This article belongs to the collection: Interviewing the Interviewer Series
For more interview questions, feel free to add the assistant’s WeChat at the end of the article!
This article overview includes:
-
What are the main differences between HTTP/1.1 and HTTP/1.0?
-
Can you elaborate on how HTTP long connections are implemented, their advantages, and disadvantages?
-
Can you explain HTTP pipelining and head-of-line blocking? What methods can completely solve the head-of-line blocking issue?
-
What improvements does HTTP/2 have over HTTP/1.1?
-
What limitations does HTTP/2 have? How does HTTP/3 based on QUIC improve connection efficiency?
Interviewer: What are the main differences between HTTP/1.1 and HTTP/1.0?
1. Connection Management: Long Connections and Pipelining
- HTTP/1.0 defaults to using short connections, requiring a new TCP connection for each request, which is closed immediately after the request is completed. To enable long connections, the header
<span>Connection: Keep-Alive</span>must be explicitly set, but compatibility is poor (some proxies do not support it). - HTTP/1.1 defaults to enabling long connections (persistent connections), allowing multiple requests/responses to be transmitted over a single TCP connection, reducing handshake overhead. It supports pipelining technology, allowing clients to send multiple requests consecutively (without waiting for responses), but the server must return responses in the order of requests to avoid head-of-line blocking.
2. Host Header Supports Virtual Hosting
- HTTP/1.0 assumes one IP corresponds to one server, and the request header does not contain a Host field, making it impossible to support virtual hosting (e.g., multiple domain names sharing the same IP).
- HTTP/1.1 mandates that the request header includes the
<span>Host</span>field to identify the target server’s domain name. If missing, the server returns<span>400 Bad Request</span>, solving the resource location issue in virtual host scenarios.
3. Enhanced Caching Mechanism
- HTTP/1.0 relies on
<span>Expires</span>(absolute time) and<span>Last-Modified</span>(last modified time) to control caching, which has clock synchronization issues. Cache validation is achieved through<span>If-Modified-Since</span>. - HTTP/1.1
- Introduces the
<span>Cache-Control</span>header (e.g.,<span>max-age</span>,<span>no-cache</span>), supporting relative time caching strategies. - Adds the
<span>ETag</span>(entity tag) mechanism to verify resource changes through<span>If-None-Match</span>. - Supports the
<span>Vary</span>header to differentiate different cache versions based on request headers (e.g.,<span>Accept-Language</span>).
4. Bandwidth Optimization and Chunked Transfer
- Range Requests HTTP/1.1 supports the
<span>Range</span>header, allowing requests for partial content (e.g., resuming downloads), with a response status code of<span>206 Partial Content</span>. - Chunked Transfer Encoding allows dynamic content to be transmitted in chunks via
<span>Transfer-Encoding: chunked</span>, eliminating the need to know the full data size in advance, thus improving transfer efficiency. - 100 Continue Status Code Before sending large requests, the client first queries the server with the
<span>Expect: 100-continue</span>header to check if the server will accept it, avoiding bandwidth waste.
5. Error Status Codes and Content Negotiation
- Error Status Codes HTTP/1.1 introduces 24 new status codes, such as:
<span>100 Continue</span>(continue request)<span>206 Partial Content</span>(partial content)<span>409 Conflict</span>(resource state conflict)<span>410 Gone</span>(resource permanently deleted).- Content Negotiation is supported through the
<span>Accept-*</span>series of headers (e.g.,<span>Accept-Language</span>,<span>Accept-Encoding</span>), allowing the server to return the most suitable version and record the negotiation basis through the<span>Vary</span>header.
6. Other Improvements
- Request Method Extensions HTTP/1.1 introduces new methods such as
<span>OPTIONS</span>,<span>PUT</span>,<span>DELETE</span>, and<span>TRACE</span>, supporting RESTful API design. - Message Passing Optimization supports the
<span>Trailer</span>header to pass metadata (e.g., checksums) after chunked transfer, enhancing the integrity of large file transfers.
Summary Comparison Table
| Feature | HTTP/1.0 | HTTP/1.1 |
|---|---|---|
| Connection Management | Short connection, long connection must be manually enabled | Default long connection, supports pipelining |
| Host Header | Not supported | Mandatory, supports virtual hosting |
| Caching Mechanism | Only Expires/Last-Modified | Cache-Control/ETag/Vary |
| Bandwidth Optimization | Does not support range requests | Supports Range requests and chunked transfer |
| Status Codes | 16 basic status codes | 24 new ones, such as 100, 206, 409, etc. |
| Content Negotiation | Limited support | Flexible adaptation through Accept headers and Vary |
Interviewer: Good, can you elaborate on how HTTP long connections are implemented, their advantages, and disadvantages?Reference Article:https://blog.csdn.net/qq_34556414/article/details/125843504
Detailed Analysis of HTTP Persistent Connections (Long Connections)
1. Principle
HTTP Persistent Connection (also known as Keep-Alive) allows clients and servers to send and receive multiple HTTP requests/responses over a single TCP connection without needing to establish a new connection for each request.
1. Workflow
- HTTP/1.0 defaults to short connections, requiring a new TCP connection for each request, which is closed immediately after the response. To enable long connections, the header must be explicitly set:
<span>Connection: keep-alive</span>. - HTTP/1.1 defaults to enabling long connections unless explicitly set to
<span>Connection: close</span>. Clients and servers can reuse the same TCP connection to handle multiple requests.
2. Connection Management
- Keep-Alive Mechanism negotiates parameters (e.g., timeout, maximum request count) through the
<span>Keep-Alive</span>header field. Example:<span>Keep-Alive: timeout=5, max=100</span>(closes the connection after 5 seconds of inactivity, handling a maximum of 100 requests). - Closure Conditions
- Client/server sends the `Connection: close` header.
- Reaches keep-alive parameter limits (e.g., timeout or maximum request count).
2. Advantages
1. Reduces TCP Handshake Overhead
- Each TCP connection requires three-way handshake to establish and four-way handshake to close.
- Reusing connections avoids repeated handshakes, reducing latency (especially significant in high-latency networks).
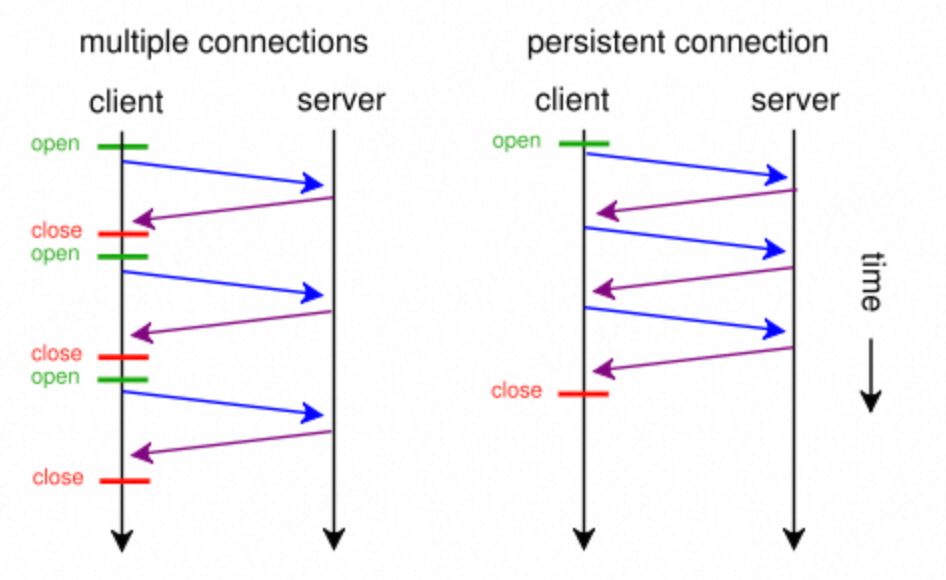 2. Improves Resource Loading Efficiency
2. Improves Resource Loading Efficiency
- Web pages typically need to load multiple resources (HTML, CSS, JS, images, etc.).
- Long connections allow parallel or serial reuse of the same connection, reducing total loading time.
3. Reduces Server Load
- Reduces system calls and memory consumption from frequently creating/destroying connections.
4. Supports Pipelining
- HTTP/1.1 allows multiple requests to be sent without waiting for responses (theoretical optimization).
- Due to implementation complexity and head-of-line blocking issues, actual usage is limited, but it is proposed based on long connections.
3. Limitations
1. Head-of-Line Blocking
- HTTP/1.1’s serial requests must be processed in order within the same connection.
- If the previous request is slow (e.g., large file upload), subsequent requests are blocked.
- HTTP/2’s Solution introduces multiplexing, allowing parallel processing of requests.
2. Resource Occupation Issues
- Long connections occupy TCP ports and memory resources on both the server and client.
- In high-concurrency scenarios, this may lead to the server reaching its connection limit (e.g., Linux default
<span>ulimit -n</span>is 1024).
3. Idle Connection Waste
- If a connection is idle for a long time, it still occupies resources until it times out and closes.
- It is necessary to configure timeout settings reasonably (e.g., Nginx default
<span>keepalive_timeout 75s</span>).
4. Comparison of Different HTTP Versions
| Feature | HTTP/1.0 | HTTP/1.1 | HTTP/2 |
|---|---|---|---|
| Default Connection | Short connection | Long connection | Long connection + Multiplexing |
| Pipelining Support | Not supported | Supported (but practically limited) | Supported (parallel and non-blocking) |
| Header Compression | None | None | HPACK Compression |
| Resource Priority | None | None | Supports priority streams |
Summary
- Core Value HTTP persistent connections significantly reduce latency and server overhead by reusing TCP connections, serving as the cornerstone of web performance optimization.
- Applicable Scenarios Resource-intensive pages, high-frequency API calls, high-concurrency services.
- Trade-offs A balance must be struck between connection reuse efficiency and resource occupation, combined with further optimizations using HTTP/2 or HTTP/3.
Interviewer: You just mentioned HTTP pipelining and head-of-line blocking. Can you explain what they are and what methods can completely solve the head-of-line blocking issue?Reference Link:https://www.jianshu.com/p/51b2a9c98fca
HTTP pipelining is an optimization technique introduced in HTTP/1.1 that allows clients to send multiple requests consecutively over the same TCP connection without waiting for the previous request’s response to return.
Principle of Pipelining
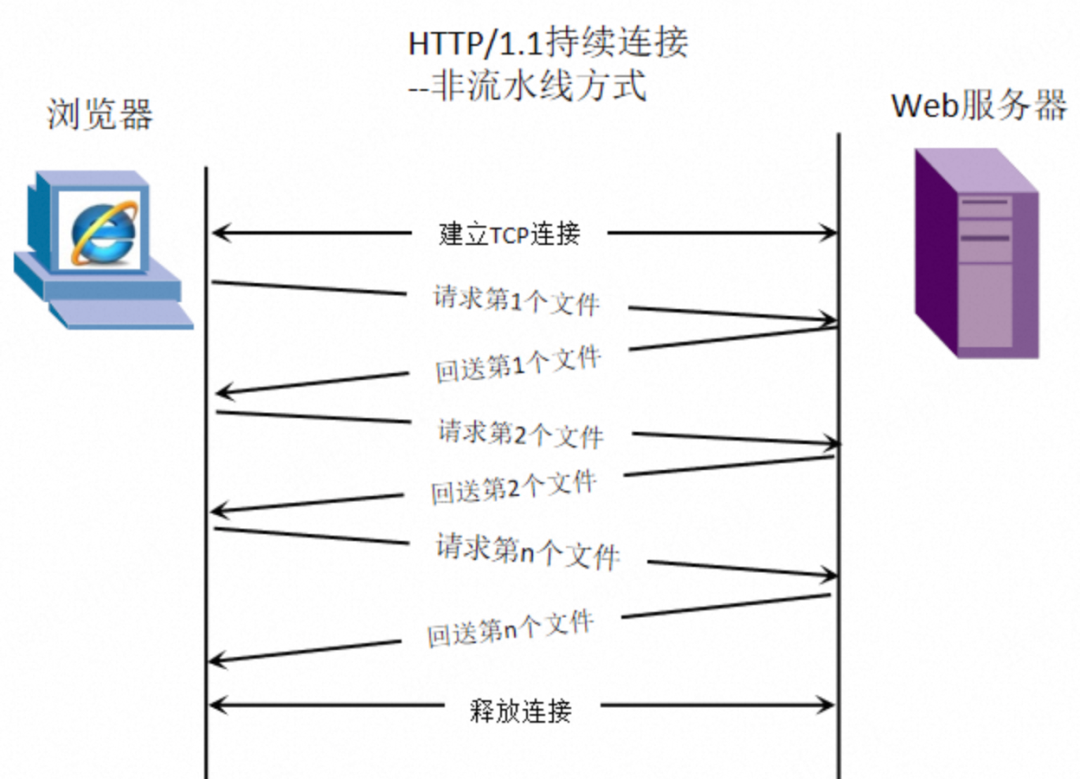
1. Comparison with Non-Pipelining
- Non-Pipelining Method (e.g., HTTP/1.0): Clients must wait for the complete response of the previous request before sending the next request. For example, request A must complete before request B can be sent, leading to cumulative delays.
- Pipelining Method (HTTP/1.1): Clients can send multiple requests consecutively without waiting for responses, and the server processes and returns responses in the order they were received. For example, clients can send requests A, B, and C at once, and the server returns responses A, B, and C in order.
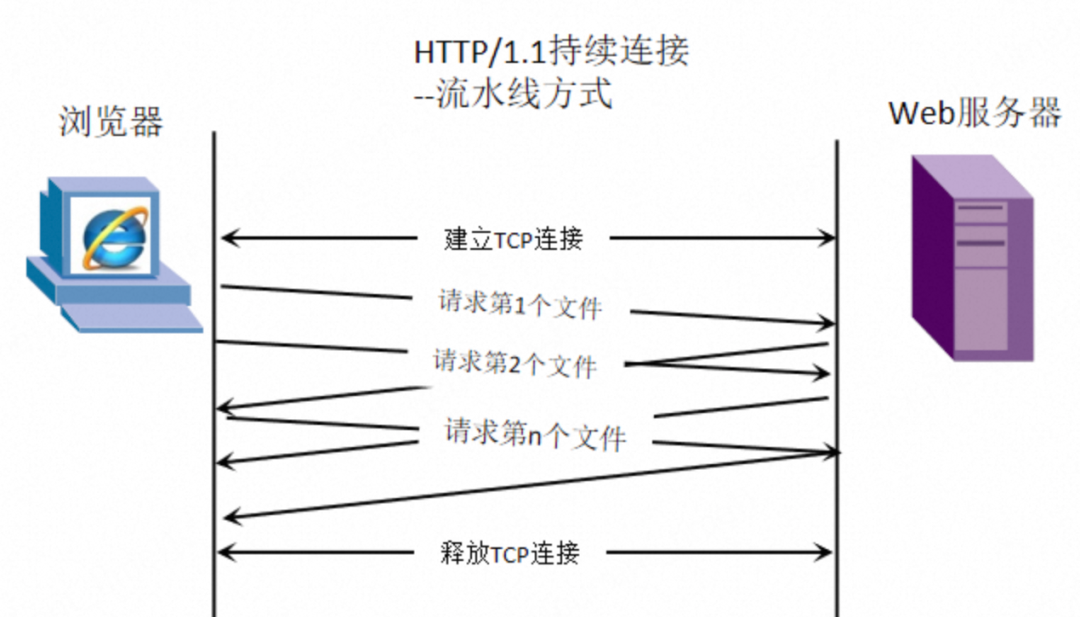 2. Implementation Conditions
2. Implementation Conditions
- Depends on Persistent Connection, which keeps the TCP connection alive through
<span>Connection: keep-alive</span>. - The server must support responding in the order of requests, and the client must be able to handle responses arriving out of order (which is rare in practice, as most implementations still return in order).
HTTP/1.1 request messages do not record the order of requests (e.g., request numbers, sequence numbers), so there is no guarantee that the return order of multiple responses corresponds to the order of multiple requests sent. In other words, if requests 1, 2, and 3 are sent in that order, but the server responds with 3, 2, and 1 due to response speed, HTTP/1.1 still waits for the response of request 1 to be ready before returning responses in the order of 1, 2, and 3. Otherwise, out-of-order responses may be delivered to the wrong requests (e.g., delivering response 3 to request 1).
In this process, responses 3 and 2 are blocked by response 1, which is known as head-of-line blocking. HTTP’s head-of-line blocking refers to the issue where the delay or loss of a request or data packet during transmission causes subsequent requests/data to be blocked.
Although theoretically, HTTP/1.1 pipelining supports concurrent transmission of multiple requests and responses over one connection, due to the unresolved head-of-line blocking issue, HTTP/1.1 will not enable pipelining in practice; it still requires one connection to serially transmit requests and responses, and if concurrent requests are needed, multiple connections must be established for limited concurrency.
The head-of-line blocking issue manifests differently at various protocol layers (e.g., HTTP/1.1, TCP), detailed as follows.
Head-of-Line Blocking in HTTP/1.1
Even with pipelining enabled, HTTP/1.1 requires the server to return responses in the order of requests. If the first request’s response is delayed due to slow server processing, subsequent requests, even if processed, must wait for the first response to return before the client can handle them.
- Example Requests A, B, and C are sent in order; if A’s response is delayed by 1 second, responses B and C, even if generated, must wait until A’s response returns before being processed by the client.
Impact
- Page Load Delay Resources (e.g., images, CSS) must queue, slowing overall loading speed.
- Low Resource Utilization TCP connections cannot be fully utilized by other requests, wasting bandwidth.
HTTP/2’s multiplexing mechanism can solve application-layer head-of-line blocking issues. To explain how HTTP/2 resolves application-layer head-of-line blocking, it is necessary to introduce the concepts of streams, messages, and frames, and their relationships.In HTTP/2, a stream represents an independent request-response interaction, which can contain multiple messages, and each message consists of multiple frames. Streams have unique identifiers, allowing multiple streams’ frames to be transmitted in parallel over the same connection, thus achieving multiplexing.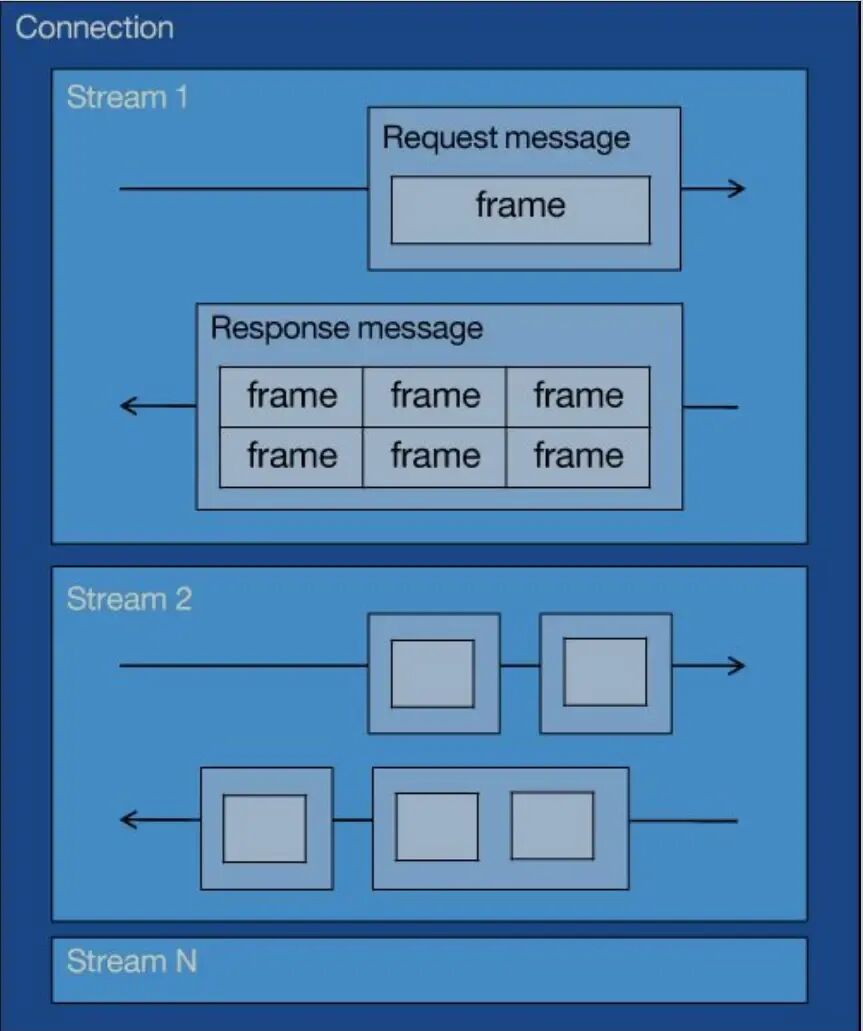
From the above image:
1 TCP connection contains one or more streams;
A stream can contain one or more messages, with each message consisting of HTTP headers and body;
A message contains one or more frames, which are the smallest transmission unit of HTTP/2, stored in a binary compressed format.
A message consists of headers frames and data frames.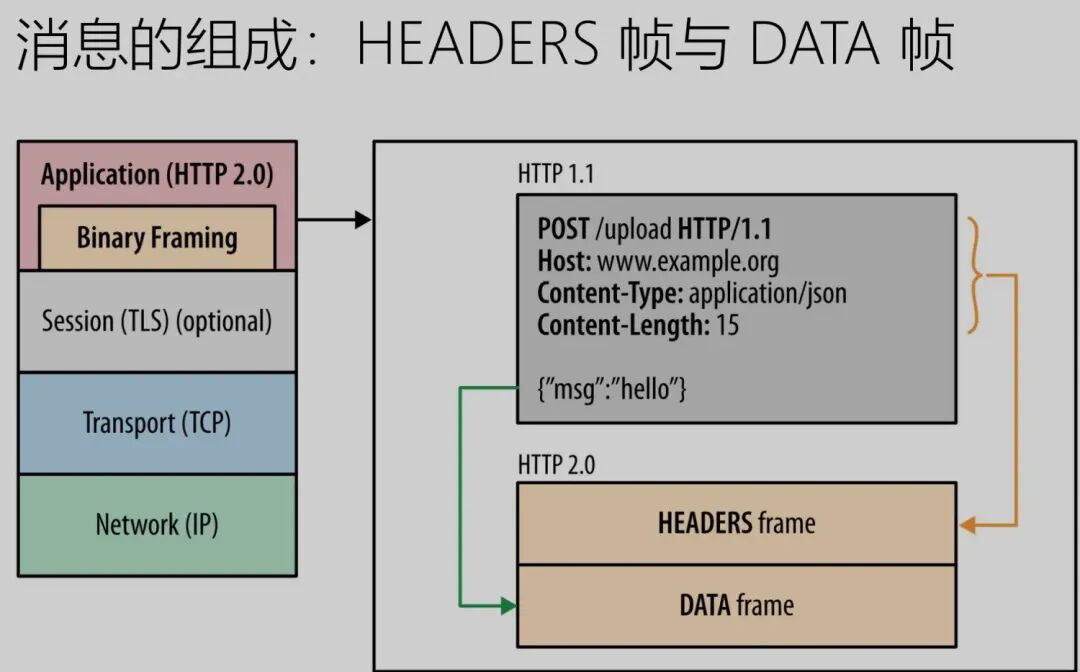
In an HTTP/2 connection, frames from different streams can be sent out of order (thus allowing concurrent streams), as each frame’s header carries stream ID information, allowing the receiving end to assemble HTTP messages in order based on stream ID. However, frames and messages within the same stream must be strictly ordered.
For example, in the image below, the server sends two responses in parallel: the response message for stream 1 and the response message for stream 3, both running on the same TCP connection. When the client receives them, it can accurately assemble the responses for streams 1 and 3 based on the unique stream identifiers and deliver them to the corresponding requests, thus solving the head-of-line blocking issue and improving concurrency.
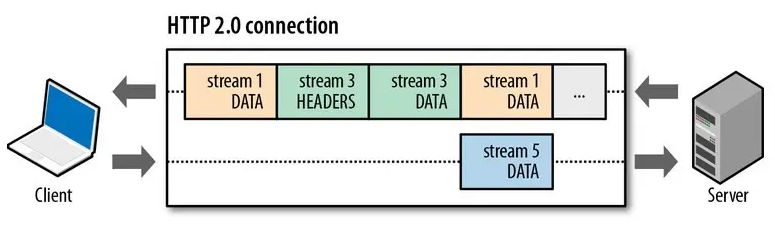
Thus, if the request message for stream 1 reaches the server before the request message for stream 3, and the response message for stream 3 is ready first, it can be sent without waiting for the response message for stream 1 to be ready. The client can accurately assemble the response messages for streams 1 and 3 based on the unique stream identifiers and deliver them to the corresponding requests, thus solving the head-of-line blocking issue and improving concurrency.Interviewer: Can you explain what improvements HTTP/2 has over HTTP/1.1?Reference Link:https://www.cnblogs.com/liujiaqi1101/p/17203703.htmlHTTP/2 significantly improves performance over HTTP/1.1 through various technical enhancements, with the main optimization points as follows:
Multiplexing
HTTP/2’s multiplexing is one of its core features, allowing multiple requests and responses to be transmitted in parallel over a single TCP connection, completely solving the head-of-line blocking issue of HTTP/1.1. The following is a detailed analysis of its principles and performance improvements:1. Streams and Frames
- Stream is a logical channel in an HTTP/2 connection, where each stream independently transmits a sequence of frames (requests or responses) in both directions.
- Frame is the smallest unit of data transmission, containing a stream identifier (Stream ID) and type (e.g., HEADERS, DATA).
- Implementation allows frames from multiple streams to be interleaved, enabling clients and servers to reassemble data by stream ID without waiting in order.
2. Comparison with HTTP/1.1
- HTTP/1.1 requires strict serialization of requests/responses, where a delay in one request causes subsequent requests to block (head-of-line blocking).
- HTTP/2 allows multiple requests to be processed in parallel on the same TCP connection, with streams being independent and not interfering with each other.
HTTP/2’s multiplexing brings the following improvements.1. Eliminates Head-of-Line Blocking
- Problem Scenario In HTTP/1.1, if the response for request A is delayed, subsequent requests B and C must queue.
- Solution HTTP/2’s multiplexing allows frames for requests B and C to be interleaved with frames for request A, so even if A is delayed, responses for B and C can still be prioritized.
2. Reduces TCP Connection Count
- HTTP/1.1 browsers typically establish 6-8 TCP connections per domain to request resources in parallel.
- HTTP/2 only requires one connection to transmit all requests in parallel, reducing the overhead of establishing and maintaining connections (e.g., three-way handshake, TLS handshake).
3. Improves Transmission Efficiency
- Resource Utilization The bandwidth of TCP connections is shared among multiple streams, avoiding a single request from occupying all resources within a TCP connection.
- Latency Optimization In weak network environments, multiplexing can reduce page loading times by 30%-50%. For example, when requesting a large JS file and a small CSS file, HTTP/2 can transmit them in parallel, while HTTP/1.1 must wait serially.
4. Saves Server Resources
- Reducing concurrent connection counts can lower server memory and CPU consumption, enhancing stability in high-load scenarios.
Header Compression
HTTP/2’s header compression is a core optimization technology implemented through the HPACK algorithm, aimed at reducing redundant header data and improving transmission efficiency. The following is a detailed explanation of its principles and advantages:
1. HPACK Algorithm
- Core Idea eliminates duplicate header fields through static tables, dynamic tables, and Huffman coding, reducing transmission volume.
- Implementation
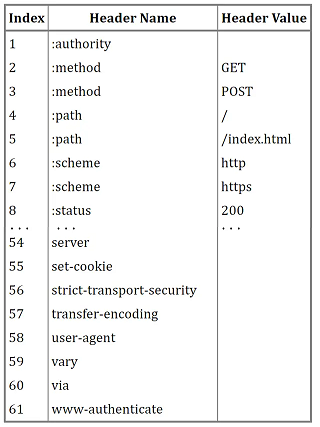
- Static Table predefines 61 common header fields (e.g., `:method`, `:path`, `content-type`), replacing full field names with index numbers. For example, `:method: GET` can be encoded as index `2`, requiring only 1 byte for transmission.
- Dynamic Table dynamically stores custom header fields exchanged between the client and server during the session, allowing subsequent requests to reference indices directly.
- For example, after initially sending `user-agent: Mozilla/5.0`, subsequent requests only need to send its dynamic table index.
- Huffman Coding compresses the keys and values of header fields at the character level, using short codes for high-frequency characters and long codes for low-frequency characters. For example, the letter `e` appears frequently and is encoded as `010`, while `z` is encoded as `111111`.
The overall effect of header compression is illustrated in the following image: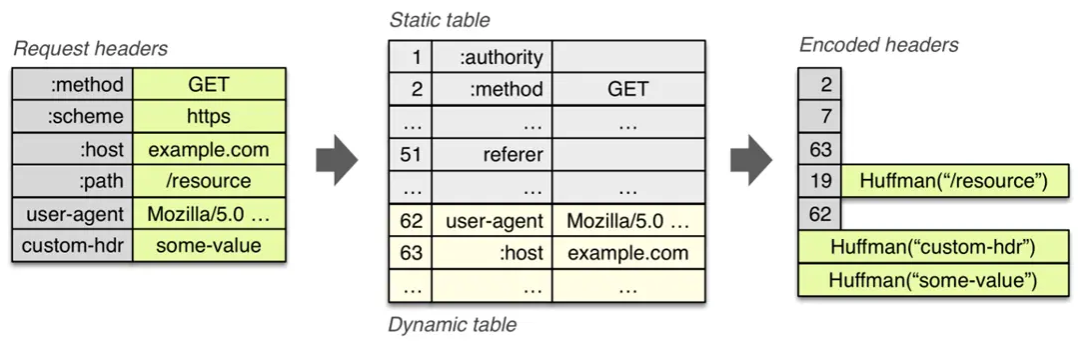 Advantages of header compression:
Advantages of header compression:
1. Significantly Reduces Bandwidth Consumption
- By eliminating redundant header fields (e.g., duplicate
<span>Cookie</span>,<span>User-Agent</span>), it lowers the amount of data transmitted, especially beneficial in mobile or low-bandwidth environments. - For example, a page with 20 requests may have a total header size of 10KB in HTTP/1.1, while HTTP/2 can compress it to below 1KB.
2. Reduces Latency and Improves Concurrency Performance
- Reduces TCP Connection Count Header compression allows a single connection to carry more requests.
- Accelerates First Screen Loading The header compression of critical resources (e.g., HTML, CSS) shortens transmission time, leading to faster page rendering.
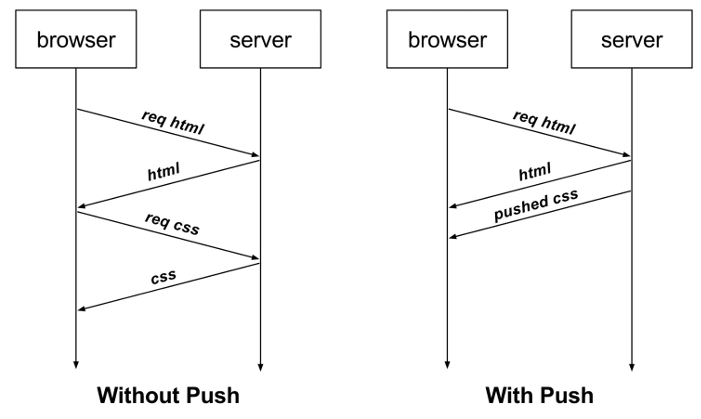
Server Push
HTTP/2’s server push is a technology that allows the server to proactively send resources to the client without waiting for explicit requests. The following are its features and advantages:
1. Proactive Push Mechanism
- When the client requests a resource (e.g., an HTML page), the server can proactively push associated resources (e.g., CSS, JS, images).
- Example If the client requests
<span>index.html</span>, the server can simultaneously push<span>style.css</span>and<span>script.js</span>, reducing the round-trip time (RTT) for subsequent requests.
 2. Resource Prediction and Priority
2. Resource Prediction and Priority
- The server can predict the resources needed by the client based on business logic (e.g., by declaring a push list through the
<span>Link</span>header). - It supports setting the priority of pushed resources to ensure that critical resources (e.g., first-screen CSS) are transmitted first.
Advantages and Limitations of Server Push1. Significantly Reduces Latency (Advantage)
- Reduces Round Trips By pushing resources in advance, the client does not need to initiate additional requests, lowering page loading times.
- Accelerates First Screen Rendering The early arrival of critical resources (e.g., CSS, JS) can complete page rendering faster.
2. Only Supports Static Resources (Limitation) Server push cannot transmit dynamically generated content (e.g., real-time data) and must be combined with WebSocket or SSE for real-time communication.
Enhanced Security Mechanisms
-
Protocol Requirements: The HTTP/2 specification (RFC 7540) recommends using it in conjunction with TLS 1.2 or higher, and must support forward secrecy and Server Name Indication (SNI).
-
TLS 1.3 Support: When HTTP/2 is combined with TLS 1.3, the handshake requires only 1 round trip time (RTT), and achieves forward secrecy through temporary keys (Ephemeral Key), ensuring that even if long-term keys are compromised, historical communications cannot be decrypted.
-
Session Resumption: Supports fast handshakes based on session IDs or tickets (Session Ticket), reducing the encryption overhead of repeated connections.
-
Binary Framing: HTTP/2 uses a binary format instead of plaintext transmission, reducing the risk of injection attacks or tampering caused by intermediate devices (e.g., proxies, firewalls) due to parsing text protocols.
-
Header Compression Security: The HPACK algorithm compresses headers through dynamic tables and Huffman coding, preventing plaintext header fields from being stolen or tampered with.
Interviewer: What limitations does HTTP/2 have? How does HTTP/3 based on QUIC improve connection efficiency?Reference Link:https://www.cnblogs.com/liujiaqi1101/p/17203703.html
Defects of HTTP/2
1. Head-of-Line Blocking at the TCP Layer
HTTP/2 solves the head-of-line blocking issue of HTTP/1 through the concurrency of streams, which seems perfect. However, HTTP/2 still has a “head-of-line blocking” problem, but the issue is not at the HTTP layer, but at the TCP layer.
HTTP/2 is based on the TCP protocol for data transmission. TCP is a byte stream protocol, and the TCP layer must ensure that the received byte data is complete and continuous. Only then will the kernel return the data in the buffer to the HTTP application. Therefore, when the “first byte of data” has not arrived, the subsequent received byte data can only be stored in the kernel buffer, and only when this first byte of data arrives can the HTTP/2 application read the data from the kernel. This is the head-of-line blocking problem in HTTP/2.
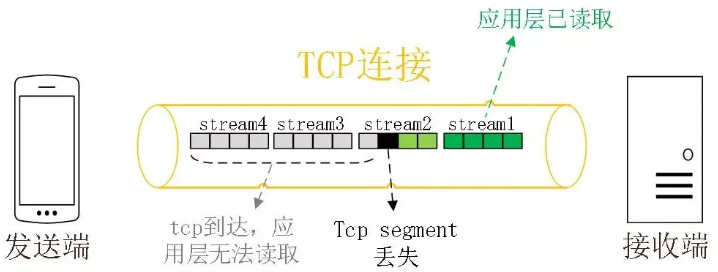
Because TCP is a byte stream protocol, it must ensure that the received byte data is complete and ordered. If a TCP segment with a lower sequence number is lost during network transmission, even if TCP segments with higher sequence numbers have been received, the application layer cannot read this data from the kernel. From the HTTP perspective, this means that the request is blocked.
For example, in the image below:
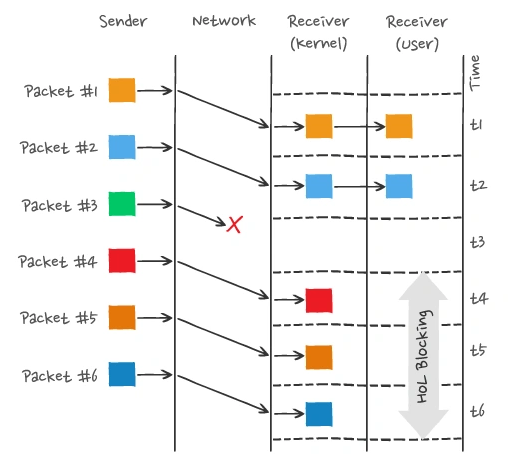
The image shows that the sender has sent many packets, each with its own sequence number, which can be considered as TCP sequence numbers. If Packet 3 is lost in the network, even if Packets 4-6 are received by the receiver, the application layer cannot read the data from the kernel because the TCP data is not continuous. The application layer can only read the data from the kernel after Packet 3 is retransmitted. This is the head-of-line blocking problem in HTTP/2, occurring at the TCP layer.
Therefore, once a packet loss occurs, it triggers TCP’s retransmission mechanism, causing all HTTP requests in a TCP connection to wait for the lost packet to be retransmitted.
2. TCP and TLS Handshake Delays
When initiating an HTTP request, it must go through the TCP three-way handshake and the TLS four-way handshake (for TLS 1.2), resulting in a total delay of 3 RTTs before the request data can be sent.
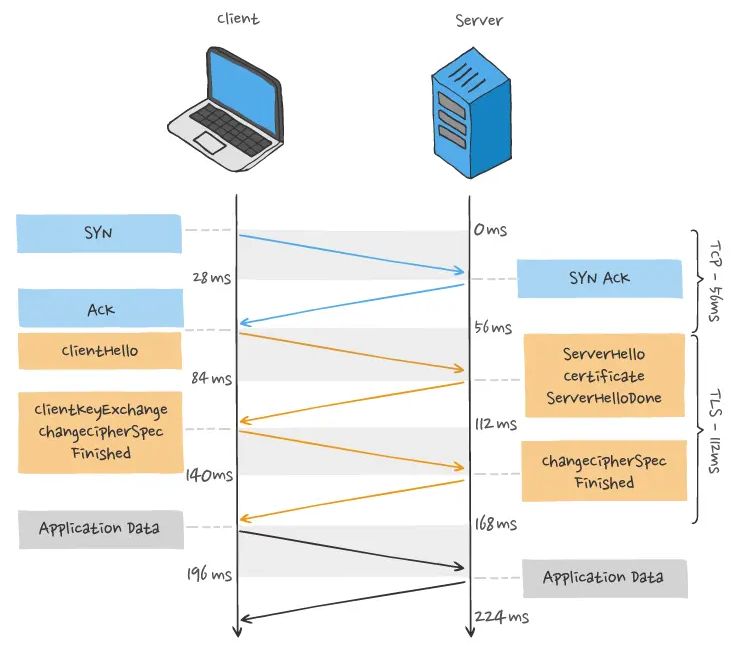
Additionally, due to TCP’s “congestion control” feature, newly established TCP connections undergo a “slow start” process, which has a “slowing down” effect on TCP connections.
3. Network Migration Requires Reconnection
A TCP connection is determined by a four-tuple (source IP address, source port, destination IP address, destination port). This means that if the IP address or port changes, TCP and TLS must re-handshake, which is not conducive to scenarios where mobile devices switch networks, such as from 4G to WiFi.
These issues are inherent to the TCP protocol, and no matter how the application-layer HTTP/2 is designed, they cannot be avoided.
HTTP/3 replaces the transport layer protocol with UDP, optimizing from the transport layer.
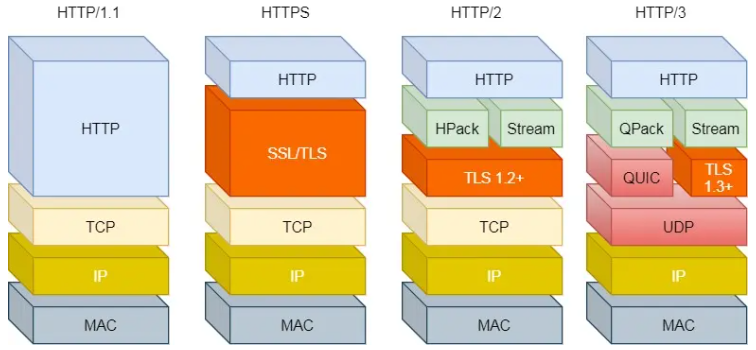
Optimizations of HTTP/3
1. No Head-of-Line Blocking
The QUIC protocol has a concept similar to HTTP/2 streams and multiplexing, allowing multiple streams to be transmitted concurrently over the same connection. A stream can be considered as one HTTP request.
Since QUIC uses the UDP transport protocol, it does not care about the order of packets. If a packet is lost, QUIC also does not care.
However, the QUIC protocol ensures the reliability of packets, with each packet having a unique sequence number. When a packet is lost in a stream, even if other packets in that stream arrive, the data cannot be read by HTTP/3 until QUIC retransmits the lost packet. However, data from other streams can be read by HTTP/3 as long as they are completely received. It can be said that HTTP/3 transfers the concept of multiple streams from the application layer to the transport layer, solving the head-of-line blocking problem at the transport layer.
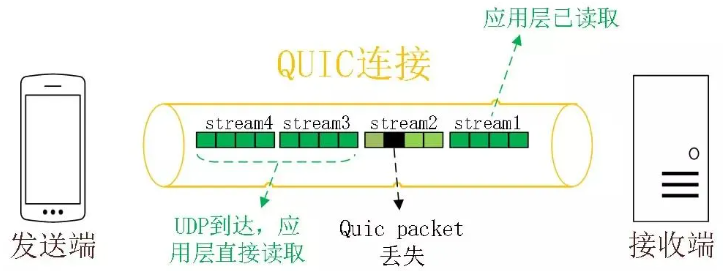
2. Faster Connection Establishment
For HTTP/1 and HTTP/2 protocols, TCP and TLS are layered, belonging to the transport layer implemented in the kernel and the presentation layer implemented in the OpenSSL library, respectively. Therefore, they are difficult to merge, requiring batch handshakes: first TCP handshake, then TLS handshake.
In HTTP/3, although the QUIC protocol handshake is required before transmitting data, this handshake process only requires 1 RTT. The purpose of the handshake is to confirm the “connection ID” of both parties, and connection migration is based on the connection ID.
However, the QUIC protocol does not layer with TLS; instead, QUIC contains TLS within itself, carrying TLS records in its own frames. Additionally, QUIC uses TLS/1.3, allowing the establishment of connections and key negotiation to be completed in just 1 RTT.
Moreover, during the second connection, application data packets can be sent along with QUIC handshake information (connection information + TLS information), achieving a 0-RTT effect.
In the right part of the image below, when session recovery occurs, effective payload data is sent together with the first packet, achieving 0-RTT (as shown in the lower right corner of the image):

3. Connection Migration
In HTTP protocols based on TCP, a connection is determined by a four-tuple (source IP, source port, destination IP, destination port).
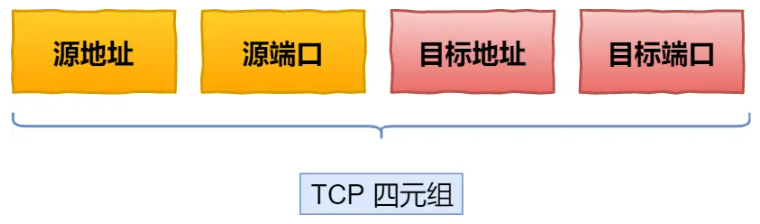
Thus, when a mobile device switches its network from 4G to WiFi, it means that the IP address changes, necessitating a disconnection and re-establishment of the connection.
The connection establishment process includes the delays of TCP three-way handshake and TLS four-way handshake, as well as the slowing effect of TCP slow start, giving users the impression of a sudden network lag. Therefore, the cost of connection migration is very high.
In contrast, the QUIC protocol does not bind connections using a four-tuple but instead uses a connection ID to mark the two endpoints of communication. Both the client and server can choose a set of IDs to mark themselves, so even if the mobile device’s network changes and the IP address changes, as long as the context information (e.g., connection ID, TLS keys, etc.) is retained, the original connection can be reused “seamlessly,” eliminating the reconnection cost and providing a smooth experience, achieving the function of connection migration.
— Previous Highlights —
Interviewing the Interviewer Series – Comprehensive Computer Networking Interview Questions (Part One)
Interviewer: What are the differences between Docker and virtual machines? How does Docker achieve data persistence? How are Docker images layered? What are the Docker network modes?
Interviewer: How is Redis distributed locking implemented, what problems exist? What is the core idea of the Redlock algorithm? How does Redis transaction work, and does it support rollback?
Interviewer: How to choose a sharding key for horizontal sharding? What is the difference between sharding and partitioning? Explain why vertical sharding is necessary from the InnoDB storage perspective.
Interviewer: Can you explain how Nginx handles requests? Why does Nginx not use a multi-threaded model? What are the load balancing algorithms in Nginx? What are forward and reverse proxies?
If this article has been helpful, please give a free “like” or “see”! Your encouragement is the motivation for continuous updates!
Welcome to join the technical exchange group, where you can regularly receive technical learning resources and the latest interview question collections!
 For business cooperation or to join the technical exchange group, please contact the assistant!
For business cooperation or to join the technical exchange group, please contact the assistant!