Click on the above“Linux Tech Enthusiast” to select “Set as Favorite”
High-quality articles delivered promptly
☞【Essentials】ChatGPT 4.0 is unlocked, no limit on questions!!!
☞【Essentials】Tsinghua University senior's self-study Linux notes, top-level quality!
☞【Essentials】Comprehensive guide to commonly used Linux commands, all in one article
☞【Essentials】Collection! Linux basic to advanced learning roadmap
Original link:https://blog.csdn.net/KUNPLAYBOY/article/details/123191919
Introduction
The virtual file system is a vast architecture, and analyzing it comprehensively can seem particularly complex and cumbersome, making it difficult to understand (of course, this is mainly due to the author’s lack of experience). Therefore, this blog will use the <span>open()</span> function as a starting point to analyze the operational mechanism of the VFS file system. The code in this article is sourced from linux3.4.2.
Basic Knowledge
First, let’s look at a diagram:
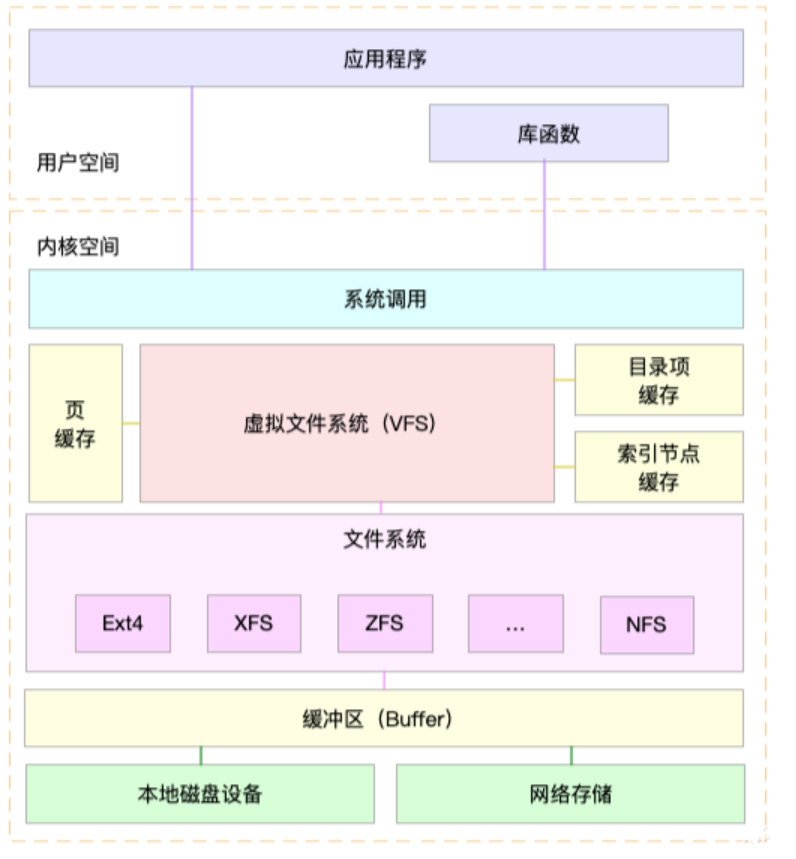
(Figure 1)
From this diagram, we can see that system call functions do not directly operate on the actual file system, but rather through an intermediate layer, which is the virtual file system. Why is there a virtual file system?
Common file systems in Linux can be categorized into three types: disk-based file systems, memory-based file systems, and network file systems. (These three types of file systems coexist at the file system layer, providing storage services for different types of data. The formats of these three types of file systems are different, meaning that if we do not go through the virtual file system and directly read the actual file system, we would need to write several corresponding read functions for different types of file systems). Therefore, the emergence of the virtual file system (VFS) allows operations on any file in Linux using the same set of file I/O system calls without needing to consider the specific file system format it resides in.
Data Structures of VFS
VFS relies on four main data structures and some auxiliary data structures to describe its structural information. These data structures behave like objects; each main object contains an operation object composed of an operation function table, which describes the operations that the kernel can perform on these main objects.
1. Superblock Object
Stores control information for an installed file system, representing an installed file system. Each time an actual file system is installed, the kernel reads some control information from a specific location on the disk to populate the superblock object in memory. Each installation instance corresponds to one superblock object. The superblock records its file system type in a field s_type within its structure.
struct super_block { // Superblock data structure
struct list_head s_list; /* Pointer to the superblock list */
……
struct file_system_type *s_type; /* File system type */
struct super_operations *s_op; /* Superblock methods */
……
struct list_head s_instances; /* Instances of this type of file system */
……
};
struct super_operations { // Superblock methods
……
// This function creates and initializes a new inode object under the given superblock
struct inode *(*alloc_inode)(struct super_block *sb);
……
// This function reads the inode from disk and dynamically fills the remaining part of the inode object in memory
void (*read_inode) (struct inode *);
……
};
2. Inode Object
The inode object stores information related to a file, representing an actual physical file on the storage device. When a file is accessed for the first time, the kernel assembles the corresponding inode object in memory to provide all the necessary information for the kernel to operate on a file; some of this information is stored at specific locations on the disk, while the rest is dynamically filled during loading.
struct inode { // Inode structure
……
struct inode_operations *i_op; /* Inode operation table */
struct file_operations *i_fop; /* File operations set for this inode */
struct super_block *i_sb; /* Related superblock */
……
};
struct inode_operations { // Inode methods
……
// This function creates a new inode for the dentry object corresponding to the file, mainly called by the open() system call
int (*create) (struct inode *, struct dentry *, int, struct nameidata *);
// Finds the inode corresponding to the dentry object in a specific directory
struct dentry * (*lookup) (struct inode *, struct dentry *, struct nameidata *);
……
};
3. Dentry Object
The concept of the dentry object is introduced mainly for the convenience of file lookup. Each component of a path, whether a directory or a regular file, is a dentry object. For example, in the path <span>/home/source/test.c</span>, the directory <span>/</span>, <span>home</span>, <span>source</span>, and the file <span>test.c</span> all correspond to a dentry object. Unlike the previous two objects, the dentry object does not have a corresponding disk data structure; VFS parses them into dentry objects one by one during the traversal of the pathname.
struct dentry { // Dentry structure
……
struct inode *d_inode; /* Related inode */
struct dentry *d_parent; /* Parent directory's dentry object */
struct qstr d_name; /* Name of the dentry */
……
struct list_head d_subdirs; /* Subdirectories */
……
struct dentry_operations *d_op; /* Dentry operation table */
struct super_block *d_sb; /* File superblock */
……
};
struct dentry_operations {
// Checks if the dentry is valid;
int (*d_revalidate)(struct dentry *, struct nameidata *);
// Generates a hash value for the dentry;
int (*d_hash) (struct dentry *, struct qstr *);
……
};
4. File Object
The file object is the representation of an opened file in memory, mainly used to establish the correspondence between a process and the file on disk. It is created on the fly by <span>sys_open()</span> and destroyed by <span>sys_close()</span><span>. The relationship between the file object and the physical file is somewhat analogous to the relationship between a process and a program. Search for the public account: Architect Guide, reply: Architect to receive materials.</span>
When we view VFS from the user space, we only need to interact with the file object without concerning ourselves with the superblock, inode, or dentry. Since multiple processes can simultaneously open and operate on the same file, the same file may also have multiple corresponding file objects.
The file object merely represents the already opened file from the process’s perspective, which in turn points to the dentry object (which points back to the inode). A file may have non-unique file objects, but its corresponding inode and dentry objects are undoubtedly unique.
struct file {
……
struct list_head f_list; /* File object list */
struct dentry *f_dentry; /* Related dentry object */
struct vfsmount *f_vfsmnt; /* Related mounted file system */
struct file_operations *f_op; /* File operation table */
……
};
struct file_operations {
……
// File read operation
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
……
// File write operation
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
……
int (*readdir) (struct file *, void *, filldir_t);
……
// File open operation
int (*open) (struct inode *, struct file *);
……
};
Main Content
After introducing the basic knowledge points, we will explore how, when we attempt to open a file using <span>open()</span>, Linux internally finds the data of the file stored on the hardware.
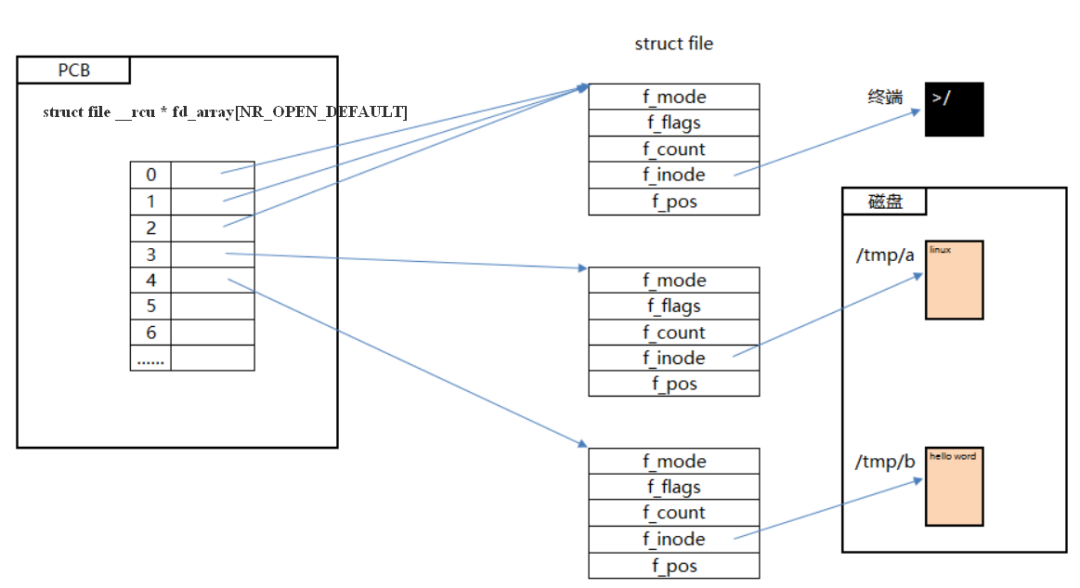
(Figure 2)

(Figure 3)
First, let’s look at the two diagrams above. <span>files_struct</span> is primarily an array of <span>file</span> pointers. The file descriptor we commonly refer to is an integer, which can serve as an index to obtain the <span>file</span> structure from <span>files_struct</span>. <span>task_struct</span> is the process descriptor, representing the action of opening a file. The point I want to express here is that when a file is opened for the first time (successfully), a connection is established as shown in the diagram above, and the returned <span>fd</span> file descriptor is linked to the underlying storage structure. <span>fd</span> serves as the file descriptor, while the file acts as the data carrier; we can understand them as the relationship between a password and a safe. The first time we open a file is akin to setting a password during initialization (establishing the connection between the password and the safe). When we later need to retrieve something from the safe, we can operate on it using the password set the first time.
In the kernel, there is a file descriptor table corresponding to each process, indicating all files opened by that process. Each entry in the file descriptor table is a pointer pointing to a data block that describes the opened file — the <span>file</span> object, which describes important information such as the file’s open mode and read/write position. When a process opens a file, the kernel creates a new <span>file</span> object.
It is important to note that the <span>file</span> object is not exclusive to a specific process; pointers in the file descriptor tables of different processes can point to the same <span>file</span> object, thereby sharing the opened file. The <span>file</span> object has a reference count that records the number of file descriptors referencing this object. The kernel only destroys the <span>file</span> object when the reference count reaches zero. Therefore, closing a file in one process does not affect other processes that share the same <span>file</span> object.
Next, let’s analyze the specific code.
Application Layer:
Before an application program can operate on any file, it must first call <span>open()</span> to open the file, notifying the kernel to create a structure representing that file and return the file descriptor (an integer), which is unique within the process. The function used is <span>open()</span>:
int open(const char * pathname,int oflag, mode_t mode )
/*pathname: represents the name of the file to be opened;
oflag: indicates the open flags (read-only, write-only, read-write, etc.)
mode: when creating a new file, the mode parameter needs to be specified (to set permissions)
*/
Kernel Layer:
When the <span>open()</span> system call enters the kernel, the final function called is:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
This function is located in <span>fs/open.c</span>, and the following will analyze its specific implementation process.
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
{
long ret;
// Check if the system supports large files, i.e., check the bit size of long; if 64, it indicates support for large files;
if (force_o_largefile())
flags |= O_LARGEFILE;
// Complete the main open work, AT_FDCWD indicates to start searching from the current directory
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
/* avoid REGPARM breakage on x86: */
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
}
This function mainly calls <span>do_sys_open()</span> to complete the open operation, and the code for <span>do_sys_open()</span> is as follows.
long do_sys_open(int dfd, const char __user *filename, int flags, int mode)
{
// Copy the filename to be opened into the kernel; the analysis of this function will be discussed later;
char *tmp = getname(filename);
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
// Find an available file table pointer from the process's file table; if an error occurs, return, see the explanation below;
fd = get_unused_fd();
if (fd >= 0) {
// Perform the open operation, see the explanation below, dfd=AT_FDCWD;
struct file *f = do_filp_open(dfd, tmp, flags, mode, 0);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f); // The purpose is to open the monitoring point of filp and add it to the monitoring system
// Add the opened file table f to the current process's file table array, see the explanation below;
fd_install(fd, f);
}
}
putname(tmp);
}
return fd;
}

(Figure 4)
From the analysis of the code and flowchart, we understand how the <span>fd</span> and <span>file</span> are linked (the <span>file</span> object contains a pointer that points to the <span>dentry</span> object. The <span>dentry</span> object represents an independent file path. If a file path is opened multiple times, multiple <span>file</span> objects will be created, but they all point to the same <span>dentry</span> object. The <span>dentry</span> object also contains a pointer to the <span>inode</span> object. The <span>inode</span> object represents an independent file. Due to the existence of hard links and symbolic links, different <span>dentry</span> objects can point to the same <span>inode</span> object. The <span>inode</span> object contains all the information needed to operate on the file, such as file system type, file operation methods, file permissions, access dates, etc.).
Now, let’s think in reverse: we have obtained the <span>fd</span>, how do we find the corresponding <span>file</span>? In the current process, we retain the file descriptor, which is stored in the file descriptor table (<span>files_struct</span>), and the file descriptor table retains the file descriptor table (<span>fatable</span>). Through the pointer array of type <span>file</span> in the file descriptor table corresponding to the <span>fd</span>, we can find the <span>file</span>.
This article concludes here, but there is still one task left unfinished: how does <span>do_filp_open(dfd, tmp, flags, mode)</span> obtain the <span>file</span>?
-End-
Reading this far indicates that you enjoy the articles from this public account. Welcome to pin (star) this public account Linux Tech Enthusiast, so you can receive notifications promptly!
In this public account Linux Tech Enthusiast, reply: Linux to receive 2T of learning materials!
Recommended Reading
1. ChatGPT Chinese version 4.0, everyone can use it, fast and stable!
2. Common Linux commands, a comprehensive summary of 20,000 words
3. Linux Learning Guide (Collection Edition)
4. No need to translate official ChatGPT and Claude as well as Midjourney, stable with after-sales service