In the field of large language models, the pre-training + fine-tuning paradigm has become an important foundation for deploying various downstream applications. Within this framework, the use of low-rank adaptation (LoRA) methods for efficient fine-tuning of large model parameters (PEFT) has resulted in a large number of reusable LoRA adapters tailored for specific tasks. However, the fine-tuning method using LoRA adapters requires explicit intent selection, leading to challenges in autonomous task awareness and switching when using a single large language model equipped with multiple LoRA adapters.
To address this, the DeepEngine team from the School of Computer Science at Nanjing University has proposed a scalable and efficient multi-task embedding architecture called MeteoRA. This framework reuses multiple task-specific LoRA adapters on the base model through a full-mode mixture of experts (MoE) model. It also includes a novel forward acceleration strategy for the mixture of experts model to improve the efficiency bottlenecks of traditional implementations. Large language models equipped with the MeteoRA framework have achieved outstanding performance in handling composite problems, efficiently solving ten different sequentially input problems in a single inference, demonstrating the model’s enhanced ability to switch adapters in real-time.

Paper Title:
MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models
Paper Link:
https://arxiv.org/abs/2405.13053
Project Homepage:
https://github.com/NJUDeepEngine/meteora
The innovations of this work mainly include the following parts:
-
Scalable LoRA Integration Framework: The MeteoRA framework can integrate existing LoRA adapters and provides the capability for large language models to autonomously select and switch different LoRAs on demand.
-
Forward Acceleration Strategy for Mixture of Experts Models: This reveals the efficiency issues of mixture of experts models and implements a forward propagation acceleration strategy using new GPU kernel operations, achieving an average speedup of about 4 times while maintaining the same memory overhead.
-
Outstanding Model Performance: Evaluations indicate that large language models using the MeteoRA framework exhibit exceptional performance in composite tasks, thereby enhancing the practical effectiveness of large language models when combining existing LoRA adapters.
1. Related Work
Low-Rank Adaptation (LoRA): Low-rank adaptation [1] provides a strategy to reduce the number of trainable parameters required for fine-tuning downstream tasks. For a transformer-based large language model, LoRA injects two trainable low-rank matrices into the weight matrix of each basic linear layer, representing the model’s fine-tuning on the original weight matrix through the multiplication of the two low-rank matrices. LoRA can be applied to seven weight matrices in the self-attention and multi-layer perceptron modules of transformers, effectively reducing the scale of fine-tuning weights. The application of low-rank adaptation techniques allows for training the parameters of LoRA adapters using the optimization objectives of autoregressive language models without altering the parameters of the pre-trained model.
Multi-task LoRA Fusion: LoRA adapters are typically fine-tuned to accomplish specific downstream tasks. To enhance the ability of large language models to handle multiple tasks, there are two mainstream approaches. One method is to merge datasets from various tasks and train a single LoRA adapter based on this, but related studies have shown that learning knowledge from different domains simultaneously is challenging [2]. The other method is to directly integrate multiple LoRA adapters into a single model, such as PEFT [3] and S-LoRA [4]. However, popular frameworks must explicitly specify the injected LoRA adapters, resulting in a lack of autonomous selection and timely switching capabilities for the model. Existing works like LoRAHub [5] can select LoRA adapters without manual specification, but still require a small amount of learning for each downstream task.
Mixture of Experts (MoE): The mixture of experts model is a machine learning paradigm that improves efficiency and performance by combining the predictions of multiple models, dynamically assigning inputs to the most relevant “experts” through a gating network to obtain predictions [6]. This model leverages specific knowledge from different experts to enhance overall performance on diverse and complex problems, with existing research demonstrating the effectiveness of MoE in large-scale neural networks [7]. For each input, MoE activates only a portion of the experts, significantly improving computational efficiency without compromising model size. This method has been shown to be highly effective in scaling transformer-based application architectures, such as Mixtral [8].
2. Method Description
This work proposes a scalable and efficient multi-task embedding architecture, MeteoRA, which can directly utilize LoRA adapters that have been fine-tuned for specific downstream tasks in the open-source community and autonomously select and switch appropriate LoRA adapters based on the input. As shown in Figure 1, the MeteoRA module can be integrated into all basic linear layers of the attention and multi-layer perceptron modules, with each module containing a series of low-rank matrices. Through the MoE forward acceleration strategy, large language models can efficiently solve a wide range of problems.
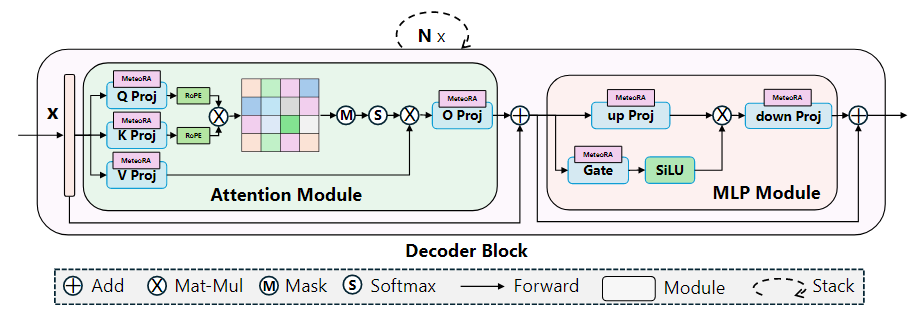
Figure 1: Large language model framework integrated with the MeteoRA module to implement the MoE architecture
Figure 2 illustrates the internal structure of the MeteoRA module. The MeteoRA module embeds multiple LoRA adapters and implements the MoE architecture through a gating network. This gating network selects the top-k LoRA adapters based on the input and combines them as fine-tuning weights for forward propagation. Through this architecture, the gating network executes routing strategies to select appropriate LoRA adapters based on the input. Each MeteoRA module contains an independent gating network, with different gating networks making independent decisions based on their inputs and dynamically selecting different LoRA adapters during the forward propagation process of all decoder modules.
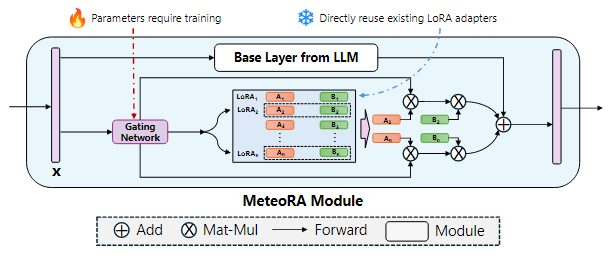
Figure 2: Architecture of the MeteoRA module integrating LoRA embeddings using the MoE model
The training of the MeteoRA module follows the model fine-tuning criteria under autoregressive language modeling tasks, requiring the base large language model weights and pre-trained LoRA adapter parameters to remain unchanged during training. Since the MeteoRA module supports the selection of the top-weighted LoRA adapters, the team introduced a joint optimization scheme that combines the autoregressive language modeling loss with the losses of all gating networks. This optimization function integrates the prediction loss in the autoregressive model with the cross-entropy loss of LoRA classification in the MeteoRA module, enabling the training of the gating networks.
The core component of the MeteoRA module is the MoE architecture that integrates multiple LoRA adapters. First, the team consolidated LoRA into tensors allocated continuously on HBM. For each token in the input sequence of each batch, since the module needs to use the gating network to find the index set of LoRA adapter numbers, the MeteoRA module is nearly impossible to maintain the same efficiency as individual LoRA modules. The simple implementation based on the original loop [8] uses a for-loop to iterate through the LoRA adapters, applying LoRA forward passes to the candidate set of that adapter in each iteration. This method simply splits all tokens of all batches into sets equal to the number of LoRAs and sequentially passes each set. However, considering the independent nature of input tokens, this method fails to fully utilize the parallelized GEMM operator [9] acceleration, especially when certain LoRA adapters are selected by only a few tokens, or when the number of tokens to be inferred is less than the number of LoRAs, potentially leading to up to 10 times the running time in experiments.
This work adopts the forward propagation acceleration strategy bmm-torch, which directly indexes the top-k adapters for all batch tokens, utilizing two bmm computations. Compared to the original loop method, bmm-torch parallelizes the top-k adapters of all batch tokens based on the bmm operator provided by PyTorch [10], achieving approximately 4 times speedup. In experiments, this strategy is only 2.5 times slower than its upper limit single LoRA module. Due to PyTorch’s indexing constraints [11], bmm-torch requires allocating larger memory for batch processing, and when the batch size or input length is too large, the high memory overhead of bmm-torch may become a bottleneck. Therefore, this work developed a custom GPU kernel operator using Triton [12] that not only maintains about 80% of the computational efficiency of bmm-torch but also keeps the low memory overhead at the level of the original loop.
3. Experimental Results
This work conducted extensive experimental validation of the proposed architecture and design on both independent and composite tasks. The experiments utilized two well-known large language models, LlaMA2-13B and LlaMA3-8B. Figure 3 shows the radar chart of the prediction performance of the MeteoRA module integrated with 28 tasks compared to single LoRA and the reference model PEFT on various independent tasks. The evaluation results indicate that regardless of the large language model used, the MeteoRA model exhibits performance comparable to PEFT, while MeteoRA does not require explicit activation of specific LoRAs. Table 1 presents the average scores of all methods across various tasks.
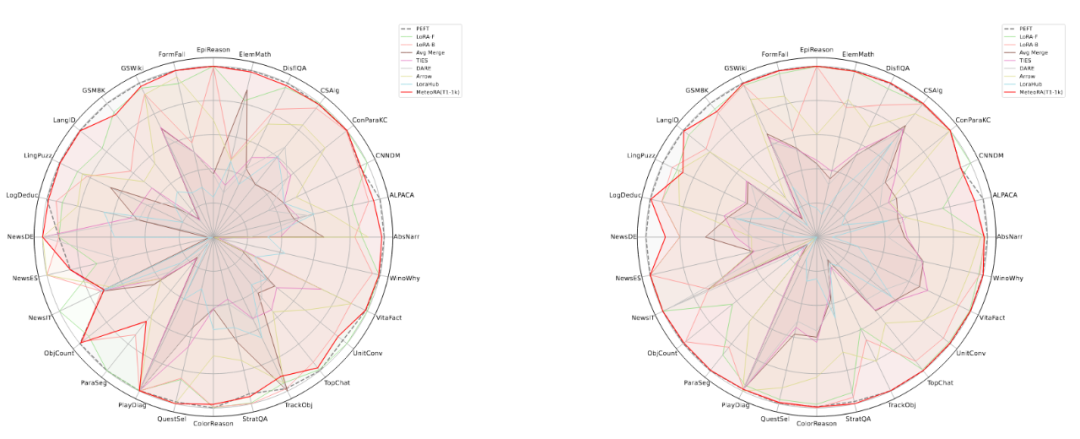
Figure 3: Evaluation performance of the MeteoRA model on 28 selected tasks
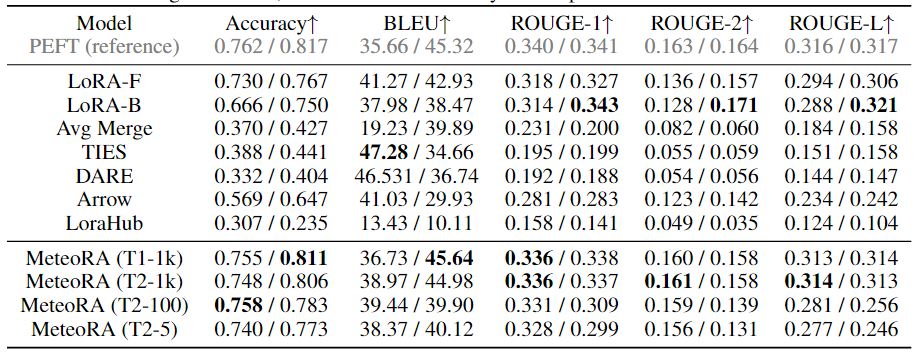
Table 1: Average performance of each model on 28 selected tasks
To verify the model’s ability to sequentially solve composite problems, this work constructed three datasets by serially connecting independent tasks, integrating 3, 5, and 10 tasks, expecting the model to solve different categories of problems input in the same sequence. The experimental results are shown in Table 2, indicating that as the number of composite tasks increases, the MeteoRA module outperforms the reference LoRA-B model in almost all aspects.
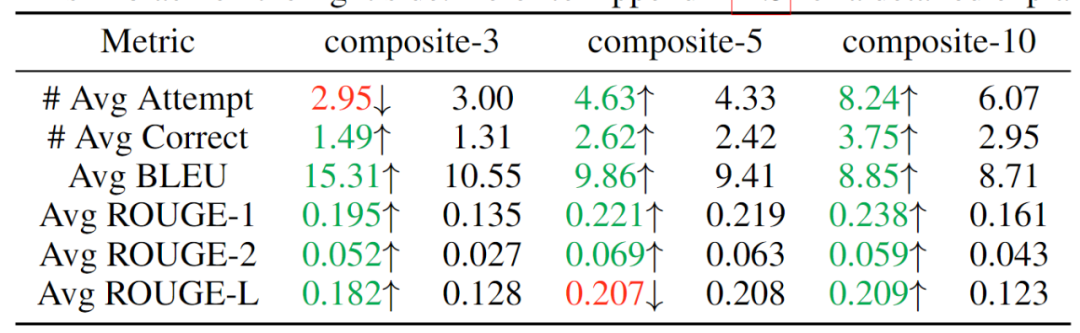
Table 2: Evaluation results of composite tasks, left side is the MeteoRA module, right side is LoRA-B
To further validate the functionality of the gating network in the MeteoRA module, this work demonstrated the LoRA selection mode using the top-2 strategy during composite task inference. At the junction of two adjacent tasks, the gating network correctly executed the switching operation of LoRA.

Figure 4: Example of LoRA selection in a composite of 3 tasks
To verify the computational efficiency of the forward propagation design using custom GPU operators, this work sampled portions of 28 tasks and compared the new forward propagation strategy with its upper limit and original implementation. The evaluation results are shown in Figure 5, demonstrating the outstanding performance of the new acceleration strategy.
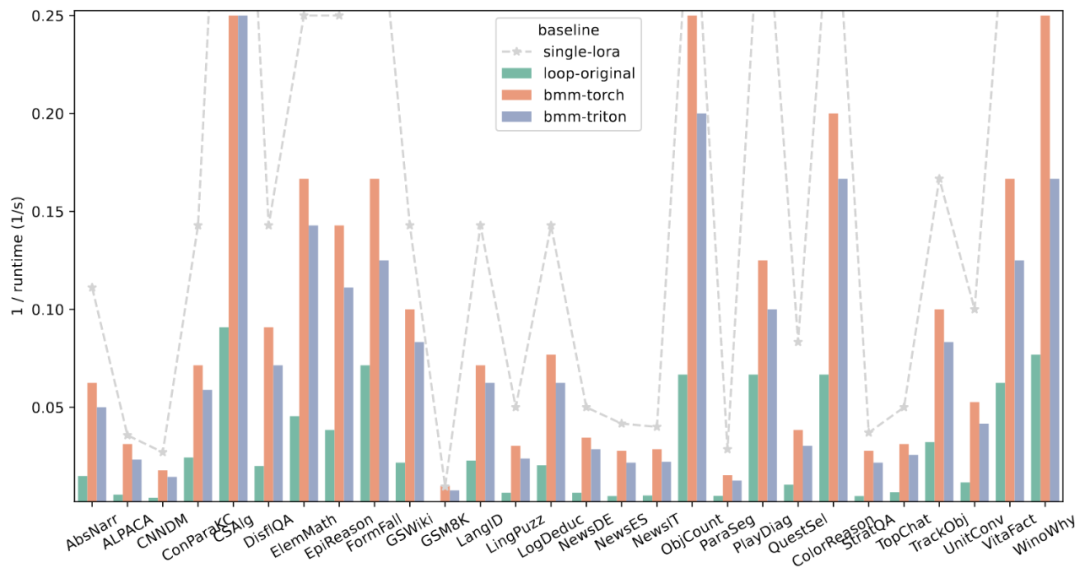
Figure 5: Overall running time of four different forward propagation strategies on 28 tasks
References
[1] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
[2] Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, Tianjiao Zhao, Amit Panalkar, Dhagash Mehta, Stefano Pasquali, Wei Cheng, Haoyu Wang, Yanchi Liu, Zhengzhang Chen, Haifeng Chen, Chris White, Quanquan Gu, Jian Pei, Carl Yang, and Liang Zhao. Domain specialization as the key to make large language models disruptive: A comprehensive survey, 2024.
[3] Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
[4] Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, et al. S-lora: Serving thousands of concurrent lora adapters. arXiv preprint arXiv:2311.03285, 2023.
[5] Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. Lorahub: Efficient cross-task generalization via dynamic lora composition. arXiv preprint arXiv:2307.13269, 2023.
[6] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3 (1):79–87, 1991.
[7] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
[8] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, MarieAnne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mixtral of experts, 2024.
[9] Shixun Wu, Yujia Zhai, Jinyang Liu, Jiajun Huang, Zizhe Jian, Bryan Wong, and Zizhong Chen. Anatomy of high-performance gemm with online fault tolerance on gpus. In Proceedings of the 37th International Conference on Supercomputing, pages 360–372, 2023b.
[10] PyTorch. torch.bmm — pytorch 2.3 documentation. https://pytorch.org/docs/stable/generated/torch.bmm.html, 2024a. Accessed: 2024-05-23.
[11] PyTorch. Tensor indexing api — pytorch documentation. https://pytorch.org/cppdocs/notes/tensor_indexing.html, 2024b. Accessed: 2024-05-23.
[12] Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
Authors: Xu Jingwei, Lai Junyu, Huang YunpengSource: WeChat Official Account 【Machine Heart】
Illustration From IconScout By IconScout Store-The End-

Scan to watch!
This week new arrivals!

“AI Technology Flow” Original Submission Plan
TechBeat is an AI learning community established by Jiangmen Venture (www.techbeat.net). The community has launched over 600 talk videos and more than 3000 technical articles, covering areas such as CV/NLP/ML/Robotics, etc.; regularly hosting top conferences and other online communication activities, and occasionally organizing offline gatherings for technical personnel. We are striving to become a high-quality, knowledge-based communication platform favored by AI talents, aiming to provide more professional services and experiences for AI talents, accelerating and accompanying their growth.
Submission Content
// Latest Technology Interpretation / Systematic Knowledge Sharing //
// Cutting-edge Information Explanation / Experience Sharing //
Submission Guidelines
Submissions must be original articles and include author information.
We will select some articles that provide greater inspiration to users in the areas of in-depth technical analysis and research insights for originality content rewards.
Submission Method
Email to
or add staff WeChat (yellowsubbj) for submission communication; you can also follow the “Jiangmen Venture” official account and reply “Submission” to get submission instructions.


About “Jiangmen”▼Jiangmen is a new venture capital institution focused on the field of core technology of digital intelligence, and is also a benchmark incubator in Beijing.The company is committed to connecting technology and business, discovering and nurturing technology innovation enterprises with global influence, and promoting enterprise innovation development and industrial upgrading. Jiangmen was established at the end of 2015, and the founding team was built by the original team of Microsoft Ventures in China, which has selected and deeply incubated 126 innovative technology startups.If you are a startup in the technology field looking not only for investment but also for a series of continuous and valuable post-investment services, feel free to send or recommend projects to “Jiangmen”: [email protected] Click the top right corner to share the article to your friendsClick the “Read the original text” button to view the original text from the community
Click the top right corner to share the article to your friendsClick the “Read the original text” button to view the original text from the community