↑↑↑ Follow and Star Kaggle Competition Guide Kaggle Competition Guide Author: Elvin Loves to Ask, excerpted from Zhai Ma
LoRA+MoE: A Historical Interpretation of the Combination of Low-Rank Matrices and Multi-Task Learning
This article introduces some works that combine LoRA and MoE, hoping to be helpful to everyone.
1. MoV and MoLoRA
Paper: 2023 | Pushing mixture of experts to the limit: Extremely parameter efficient MoE for instruction tuning.
Authors: Zadouri, Ted, Ahmet Üstün, Arash Ahmadian, Beyza Ermiş, Acyr Locatelli, and Sara Hooker
Affiliation: Cohere for AI
Citations: 91
Code: parameter-efficient-moe
Paper: https://arxiv.org/pdf/2309.05444
The authors proposed MoV (IA^3’s MoE) version and MoLORA (LoRA’s MoE), let’s first review IA^3 and LoRA.
(1) IA^3: Adds a dot product vector l_k, l_v, and l_ff to K, V, and FFN of the Transformer, respectively, and then implements additional fine-tuning on the attention layer (i.e., only fine-tuning these 3 vectors l), as shown below. Here, W1 and W2 are the frozen parameters of the forward feedback layer of the pre-trained model.
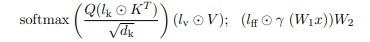
(2) LoRA: Adds an incremental parameter matrix to the pre-trained weight matrix W0, but performs a low-rank transformation to reduce the amount of incremental parameters.
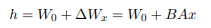
The idea of adding MoE is quite simple, as shown in the figure below, which adds n experts, each expert being a parameter function, and then uses the input of the target fine-tuning layer to route to the experts to obtain the weights of each expert, and then performs a weighted sum of the outputs of the experts to produce the final output.
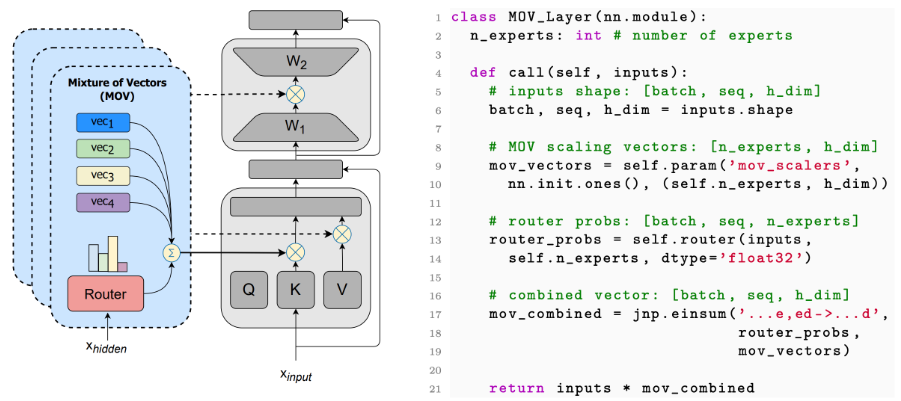
Figure: MoV Layer
The experimental performance is as follows, showing no significant difference compared to full parameter fine-tuning.
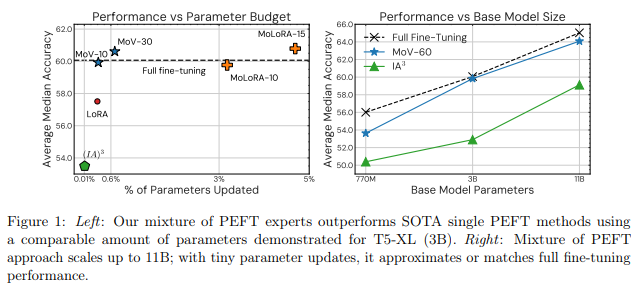
Figure: Comparison of experimental results of MoV and MoLoRA with full parameter fine-tuning
2. LoRAMoE
Paper: 2023 | LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
Authors: Dou, Shihan, Enyu Zhou, Yan Liu, Songyang Gao, Jun Zhao, Wei Shen, Yuhao Zhou et al
Citations: 23
Code: None
Paper: https://simg.baai.ac.cn/paperfile/96f0cfd7-79c7-4110-88e5-4ea80a7fbc8d.pdf
The figure below shows that instruction fine-tuning leads to the gradual forgetting of the world knowledge learned from the original pre-training. To address this, the authors proposed LoRAMoE, which incorporates both world knowledge and instruction data into LoRA’s multi-task learning, allowing experts to handle both tasks effectively.
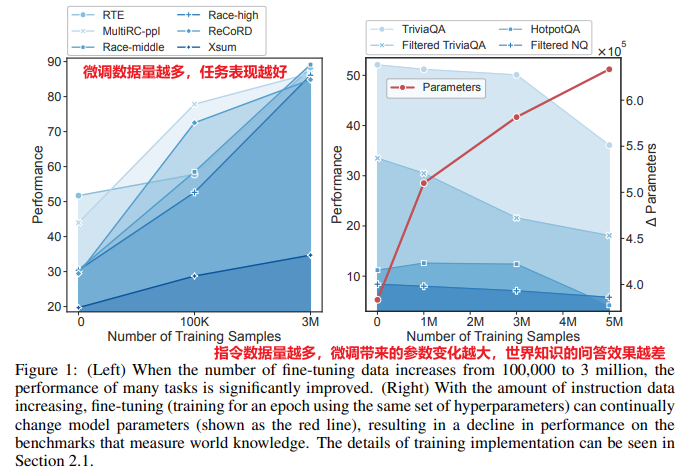
Figure: Original knowledge forgetting caused by fine-tuning
The architecture of LoRAMoE is shown in the figure below:
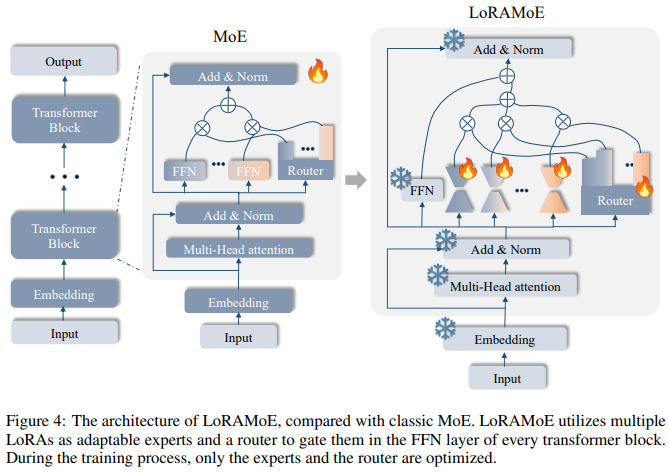
Figure: Differences between LoRAMoE architecture and traditional MoE architecture
The left figure shows that in the unconstrained LoRAMoE model, the coefficient of variation of the experts eventually stabilizes at a high level, indicating that a few experts dominate for a long time. Without constraints, the expert allocation may become unbalanced, leading to some experts being overused while others are gradually marginalized.
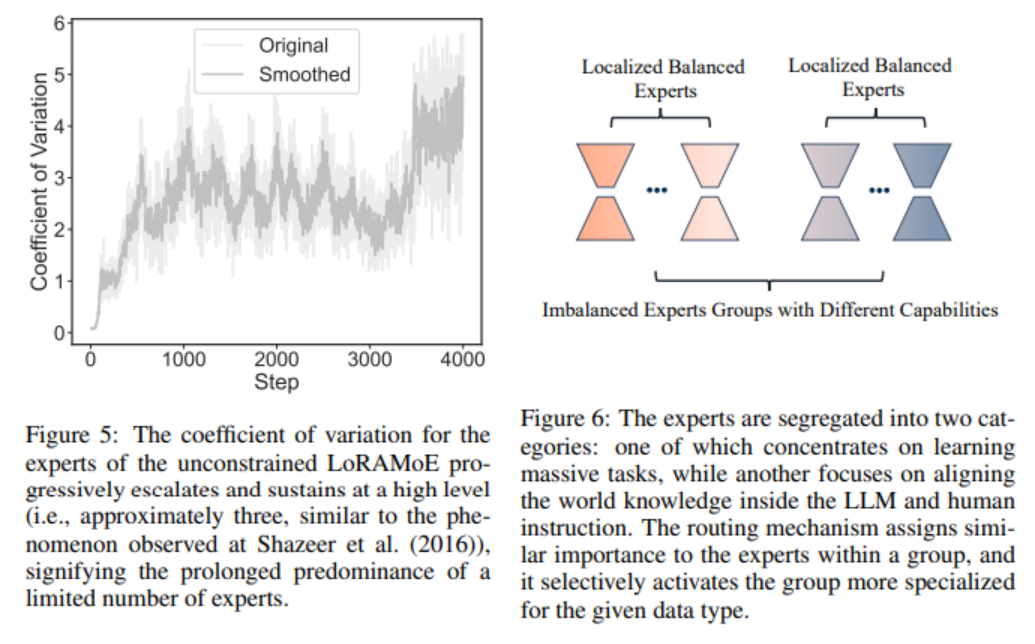
Left figure: Expert coefficient of variation; Right figure: Expert classification
Therefore, as shown in the right figure, we need to have an unbalanced group of experts, where the imbalance refers to the differences in capabilities among different expert groups. For example, one type of expert is responsible for maintaining world knowledge in the pre-trained model, while another type of expert is responsible for learning new instruction-following task knowledge. To achieve this, constraints need to be added to the LoRAMoE model. First, formally, the importance matrix Q of the LoRAMoE layer is defined, where Q_{n,m} represents the sum of the router values of the n-th expert in the m-th training sample:
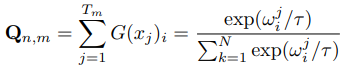
Where N and T_m represent the number of experts and the number of tokens in the m-th training sample, respectively. x_j is the hidden input of the j-th token to the LoRAMoE layer. This is all understandable.
Then, a coefficient matrix I of the same size as the importance matrix Q is defined, where I_{n,m} represents the importance coefficient of Q_{n,m}, which can be written as:
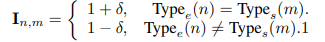
Where delta∈[0,1] controls the degree of imbalance between expert groups. Type refers to the task type, and there are two types of tasks mentioned earlier: CBQA (data of world knowledge) and other downstream task data. If the task type Type_e (𝑛) of the n-th expert is equal to the task type Type_t (m) of the m-th training sample, it indicates that the m-th training sample should enter the n-th expert (like seeing a doctor in the right department), so 1+delta increases the importance of “seeing the right doctor”.
How does this coefficient matrix I impose constraints on the model? It is added to the original cross-entropy loss, along with the load balancing loss L_Ibc:
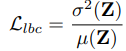
Where Z=I multiplied by Q. This is understandable; I is the weight matrix of Q, and here it is a weighting operation. The variance divided by the mean is the coefficient of variation, and the larger the coefficient of variation, the more unbalanced the expert allocation is, indicating that some experts are marginalized, which increases the loss.
The experimental performance is as follows:
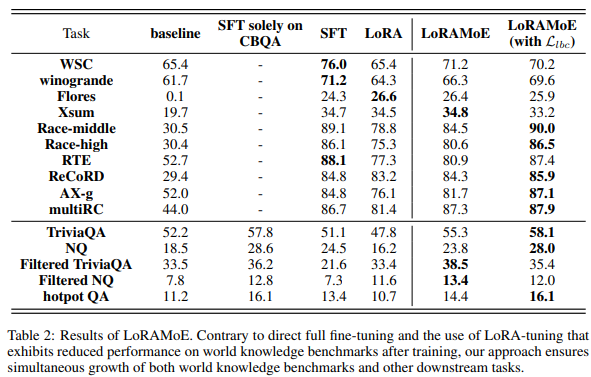
Figure: LoRAMoE Experimental Performance
3. MoLA
Paper: 2024 | Higher Layers Need More LoRA Experts Model Alignment
Authors: Gao, Chongyang, et al.
Citations: 46
Code: https://github.com/GCYZSL/MoLA
Paper: https://arxiv.org/pdf/2402.08562
This paper mainly studies the allocation of the number of LoRA experts at different layers. To this end, four different experiments on the allocation of LoRA experts at different layers were designed, and the results found that the Inverted-Triangle performed the best, indicating that higher layers need more experts, while lower layers do not require as many experts.
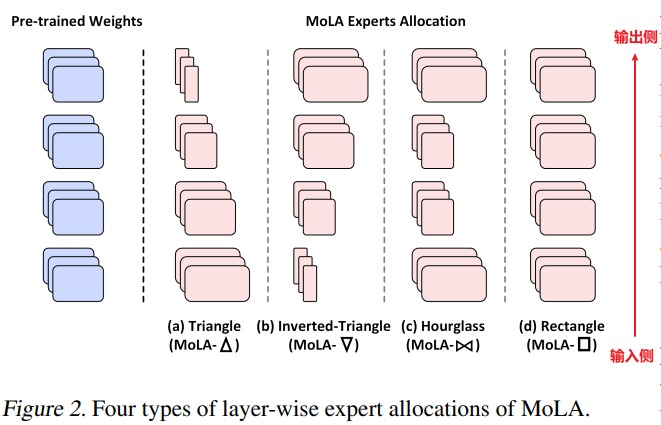
Figure: MoLA’s Design for Allocating Experts at Different Layers
Experimental performance:
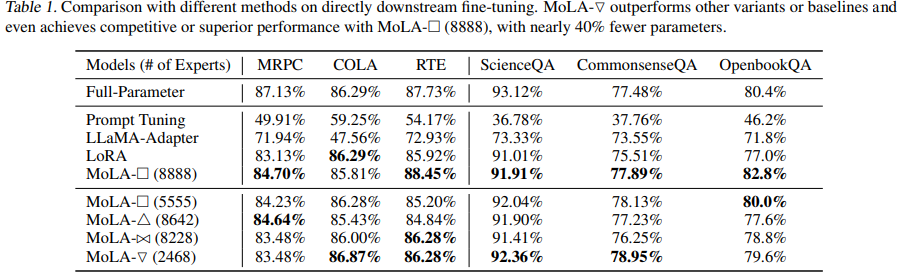
Figure: MoLA’s Experimental Performance
4. HydraLoRA
Paper: 2024 NIPS | Higher Layers Need More LoRA Experts Model Alignment
Authors: Tian, Chunlin, Zhan Shi, Zhijiang Guo, Li Li, and Cheng-Zhong Xu
Citations: 26
Paper: https://proceedings.neurips.cc/paper_files/paper/2024/file/123fd8a56501194823c8e0dca00733df-Paper-Conference.pdf
The authors discovered an issue: the main differences in fine-tuning LoRA modules between different tasks mainly come from the B matrix, while the A matrix parameters under each task are highly similar.
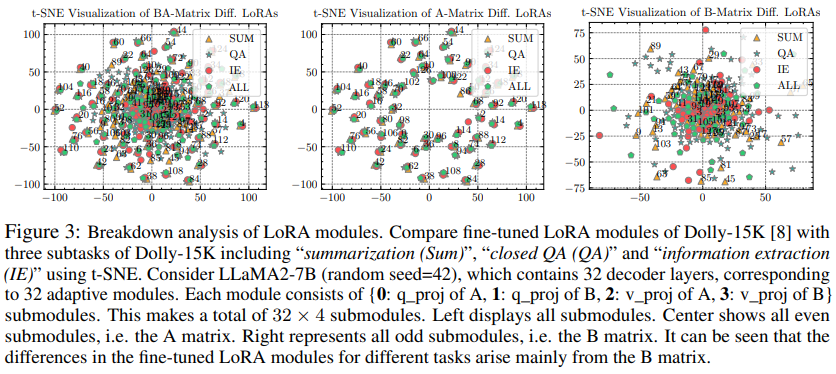
Figure: Visualization analysis of the LoRA module using t-SNE, specifically comparing the fine-tuned LoRA modules of the Dolly-15K model on three sub-tasks: Summarization, Closed QA, and Information Extraction
Thus, share A and only perform multi-expert tuning on B:
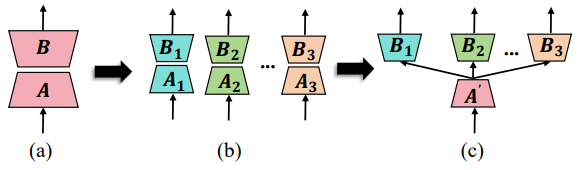
Figure: Evolution of HydraLoRA
Experimental performance:
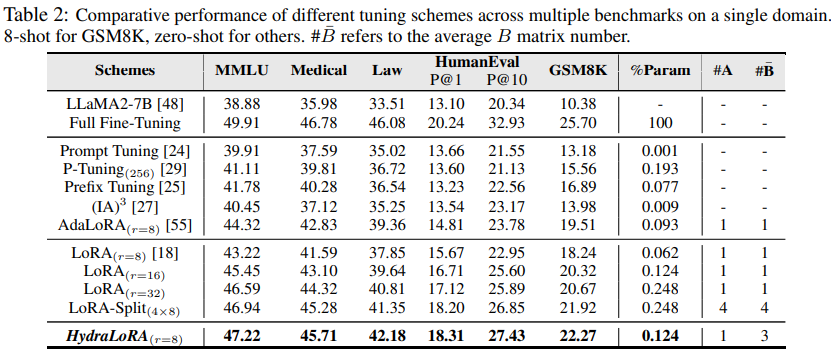
Figure: HydraLoRA’s Experimental Performance
5. Others
As I read more and more papers on LoRA+MoE, I found that the years 2023-2024 have become quite diverse in this area, but most are products of arXiv. There are very few truly innovative works that stand out. Next, I will briefly list some studies without going into detail.
MELoRA (Citations: 23, 2024 arXiv): Miniaturizes LoRA, similar to the concepts of batch and mini-batch.
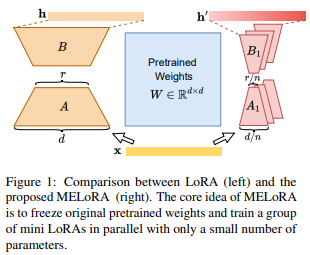
Figure: MELoRA
ALoRA (Citations: 27, 2024 arXiv): A diagonal matrix is added between A and B for pruning or reparameterization of low-rank matrices.
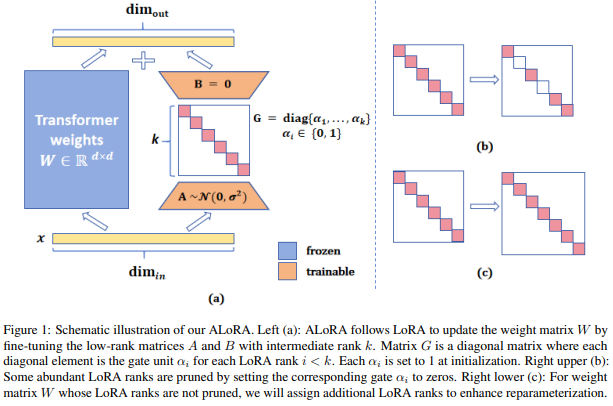
Figure: ALoRA
AdaMoE (Citations: 9, 2024 arXiv): Introduces empty experts. Each token selects the top four experts, which can be either real experts or empty experts.
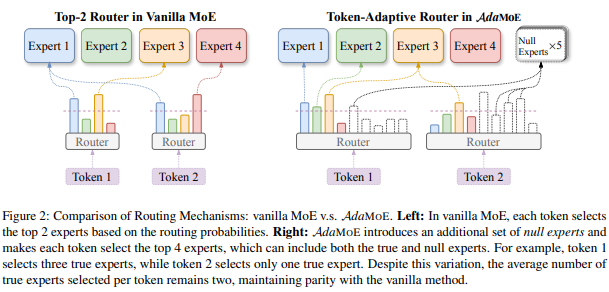
Figure: AdaMoE