
Image Source: Unsplash
The Julia language has emerged as a dark horse in the scientific world in recent years. Physicist Lee Phillips published a popular science article introducing the true charm of this scientific computing language.
This article is reprinted from the public account “Data Practicalist”
Written by Lee Phillips, Physicist
Translated by REN
Recently, I have met online several times with many scientists who are excited about a new tool. It is neither the latest particle accelerator nor a supercomputer, but a young programming language – Julia.
Different programming languages excel at different tasks; some are very fast, some are easier to develop and deploy, some have large ecosystems and libraries, and some are suitable for solving specific problems.
For scientists needing to simulate climate change or nuclear fusion, the mainstream language is currently Fortran. Its compiler can fully utilize the powerful performance of large supercomputers. For data scientists, however, Python is the most favored language due to its rich ecosystem, strong interactivity, and rapid development cycle.
Six years ago, I wrote about Fortran’s position in the field of scientific computing and compared it with several other languages. At the end of the article, I predicted that in ten years, a new language called Julia would likely replace it as the preferred language for scientists solving large-scale numerical computation problems.
My prediction was not very accurate, as Julia has approached this goal in about half the time.
Through recent communications with many scientists, I am convinced that Julia has sparked new enthusiasm in the industry. However, when I analyzed its potential back then, I did not understand why this language would be so popular.
At that time, my assessment was based on Julia’s unique convenient syntax and excellent performance. Although the official version of Julia 1.0 has not yet been released, the entire community is already very excited.
Julia seems to have solved the “two-language problem” (two-language problem), which is a common dilemma faced by users of interpreted languages like Python. Writing a program in Python allows one to enjoy its convenient syntax and interactivity, but when the scale of computation increases to a certain extent, the program’s execution speed slows down significantly. This is a limitation of the Python language itself.
For large simulation computations, due to the massive amount of data, the speed of program execution is crucial, so researchers have to rewrite the same program in languages like C to improve the execution speed in practical applications. However, once the speed is achieved, they must maintain and update code in both languages in subsequent research. Thus, the “two-language problem” arises.
Since its inception, Julia has aimed to solve the “two-language problem” to attract scientists and others to learn the language, but this is not its only exciting aspect.
Take this year’s JuliaCon conference as an example; most ordinary computer conferences revolve around topics like programming, compilers, algorithms, and optimization. While JuliaCon also covers these, it focuses more on scientific research topics such as fluid dynamics, language processing, brain imaging, and more. These presentation topics give the impression of stepping into a scientific research conference.
This flourishing situation is due to the open attitude of the Julia programming community, where everyone’s code can be found on GitHub. If someone wants to use existing algorithms, they can access the latest versions from documentation to code comments.
This is completely different from the atmosphere familiar to most older scientists: in the past, research code rarely left the laboratory.
The Julia community is built on large-scale collaboration and code sharing.
Solving the “Expression Problem”
The “Expression Problem” is a common concept in the study of programming language design. It is a branch of computer science research, and its meaning and interpretation are often quite abstract and rely on technical terminology.
To better understand this concept, we might compare it to cooking.
First, we need to clarify some computer science terms, including functions/programs, data types, and libraries/modules/packages.
In simple terms, a function/program refers to the process of “taking input values, processing them, and finally producing output values.” Data types are collections of numbers, characters, or other information, which can have various structures manipulated by functions. Libraries/modules/packages are collections of functions, along with descriptions of the data types used by those functions.
Next, we start the analogy.
If you know what a recipe and cooking mean, this analogy is easy to understand. We can view libraries/modules/packages as “cookbooks” sold on the market, functions/programs as the “complete process or technique for making dishes,” and data types as the “ingredients or materials” needed.
Now imagine the content of a recipe. Generally, recipes are categorized by different dishes, such as how to stir-fry onions, how to stir-fry shrimp, etc. Each dish has different steps because they use different ingredients or materials. These ingredient and material lists are also part of the recipe.
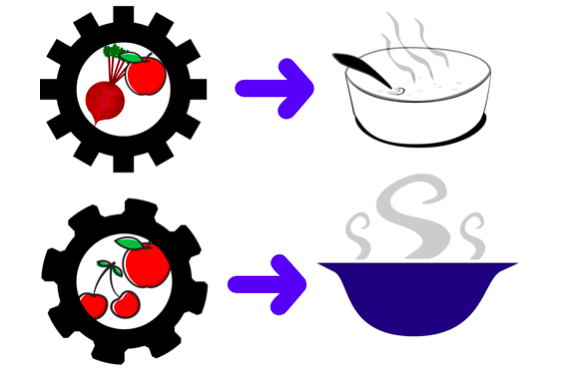
Cooking dishes requires specific ingredients and materials. (Image Source: Lee Phillips)
If we want to add a new dish, we only need to encompass all the ingredients or materials involved, and no existing dishes need any changes – the new dish will not invalidate the old ones.

Adding a new dish does not affect old dishes. (Image Source: Lee Phillips)
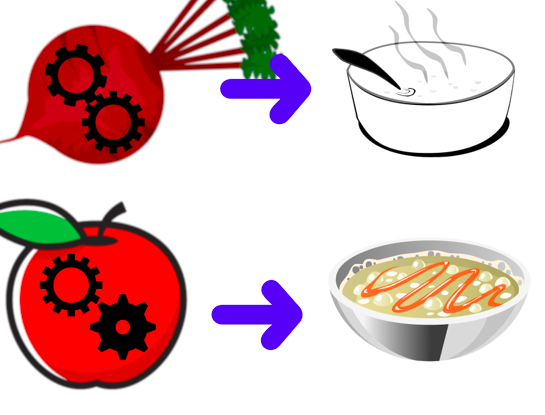
But what if we want to add new ingredients or materials? For example, if the existing dish-making process does not use fish, we will need to modify the existing process.

But to add new ingredients, we need to change the existing recipe. (Image Source: Lee Phillips)
However, there are many ways to organize a cookbook; another method is to organize the recipes around the ingredients rather than the cooking methods. Each ingredient will have corresponding cooking techniques and methods. As shown in the following image:
Organizing recipes around ingredients. (Image Source: Lee Phillips)
In this case, cooking techniques are no longer independent but are associated with the ingredients used. If we want to add fish as a new ingredient, we can write a new method for cooking fish, integrating it with existing fish cooking methods.

In this way, adding new ingredients does not require changing the existing recipes. (Image Source: Lee Phillips)
But what if we want to add a new cooking technique? For example, how to use a blender?
Without changing the existing work, we cannot achieve this. Because the existing techniques are already bound to the ingredients, the new cooking technique will inevitably change the method of preparing the ingredients.
These two ways of organizing recipes are similar to two types of programming languages. A cookbook organized around cooking processes is a “procedural language,” while a cookbook organized around ingredients is an “object-oriented language.” Both languages have their strengths.
This is essentially the “Expression Problem”: regardless of the language, there are obstacles to extending software (recipes). When reusing and combining existing code, whether it is possible to do so without changing existing software packages is crucial.
If you feel that the previous analogy is not clear enough, the next section provides another more intuitive explanation.
Introducing “Multiple Dispatch”
It is evident that if there were a way to organize recipes without changing existing content under any circumstances, it would provide great freedom of extension, which would be a significant advantage.
Instead of strictly adhering to the cooking processes and ingredients to organize recipes, it is better to adopt a more general and flexible approach. As shown in the following image:

The seemingly chaotic new recipe combination allows for greater freedom. (Image Source: Lee Phillips)
This image shows the free association of methods and ingredients, where neither is subordinate to the other. But this does not mean that unrelated methods can be randomly combined; rather, it is about creating variants based on existing methods and pairing them with different ingredients.
For example, our existing cookbook contains the cooking process for fried chicken. If we want to add the process for frying fish, we do not need to rewrite it; we just need to guide the reader to fry fish using the method for fried chicken, but at a higher temperature and removing the ingredients earlier.
Another way to view the three thinking models is to think about the “table of contents” of the recipes.
In the “functional” version, the table of contents might look like this:
– Chapter 1: Frying
Chicken
Fish
– Chapter 2: Boiling
Chicken
Fish
In this case, adding a new function only requires opening a new chapter, but adding a new ingredient (like eggs) requires modifying existing chapters: adding fried eggs in Chapter 1, boiled eggs in Chapter 2, etc.
In the “object-oriented” version, the table of contents might look like this:
– Chapter 1: Chicken
Frying
Boiling
– Chapter 2: Fish
Frying
Boiling
In this case, adding a new ingredient only requires opening a new chapter, but adding a new cooking method (like roasting) requires modifying existing chapters: adding roasted chicken in Chapter 1, roasted fish in Chapter 2, etc.
As for the third method, adhering to the idea of maximizing the extensibility of the recipes, the table of contents might look like this:
– Chapter 1: Fried Chicken
– Chapter 2: Boiled Chicken
– Chapter 3: Fried Fish
– Chapter 4: Boiled Fish
Clearly, both ingredients and cooking techniques can be freely added as new chapters to the book without modifying any existing chapters: Chapter 5 Fried Chicken, Chapter 6 Fried Fish, etc.
Compared to the first two versions, the third model seems less organized.
However, in practice, the relationship between cooking methods and ingredients can become part of the library structure. In the context of the recipe analogy, we can imagine that chicken and fish are subsets of meat, strawberries and cherries are subsets of red fruits, and frying and boiling are variants of larger general cooking methods, and so on.
This way of thinking is an attempt to solve the “Expression Problem.” In language design, this is also known as “multiple dispatch”, which refers to the automatic selection of methods based on all data types to be applied.
“Multiple dispatch” is Julia’s method for solving the “Expression Problem” and is its core organizational principle, making Julia neither object-oriented nor functional. The solution it adopts is more powerful and general than both. This means that Julia is freer in mixing and using libraries.
Importance of Tools
Julia is not the first language to attempt to solve the “Expression Problem,” nor is it the first to use “multiple dispatch.” Languages like Common Lisp have had this feature for 40 years, and the latest versions of languages like Perl also have this feature. Users have confirmed the convenience of “multiple dispatch” in writing and extending libraries.
However, the difference with Julia is that Julia is designed around “multiple dispatch”, while other languages treat it as an option and may incur performance losses. For example, Julia’s “multiple dispatch” allows it to express mathematical thinking more flexibly and naturally, and the amount of code reuse in its community has surprised language designers.
However, to establish a foothold in the scientific community, having the above advantages is not enough. Julia has garnered significant attention because it combines “multiple dispatch” with other features, such as high-quality code that is free and easy to get started with, and very fast computation speeds, which are very attractive to scientists who require extensive numerical computations.
Stanford University professor Mykel Kochenderfer designed a system to avoid airplane collisions using Julia, which has become an international standard. He stated that Julia is not only “a high-level, interpretable language, but its execution speed is also comparable to highly optimized C++ code.”
Julia also has expressive and readable syntax, especially when dealing with arrays. It provides a fast track for parallel processing of numerical algorithms. It has design advantages in the Unicode era, making it more like real mathematics when expressing mathematical formulas.
The following image shows actual code in a Julia program, using a font specifically designed for the Julia language.
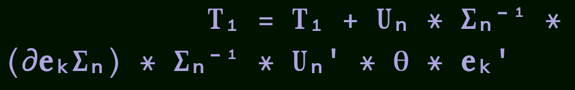
Mathematical formula expression in Julia language. (Image Source: Lee Phillips)
These features of Julia attracted many scientists early on, even before the special advantages of “multiple dispatch” drew attention, it had already attracted a large user base.
What I have learned from this is the core idea: tools are important. Just as a painter must choose brushes and paints that match the style of the work, a composer must ensure that the melodies in their mind align with the instruments and performers’ skills.
As a programming tool, Julia is the same for scientists. It can extend what scientists can accomplish in a limited time, helping them realize ideas they had never imagined.
Reference Source:
The unreasonable effectiveness of the Julia programming language
https://arstechnica.com/science/2020/10/the-unreasonable-effectiveness-of-the-julia-programming-language/
This article is reprinted from the public account “Data Practicalist” (ID: gh_ff93f845912e)

 Click [View] to receive our content updates in a timely manner
Click [View] to receive our content updates in a timely manner
