
Introduction: In the era of edge-cloud collaboration, how does NPU rewrite the computing power landscape?
The explosive growth of artificial intelligence is reshaping the semiconductor industry, with computing power demand rapidly penetrating from the cloud to the edge. According to IDC’s forecast, by 2028, global shipments of GenAI smartphones equipped with NPUs will reach 910 million units, with a compound annual growth rate of 78%; the NPU penetration rate in AI PCs will exceed 94%, becoming the core carrier of personal computing power.
As a dedicated chip optimized for neural networks, the NPU has three major advantages: high energy efficiency, low latency, and customized computing architecture, sparking a revolution in edge computing power in fields such as smartphones, autonomous driving, and industrial robots. This article will dissect how NPUs move from the edge to the core stage of AI computing from the perspectives of technical differences, application scenarios, and industrial ecology.
The content of this article is for reference only, and industry experts are welcome to discuss together~
01
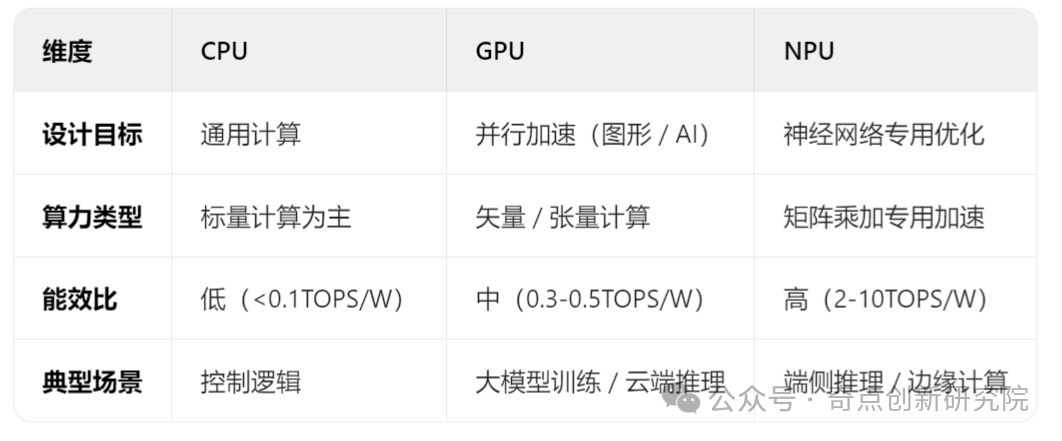
NPU vs GPU vs CPU: The Division of Labor and Competition in the AI Computing Triangle In the AI computing system, CPU, GPU, and NPU form a layered collaborative structure of “general computing – parallel acceleration – dedicated optimization” due to different architectural designs.
01. CPU: The “Brain” of General Computing, the Cornerstone of the AI Enlightenment Era
- Technical Characteristics:
Based on the von Neumann architecture, it excels in logic control and single-thread processing, supporting complex instruction sets (such as x86, ARM).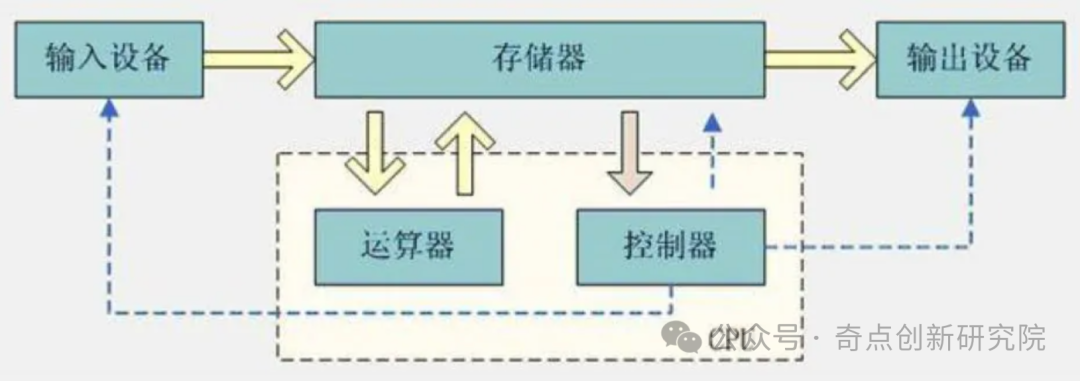 It has low parallelism (typical CPUs have only 8-16 cores), making it inefficient in processing matrix operations and other AI tasks—training ResNet-50 takes 3 days and consumes over 200W.
It has low parallelism (typical CPUs have only 8-16 cores), making it inefficient in processing matrix operations and other AI tasks—training ResNet-50 takes 3 days and consumes over 200W.
- Limitations in AI Applications:
Due to the parallel processing capabilities of GPUs, all AI computation needs to be processed in parallel. It can only support small-scale models (such as logistic regression, shallow neural networks) or serve as the control center of AI systems. Representative scenarios: traditional machine learning data preprocessing and model training process scheduling.02. GPU: The “Super Factory” of Parallel Computing, the Core Engine of Cloud AI
- Technical Breakthroughs:
Thousands of CUDA cores (e.g., NVIDIA H100 contains 18,432 FP16 cores) support large-scale matrix operations, achieving a computing power of 3 PetaFLOPS (FP16). By building a software barrier through the CUDA ecosystem, it supports mainstream frameworks such as PyTorch/TensorFlow, monopolizing over 90% of the large model training market.
- Pain Points and Bottlenecks:
The “memory wall” problem: the growth of computing power far exceeds memory bandwidth (from 2010 to 2023, computing power increased by 55% annually, while DRAM bandwidth only increased by 9.3%), resulting in an actual GPU computing power utilization rate of less than 40%. High power consumption: single card power consumption reaches 700W (H100), which edge devices cannot bear; training a model with hundreds of billions of parameters requires thousands of cards in a cluster, costing over ten million yuan.
- Core Scenarios:
Large model training, scientific computing, high-end graphics rendering.03. NPU: The “Customized Engine” for Neural Networks, the Optimal Solution for Edge AI
- Architectural Advantages:
Dedicated computing units: integrate a large number of multiply-accumulate (MAC) arrays, such as the 128×128 MAC array of Huawei Ascend 910B, capable of completing 16,384 multiply-accumulate operations in a single cycle. Storage-computation optimization: on-chip cache (e.g., Cambricon MLU370-X8 with 32MB SRAM) reduces data movement, achieving an energy efficiency ratio over 10 times that of GPUs (Ascend 310: 16TOPS@8W, TOPS/W=2; NVIDIA A100: 156TOPS@400W, TOPS/W=0.39). Low precision support: natively supports INT8/FP16 mixed precision operations, with less than 0.1% accuracy loss in image recognition tasks, but a 5-fold increase in computing power. NPU Neural Processing Unit
NPU Neural Processing Unit
- Irreplaceability:
Real-time performance on the edge: the NPU in smartphones processes voice wake-up with a delay of less than 50ms, far lower than the CPU’s 400ms. Edge deployment: the NPU in drones processes 8K video streams in real-time at an altitude of 200m, consuming only 15W (the GPU solution requires over 50W).
Summary of the Three
 02NPU Architecture “A Hundred Flowers Bloom”: Performance Differences from Hardware Design Perspective The core competitiveness of NPUs stems from architectural innovation, with different technical routes focusing on computing power, energy efficiency, and flexibility.01. NPU Mainstream Architecture Classification and Representative Products
02NPU Architecture “A Hundred Flowers Bloom”: Performance Differences from Hardware Design Perspective The core competitiveness of NPUs stems from architectural innovation, with different technical routes focusing on computing power, energy efficiency, and flexibility.01. NPU Mainstream Architecture Classification and Representative Products
- MAC Array Architecture: The “Generalist” with Optimal Compatibility:
Technical Principle: Organizes multiply-accumulate units (MAC) in a matrix form to accelerate general matrix multiplication (GEMM) Representative Products:
Representative Products:
- NVIDIA TensorCore (built into GPU): supports FP16/INT8 mixed precision, with a 4-fold speedup in matrix operations.
- Cambricon MLU series: MLU370-X8 adopts 7nm process, with INT8 computing power of 256TOPS, supporting dynamic sparse computing.
Advantages: Compatible with existing parallel computing frameworks, easy to migrate PyTorch models; suitable for dense matrix operations (such as Transformer layers).
Disadvantages: Insufficient support for sparse models, with hardware resource utilization peaking at only 70%.
- Pulsed Array Architecture: The “Ceiling” of Computing Power Density:
Technical Highlights: Google TPU and others use pulsed arrays to transmit data and partial sums along fixed paths in a two-dimensional PE (processing element) array, achieving highly parallelized matrix operations. The advantage of pulsed architecture lies in its extremely high computing power density and energy efficiency: TPU has thousands of multipliers forming a pipeline array, and Cloud TPU v3 is configured with two 128×128 pulsed arrays. This allows for continuous pipeline output during convolution and matrix multiplication, achieving high throughput; however, pulsed arrays have low flexibility in operation scheduling, relatively high programming difficulty, and insufficient support for model sparsity. Representative Products:
- Google TPU v4: 256×256 pulsed array, achieving computing power of 100PetaOPS (INT8), with a ResNet-50 inference speed 15 times faster than GPU.
- Huawei Ascend 910B: adopts 3D Cube units, with matrix operation throughput reaching 256TFLOPS (FP16), supporting training at the scale of thousands of cards.

Advantages: Extremely high computing power density (10TOPS/mm²), suitable for dense computations in convolutional neural networks (CNN).
Disadvantages: Complex programming model, requiring a dedicated compiler (such as TensorFlow Lite for TPU), with lower flexibility.
- Sparse Architecture: The “Minimalist” with Energy Efficiency Priority:
Technical Highlights: NPUs are optimized at the hardware level for processing sparse data (i.e., matrices or tensors with many zero elements), thereby accelerating computation speed and reducing power consumption. Sparsity is common in deep learning, such as: Pruned neural networks: many weights are set to zero; Sparse attention mechanisms: only local attention is computed in Transformers; Sparse activation: ReLU functions cause most activation values to be zero. The advantage of sparse architecture is that when the model has structured sparsity (such as after pruning), it can significantly improve efficiency and save power. Representative Products:
- AWS Inferentia: optimized for pruned models, achieving a 3-fold speedup in inference speed at 70% sparsity, with a 40% reduction in power consumption.
- Horizon Journey 6M: supports dynamic sparsification, improving computing power utilization from 50% to 90% in autonomous driving object detection.

Advantages: Friendly to model compression, suitable for edge devices (such as smart cameras, requiring only 2TOPS to run YOLOv5).
Disadvantages: Dense computation performance decreases by 20%, requiring a model pruning toolchain.

- Data Flow Architecture: The “Transformers” with Flexible Adaptation:
Technical Highlights: For example, Graphcore IPU and SambaNova use programmable data flow architectures, allowing dynamic adjustment of computation flows based on model structures (such as graph neural networks, Transformers). Such architectures typically include a large number of small computing units and flexible routing networks, with the advantage of optimizing data reuse and scheduling for different network layers, improving energy efficiency; however, the programming model is complex and requires dedicated compilation tools. Representative Products:
- Graphcore IPU: thousands of small computing units + flexible routing network, with BERT inference throughput 2 times higher than GPU.
- SambaNova SN10: programmable data flow engine, adaptable to MoE (Mixture of Experts) models, supporting parameter scales up to trillions.
Advantages: 50% increase in data reuse rate, 30% higher energy efficiency than traditional architectures.
Disadvantages: Relies on dedicated programming models (such as Poplar), with a relatively weak developer ecosystem.
02. Performance Comparison: How to Choose the Right NPU?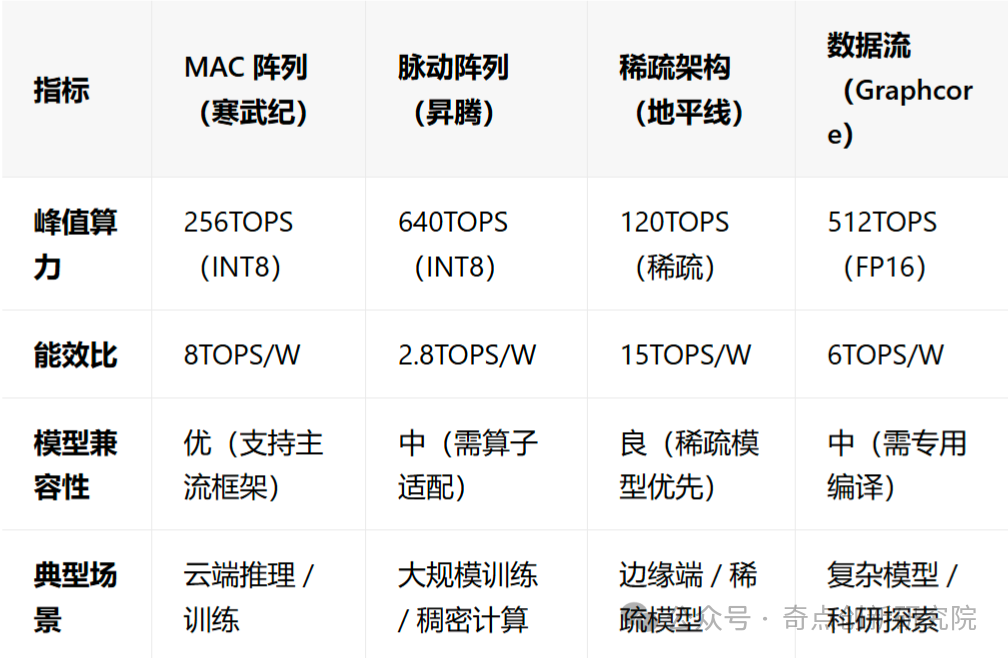 03NPU Application Panorama: The “Computing Power Penetration War” from Edge to Cloud With differentiated advantages, NPUs have achieved large-scale implementation in six core areas.01. Smart Devices: The “Last Mile” of Edge AI
03NPU Application Panorama: The “Computing Power Penetration War” from Edge to Cloud With differentiated advantages, NPUs have achieved large-scale implementation in six core areas.01. Smart Devices: The “Last Mile” of Edge AI
- Smartphones:
Core Functions: For example, the NPU in Huawei Mate 60 Pro supports edge-side large models with 10 billion parameters, enabling offline voice assistants (response delay < 1 second) and real-time AI photo editing (processing speed increased by 3 times). Market Data: In 2024, global shipments of GenAI smartphones will reach 223 million units, with an average NPU computing power of 30TOPS (Snapdragon 8 Gen3), supporting Stable Diffusion image generation (single image processing time < 2 seconds).
Market Data: In 2024, global shipments of GenAI smartphones will reach 223 million units, with an average NPU computing power of 30TOPS (Snapdragon 8 Gen3), supporting Stable Diffusion image generation (single image processing time < 2 seconds).
- AI PCs:
Productivity Revolution: The NPU computing power of Apple’s M4 chip is 38TOPS, with a 5-fold increase in local Photoshop AI photo editing speed; Lenovo Yoga AI+ achieves real-time meeting minutes generation (accuracy rate 98%) through NPU. Penetration Explosion: By 2028, AI PC shipments will reach 267 million units, with NPUs becoming the core hardware for localized operation of Windows Copilot.02. Autonomous Driving: The “Real-time Brain” from Perception to Decision
- Intelligent Driving Systems:
Sensor Fusion: Tesla’s FSD chip uses a 96×96 MAC array (36.8TOPS) to process data from 8 cameras in real-time, with a delay of 22ms; NVIDIA Orin relies on 254TOPS computing power, with a delay of 35ms.
Domestic Breakthrough: Horizon Journey 6M has a computing power of 560TOPS, supporting fusion of 16 cameras + 4 lidar, with a decision delay 40% lower than GPU solutions in urban NGP of XPeng G9.
- Intelligent Cockpit:
Mercedes MB.OS is equipped with NPU+GPU heterogeneous computing, achieving lip-reading recognition (accuracy rate 98%) and gesture control (response < 10ms); BMW Dee analyzes user biometric data through edge-side NPU to dynamically adjust seats/fragrance.03. Industry and IoT: The “Cost-Effective Choice” for Edge Computing
- Industrial Robots:
AGV Navigation: Yushu Technology’s Go2 robot is equipped with a domestic NPU of 6TOPS, processing SLAM data with a power consumption of only 3W (the CPU solution requires 8W), with a navigation accuracy of ±2cm. Defect Detection: Hikvision’s industrial camera uses Rockchip RK3588 (6TOPS), achieving a frame rate of 120FPS in PCB detection, with a false detection rate of < 0.1%.
- Intelligent Security:
Dahua’s camera integrates Cambricon Siyuan 220 (16TOPS), supporting simultaneous facial recognition of 300 people, with local storage saving 50% bandwidth.04. Cloud Inference: The “Cost-Reduction Tool” for Large Model Implementation
- Cost Advantages:
Alibaba Cloud Tongyi Qianwen inference service uses Ascend 910B clusters, reducing costs by 60% compared to GPU solutions, with a single card supporting 100 concurrent requests (A100 only supports 50 requests). Cambricon MLU290-M5 (512TOPS) achieves a throughput of 200 tokens/second in GPT-3.5 inference, with a 30% lower latency than GPUs.
- Scenario Adaptation:
Voice Interaction: Baidu Voice Cloud uses NPU for real-time transcription, reducing the character error rate to 4.5%, saving 40% in computing power costs. Image Generation: Tencent Cloud AI drawing service is optimized based on NPU, reducing single image generation time from 4 seconds on GPU to 2.5 seconds.05. Large Model Training: From “Supporting Role” to “Potential Stock”
- Current Challenges:
Insufficient single card computing power: Ascend 910B’s FP16 computing power is 320TFLOPS, only 1/10 of H100, requiring a cluster of 2048 cards to train a model with hundreds of billions of parameters. Ecological Dependence: PyTorch natively supports GPUs, while NPUs need to be adapted through frameworks (such as MindSpore automatic differentiation optimization).
- Breakthrough Progress:
Huawei Ascend 910B, in the training of the Pengcheng Pangu large model, achieves a convergence speed 80% that of GPUs through dynamic mixed precision technology; Suiruan Technology’s Suisi 2.0 supports TF32 precision, with a single card FP32 computing power of 160TFLOPS and a total cluster computing power of 1.3EFLOPS.
06. Consumer Electronics: The “Invisible Core” Reshaping User Experience
- Smart Watches:
The NPU computing power of Apple’s Watch Ultra 2 has increased by 50%, supporting real-time blood pressure monitoring (data processing delay < 20ms), with a battery life extended to 36 hours.
- Drones:
DJI Mavic 4 Pro is equipped with a 12TOPS NPU, achieving omnidirectional obstacle avoidance (response speed 10ms), with a 40% improvement in flight stability in complex scenarios.
04
Can NPU Replace GPU? The “Computing Power Replacement War” in the Era of Large Models In the core link of large model implementation, NPU and GPU present a differentiated competitive landscape of “strong inference, weak training”.01. Inference Side: NPU’s “Absolute Home Court”
- Three Major Advantages:
Energy efficiency ratio crushes: NPU inference energy efficiency is 5-10 times higher than GPU, such as Cambricon MLU370-X8 achieving TOPS/W of 128 in BERT inference, while A100 only achieves 25.
Delay Control: Edge-side NPU processes voice recognition with a delay of < 50ms, while cloud-side NPU clusters (such as Ascend 910B) support real-time conversations (round-trip delay < 100ms), while GPU solutions typically require over 200ms.
Cost Advantages: The price of a single NPU card is only 1/5 to 1/3 of that of a GPU (Ascend 310 is about 2000 yuan, while A100 exceeds 80,000 yuan), reducing deployment costs for small and medium-sized manufacturers by 70%.
- Technical Verification:
DeepSeek trained a 671 billion parameter model on 2048 H800 GPUs; if using Ascend 910B, 4096 cards would be needed, but inference costs could be reduced by 50%.02. Training Side: GPU’s “Temporary Barrier”, NPU’s “Breakthrough Direction”
- Irreplaceability of GPU:
High-precision computation: Large model training relies on FP32/FP64 high-precision operations, while NPU natively supports FP16/INT8, requiring additional optimization for precision loss.
Ecological Maturity: The CUDA toolchain supports 90% of AI frameworks, while the NPU training ecosystem (such as MindSpore, Cambricon NeuWare) is still being improved, with operator coverage only at 80%.
- Irreplaceability of NPU:
Mixed precision training: Huawei Ascend 910B supports dynamic switching between FP16/FP32, achieving accuracy consistent with GPUs in ResNet-50 training, with a speed of 95%.
Architectural Innovation: The data flow architecture of Graphcore IPU supports end-to-end training, improving memory utilization by 40% and reducing memory requirements by 30% in GPT-2 training.
Cluster Collaboration: Suiruan Technology’s Cloud Suiruan T20 cluster scales to 8000 cards, with a total computing power of 1.3EFLOPS, supporting distributed training of hundreds of billions of parameter models.
03. Future Trends: From “Replacement” to “Collaboration”
- Division of Labor between Edge and Cloud:
Edge-side NPUs handle real-time inference (such as mobile voice assistants), while cloud-side GPUs are responsible for model updates and complex training, forming a “light inference + heavy training” architecture.
- Heterogeneous Fusion:
“GPU+NPU” hybrid servers, with GPUs handling high-precision computations and NPUs accelerating low-precision inference, improving overall efficiency.
- Potential Scenarios for NPU:
Small model training: For models with fewer than 10 billion parameters (such as LLaMA-7B), NPU training efficiency is already close to that of GPUs, with costs reduced by 40%. Incremental training: For fine-tuning tasks based on user personalized data, NPUs, with their low power consumption and localization advantages, become the preferred solution.
05
China’s Computing Power Dilemma and the Path of Local NPU Manufacturers to Breakthrough Affected by U.S. export controls, China’s AI computing power faces the challenge of “high-end GPU supply interruption,” making NPUs the core tool for domestic substitution.01. Core Dilemma: Dual “Bottleneck” of Technology and Ecology
- Hardware Performance Gap:
Process lag: International leading NPUs have adopted 3nm (Apple M4), while domestic mainstream still uses 7nm (Cambricon MLU370), with a computing power density 40% lower (domestic 2.5TOPS/mm² vs Qualcomm 8TOPS/mm²). Memory bandwidth bottleneck: Domestic NPUs mostly use LPDDR4X (bandwidth 64GB/s), while international advanced products have deployed HBM3 (1.5TB/s), with a data throughput gap of 20 times.
- Software Ecosystem Deficiency:
High cost of framework adaptation: PyTorch native operators only support 50% of NPU operations, requiring manual optimization (such as operator fusion, data format conversion). Few developer resources: There are over 5 million CUDA developers, while domestic NPU developers are less than 500,000, with an ecological maturity gap of over 5 years.02. Domestic Manufacturers’ “Three-Horse Carriage” Leading Breakthroughs
- Huawei Ascend: Full-Stack Autonomy
Technical Layout:
- Da Vinci architecture: 3D Cube units support matrix operation acceleration, with Ascend 910B FP16 computing power of 320TFLOPS, compatible with MindSpore framework for automatic parallelization.
- Edge-cloud collaboration: Atlas 900 computing cluster has a total computing power of 256EFLOPS, supporting large model training such as Pengcheng Pangu; Ascend 310B achieves 16TOPS computing power at the edge with only 8W power consumption.

Market Implementation:
- Smart Cars: GAC AION LX Plus is equipped with 4 Ascend 910 chips, achieving L4 level autonomous driving; over 60% of Huawei Cloud AI service customers adopt Ascend solutions.
- Cambricon: The “Technical Faction” of Market Pioneers
Product Matrix:
- Full coverage of edge and cloud: MLU100 (edge, 4TOPS), MLU370 (cloud, 256TOPS), MLU290 (training, 512TOPS), supporting Chiplet packaging to enhance computing power density.
- Technical Advantages: 7nm process, sparse computing engine, achieving throughput in BERT inference 2.3 times that of GPUs, already entering the supply chains of Huawei Cloud and Tencent Cloud.
Commercial Breakthrough: In 2024, revenue is expected to exceed 2 billion yuan for the first time, with a net profit of 210 million yuan, and the MLU370-X8 acceleration card has a market share of 18% in the AI server market.

- Horizon: The “Invisible Champion” in the Autonomous Driving Track
Differentiated Positioning:
- Automotive-grade NPU: Journey 6M with 560TOPS computing power, supporting 16-bit lidar point cloud processing, with a power consumption of only 45W (NVIDIA Orin requires 150W), receiving orders from Volkswagen and BYD.
 03. Comparison of Alternative Solutions
03. Comparison of Alternative Solutions
In the current situation, domestic solutions generally adopt a heterogeneous acceleration route:
At the GPU level, companies like Huawei Haiguang and Hanbo are also developing autonomous GPUs;
At the AI acceleration level, the aforementioned NPUs and ASICs have become the focus.
Overall, domestic NPUs have gradually caught up with international levels in performance, but the software ecosystem and development maturity still need improvement.
With capital and policy support, the industry has formed a good innovation echelon: Hisilicon and Cambricon are in the first echelon, while Suiruan and Tianshu Zhixin are positioned in the second echelon.
Looking ahead, Chinese NPU manufacturers will continue to increase R&D investment, promoting domestic NPUs to keep pace with international giants in computing power, energy efficiency, and ecology.

NPU is Expected to Open the Era of Universal Computing Power
From edge smartphones to cloud data centers, NPUs are reconstructing the AI computing power landscape with advantages of “specialization, efficiency, and scenario-based applications.” Although breakthroughs are still needed in the ecological and precision bottlenecks on the large model training side, their absolute advantages on the inference side are irreversible—by 2025, devices equipped with NPUs will exceed 1 billion units, with computing power demand shifting from TOPS level to hundreds of TOPS level. In the future, NPUs will not completely replace GPUs, but will form a computing power network of “edge-cloud collaboration and heterogeneous complementarity” with CPUs and GPUs, transforming AI from a “cloud luxury” into an “edge necessity.” You may also want to share content on this topic
Welcome to scan the code to join our discussion community, with the note “AI”
↓