Integrated circuit EDA tools are not a single tool, but rather a collection of point tools that form a toolchain from front-end design (RTL to gate-level netlist) to back-end design (gate-level netlist to GDS). This includes synthesis, simulation, layout planning, place-and-route, and timing and power analysis optimization. The breakthroughs in EDA tools rely on key technological advancements in various EDA point tools, as well as the integrated design optimization of these point tools. Therefore, the chaining of EDA point tools based on a common data foundation and the integrated optimization based on the entire EDA chain have become essential paths to promote breakthroughs in EDA tools.
In view of the many challenges and opportunities facing EDA technology development, this journal has specially planned to publish the “EDA Research Column.” In this article, three pieces are planned by the column editor Cai Hao, and one by another column editor Yao Hailong, covering the latest advancements and innovative technologies in agile design, layout planning, timing analysis, power optimization, and analog simulation. This journal aims to showcase the latest research progress and academic achievements in integrated circuit EDA technology, promote academic exchanges in the EDA field, drive the development and breakthroughs of key technologies, and provide theoretical and technical support for the advancement of EDA technology in China. The following four articles were published in the first issue of “Integrated Circuits and Embedded Systems” in 2024, and the last two articles will be published in the second issue of 2024.
Shi Rui, Zuo Yunfan, Yan Hao
(School of Integrated Circuits, Southeast University, Nanjing 210096)
Abstract: In transient circuit simulation, linear system models are often established, and sequentially solving triangular matrices with multiple right-hand sides is quite time-consuming. To improve the back-substitution speed of triangular matrices in transient circuit simulation, a parallel computing method based on heterogeneous platforms is proposed to quickly solve triangular matrices. By prioritizing the multiplication related to the solution vector, the parallelism of back-substitution computation is exploited. The core design includes an operation array with multiple floating-point computing functions and a master-slave two-layer state machine control module. Compared to the Intel 24-core CPU platform using the MKL solver library, this architecture is implemented on the XCZU15EG Zynq UltraScale series FPGA for linear matrix solving experiments, where all matrices used are symmetric positive definite, diagonally dominant, and have a density greater than 50%. The proposed acceleration architecture achieves an average speedup of 22 times, with a solution error between 1E-17 and 1E-14. The experimental results indicate that this architecture improves the matrix solving speed to some extent, making it suitable for forward and backward substitution solving of high-dimensional linear matrices.
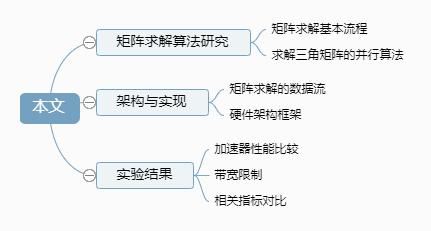
Reference format for this article: Shi Rui, Zuo Yunfan, Yan Hao. Research on Accelerated Solution of Triangular Matrix Based on Heterogeneous Platform [J]. Integrated Circuits and Embedded Systems, 2024, 24(1): 13-18.
Liu Sunchengxing, Cai Hao
(School of Integrated Circuits, Southeast University, Nanjing 211189)
Abstract: Magnetic Random Access Memory (MRAM), as a new type of non-volatile memory, has broad application prospects in embedded storage due to its excellent read/write speed and durability. However, the customized design of MRAM usually takes several months to complete, resulting in a long design cycle, which contradicts the fast design iteration requirements of system-on-chip (SoC). Memory compilers, as tools for quickly generating memory designs, are effective means to solve this contradiction. This paper starts from the fully customized design process of MRAM and surveys the current research status of various memory compilers, summarizing the current state and challenges of memory compiler work, and finally discusses the design methodology of MRAM compilers.
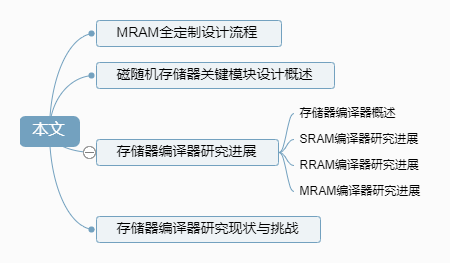
Reference format for this article: Liu Sunchengxing, Cai Hao. Research on Agile Generation Technology Based on Memory Compiler [J]. Integrated Circuits and Embedded Systems, 2024, 24(1): 19-24.
Zhang Zhanhua, Wang Jiahao, Ding Wenjie, Cao Peng
(National ASIC Engineering Center, Southeast University, Nanjing 210096)
Abstract: As advanced processes evolve, leakage power has gradually become one of the important factors restricting the reduction of total power consumption in integrated circuits. Among the existing leakage power optimization methods, the method based on threshold voltage distribution has an exponential relationship for power optimization and does not affect the already completed place-and-route, hence it is widely adopted. However, in commercial sign-off tools, the global search performed by the underlying algorithms is limited to maintain pseudo-linear complexity, making it difficult to obtain optimal results. This paper proposes a joint optimization framework RL-LPO based on graph neural networks and reinforcement learning to achieve efficient threshold voltage distribution of gate units. In RL-LPO, the GraphSAGE algorithm encodes the timing and physical information of the circuit to aggregate the target unit and its local neighborhood information; the Deep Deterministic Policy Gradient (DDPG) reinforcement learning algorithm allocates threshold voltage considering leakage power and timing changes under the guidance of the reward function. The proposed threshold voltage distribution framework RL-LPO was validated under the 28 nm process using IWLS2005 and Opencores benchmark circuits, achieving at least a 2.1% reduction in additional leakage power without introducing timing violations compared to commercial sign-off tools, and realizing at least a 4.2-fold acceleration.
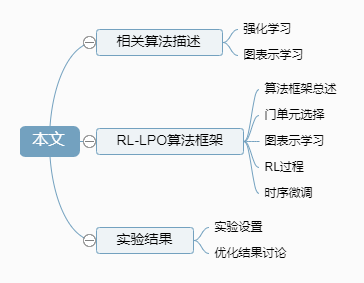
Reference format for this article: Zhang Zhanhua, Wang Jiahao, Ding Wenjie, et al. Research on Threshold Voltage Distribution Leakage Power Optimization Method Based on Reinforcement Learning [J]. Integrated Circuits and Embedded Systems, 2024, 24(2): 57-63.
Ni Wenwei, Zuo Yunfan, Yan Hao
(School of Integrated Circuits, Southeast University, Nanjing 210096)
Abstract: Sparse matrix solving is an important part of SPICE simulation, and the operators currently used for solving are usually general floating-point computing units, which limits the computation speed. This paper improves the addition/subtraction and multiplication units in general floating-point operators to achieve faster solving speed under the specific context of SPICE simulation. The traditional addition/subtraction units utilize rounding parallel delay optimization algorithms and dual-path design schemes, optimizing the critical path delay of the circuit using Shannon expansion, imprecise leading-zero compensation, and other methods. The traditional multiplication units improve the relevant delay by changing the traditional compressed topology layer structure and optimizing the rounding carry in the injection value algorithm. Finally, under the TSMC 28 nm process, the double-precision floating-point solving speeds are 0.46 ns and 0.79 ns respectively, reducing the delays of Synopsys’ DW library units by 33.4% and 7.1%, and the areas by 4.62% and 1.6%. The experimental results show that the improved floating-point units can effectively reduce the time of a single matrix solving step, thereby accelerating the overall speed of transient simulation to some extent.
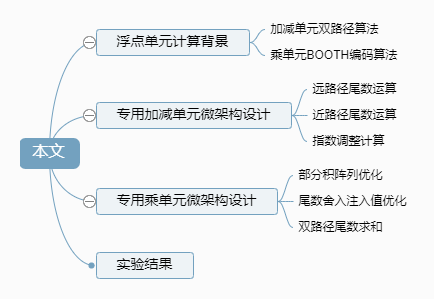
Reference format for this article: Ni Wenwei, Zuo Yunfan, Yan Hao. Research on Dedicated Floating Point Computing Unit for SPICE Simulation [J]. Integrated Circuits and Embedded Systems, 2024, 24(2): 64-69.

Cai Hao: Associate Professor at the School of Integrated Circuits, Southeast University, PhD supervisor, engaged in spin magnetic random access memory (MRAM) chip design, focusing on three research areas: the compact modeling of magnetic tunnel junction devices, device-circuit co-design methodology, and chip design for new computing paradigms and hybrid storage. He has published over 30 high-level papers in journals such as ISSCC, IEDM, JSSC, and IEEE Transactions. The MRAM-MTJ open-source model has been downloaded and referenced by over 60 research institutions in more than 20 countries. He has presided over two projects of the National Natural Science Foundation and one project of the National Key R&D Program. He serves as a member of the Technical Program Committee (TPC) of the IEEE Circuits and Systems Society and has been a TPC member for over 10 international conferences such as DAC.

Welcome to submit articles on our official website (www.jices.cn)