1. Overview
The structure of onnx-runtime is as follows:
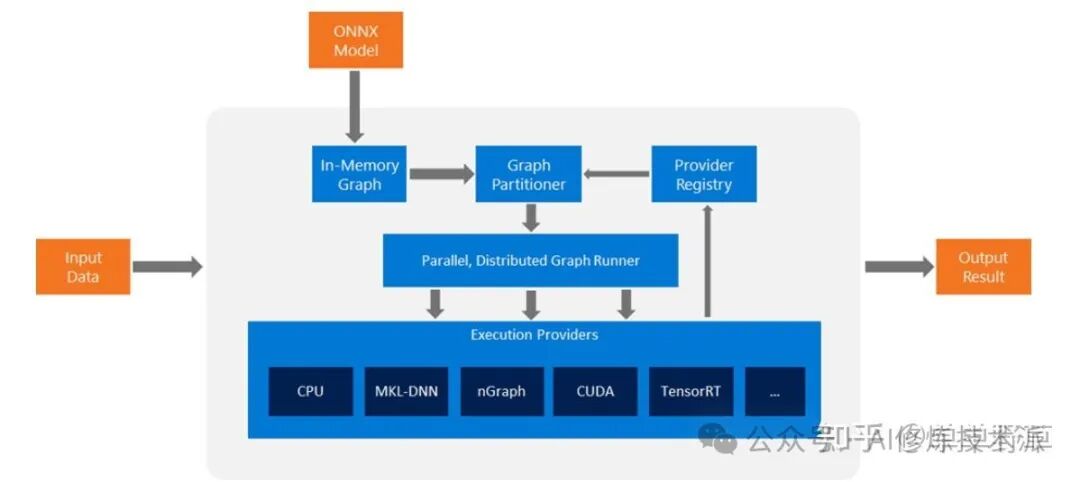
Overall, this is a heterogeneous model execution framework that first performs hardware-independent graph optimization on the original ONNX model, retrieves the operator library corresponding to the currently supported hardware, then splits the model into multiple sub-models, and finally dispatches them to various hardware platforms for execution. ONNX refers to this as a parallel and distributed runtime. Currently, ONNX Runtime only provides synchronous mode for model computation and does not support asynchronous mode.
ORT: abbreviation for onnx-runtime
Graph Transformer: the abstraction of graph optimization in onnx-runtime
EP: Execution Provider: an abstraction of ONNX’s operator library + runtime for various hardware platforms, providing memory management + operator library on the corresponding hardware; it can implement only a subset of ONNX operators, but the default execution provider (CPU) of onnx-runtime supports all ONNX operators; onnx-runtime provides a standard tensor definition, but each execution provider can provide its own different definitions, but needs to provide an interface for converting standard tensors to custom tensors; new EPs and Ops can be added.
The run interface of each inference session can be called in multi-threading, thus requiring that the compute interface of each kernel supports concurrency (i.e., is stateless).
Compatibility: ORT supports backward compatibility, meaning that the new ORT can run older versions of ONNX models.
Multi-platform support: Windows (CPU+GPU), Linux (CPU+GPU), Mac, iOS, Android.
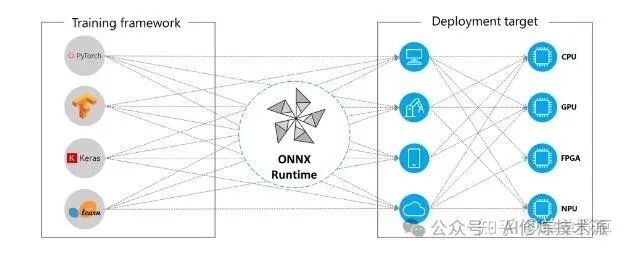
2. Applications
2.1 Installation
# linux + cuda 11.6 + python
# onnxruntime --- cpu
# onnxruntime-gpt --- cuda&tensorrt&cpu
# onnxruntime-gpu includes the functionality of onnxruntime, and the two cannot coexist
pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple2.n: Performance Optimization
3. Source Code Analysis
3.1 Overview
Analysis of ORT header files
onnx-runtime\include\onnxruntime\core\common
onnx-runtime\include\onnxruntime\core\eager
onnx-runtime\include\onnxruntime\core\framework
onnx-runtime\include\onnxruntime\core\graph
onnx-runtime\include\onnxruntime\core\optimizer
onnx-runtime\include\onnxruntime\core\platform
onnx-runtime\include\onnxruntime\core\providers
onnx-runtime\include\onnxruntime\core\session3.1.1 Common
onnx_runtime\onnx-runtime\include\onnxruntime\core\common\basic_types.h
/** A computed hash value. */
using HashValue = uint64_t; // Using uint64 to represent hash valueonnx_runtime\onnx-runtime\include\onnxruntime\core\common\exceptions.h
// ORT exception definitions: such as unimplemented operator {NotImplementedException}, runtime exceptions, etc.
class NotImplementedException : public std::logic_error
class TypeMismatchException : public std::logic_error
class OnnxRuntimeException : public std::exceptiononnx_runtime\onnx-runtime\include\onnxruntime\core\common\narrow.h
// A wrapper for gsl::narrow, can be used even when exceptions are disabled, used for overflow checks3.1.2 Framework
onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\alloc_kind.h ---- Memory allocation types
1. Model input tensor: allocated by the user
2. Model output tensor: allocated by runtime, runtime transfers permission to the user: ---- this is quite strange
3. Weight: static memory, allocated once, used multiple timesonnx_runtime\onnx-runtime\include\onnxruntime\core\framework\allocator.h ---- Memory allocation and release
1. Provides Alloc/Free interfaces, implemented by underlying hardware such as: CPU, GPUonnx_runtime\onnx-runtime\include\onnxruntime\core\framework\execution_provider.h --- EP abstract interface, each EP is responsible for implementation
1. Provides data format conversion: e.g., NCHW--->NHWC: GetDataTransfer
2. Provides operator lookup interface: based on Node to find information about whether this EP supports the operator, facilitating FMK to create corresponding kernels on this EP
virtual const KernelCreateInfo* LookUpKernel(const Node& node) const = 0;
3. Provides an interface to get registered kernels
GetKernelRegistry()onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\kernel_registry.h --- Kernel registration interface for each EP, responsible for registering to the operator library
onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\op_kernel_context.h --- Kernel runtime environment information
onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\op_node_proto_helper.h -- Helper to get op information defined in proto
onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\ort_value.h --- Encapsulation of tensor/sparse_tensor, etc. in ORT
onnx_runtime\onnx-runtime\include\onnxruntime\core\framework\ortdevice.h --- Definition of device: CUDA/CPU/HIP/CANNThe framework mainly provides: memory management (Alloc/Free) + tensor definition + op_kernel registration + EP interface definition, etc.
3.1.3 Graph
onnx_runtime\onnx-runtime\include\onnxruntime\core\graph\constants.h --- Some commonly used constant definitions
constexpr const char* kOnnxDomainAlias = "ai.onnx";
constexpr const char* kMLDomain = "ai.onnx.ml";
// Various EPs
constexpr const char* kCpuExecutionProvider = "CPUExecutionProvider";
constexpr const char* kCudaExecutionProvider = "CUDAExecutionProvider";
constexpr const char* kDnnlExecutionProvider = "DnnlExecutionProvider";
constexpr const char* kOpenVINOExecutionProvider = "OpenVINOExecutionProvider";onnx_runtime\onnx-runtime\include\onnxruntime\core\graph\graph.h ---- Definitions and operations for graph, node/edge: graph, edge, node
--- Definition of computation graph
class Graph :
// 0. Graph identifier: uniquely identified by name
const std::string& Name()
void SetName(const std::string& name);
const std::string& Description()
void SetDescription(const std::string& description);
// 1. Supports graph nesting, if the current graph is a sub-graph, it has a parent graph
bool IsSubgraph()
Graph* ParentGraph()
// 2. Supports modification/insertion/querying of weight data in nodes of the graph, replacing tensors with the same name with new new_initializers
Generally used in graph fusion, such as conv+bn fusion
common::Status ReplaceInitializedTensor(ONNX_NAMESPACE::TensorProto new_initializer);
/** Add an initializer tensor to the Graph. */
void AddInitializedTensor(const ONNX_NAMESPACE::TensorProto& tensor_proto);
/** Remove the initializer tensor with the provided name from the Graph. */
void RemoveInitializedTensor(const std::string& tensor_name);
/** Check if a given name is an initializer tensor's name in this graph. */
bool IsInitializedTensor(const std::string& name) const;
bool GetInitializedTensor(const std::string& tensor_name, const ONNX_NAMESPACE::TensorProto*& value) const;
// 3. Get input and output tensors of the graph, input tensors are of two types, constant and non-constant: non-constant is tensor, constant is initializer
std::vector<const NodeArg*>& GetInputs() // Input is tensor
std::vector<const NodeArg*>& GetInputsIncludingInitializers() // Input is const tensor
std::vector<const NodeArg*>& GetOutputs()
// 4. Provides operations on nodes in the graph: add, delete, modify, query
const Node* GetNode(NodeIndex node_index) // Get node by index
GraphNodes& Nodes() // Get all nodes
int MaxNodeIndex() // Get the maximum index of nodes in the graph
int NumberOfNodes() // Get the number of nodes in the graph
NodeArg* GetNodeArg(const std::string& name) // Get node by node-name
Node& AddNode(const Node& other); // Provides various methods to add node
bool RemoveNode(NodeIndex node_index); // Delete
void AddEdge(NodeIndex src_node_index, NodeIndex dst_node_index, int src_arg_index, int dst_arg_index);
void RemoveEdge(NodeIndex src_node_index, NodeIndex dst_node_index, int src_arg_index, int dst_arg_index);
bool AddControlEdge(NodeIndex src_node_index, NodeIndex dst_node_index); // Control flow operators will use this, control edges are separated from ordinary edges
// 5. Topological sorting of the graph
void KahnsTopologicalSort(const std::function<void(const Node*)>& enter,
const std::function<bool(const Node*, const Node*)>& comp) const;
// 6. Sub-graph exists as a node, embedded into the current graph
Node& BeginFuseSubGraph(const IndexedSubGraph& sub_graph, const std::string& fused_node_name);
void FinalizeFuseSubGraph(const IndexedSubGraph& sub_graph, Node& fused_node);
// 7. Interoperability between graph and graph-proto
const ONNX_NAMESPACE::GraphProto& ToGraphProto();
ONNX_NAMESPACE::GraphProto ToGraphProto() const;
// 8. Operations between node and op
bool SetOpSchemaFromRegistryForNode(Node& node); // Set op-schema for node
// 9. Operations between graph and model
Model& GetModel() // Get the model to which the graph belongs
// 10. Graph construction
Graph(Graph& parent_graph, const Node& parent_node, ONNX_NAMESPACE::GraphProto& subgraph_proto);
Graph(const Model& owning_model, // The model to which it belongs
IOnnxRuntimeOpSchemaCollectionPtr schema_registry,
ONNX_NAMESPACE::GraphProto& subgraph_proto,
const std::unordered_map<std::string, int>& domain_version_map,
const logging::Logger& logger,
bool strict_shape_type_inference);
// 11. Graph resolution
/**
Resolve this Graph to ensure it is completely valid, fully initialized, and able to be executed.
1. Run through all validation rules.
a. Node name and node output's names should be unique.
b. Attribute match between node and op definition.
c. Input/Output match between node and op definition.
d. Graph is acyclic and sort nodes in topological order.
2. Check & Setup inner nodes' dependency.
3. Cleanup function definition lists.
Note: the weights for training can't be cleaned during resolve.
@returns common::Status with success or error information.
*/
common::Status Resolve(const ResolveOptions& options);
common::Status Resolve() {
ResolveOptions default_options;
return Resolve(default_options);
}
The key aspects of the graph are: graph construction, graph sorting, and graph modification (deleting or adding nodes or modifying nodes).
3.1.4 Optimizer
ORT categorizes optimizations into different levels, with various optimizations belonging to different optimization levels.
enum class TransformerLevel : int {
Default = 0, // required transformers only
Level1, // basic optimizations
Level2, // extended optimizations
Level3, // layout optimizations
// The max level should always be same as the last level.
MaxLevel = Level3
};Graph optimization and graph fusion related operations
onnx_runtime\onnx-runtime\include\onnxruntime\core\optimizer\graph_transformer.h
Status Apply(Graph& graph, bool& modified, const logging::Logger& logger) const; // Entry point for graph fusion
onnx_runtime\onnx-runtime\include\onnxruntime\core\optimizer\rewrite_rule.h ---- Subgraph rewriting rules --- operator fusion3.1.4.1 RewriteRule
Implements local graph rewriting, such as operator fusion, invalid operator deletion, etc., mainly consisting of two steps:
Step 0: Determine the operator that triggers the rule:
std::vector<std::string> TargetOpTypes() const noexcept override {
return {"Cast"}; // Can be one or multiple operators. If these operators are present, the rule will be triggered.
}Step 1: Rule matching: The core is subgraph matching, parameter matching, attribute matching, etc. The principles and steps of operator fusion are the same.
virtual bool SatisfyCondition(const Graph& graph, const Node& node, const logging::Logger& logger) const = 0;
1. In this interface, set the matching rules, such as: conv+bn subgraph matching
2. This interface will be called by the graph optimization framework
3. graph --- is the entire computation graph, node is the current nodeStep 2: Perform rewriting
virtual common::Status Apply(Graph& graph, Node& node, RewriteRuleEffect& rule_effect, const logging::Logger& logger) const = 0;
};Upper framework calling method:
common::Status CheckConditionAndApply(Graph& graph, Node& node, RewriteRuleEffect& rule_effect, const logging::Logger& logger) const {
return SatisfyCondition(graph, node, logger) ? Apply(graph, node, rule_effect, logger) : Status::OK();
}
The impact of rewriting on the graph: updating op parameters, modifying op, deleting op
enum class RewriteRuleEffect : uint8_t {
kNone, // The rewrite rule has not modified the graph.
kUpdatedCurrentNode, // The rewrite rule updated (but did not remove) the node on which it was triggered.
kRemovedCurrentNode, // The rewrite rule removed the node on which it was triggered.
kModifiedRestOfGraph // The rewrite rule modified nodes other than the one it was triggered on.
};Class relationships:
class RuleBasedGraphTransformer : public GraphTransformer
Status RuleBasedGraphTransformer::ApplyRulesOnNode(Graph& graph, Node& node,
gsl::span<const std::reference_wrapper<const RewriteRule>> rules,
RuleEffect& rule_effect, const logging::Logger& logger) const {
for (const RewriteRule& rule : rules) { // Iterate through multiple subgraph fusion rules, so this also involves the order of fusion
ORT_RETURN_IF_ERROR(rule.CheckConditionAndApply(graph, node, rule_effect, logger));
// If the current node was removed as a result of a rule, stop rule application for that node.
if (rule_effect == RuleEffect::kRemovedCurrentNode) {
break;
}
}
return Status::OK();
}Upper layer calling:
onnx_runtime\onnx-runtime\onnxruntime\core\optimizer\graph_transformer_utils.cc
InlinedVector<std::unique_ptr<GraphTransformer>> GenerateTransformers(
TransformerLevel level,
const SessionOptions& session_options,
const IExecutionProvider& cpu_execution_provider, /*required by constant folding*/
const InlinedHashSet<std::string>& rules_and_transformers_to_disable) {
// When level=0, it will add rewiterule related to operator fusion
auto rule_transformer = GenerateRuleBasedGraphTransformer(level, rules_and_transformers_to_disable, {});
if (rule_transformer != nullptr) {
transformers.emplace_back(std::move(rule_transformer));
}
}Status RuleBasedGraphTransformer::ApplyImpl(Graph& graph, bool& modified, int graph_level, const logging::Logger& logger) const {
GraphViewer graph_viewer(graph);
auto& order = graph_viewer.GetNodesInTopologicalOrder(); // First topologically sorted graph
for (NodeIndex i : order) {
auto* node = graph.GetNode(i); // Iterate according to the execution order of the computation graph operators
// A node might not be found as it might have already been deleted from one of the rules.
if (!node) {
continue;
}
// Initialize the effect of rules on this node to denote that the graph has not yet been modified
// by the rule application on the current node.
auto rule_effect = RuleEffect::kNone;
// Check which devices the current op's fusion rules apply to, involving fusion in heterogeneous scenarios
if (!graph_utils::IsSupportedProvider(*node, GetCompatibleExecutionProviders())) {
continue;
}
// First apply rewrite rules that are registered for the op type of the current node; then apply rules that are
// registered to be applied regardless of the op type; then recursively apply rules to subgraphs (if any).
// Stop further rule application for the current node, if the node gets removed by a rule.
const InlinedVector<std::reference_wrapper<const RewriteRule>>* rules = nullptr;
rules = GetRewriteRulesForOpType(node->OpType()); // Get a series of fusion rules related to this op according to op_type
if (rules) {
ORT_RETURN_IF_ERROR(ApplyRulesOnNode(graph, *node, *rules, rule_effect, logger));
}
if (rule_effect != RuleEffect::kRemovedCurrentNode) {
rules = GetAnyOpRewriteRules();
if (rules) {
ORT_RETURN_IF_ERROR(ApplyRulesOnNode(graph, *node, *rules, rule_effect, logger));
}
}
// Update the modified field of the rule-based transformer.
if (rule_effect != RuleEffect::kNone) {
modified = true;
}
if (rule_effect != RuleEffect::kRemovedCurrentNode) {
ORT_RETURN_IF_ERROR(Recurse(*node, modified, graph_level, logger));
}
}
return Status::OK();
}
Common RewriteRule Optimizations
: onnxruntime\core\optimizer\conv_bn_fusion.h
1. conv + bn ---> conv
class ConvBNFusion : public RewriteRule
2. Operator elimination class: EliminateXXX
If the src.dtype of the cast operator == dst.dtype, then delete the cast operator
class CastElimination : public RewriteRule
class EliminateDropout : public RewriteRule : infer network deletes dropout operator
class ExpandElimination : public RewriteRule : If the input and output shapes of the expand operator are the same, then delete expand
class EliminateIdentity : public RewriteRule : identity operator deletion
class NoopElimination : public RewriteRule: meaningless calculations in addition, subtraction, multiplication, and division: x+0, 0+x, x-0, x*1, 1*x and x/1
3. conv + mul ---> conv
class ConvMulFusion : public RewriteRule
3.1.4.2 GraphTransformer
3.1.4.2.1 Overview
The base class for all graph optimizations, the entire fusion process is as follows:
The entire process is as follows:
1. Match subgraphs
2. Extract parameters from subgraphs, construct fusion-op
3. Modify the graph, add the fused operator to the graph, and remove the operators that have been fusedThe overall logic is still consistent with the fusion logic of other inference frameworks.
The calling process of graph transformer in ORT is as follows:
InferenceSession::Initialize() // During session initialization, execute graph-transformers
InferenceSession::AddPredefinedTransformers
GenerateTransformers
case TransformerLevel::Level1:
GenerateRuleBasedGraphTransformer
GenerateRewriteRules
case TransformerLevel::Level1:
EliminateIdentity
CastElimination
ConvAddFusion
......
ConstantSharing
CommonSubexpressionElimination
ConstantFolding
....
case TransformerLevel::Level2:
GemmActivationFusion
MatMulIntegerToFloatFusion
ConvActivationFusion
....
case TransformerLevel::Level3:
NchwcTransformer
NhwcTransformer3.1.4.2.2 Important Interfaces
// Base class definition
class GraphTransformer {
public:
// Constructor: name --- custom name
GraphTransformer(const std::string& name,
const InlinedHashSet<std::string_view>& compatible_execution_providers = {}) noexcept
: name_(name), compatible_provider_types_(compatible_execution_providers) {
}
// Execute transformer on graph
Status Apply(Graph& graph, bool& modified, const logging::Logger& logger) const;
3.1.4.2.3 Example
Example 1: Fuse Add + Gelu to BiasGelu or FastGelu
onnxruntime\core\optimizer\bias_gelu_fusion.h
class BiasGeluFusion : public GraphTransformer {
public:
BiasGeluFusion(const InlinedHashSet<std::string_view>& compatible_execution_providers = {}) noexcept
: GraphTransformer("BiasGeluFusion", compatible_execution_providers) { // Constructor, defines the name of the fusion
}
// Override
Status ApplyImpl(Graph& graph, bool& modified, int graph_level, const logging::Logger& logger) const override;
};
Status BiasGeluFusion::ApplyImpl(Graph& graph, bool& modified, int graph_level, const logging::Logger& logger) const {
GraphViewer graph_viewer(graph);
// 1. Get the list of operators in the graph after topological sorting
const auto& node_topology_list = graph_viewer.GetNodesInTopologicalOrder();
// 2. Traverse the graph
for (auto node_index : node_topology_list) {
auto* node_ptr = graph.GetNode(node_index);
if (nullptr == node_ptr)
continue; // node was removed
auto& node = *node_ptr;
// Subgraph processing
ORT_RETURN_IF_ERROR(Recurse(node, modified, graph_level, logger));
// 3. Check if the current node is an Add operator, and that the Add operator has only one output edge, i.e., the Add operator has only one output
if (!graph_utils::IsSupportedOptypeVersionAndDomain(node, "Add", {7, 13, 14}) ||
!graph_utils::IsSupportedProvider(node, GetCompatibleExecutionProviders()) ||
!optimizer_utils::CheckOutputEdges(graph, node, 1)) {
continue;
}
InlinedVector<NodeArg*> gelu_input;
// 4. Get the shapes of the two input tensors of the current Add operator
const TensorShapeProto* input1_shape = node.MutableInputDefs()[0]->Shape();
const TensorShapeProto* input2_shape = node.MutableInputDefs()[1]->Shape();
// 5. Only supports 2D and above input for Add
if (input1_shape == nullptr ||
input2_shape == nullptr ||
input1_shape->dim_size() < 1 ||
input2_shape->dim_size() < 1) {
continue;
}
// 6. Requires that the last dimension of the shapes of the two inputs of the Add operator are equal, for example: [3,5] and [4,5] are supported, [3,4] and [3,3] are not supported
if (input1_shape->dim(input1_shape->dim_size() - 1) != input2_shape->dim(input2_shape->dim_size() - 1)) {
continue;
}
// 7. Fill the input shape parameters of the Add operator to the gelu operator
if (input1_shape->dim_size() == 1) {
gelu_input.push_back(node.MutableInputDefs()[1]);
gelu_input.push_back(node.MutableInputDefs()[0]);
} else if (input2_shape->dim_size() == 1) {
gelu_input.push_back(node.MutableInputDefs()[0]);
gelu_input.push_back(node.MutableInputDefs()[1]);
} else {
continue;
}
// 8. If the Add operator is the last operator in the graph, fusion is not supported
auto next_node_itr = node.OutputNodesBegin();
if (next_node_itr == node.OutputNodesEnd()) {
continue;
}
// 9. Check if the next operator of the Add operator is Gelu or FastGelu
const Node& next_node = (*next_node_itr);
if (!(graph_utils::IsSupportedOptypeVersionAndDomain(next_node, "Gelu", {1}, kMSDomain) ||
graph_utils::IsSupportedOptypeVersionAndDomain(next_node, "FastGelu", {1}, kMSDomain)) ||
next_node.GetExecutionProviderType() != node.GetExecutionProviderType()) {
continue;
}
bool is_fast_gelu = next_node.OpType().compare("FastGelu") == 0;
if (is_fast_gelu && next_node.InputDefs().size() > 1) {
continue;
}
// 10. Check if the gelu operator is the last operator in the graph, many fusion frameworks have this requirement: the sub-graph to be fused cannot be the last part of the graph
// That is: Add +Gelu if it is the last part of the graph, fusion is not supported
if (graph.NodeProducesGraphOutput(node)) {
continue;
}
Node& add_node = node;
// 11. Directly convert the next operator of Add to the Gelu operator
Node& gelu_node = const_cast<Node&>(next_node);
std::string op_type = "BiasGelu";
if (is_fast_gelu) op_type = "FastGelu";
// 12. Add the fused operator of Add + Gelu to the graph
Node& gelu_add_fusion_node = graph.AddNode(graph.GenerateNodeName(op_type),
op_type,
"fused Add and Gelu",
gelu_input,
{},
{},
kMSDomain);
// Assign provider to this new node. Provider should be same as the provider for old node.
gelu_add_fusion_node.SetExecutionProviderType(gelu_node.GetExecutionProviderType());
// move output definitions and edges from gelu_node to gelu_add_fusion_node
// delete add_node and gelu_node.
// 13. Delete Add and gelu operators, keeping the fused Gelu operator
graph_utils::FinalizeNodeFusion(graph, {add_node, gelu_node}, gelu_add_fusion_node);
modified = true;
}
return Status::OK();
}
Common GraphTransformer Examples:
onnxruntime\core\optimizer\bias_gelu_fusion.h
1. Fuse Add + Gelu to BiasGelu or FastGelu
class BiasGeluFusion : public GraphTransformerOthers
onnxruntime\core\optimizer\compute_optimizer: Training related optimizations
3.1.5 Platform
Provides thread, file, so/dll loading, timer-related, logging, and other operations across different platforms.
Windows + Android + Linux + Mac, etc.
os and other platform difference interface encapsulation
onnx_runtime\onnx-runtime\include\onnxruntime\core\platform\ort_mutex.h --- Thread lock
onnx_runtime\onnx-runtime\include\onnxruntime\core\platform\threadpool.h --- Thread pool3.1.6 Session
ORT uses sessions to abstract and manage the entire inference process.
Session external interface
onnx_runtime\onnx-runtime\include\onnxruntime\core\session\onnxruntime_cxx_api.hInference Session Analysis
Inference session is the main entry point for model inference in onnx-runtime.
onnx_runtime\onnx-runtime\onnxruntime\core\session\inference_session.h
// Simple usage flow is as follows:
* Sample simple usage:
* CPUExecutionProviderInfo epi;
* ProviderOption po{"CPUExecutionProvider", epi};
* SessionOptions so(vector<ProviderOption>{po});
* string log_id = "Foo";
* auto logging_manager = std::make_unique<LoggingManager>
(std::unique_ptr<ISink>{new CLogSink{}},
static_cast<Severity>(lm_info.default_warning_level),
false,
LoggingManager::InstanceType::Default,
&log_id)
* Environment::Create(std::move(logging_manager), env) // 1. Create env
* InferenceSession session_object{so,env}; // 2. Create session object
* common::Status status = session_object.Load(MODEL_URI); // 3. Use session to load model (onnx or ort model)
* common::Status status = session_object.Initialize(); // 4. Session initialization, including memory allocation, graph optimization, etc.
*
* NameMLValMap feeds;
* feeds.insert({}); // 5. Construct tensor as input data for the entire model inference through the name of the model's input node and input data.
* ...
* std::vector<std::string> output_names;
* output_names.insert(...); // 6. Names of the model's output nodes, this way of specifying the names of output nodes allows inference to be done only on part of the model.
* ...
* std::vector<OrtValue> fetches;
* common::Status status = session_object.Run(run_options, feeds, output_names, &fetches); // 7. Execute inference, synchronous interface, results stored in fetches
* process the output here... // 8. Post-process the model's computation results ----> business logic part
(1): Analysis of Inference Session Constructor
// There are multiple constructors, main parameters are as follows: session-option and env and model loading path
explicit InferenceSession(const SessionOptions& session_options,
const Environment& session_env);
explicit InferenceSession(const SessionOptions& session_options,
const Environment& session_env,
onnxruntime::concurrency::ThreadPool* external_intra_op_thread_pool, // What are these two thread pools for?
onnxruntime::concurrency::ThreadPool* external_inter_op_thread_pool);
InferenceSession(const SessionOptions& session_options,
const Environment& session_env,
const std::string& model_uri);
// The above constructors will call Model::Load for model loading and ConstructorCommon for thread pool initialization, etc.
void InferenceSession::ConstructorCommon(const SessionOptions& session_options,
const Environment& session_env)
{
FinalizeSessionOptions // Build session-option, sourced from model or InferenceSession and constructor parameters: session_options
InitLogger(logging_manager_); // Initialize log
// Under default configuration, a thread pool will be created
concurrency::CreateThreadPool(&Env::Default(), to, concurrency::ThreadPoolType::INTRA_OP);
// If the session-option is in parallel computing mode, a parallel computing thread pool will be created
concurrency::CreateThreadPool(&Env::Default(), to, concurrency::ThreadPoolType::INTER_OP);
}
static Status FinalizeSessionOptions(const SessionOptions& user_provided_session_options,
const ONNX_NAMESPACE::ModelProto& model_proto,
bool is_model_proto_parsed,
/*out*/ SessionOptions& finalized_session_options) {
const Env& env_instance = Env::Default(); // Get the current platform or system's environment information: Windows or Linux, etc.
// Get the configuration information of the environment variable: this environment configuration indicates whether to get session-option from the model
const std::string load_config_from_model_env_var_value =
env_instance.GetEnvironmentVar(inference_session_utils::kOrtLoadConfigFromModelEnvVar);
// If getting session-option from the model
auto status = config_parser.ParseOrtConfigJsonInModelProto(model_proto);
if (!status.IsOK()) {
return status;
}
status = config_parser.ParseSessionOptionsFromModelProto(constructed_session_options);
if (!status.IsOK()) {
return status;
}
}It can be seen that the constructor completes various runtime environment initialization tasks based on session-options: the core is model loading and thread pool creation.
(2): Load
// Model loading interface, supports loading from file path, memory, no unload interface found (to be analyzed)
common::Status Load(const std::string& model_uri);
common::Status Load(const void* model_data, int model_data_len);
// Internal interface for saving ONNX model as ORT model (flatbuffer format)
common::Status SaveToOrtFormat(const PathString& filepath) const;Model loading is done by deserializing ONNX or ORT models into computation graph objects through protobuf or flatbuffer interfaces for ORT to use.
(3): Initialize
// Inference-session initialization interface
common::Status Initialize();
// 1. First get the graph
onnxruntime::Graph& graph = model_->MainGraph();
// 2. If there is no CPU computation library, create and start the CPU computation library, others are based on the PE provided by the user through the inference-session interface to get from the lib library
CPUExecutionProviderInfo epi{session_options_.enable_cpu_mem_arena};
auto p_cpu_exec_provider = std::make_unique<CPUExecutionProvider>(epi);
// 3. Iterate through each EP, get the memory management interface of each EP
for (auto& ep : execution_providers_) {
auto tuning_ctx = ep->GetTuningContext();
if (nullptr != tuning_ctx) {
tuning_ctx->RegisterAllocatorsView(&session_state_->GetAllocators());
}
}
// 4. Get the operator registration map for each EP
kernel_registry_manager_.RegisterKernels(execution_providers_)
// 5. If an ONNX model is loaded, some preprocessing transformers need to be added
AddPredefinedTransformers--->GenerateTransformers ----> RewriteRule and other passes
// 5.1. Perform graph optimization (passes registered in GenerateTransformers)
TransformGraph(graph, saving_ort_format))
// 6. If an ORT model is loaded
// 6.1 It will partition operators based on supported EPs, for example: if operator x can only run on CPU, it will be partitioned to CPU, operator y will be partitioned to CUDA
// By querying the operator situation registered by EP, the graph will be split into subgraphs running on different devices for subsequent execution calls
PartitionOrtFormatModel
// 6.2. Online inference graph optimization
ApplyOrtFormatModelRuntimeOptimizations(graph, *session_logger_, session_options_, optimizers_to_disable_, cpu_ep)
// 7. If configured to save the ORT format model, save it, the ORT model is a model that has been optimized and partitioned for heterogeneous execution
SaveToOrtFormat(session_options_.optimized_model_filepath)The core logic is: bring up each PE, perform graph optimization, and save the ORT model, preparing for the subsequent run interface.
(4): Model Inference Interface
// Interface definition is similar to tf's session interface
[[nodiscard]] common::Status Run(const RunOptions& run_options, gsl::span<const std::string> feed_names,
gsl::span<const OrtValue> feeds, gsl::span<const std::string> output_names,
std::vector<OrtValue>* p_fetches,
const std::vector<OrtDevice>* p_fetches_device_info = nullptr);
[[nodiscard]] common::Status Run(const RunOptions& run_options,
gsl::span<const char* const> feed_names,
gsl::span<const OrtValue* const> feeds,
gsl::span<const char* const> fetch_names,
gsl::span<OrtValue*> fetches);
// Does it support heterogeneous inference?
[[nodiscard]] common::Status RunAsync(const RunOptions* run_options,
gsl::span<const char* const> feed_names,
gsl::span<const OrtValue* const> feeds,
gsl::span<const char* const> fetch_names,
gsl::span<OrtValue*> fetches,
RunAsyncCallbackFn callback,
void* user_data = nullptr);
// 1. Validate model inputs and outputs
ORT_RETURN_IF_ERROR_SESSIONID_(ValidateInputs(feed_names, feeds));
ORT_RETURN_IF_ERROR_SESSIONID_(ValidateOutputs(output_names, p_fetches));
// 2. Notify each EP to start computation
for (auto& xp : execution_providers_) {
// call OnRunStart and add to exec_providers_to_stop if successful
auto start_func = [&xp, &exec_providers_to_stop]() {
auto status = xp->OnRunStart();
if (status.IsOK())
exec_providers_to_stop.push_back(xp.get());
return status;
};
ORT_CHECK_AND_SET_RETVAL(start_func());
}
// 3. Perform computation graph inference
retval = utils::ExecuteGraph(*session_state_, feeds_fetches_manager, feeds, *p_fetches,
session_options_.execution_mode,
run_options,)(5): Information Retrieval Interface
// Get model metadata, ONNX defines metadata about the model, such as version, etc.
std::pair<common::Status, const ModelMetadata*> GetModelMetadata() const;
// Get information about model input and output ops: such as name, shape, dtype
std::pair<common::Status, const InputDefList*> GetModelInputs() const;
std::pair<common::Status, const OutputDefList*> GetModelOutputs() const;
// Get registered EP types: cpu, cuda, etc.
const std::vector<std::string>& GetRegisteredProviderTypes() const;
(6): Others
// Model input and output validation
[[nodiscard]] common::Status ValidateInputs(gsl::span<const std::string> feed_names,
gsl::span<const OrtValue> feeds) const;
[[nodiscard]] common::Status ValidateOutputs(gsl::span<const std::string> output_names,
const std::vector<OrtValue>* p_fetches) const;// Profiling related
void StartProfiling(const logging::Logger* logger_ptr);
std::string EndProfiling();
const profiling::Profiler& GetProfiling() const;(7): SessionOptions
As session running configuration parameters: SessionOptions
onnx_runtime\onnx-runtime\onnxruntime\core\framework\session_options.h
// Execution method of computation graph
enum class ExecutionOrder {
DEFAULT = 0, // default topological sort --- Default topo sorting method, i.e., executing operators one by one from front to back
PRIORITY_BASED = 1 // priority-based topological sort ---- Priority sorting execution method, ????
};
// Execution priority of the model: In concurrent execution scenarios of multiple models, execute according to priority
enum class ExecutionPriority : int {
GLOBAL_HIGHT = -100,
LOCAL_HIGH = -10,
DEFAULT = 0,
LOCAL_LOW = 10,
GLOBAL_LOW = 100
};
// Session configuration: covers whether to execute ops concurrently, graph optimization level, whether to reuse memory, whether to enable profiling, etc.
struct SessionOptions {
ExecutionMode execution_mode = ExecutionMode::ORT_SEQUENTIAL;
// set the execution order of the graph
ExecutionOrder execution_order = ExecutionOrder::DEFAULT;
// enable profiling for this session.
bool enable_profiling = false;
// enable the memory pattern optimization.
// The idea is if the input shapes are the same, we could trace the internal memory allocation
// and generate a memory pattern for future requests. So next time we could just do one allocation
// with a big chunk for all the internal memory allocation.
// See class 'OrtValuePatternPlanner'.
bool enable_mem_pattern = true;
// Enable memory reuse in memory planning. Allows to reuse tensor buffer between tensors if they are of
// the same size. The issue with this is it can lead to memory being held for longer than needed and
// can impact peak memory consumption.
bool enable_mem_reuse = true; // This memory reuse mechanism needs analysis
// enable the memory arena on CPU
// Arena may pre-allocate memory for future usage.
// set this option to false if you don't want it.
bool enable_cpu_mem_arena = true;
// set graph optimization level --- Graph optimization level
TransformerLevel graph_optimization_level = TransformerLevel::Level3;
// controls the size of the thread pool used to parallelize the execution of tasks within individual nodes (ops)
OrtThreadPoolParams intra_op_param;
// controls the size of the thread pool used to parallelize the execution of nodes (ops)
// configuring this makes sense only when you're using parallel executor
OrtThreadPoolParams inter_op_param;
// By default the session uses its own set of threadpools, unless this is set to false.
// Use this in conjunction with the CreateEnvWithGlobalThreadPools API.
bool use_per_session_threads = true;
bool thread_pool_allow_spinning = true;
};
4. EP Analysis
EPs in ORT are divided into two main categories: 1. Operators implemented by ORT, such as CPU/CUDA 2. Operators implemented by third-party libraries, such as TensorRT/CoreML/SNPE, etc. How does ORT organize these two different types of EPs? How does ORT’s fmk call different EPs? How does the ONNX model interface with SPNE/CoreML/TensorRT, etc.? How does ORT’s memory interface with SNPE/CoreML? How does ORT achieve a framework above meta-frameworks (SPNE/CoreML, etc.)? Does ORT support true heterogeneity (such as heterogeneous SNPE and CPU operator libraries)?
— ORT interfaces with CoreML and TensorRT using an online compilation method, passing the graph after loading the ONNX model to CoreML and TensorRT for computation.
4.1 EP Overview
# EP Base class definition and core interfaces
onnx-runtime\include\onnxruntime\core\framework\execution_provider.h
# Base class for all EPs
class IExecutionProvider:
// 1. Constructor: type --- EP type, device--- device on which EP runs
IExecutionProvider(const std::string& type, OrtDevice device, bool use_metadef_id_creator = false)
// 2. Data copy between CPU and EP
std::unique_ptr<onnxruntime::IDataTransfer> GetDataTransfer()
// 3. Built-in class, finds the current EP's kernel based on the node's op_type
class IKernelLookup {
public:
/**
* Given `node`, try to find a matching kernel for this EP.
* The return value is non-null if and only if a matching kernel was found.
*/
virtual const KernelCreateInfo* LookUpKernel(const Node& node) const = 0;
};
// 4. Each EP has a kernel registry for kernel registration (to the belonging EP)
virtual std::shared_ptr<KernelRegistry> GetKernelRegistry()
// 5. Synchronous interface, waits for EP to complete execution
virtual common::Status Sync()
// 6. There are also some other interfaces, but not all interfaces are supported by each EP, EP selectively supports some interfaces, some interfaces are specific to certain EPs, such as CUDA
ORT mainly supports the following backend operator libraries:
acl: Arm Compute Library: an open-source project released by ARM, providing hardware acceleration libraries for ARM platforms
armnn: An open-source inference framework based on ARM embedded devices by Arm, achieving high acceleration on Arm Cortex-A CPUs, Arm Mali GPUs, and Arm Machine Learning processors
rknpu: RKNPU (Rockchip Neural Processing Unit) is an AI chip from Rockchip
cann: Huawei NPU
coreml: Apple
snpe: Qualcomm
tensorrt/cuda: NVIDIA
rocm: AMD
xnnpack: Google's open-source computation library for floating-point
qnnpack: Google's open-source computation library for quantization
4.2 CPU_EP
Class relationships of CPU_EP
// Class inheritance: core\providers\cpu\cpu_execution_provider.h
IExecutionProvider
CPUExecutionProvider:
// Overrides three interfaces of the base class
GetKernelRegistry // Register operators to CPU_EP
GetDataTransfer
CreatePreferredAllocators // Memory allocation interface for CPU_EP
CPUAllocator // Undertakes memory allocation and management on CPUCPU_EP is special, as it is actively brought up by the inference session, rather than being registered to ORT by the EP.
// Inference session brings up CPU_EP
InferenceSession::Initialize():
CPUExecutionProviderInfo epi{session_options_.enable_cpu_mem_arena};
auto p_cpu_exec_provider = std::make_unique<CPUExecutionProvider>(epi);
RegisterExecutionProvider(std::move(p_cpu_exec_provider))CPU_EP operator registration process:
CPUExecutionProvider::GetKernelRegistry():
RegisterCPUKernels
RegisterOnnxOperatorKernels: ONNX operator implementation registration on CPU
Covers each operator's supported ONNX version, data types, etc.
BuildKernelCreateInfo<ONNX_OPERATOR_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 6, Elu)>,
BuildKernelCreateInfo<ONNX_OPERATOR_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 6, HardSigmoid)>,
BuildKernelCreateInfo<ONNX_OPERATOR_VERSIONED_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 6, 15, LeakyRelu)>,
BuildKernelCreateInfo<ONNX_OPERATOR_VERSIONED_TYPED_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 6, 12, float, Relu)>,
BuildKernelCreateInfo<ONNX_OPERATOR_VERSIONED_TYPED_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 6, 12, double, Relu)>,
RegisterFp16Kernels: fp16 operator library, requires specific implementation
RegisterOnnxMLOperatorKernels
RegisterCpuContribKernels
RegisterCpuTrainingKernels
CPU_EP operator implementation process
// Op helper class【1】: Extracts input/output, attr, etc. information from the operator's proto in the model for use in operator computation
class ProtoHelperNodeContext {
public:
explicit ProtoHelperNodeContext(const onnxruntime::Node& node) : node_(node) {}
ProtoHelperNodeContext() = delete;
const ONNX_NAMESPACE::AttributeProto* getAttribute(const std::string& name) const;
size_t getNumInputs() const;
const ONNX_NAMESPACE::TypeProto* getInputType(size_t index) const;
size_t getNumOutputs() const;
const ONNX_NAMESPACE::TypeProto* getOutputType(size_t index) const;
private:
const onnxruntime::Node& node_;
};
// Op helper class【2】: OpKernelInfo: encapsulates op_proto information, belonging PE information, memory allocation information, providing all environment information for OpKernel computation
class OpKernelInfo : public OpNodeProtoHelper<ProtoHelperNodeContext> {
public:
explicit OpKernelInfo(const onnxruntime::Node& node,
const KernelDef& kernel_def,
const IExecutionProvider& execution_provider,
const std::unordered_map<int, OrtValue>& constant_initialized_tensors,
const OrtValueNameIdxMap& mlvalue_name_idx_map,
const DataTransferManager& data_transfer_mgr,
const AllocatorMap& allocators = {});
class OpKernelInfo : public OpNodeProtoHelper<ProtoHelperNodeContext>
// 【Key Point】 Operator base class: OpKernel analysis
// onnx-runtime\include\onnxruntime\core\framework\op_kernel.h
class OpKernel {
// 1. Constructor
explicit OpKernel(const OpKernelInfo& info) :
// 2. Operator computation interface: OpKernelContext is the parameter, containing information such as operator input and output tensors
virtual Status Compute(_Inout_ OpKernelContext* context)Taking the random operator as an example:
onnxruntime\core\providers\cpu\generator\random.h
// 1. Operator definition & implementation
class RandomNormal final : public OpKernel:
// 2. During the operator construction process, extract all information needed for the operator computation
RandomNormal(const OpKernelInfo& info) : OpKernel(info) {
ORT_ENFORCE(info.GetAttr<float>("mean", &mean_).IsOK());
ORT_ENFORCE(info.GetAttr<float>("scale", &scale_).IsOK());
// read optional seed attribute and generate if not provided
float seed = 0.f;
if (info.GetAttr<float>("seed", &seed).IsOK()) {
generator_ = std::default_random_engine{gsl::narrow_cast<uint32_t>(seed)};
} else {
// node index is added to the global seed to avoid two nodes generating the same sequence of random data
generator_ = std::default_random_engine{gsl::narrow_cast<uint32_t>(utils::GetRandomSeed() + info.node().Index())};
}
int64_t dtype;
ORT_ENFORCE(info.GetAttr<int64_t>("dtype", &dtype).IsOK());
dtype_ = static_cast<ONNX_NAMESPACE::TensorProto::DataType>(dtype);
ORT_ENFORCE(ONNX_NAMESPACE::TensorProto::DataType_IsValid(dtype_) && dtype_ != ONNX_NAMESPACE::TensorProto::UNDEFINED,
"Invalid dtype of ", dtype_);
TensorShapeVector shape;
ORT_ENFORCE(info.GetAttrs("shape", shape).IsOK());
shape_ = TensorShape(shape);
}
// 3. Implement the computation process in the compute interface, the computation process is the input inference session's run process, i.e., the computation process:
Status RandomNormal::Compute(OpKernelContext* ctx) const {
Tensor& Y = *ctx->Output(0, shape_);
std::lock_guard<onnxruntime::OrtMutex> l(generator_mutex_);
auto status = RandomNormalCompute(mean_, scale_, generator_, dtype_, Y);
return status;
}
// 4. Register to CPU_PE, adding the required operators in the CPU_PE's operator registration interface
Status RegisterOnnxOperatorKernels(KernelRegistry& kernel_registry):
BuildKernelCreateInfo<ONNX_OPERATOR_KERNEL_CLASS_NAME(kCpuExecutionProvider, kOnnxDomain, 1, RandomNormal)>,
Taking conv as an example:
// Instantiate conv operator according to data type
template <typename T>
class Conv : public OpKernel {
public:
Conv(const OpKernelInfo& info) : OpKernel(info), conv_attrs_(info) {
}
Status Compute(OpKernelContext* context) const override;
private:
ConvAttributes conv_attrs_; // During construction, extract kernel/stride and other attr information from OpKernelInfo into ConvAttributes
};
template <typename T>
Status Conv<T>::Compute(OpKernelContext* context):
// 1. Perform data preprocessing, such as calculating the size of output.shape, obtaining pad/kernel and other information from ConvAttributes. It seems to support dynamic shapes
// 2. Dynamically allocate workspace
// 3. Perform computation, calling different kernels for different shape scenarios, e.g., im2col, gemm, these operators are all optimized implementations for different CPU platforms
// Operator implementations are located in: onnxruntime\core\util\math_cpu.cc and onnxruntime\core\mlas\inc\mlas.h: High-performance computations are located under the mlas library
// Optimized implementations for various CPUs (32/64-bit) are available
math::Im2col<T, StorageOrder::NCHW>()
math::Gemm<T>Overall, CPU_PE is an abstraction of an operator library, but it is merely an operator library and does not include PE-specific graph optimization parts (i.e., hardware-related optimizations). Additionally, due to supporting dynamic shapes, workspace allocation occurs during each inference.
Moreover, the high-performance operator library implementation of CPU_PE is located at:
1. onnx_runtime\onnx-runtime\onnxruntime\core\mlas : High-performance implementations of conv/gemm operators for various CPUs
2. onnx_runtime\onnx-runtime\onnxruntime\contrib_ops\cpu : Some CPU operator implementations4.3 CUDA_EP
4.4 SNPE_EP
SNPE supports converting ONNX models to DLC models, and then directly performing inference based on SNPE. It seems that calling SNPE interfaces through ORT here is not very meaningful;
The current process of interfacing with SNPE through ORT is as follows:
1. Convert the SNPE DLC format model to an ONNX model, encapsulating the entire DLC model into a custom operator called "snpe" (this operator is custom-defined in ORT:), for details refer to:
onnx_runtime_example\onnxruntime-inference-examples\c_cxx\Snpe_EP\README.md
import onnx
from onnx import helper
from onnx import TensorProto
with open('./dlc/inception_v3_quantized.dlc','rb') as file:
file_content = file.read();
input1 = helper.make_tensor_value_info('input:0', TensorProto.FLOAT, [1, 299, 299, 3]);
output1 = helper.make_tensor_value_info('InceptionV3/Predictions/Reshape_1:0', TensorProto.FLOAT, [1, 1001]);
// Encapsulate the entire DLC model into the snpe operator
snpe_node = helper.make_node('Snpe', name='Inception v3', inputs=['input:0'], outputs=['InceptionV3/Predictions/Reshape_1:0'], DLC=file_content, snpe_version='1.61.0', target_device='DSP', notes='quantized dlc model.', domain='com.microsoft');
graph_def = helper.make_graph([snpe_node], 'Inception_v3', [input1], [output1]);
model_def = helper.make_model(graph_def, producer_name='tensorflow', opset_imports=[helper.make_opsetid('', 13)]);
onnx.save(model_def, 'snpe_inception_v3.onnx');
2. Then use ORT's interface to perform inference, setting the EP to SNPEOverall, the process involves converting the ONNX model to a DLC model, then wrapping the DLC model as an ONNX model, and finally performing inference through ORT.
4.5 CANN_EP
5. Summary
ONNX Runtime can load ONNX or ORT format models.
— ONNX model, i.e., the original ONNX model, stored in protobuf format.
— ORT model, the model that ONNX Runtime saves after graph optimization, using flatbuffer, with better performance and smaller size.
Overall, ONNX Runtime has done a lot of complex work to support multiple devices and platforms, and the overall inference software stack logic remains consistent; flatbuffer is also a very good alternative to protobuf.
6. Appendix
1. ORT Source Code Compilation
# Environment information: linux, torch, ORT cpu version compilation and installation
# 0. Environment preparation
conda create -n onnx_test python=3.9
pip install torch -i https://mirrors.aliyun.com/pypi/simple/
pip install onnx -i https://mirrors.aliyun.com/pypi/simple/
# 1. Code download
git clone https://gitee.com/mirrors/onnx-runtime.git
git submodule sync
git submodule update --init --recursive # Due to network issues, this command may need to be executed multiple times
# 2. Compilation: linux+torch+cpu
# Install cmake
conda install cmake
cmake --version # Check if cmake is installed successfully
# ORT requires gcc>8.0, this environment is 7.x, upgrade
conda config --add channels conda-forge
conda install gcc or conda install gcc=8.3 # One is the latest version, the other is a specified version
gcc --version
# Four compilation modes: --config Debug, Release, RelWithDebInfo and MinSizeRel
# By default, after compilation, all test cases will run, if you do not want to run, add: --build or --update --build
# --parallel means to start multi-threaded compilation, which will speed up the compilation
# --build_shared_lib means to compile ORT into so
# --build_wheel means to compile into a python installation package
./build.sh --config Debug --build_shared_lib --parallel --compile_no_warning_as_error --skip_submodule_sync
# Compile a debug mode ORT python version package, so you can use the python interface to run ONNX models, and also add log printing in C++ code to track the ORT process, or use pdb+gdb
# During the compilation process, a lot of third-party dependencies will be downloaded from GitHub, which may fail, and you can execute it multiple times
./build.sh --config Release --enable_pybind --build_wheel
#
ORT's compilation script: build.sh is ultimately completed through this python script, specific compilation can be analyzed in this script
onnx_runtime\onnx-runtime\tools\ci_build\build.py