Currently, there are quite a few mobile deep learning inference frameworks in the community (such as NCNN, MNN), which provide considerable convenience for community users to deploy deep learning on mobile devices. However, these inference frameworks share a common problem: as they continue to iterate and optimize performance, the runtime libraries gradually increase in size. Especially when different operators are fused, it leads to a large number of long-tail operators, making the App or SDK size bloated.
To address this issue, the MegEngine team has open-sourced MegCC, which innovatively uses a model pre-compilation scheme to generate the necessary code for model inference while removing code unrelated to model inference, thus significantly reducing the size of the inference engine. Its main approach isto move all necessary steps of traditional framework runtime, such as computation graph optimization, kernel selection, and memory allocation, into the compilation process, thereby minimizing the binary size during runtime and further optimizing performance based on model information.

Features of the Scheme
-
The size of the inference engine will no longer increase with the iteration of the framework. -
Operator fusion can generate corresponding code at compile time based on model information. -
The entire computation graph information can be obtained during model compilation for further extreme performance optimization. -
Can absorb community experiences in code generation to help generate code for MegCC.

Usage Method and Effects
-
Model Compilation: Compile the MegEngine model to generate the corresponding kernel and the optimized model. -
Runtime Compilation: This stage compiles the runtime and the kernel generated in the previous step into a static library. -
Integration into the Application: Call the interface of the static library compiled in the previous step for inference.
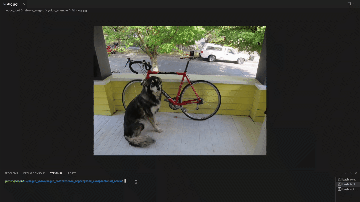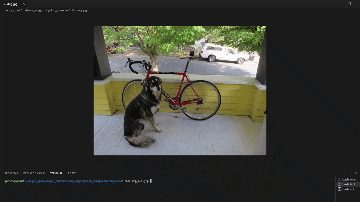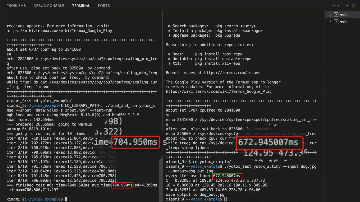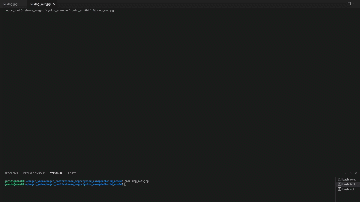
Future Plans
-
Support ONNX models as input -
More kernel fusion -
Support more backend devices
Exciting Preview
Chen Qiyou, the person in charge of MegEngine edge-side inference, will participate in the AI Basic Software Architecture Summit “Deep Learning Framework Forum” held during DataFunSummit2022 on November 19, 2022, and present a keynote speech titled “Achieving Ultra Lightweight High-Performance Inference on Edge with Model Compilation via MegCC”. This will cover an analysis of the current state of edge inference, especially regarding the size of inference engines, and a detailed explanation of the innovative use of model pre-compilation schemes in MegCC, showcasing the charm of the next generation AI model compiler MegCC.
Speech Outline:
1. Overview of the current state of edge inference, mainly focusing on the size of inference engines
2. Introduction of MegCC’s compiler scheme
3. Sharing the realization ideas of characteristics such as “ultra-lightweight, high performance, and strong scalability”
4. Summary of MegCC’s current status, advantages, and future plans
Don’t miss out on this exciting event, and we look forward to seeing you at the online live broadcast~
Click to read the original text at the end of the article and sign up immediately