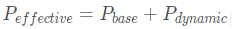Click ▲ to follow “CU Technology Community” and pin it to the top of your public account
More exciting content delivered at the first time
Link:https://blog.csdn.net/dog250/article/details/96362789
First, let’s see if it’s true, then ask why.
I know someone will say this, but that would make it an argumentative essay, and I just want to write a casual piece. So, regardless of whether the fact is true, I just feel that Windows, MacOS, and iOS are very smooth, while Linux and Android are lagging. Of course, this refers to the GUI; if we change the consideration to the throughput and latency of web services, the conclusion would probably be reversed. However, that’s something that client programs feel, and as a person, who cares!
I also have another intention in writing this article, which is to draw a topic: if we want to optimize Linux and Android (of course, the Android kernel is also Linux) so that the GUI no longer lags, what should we do?
About a year ago, on a hot afternoon after lunch, my colleagues and I were wandering near the company, discussing “Why do Apple phones run smoothly while Android phones lag regardless of how expensive they are?” I remember one colleague said that iOS has done a lot of optimizations in terms of GUI, while Android has not.
This statement is correct! However, a more important point is that discussing optimization without talking about specific scenarios is futile!
Whether it’s Windows or iOS, they know their application scenarios, so after optimizing for their application scenarios, they can outperform Linux in those scenarios by a wide margin.
Before we officially start the technical analysis, let me state a few points.
-
This article does not claim that the Linux system is generally laggy; it only states that GUI programs on the desktop version of Linux are laggy compared to Windows. If you really think this article is criticizing Linux, then consider it a critique of the Linux desktop.
-
This article does not intend to discuss the differences between X window and Windows window subsystem, one in user mode and the other in the kernel, as that is irrelevant. My thought is that even if you throw X window into the kernel, the existing Linux kernel’s handling of GUI will still lag.
-
This article evaluates why Windows/iOS are smooth while Linux lags only from the perspective of scheduling algorithms. Of course, there are other perspectives, but they are not the focus of this article.
-
The Windows kernel schedules threads instead of processes; however, this article uniformly uses the term process for no other reason than that the concept of a process aligns with modern operating system concepts, while the concept of a thread came later.
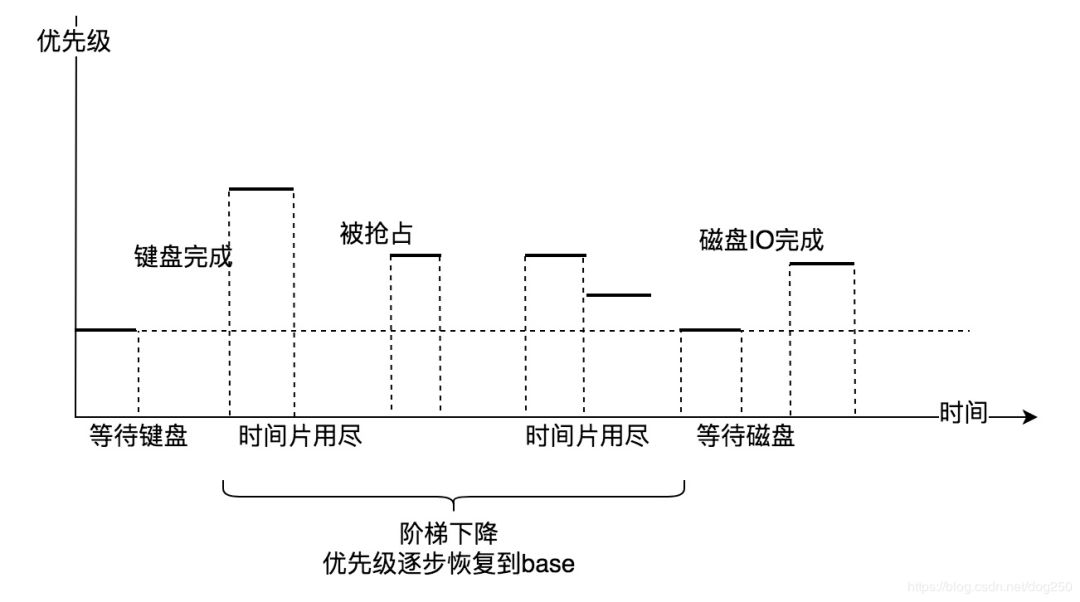
First, let’s look at the service targets, which distinguishes the usage scenarios of Windows, MacOS/iOS, and Linux:
-
Windows/MacOS/iOS systems are mainly operated by people, providing services for document writing, gaming, reporting, drawing, web browsing, video playback, etc.
-
Linux systems mainly provide network services, supporting various remote clients, providing data processing and querying, data generation, data storage, and other services.
It has been proven that Linux has done well enough in its specialized fields, but the question is, why has it always been poor in GUI processing? This comes down to the differences in specific scenarios.
For network services, the behavior of the scenarios is predictable, and we can simply summarize these scenarios as:
-
Fair and fast processing of concurrent network requests.
-
Fair and fast processing of concurrent disk IO.
-
High-throughput CPU-intensive data processing and calculations.
The excellent O(1) scheduler and the later CFS scheduler of Linux can perfectly cover the above three scenarios. As for why, there’s no need to elaborate; a simple summary is as follows:
-
Whether it’s O(1) based on priority time-slicing or CFS based on weighted time quotas, both can meet the differentiated service needs of priority while ensuring high throughput, which comes from the scheduler itself rather than relying on frequent context switches.
-
Additional simple heuristic reward and punishment mechanisms can make the responsiveness of network IO and disk IO higher without affecting the high throughput of CPU-intensive computing services.
The second point above is an additional aid, taking care of the IO process to quickly obtain responsiveness, which is a very nice support. However, note that no matter how good the heuristic algorithm is, it is always auxiliary; improving responsiveness is an auxiliary function that enhances the main goal of high throughput.
The IO process is the only channel for a Linux server to interact with the outside world, through which processed data can be sent out to the network or disk, while new data can be obtained from the network or disk. In other words, the IO process is like a door. But it is merely a door.
Taking care of the IO process to achieve high responsiveness is to make the door wider and increase the efficiency of passage!
Those familiar with the evolution of the Linux kernel scheduler should know that the transition from O(1) to CFS occurred during the 2.6.0 kernel to 2.6.22 versions, which adopted the epoch-making O(1) scheduler. However, due to two reasons:
1. The dynamic range of the O(1) scheduler is either too large or too small.
2. The IO compensation mechanism is inadequate, leading to unfair time slice allocation.
To solve these problems, the Linux kernel switched to the CFS scheduler.
With the switch to the CFS scheduler, people expected that CFS could make the time slice allocation of processes fairer and allow multiple processes to run more smoothly. Thus, wouldn’t the GUI interface be smooth as well?
However, it still lags, and the fundamental reason is that the scenarios are simply not appropriate.
In the scenario of a Linux server, priority and time slices are positively correlated. Whether it’s the static linear mapping time slice of the O(1) scheduler or the dynamic time quota of CFS, the higher the priority of the process, the longer it runs each time. However, in reality, these two are not the same thing.
In more complex scenarios, the correct approach should refer to the Four Quadrant Method of Time Management to design the process scheduler. Among them:
1. Processes handling important and urgent events need to be assigned high priority and long time slices to preempt the current process.
2. Processes handling important but not urgent events should maintain their inherent priority and be assigned long time slices for readiness.
3. Processes handling unimportant but urgent events should have their priority increased but not be assigned long time slices, returning to their inherent priority immediately after completion.
4. Background processes that are neither important nor urgent should have low priority and short time slices, scheduled only when the system is idle.
Later, we will see that the Windows scheduler is designed this way.
Let’s first take a general look at the GUI system’s scenarios.
Its service target is people, which is in stark contrast to the predictable behavior of Linux’s service scenarios; human operations are unpredictable!
GUI processes in desktop systems like Windows and MacOS/iOS are often waiting for further operations from people and are asleep, either waiting for the mouse, waiting for the keyboard, waiting for sound card and graphics card output, or waiting for IO completion while writing user input information to the disk. Desktop systems focus more on providing efficient response services to these events rather than the system’s data throughput.
Desktops care about latency, not total throughput, and this latency is treated differently. Some latency tolerances are very high, such as network cards (the reason why the priority of network card IO is not significantly elevated is that network cards have queue buffers, and most packets come in bursts, allowing the queue buffer to smooth out the initial packet delay. Moreover, due to the speed of light limit, compared to network latency, host scheduling latency can be ignored), while others are very small, such as keyboard and mouse. Therefore, Windows and similar desktop systems must be able to distinguish between the current urgency and importance of a process.
Can the Linux kernel achieve this distinction?
Linux can determine whether a process is an interactive IO process by calculating its average sleep time, thus deciding whether to give it a certain priority boost. However, this is only as far as it can go because the Linux kernel cannot obtain further information.
The Linux kernel does not know whether a process is an IO process or merely a CPU-intensive process that has IO behavior during a time period. The Linux kernel also does not know whether a process is awakened because keyboard data has arrived or an irrelevant signal has arrived. Therefore, all of this can only be predicted heuristically.
The Linux kernel can only track an average sleep time, which cannot distinguish the current urgency and importance of a process. Without external information input, relying solely on heuristic predictions, current AI algorithms seem to have not reached this level yet. In other words, heuristic algorithms are inaccurate. If you look at how the sleep_avg of the Linux kernel’s O(1) scheduler is calculated and how it participates in dynamic priority adjustment, you will understand what I mean.
Since Windows GUI operations are smoother than Linux, it must be that Windows has achieved a distinction between the current urgency and importance of processes, right? Of course. How does it achieve this?
Although the Windows scheduler is also priority-based, preemptive, and uses round-robin for processes of the same priority, which seems no different from Linux, almost all operating system schedulers have been designed with this idea since 4.3BSD. Looking at the how to select the next process to run algorithm, almost all operating system schedulers are similar. The reason Windows is different lies in its different handling of priorities.
Since 4.3BSD, all priority-based preemptive schedulers’ priority calculations include two factors: inherent priority and dynamic priority:
All along,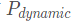 has only played a fine-tuning role, while
has only played a fine-tuning role, while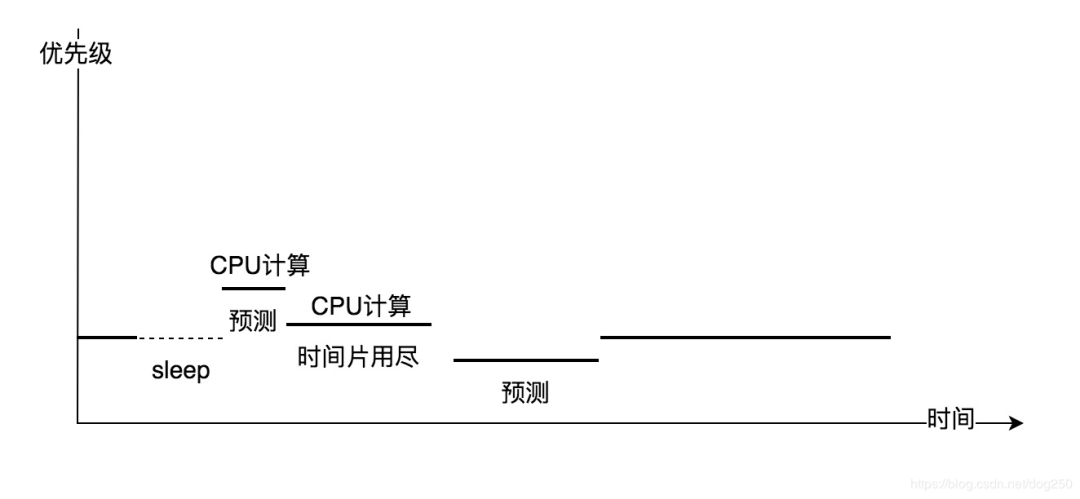 is more significant.
Windows is different in that it weakens the initial base priority of the process (actually it should be threads, but I will uniformly refer to it as processes for the sake of readers who do not understand Windows kernel principles) while strengthening dynamic priority
is more significant.
Windows is different in that it weakens the initial base priority of the process (actually it should be threads, but I will uniformly refer to it as processes for the sake of readers who do not understand Windows kernel principles) while strengthening dynamic priority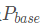 , more importantly, the value of dynamic priority does not come from prediction but from events, the urgency of the events feeds back into the value of dynamic priority, while the importance of the events feeds back into the time slice:
It can be seen that Windows defines specific values for priority increments for different events, precisely associating the value of dynamic priority with specific events.
In the definition of these values, the details are even meticulous and considerate; detailed values can be found in ntddk.h:
, more importantly, the value of dynamic priority does not come from prediction but from events, the urgency of the events feeds back into the value of dynamic priority, while the importance of the events feeds back into the time slice:
It can be seen that Windows defines specific values for priority increments for different events, precisely associating the value of dynamic priority with specific events.
In the definition of these values, the details are even meticulous and considerate; detailed values can be found in ntddk.h:
// Priority increment definitions. The comment for each definition gives
// the names of the system services that use the definition when satisfying
// a wait.
// Priority increment used when satisfying a wait on an executive event
// (NtPulseEvent and NtSetEvent)
#define EVENT_INCREMENT 1
// Priority increment when no I/O has been done. This is used by device
// and file system drivers when completing an IRP (IoCompleteRequest).
#define IO_NO_INCREMENT 0
// Priority increment for completing CD-ROM I/O. This is used by CD-ROM device
// and file system drivers when completing an IRP (IoCompleteRequest)
#define IO_CD_ROM_INCREMENT 1
// Priority increment for completing disk I/O. This is used by disk device
// and file system drivers when completing an IRP (IoCompleteRequest)
#define IO_DISK_INCREMENT 1
// Priority increment for completing keyboard I/O. This is used by keyboard
// device drivers when completing an IRP (IoCompleteRequest)
#define IO_KEYBOARD_INCREMENT 6
// Priority increment for completing mailslot I/O. This is used by the mail-
// slot file system driver when completing an IRP (IoCompleteRequest).
#define IO_MAILSLOT_INCREMENT 2
// Priority increment for completing mouse I/O. This is used by mouse device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_MOUSE_INCREMENT 6
// Priority increment for completing named pipe I/O. This is used by the named pipe
// file system driver when completing an IRP (IoCompleteRequest).
#define IO_NAMED_PIPE_INCREMENT 2
// Priority increment for completing network I/O. This is used by network
// device and network file system drivers when completing an IRP
// (IoCompleteRequest).
// The reason the priority of network card I/O is not significantly elevated is that
// first, network cards have queue buffers, and most packets come in bursts,
// allowing the queue buffer to smooth out the initial packet delay. Secondly, due to
// the speed of light limit, compared to network latency, host scheduling latency
// can be ignored.
#define IO_NETWORK_INCREMENT 2
// Priority increment for completing parallel I/O. This is used by parallel
// device drivers when completing an IRP (IoCompleteRequest)
#define IO_PARALLEL_INCREMENT 1
// Priority increment for completing serial I/O. This is used by serial device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_SERIAL_INCREMENT 2
// Priority increment for completing sound I/O. This is used by sound device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_SOUND_INCREMENT 8
// Priority increment for completing video I/O. This is used by video device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_VIDEO_INCREMENT 1
// Priority increment used when satisfying a wait on an executive semaphore
// (NtReleaseSemaphore)
#define SEMAPHORE_INCREMENT 1
---------------------
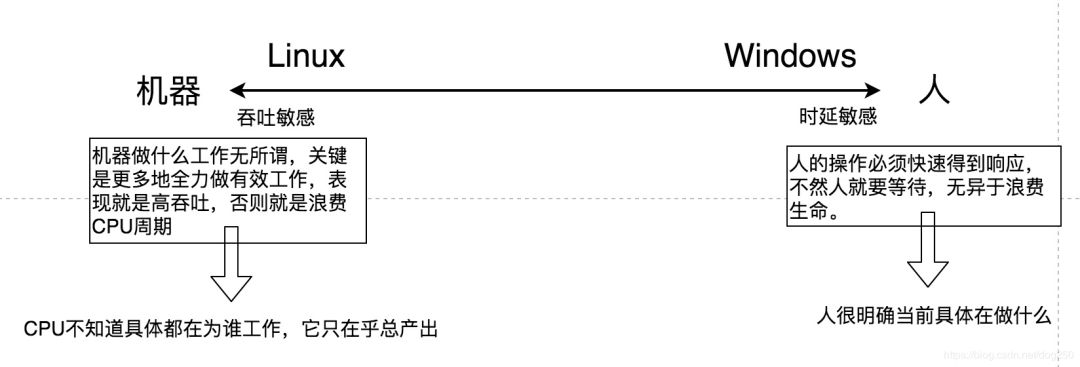
Upon careful examination, you will notice that for sound cards, the priority increment upon IO completion is very high, while for disks and graphics cards, it is not very high. This fully reflects the designer’s consideration of the sensitivity of the human ear compared to the resolution of the human eye. Sound is output in a flowing sequence, and the ear can easily discern sound lag, while images can be slowly double-buffered, and the human eye does not have such high resolution to recognize this. Therefore, sound card events must be processed first. Additionally, the IO completion of keyboard and mouse operations also has considerable priority increments, as lag in keyboard and mouse inputs can be clearly felt by people, making mouse movements seem sluggish. These are easily recognizable lag events, so Windows gives processes higher dynamic priority to quickly handle these events.
For the window subsystem, when a window gains focus, the corresponding processing process’s priority is also elevated, giving the impression that the interface you are operating is always very smooth because the interface you are interacting with is the foreground window. As for the processing processes of background windows, even if they are dead, you won’t feel it because you are not interacting with them. When you do interact with them, the corresponding processing process’s priority will be elevated.
All priority elevations come with a recalculation of time slices, but unlike Linux, Windows does not directly correlate process priority with time slices; time slices are calculated independently. Most of the time, Windows uses the same time slice for all processes, regardless of priority.
Thus, it appears that although Windows is also a priority scheduling system, its priority is driven by operational behavior, which is what makes it different.
Can the Linux kernel scheduling system finely distinguish between disk events’ wake-up and keyboard/mouse/sound card events’ wake-up? No.
Having discussed why Windows GUI operations are smooth, it’s time to address some negatives about Windows. Why does Windows often crash?
This largely relates to the scheduler described above.
Looking closely at this operation-behavior-driven dynamic priority scheduler, a significant issue is that it easily starves low-priority processes, especially those with very low Pbase.
Windows’ solution is to use a background process (officially called the balancing set management thread) that polls to elevate the priority of processes that have not been scheduled for more than a second to a high position for preemption.
What is the problem with this mechanism? The issue is that Windows relies on a third-party thread to alleviate starvation rather than relying on the scheduler itself, which increases the likelihood of scheduling failures:
-
The third-party thread itself does not work as expected.
-
Too many starving processes.
-
Starving processes are elevated in priority but are preempted again.
-
…
Aside from the crashing issue, Windows has not elegantly adjusted the scheduler for the server version. Windows has only adjusted system parameters for the server version and has made almost no modifications to the scheduling algorithm. For the server version, Windows simply extended the time slice and almost no longer dynamically calculates it, opting to always use a sufficiently long value to reduce process switching and increase throughput. This approach is clearly inappropriate because dynamic priority increases based on events will still cause processes to continually preempt each other, affecting throughput.
However, since Windows is a desktop system, it is not fundamentally designed for high throughput; such strategy adjustments for the server version are understandable. Just as Linux servers can perfectly handle high-throughput scenarios, the desktop versions like Ubuntu and Suse are also somewhat limited, right? Although the Linux kernel also has the notion of dynamic priority elevation.
In human-machine interaction, Windows is closer to the human end, adapting to human operational behavior, providing a good short-latency experience for the person operating the machine. In contrast, Linux is closer to the machine end, allowing the CPU to run tasks at full throttle instead of frequent switching, thus providing maximum data throughput for clients.
Windows’ design is indeed exquisite, considering every detail of human behavior (except for tolerance to crashes). In addition to the precise association of dynamic priority with specific events, the deadline for standby recovery time within 7 seconds is also noteworthy. This 7-second threshold considers the limits of human short-term memory; if someone suddenly thinks of an idea and needs to open the computer to record it, if the time to open the computer exceeds 7 seconds, that idea may slip away, so the standby recovery time must be limited to within 7 seconds. Isn’t that impressive?
Regarding MacOS/iOS, I haven’t researched it much, but it can be imagined that it should also be similar to Windows because they are both on the human end of human-machine interaction. I casually looked at MacOS’s development manual and found the following paragraph:
When I searched for things related to GUI and scheduling, I found the following definition just below that paragraph:
It seems that the kernel can also recognize the so-called foreground window.
In any case, Windows, MacOS/iOS, and these systems share a common feature: Most of the time, only one focus window is at the front end receiving input and output. After all, it is rare to minimize windows to fill a screen. So what? This is a typical scenario!
Just look at Win10; can’t it be set to tablet mode?
Piling all the resources and mechanisms of the machine and operating system kernel to take care of this few, almost unique front-end focus window processing process is almost like single-process processing! Then handle user window switching, such as Windows’ Ctrl-Tab.
If Linux followed this idea, writing a separate scheduler to replace CFS instead of adding a scheduling class, it would optimize the system processes uniformly according to the priority and event association method; I believe the issues could be significantly improved.
It is getting late, so let’s say something else but related.
The history of the Linux kernel’s O(1) scheduler is actually very short, from 2.6 initial to 2.6.22, but many classic books on the Linux kernel are describing the versions during this period. This gave people the illusion that the O(1) scheduler is invincible and epoch-making. So when the new CFS scheduler emerged, people were amazed, saying that O(1) is only at the galaxy level, while CFS is at the cosmic level.
However, the significance of O(1) is merely optimizing how to quickly find the next process to run. Although it also involves dynamic priority calculation, that is not its focus. To be honest, if you look at Windows’s scheduler, 4.4BSD, SystemV4’s scheduler, they are basically in the form of bitmap plus priority queue, and the ideas are almost the same. That being said, they are all O(1) as well, and these schedulers existed for years before Linux had O(n) schedulers, yet nobody paid attention to them.
The reason Windows kernel scheduling algorithms are not well-known is not only because they are closed-source but also because the overall promotion of Windows kernel technology is too limited. In China, apart from Pan Aimin, who has been committed to promoting this area, there is no one else. Perhaps it’s because people feel that learning about Windows kernel beyond debugging is not very useful.
It’s true that Linux is open-source, but isn’t BSD also open-source? Why hasn’t anyone noticed the scheduling implementation in BSD? Haha, whether it is open-source or not doesn’t matter; what matters is whether it can create momentum and make things happen, and whether it is easily accessible for everyone to use. Linux version 2.4 was frankly terrible, but the key is that many people used it; that’s all that matters. Solaris, while perfectly and elegantly designed, had barriers to entry, and no one used it, and eventually, it also fell by the wayside. The same can be said for Ethernet.
The entire article compares how the Windows and Linux schedulers affect people’s operational experience. Finally, let’s talk about iOS and Android, as a side note, without involving technology.
Android lags, and I will not accept rebuttals.
No matter how expensive the Android device is, it lags, whether it’s Samsung or Huawei; they all lag, just slightly better than others. This means they cannot become arcade machines. Because phones are meant to be used, not debugged. Except for programmers, no one cares about the reasons for Android lagging. Even programmers often do not have the energy to debug it; it’s just that their profession makes it incorrect not to use Android. However, many programmers in internet companies are using iPhones now because they are convenient. Moreover, internet company programmers are mostly focused on business logic, lacking in-depth technical knowledge, so they naturally use whatever works well. iPhones are expensive, but internet programmers earn well.
Ultimately, the only advantage of Android is its price. Try selling Android devices for the same price as iPhones, and they will be crushed in an instant. If we talk about the only other advantage, it’s the brand; Samsung is not to be underestimated. Even if Samsung’s products are subpar, it still holds market share simply because of its brand; for instance, I am a Samsung user. I do not think Samsung’s Android is better than Xiaomi’s Android, but I like the Samsung company and brand, and that is all.
The 11th China System Architect Conference (SACC2019) hosted by the ITPUB community is grandly launched. This conference continues to use the four main line parallel speaking mode, setting up three main lines of business system architecture design, big data platform architecture design, digital transformation practice, and sub-lines such as microservices, open-source architecture design, and cloud-native, with a total of 1 main venue, 20 technical sub-venues, and 100+ guests from the internet, finance, manufacturing, e-commerce, and other fields.Please click【Read the original text】 to enter the conference official website.
Are you watching?
 Click to enter the SACC2019 conference official website~
Click to enter the SACC2019 conference official website~