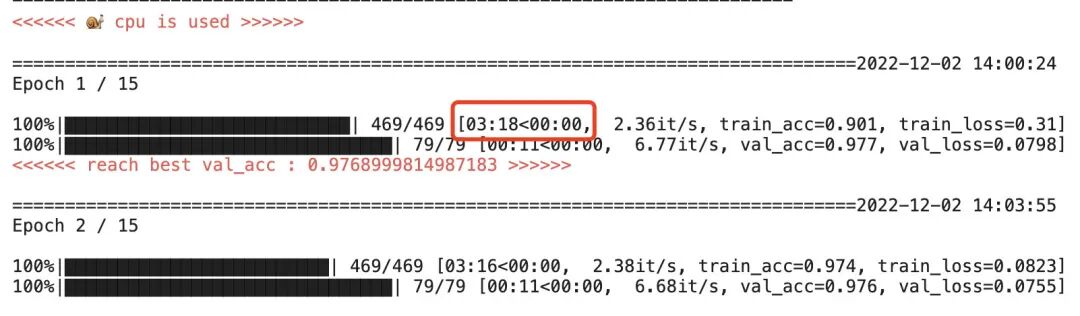
Mac M1 chip acceleration effect 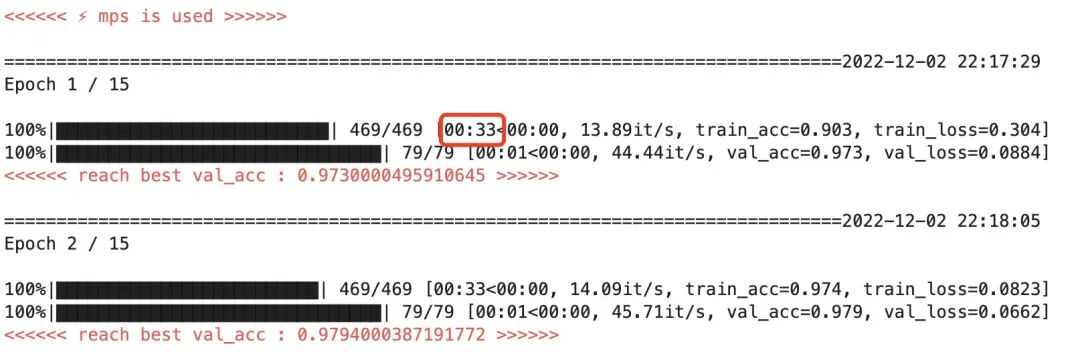
Tesla P100 GPU acceleration effect 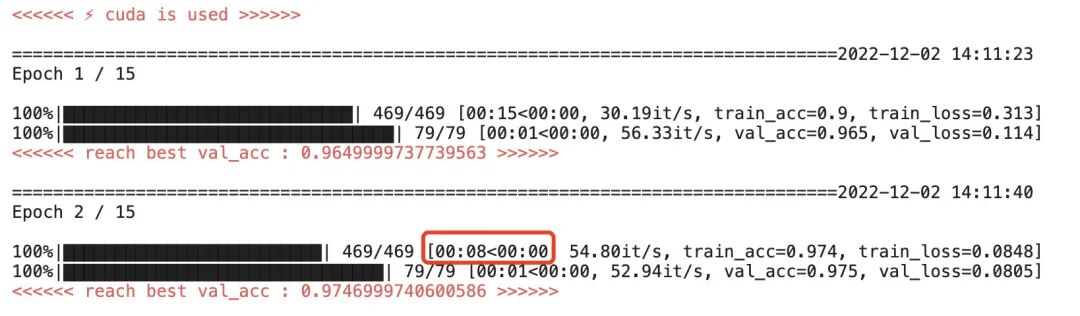
Running one epoch on pure CPU takes about 3 minutes and 18 seconds.
Using the Mac M1 chip for acceleration, one epoch takes about 33 seconds, which is approximately 6 times faster than running on CPU.
This is consistent with the average acceleration of 7 times shown on the PyTorch official website during the training process.
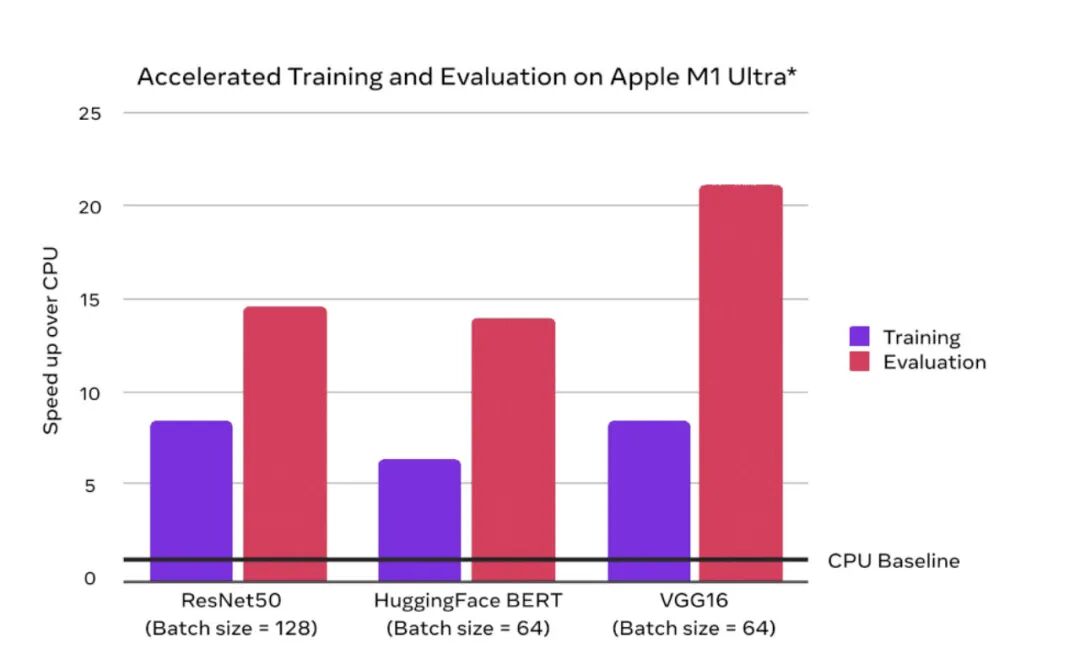
Using the Nvidia Tesla P100 GPU for acceleration, one epoch takes about 8 seconds, which is approximately 25 times faster than running on CPU.
However, currently, there is still a 2 to 4 times training speed difference compared to the high-end Tesla P100 GPU commonly used in enterprises, which can be considered a mini version of a GPU.
Therefore, the Mac M1 chip is more suitable for local training of medium to small-scale models, allowing for rapid iteration of ideas, which is quite appealing.
Especially for those who are already planning to change computers, using a Mac for development is much better than Windows.
Recommended Reading
1. Pandas 100 Cool Operations
2. Pandas Data Cleaning
3 Original Series on Machine Learning