The dream of creating machines that imitate human intelligence has existed for a long time. Although it mostly appeared in science fiction, in recent decades, we have gradually made progress in building intelligent machines that can perform certain tasks like humans. This field is known as artificial intelligence. The origins of artificial intelligence can perhaps be traced back to Pamela McCorduck’s work, “Machines Who Think,” where she describes artificial intelligence as an ancient desire to replicate divine beings.
Deep learning is a branch of artificial intelligence that aims to bring machine learning closer to its original goal: artificial intelligence. The approach taken by deep learning mimics the activity of neuron layers in the neocortex. The neocortex occupies 80% of the brain’s folds and is responsible for generating thought. The human brain contains about 100 billion neurons and 100 to 1,000 trillion synapses. For different types of data, such as images, videos, sounds, and text, deep learning understands data patterns by learning hierarchies, representation levels, and abstraction levels.
High-level abstraction can be defined as a combination of low-level abstractions. The former is called deep because it involves multiple nonlinear feature transformation states. One of the advantages of deep learning is its ability to automatically learn feature representations at multiple levels of abstraction. This allows the system to learn complex function mappings from input space to output space without relying on manual feature extraction. Additionally, deep learning offers a pre-training mechanism, where representations learned on one dataset can be applied to other datasets. Of course, the pre-training mechanism may have some limitations, such as the need for the learning data to be of sufficiently good quality. Moreover, deep learning can also perform well when learning greedily based on a large amount of unsupervised data.
Figure 1-1 shows a simplified convolutional neural network (CNN).
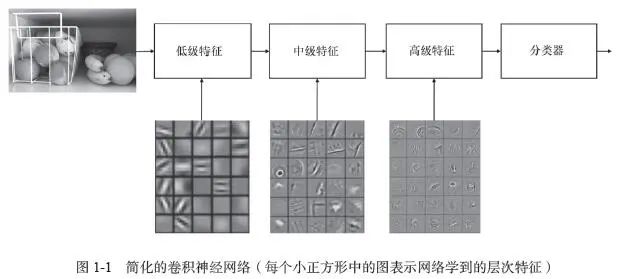
A deep learning model, which is a trained deep neural network, typically consists of multiple network layers. These network layers collaborate hierarchically to build an improved feature space. The first layer learns low-level features, such as color and edges. The second layer learns high-level features, such as corners. The third layer learns small patches or texture features. Network layers usually learn in an unsupervised manner to discover general features of the input space. Then, the features from the last layer of the network can be fed into a supervised layer to complete classification or regression tasks.
Between network layers, nodes are connected by weighted edges. Each node is associated with an activation function, which can be viewed as a simulation of the neocortex. The inputs to each node come from its lower-layer nodes. However, constructing such a large, multilayered array of neuronal information flow was an idea from a decade ago. From the inception of the idea to recent successes, the development of deep networks has experienced a roller coaster of ups and downs.
With improvements in mathematical formulas, the increasing power of computers, and the creation of large-scale datasets, the spring of deep learning has arrived. Currently, deep learning has become a major pillar in today’s technology world and has been widely applied in multiple fields. In the next section, we will trace the history of deep learning and discuss its incredible journey of ups and downs.