
Produced by | Huxiu Technology Team
Author | Utada
Header Image | Visual China
Starting from the fountain pool beside A38 road in Bristol, you can ride a bicycle and “dash” out of this southwestern city of the UK in less than 20 minutes, entering an area filled with rows of English bungalows, shrubs, and waterways.
Indeed, even though Bristol is a veritable center of the southwest of England, many Chinese students have given it a very fresh and unique name – “Bucun” (“Apart from London, everything else is a village”).
However, after getting involved in the chip industry, we suddenly realize that this ancient British town actually hides one of the most powerful semiconductor industry clusters in the UK.

The image shows NVIDIA’s R&D center in Bristol. After acquiring the UK semiconductor company Icera in 2011, NVIDIA established a base in Bristol and invested tens of millions of pounds to build new factories and laboratories here.
In 1972, the famous Fairchild Semiconductor in Silicon Valley (where founders of Intel and AMD came from) made an important decision to enter the European market by setting up an office in Bristol. This opened the global perspective of this small town in western England towards the semiconductor industry.
Six years later, the microprocessor company Inmos, born in Bristol and occupying 60% of the global SRAM market in the 1980s, received £200 million in investments from the Callaghan and Thatcher governments, finally creating a semiconductor infrastructure and ecosystem centered in Bristol, gathering a large number of semiconductor super elites like XMOS semiconductor founder David May.
“Actually, Bristol has always been a hub for IT in the UK. It, along with the surrounding Swindon and Gloucester, forms a triangular area known as Europe’s ‘Silicon Valley’. If semiconductor companies want to set up R&D centers in Europe, Bristol is usually the first choice. For example, world-class giants like NVIDIA, HP, Broadcom, and Qualcomm all have offices in Bristol.”
A practitioner familiar with the European semiconductor industry told Huxiu that many people are impressed by ARM’s presence in Cambridge, but historically, Bristol is actually the chip design center of the UK.
“Huawei also has an R&D center in Bristol.”
Just like in the 1950s, when eight genius “traitors” left Fairchild Semiconductor to establish Intel, AMD, Teradyne, and other companies, leading to the creation of today’s Silicon Valley, the talented engineers in Bristol are also unwilling to remain in the “past”—at the critical point where the controversy over the failure of Moore’s Law peaks and the structure of artificial intelligence and computing undergoes changes, no one is not eager to become the leader who changes the era.
An engineer named Simon Knowles graduated from Cambridge University and first set foot in Bristol in 1989, accepting a chip design job at the memory company Inmos.
In the nearly 20 years that followed, from being the leader of a dedicated processor team within Inmos to being one of the founders of two semiconductor companies, Element 14 and Icera, Knowles witnessed the entire process of Moore’s Law reaching its peak and then declining. Fortunately, the two companies he co-founded, valued at over $1 billion, were acquired by Broadcom and NVIDIA in 2000 and 2011, respectively.
Not surprisingly, this genius semiconductor designer and serial entrepreneur continued in 2016 to start anew with another genius semiconductor engineer, Nigel Toon, to establish a new semiconductor design company, actively confronting the opportunities for chip architecture innovation triggered by the demand of the artificial intelligence market.
Indeed, this company is Graphcore, which announced the completion of $222 million in financing on December 29, 2020 (this financing also gave the company a balance sheet with $440 million in cash), and is valued at $2.77 billion, being referred to by foreign media as one of NVIDIA’s biggest competitors in AI accelerator processor design.
It is worth noting that it is also the only unicorn in the Western AI chip field at present.

The image shows Graphcore’s IPU processor.
Western private equity and venture capital have always been very cautious about semiconductor projects because they are highly capital-intensive and it is difficult to predict the return on early investments. As Knowles admitted in an interview: “Compared to the software industry, which can try on a small scale and switch to another pit if unsuccessful, if a chip design fails, apart from spending all the money, the company has almost no way out.”
Therefore, it was not until after 2018, with the continuous hype and amplification of the commercialization potential of artificial intelligence, that investors began to see the prospect of returns from the trend of “chip structure changes driven by large-scale AI computing”.
Thus, after receiving over $80 million in investments in 2017, Graphcore subsequently secured $200 million and $150 million in venture capital in 2018 and 2020, respectively.
It is worth noting that besides Bosch and Samsung, which participated from the A round, Sequoia Capital led Graphcore’s C round, while Microsoft and BMW’s iVentures became the lead investors in its D round financing;
In the E round financing, the main participants were non-industry funds—the Ontario Teachers’ Pension Plan Board led the round, with Fidelity International and Schroders also joining this round of financing.
You can see from the investors that Graphcore’s industrial investors are basically divided into three industry directions—cloud computing (data centers), mobile devices (smartphones), and automotive (autonomous driving). Indeed, these are the three industries that were first “invaded” by artificial intelligence technology.
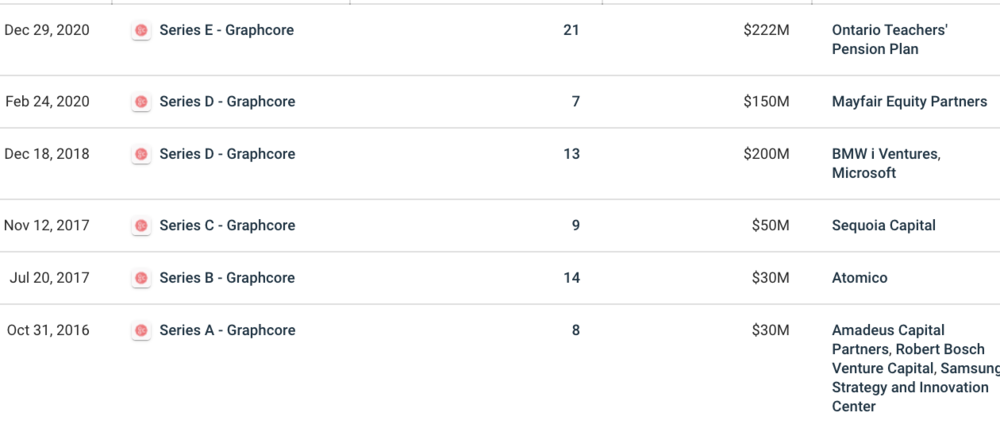 Image from Crunchbase
Image from Crunchbase
Industries seem to increasingly reach a consensus that the future needs a foundational innovation company like ARM that dominated the mobile device era, which not only hopes to sell hundreds of millions of chips but also can promote the deep integration of artificial intelligence with various industries, ultimately reaching hundreds of billions of ordinary consumers.
From a product perspective, Graphcore launched a relatively eye-catching product in 2020—the second-generation IPU-M2000 chip, which is mounted on a computing platform called the IPU Machine platform. Additionally, its chip’s accompanying software stack tool, Poplar, has also been updated simultaneously.
“Teaching computers how to learn is completely different from teaching computers to do math problems. Enhancing a machine’s ‘understanding’ focuses on efficiency rather than speed,” said Graphcore CEO Nigel Toon, viewing the development of the new generation of AI chips as a “once-in-a-lifetime opportunity.”
“Any company that can achieve this will share the decision-making power for the innovation and commercialization of artificial intelligence technology for the next few decades.”
Hitting NVIDIA’s ‘Soft Spot’
No AI chip design company wants to do anything but take down NVIDIA, which has a market value of $339.4 billion. In other words, no company wants to create a better AI accelerator product than GPUs.
Therefore, in the past five years, various chip design companies have tended to compare their enterprise-level chip products with NVIDIA’s T4, V100, or even the recently released “strongest product” A100 in PPTs, proving that their processors have better computational efficiency.
Graphcore is no exception.
They also believe that since the previous generation of microprocessors—such as Central Processing Units (CPUs) and Graphics Processing Units (GPUs)—were not specifically designed for AI-related tasks, the industry needs a brand new chip architecture to accommodate the new data processing methods.
Of course, such statements are not mere conjectures from stakeholders.
We cannot ignore the increasing criticism from academia and industry regarding GPUs— as the diversity of artificial intelligence algorithm training and inference models rapidly increases, GPUs, which were not designed for artificial intelligence from the beginning, have exposed their “weaknesses” in certain areas.
“If what you are doing is just convolutional neural networks (CNNs) in deep learning, then GPUs are a good solution, but as the networks become longer and more complex, GPUs are increasingly unable to satisfy the growing appetite of AI developers.”
An algorithm engineer pointed out to Huxiu that the reason GPUs are fast is that they are inherently capable of parallel processing tasks (the definition and characteristics of GPUs can be found in the article “Taking Down NVIDIA”). If the data has a “sequence” and cannot be parallelized, then CPUs must be used again.
“Many times, since the hardware is fixed, we will find ways from the software layer to convert sequential data into parallel data. For example, in language models, text is continuous, and a ‘teacher-driven’ training model can convert it into parallel training.
But certainly not all models can be done this way, for example, ‘reinforcement learning’ in deep learning is not very suitable for GPUs, and it is also difficult to find a parallel method.”
From this perspective, many in academia even claim that “GPUs hinder the innovation of artificial intelligence” is not an exaggeration.
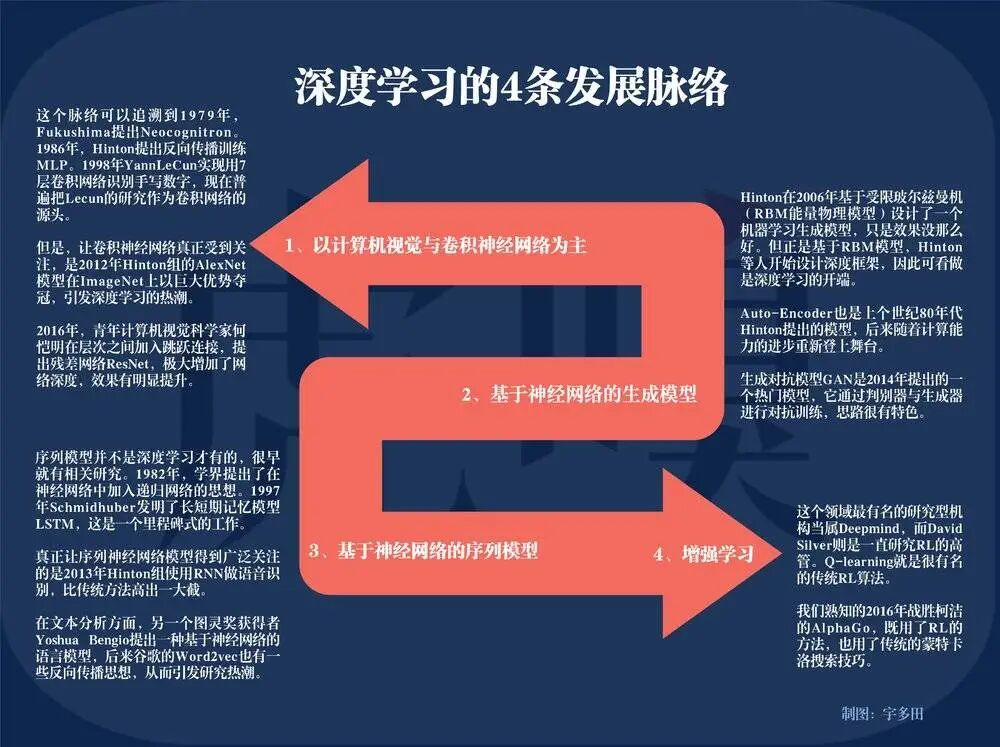
The four development lines of deep learning, charted by Utada.
“Deep learning,” the fastest-growing branch of machine learning in the past decade, has developed neural network models so quickly and widely that it is difficult for a single hardware like GPUs to keep up with its complex computational pace.
Graphcore provided Huxiu with a more detailed answer. They believe that for several branches of deep learning other than CNNs, especially Recurrent Neural Networks (RNNs) and Reinforcement Learning (RL), many developers’ research areas have been limited.
For example, the British AI company DeepMind, which created AlphaGo using reinforcement learning, has long focused on Graphcore due to the computational limitations of GPUs, and its founder, Demis Hassabis, eventually became an investor in Graphcore.
“Many developers in product departments of enterprises hand over their requirements (especially latency and throughput data metrics) to the computing power platform department, and they usually refuse, saying ‘GPUs currently cannot support such low latency and high throughput.’
The main reason is that the architecture of GPUs is more suitable for computational vision tasks with high-density data, such as ‘static image classification and recognition,’ but not the best choice for training sparse data models.
On the other hand, algorithms related to text, such as “Natural Language Processing” (NLP), have less data (sparse), and these algorithms require multiple data passes during training and quickly provide feedback to create a context that is easy to understand for the next training step.”
In other words, this is a continuous flow and cycle of training data.
Just like the “You might also like” feature on Taobao, after learning your browsing and order data on the first day, it provides limited feedback to the algorithm for correction, and continues to learn and provide feedback on the second, third, and future days, becoming increasingly familiar with your product preferences.
And this type of task, such as the BERT model proposed by Google in 2018 to better optimize user searches, is an excellent and far-reaching RNN model, which is also one of the tasks that Graphcore mentions that “GPUs are very poor at.” To solve such problems, many companies still use a large number of CPUs for training.
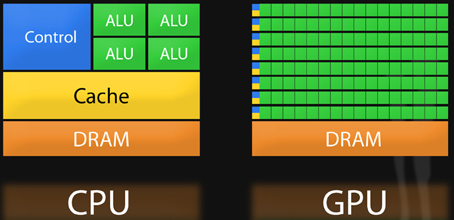 Comparison of CPU and GPU architectures
Comparison of CPU and GPU architectures
Fundamentally, this is actually determined by one of the biggest bottlenecks of the current chip operating system—how to transfer data as quickly as possible from the memory module to the logic operation unit on a processor without consuming too much power. As we enter the era of data explosion, unlocking this bottleneck has become increasingly urgent.
For example, in October 2018, the BERT-Large model had 330 million parameters, and by 2019, the GPT-2 model had reached 1.55 billion (both belong to natural language processing models). It can be said that the impact of data volume on the system’s underlying hardware to the upper-level SaaS services is no longer negligible.
A traditional GPU or CPU can certainly perform multiple operations in succession, but it needs to “first access registers or shared memory, then read and store intermediate computation results.” This is like going to the outdoor cellar to get stored ingredients and then returning to the indoor kitchen for processing, back and forth, which undoubtedly affects the overall efficiency and power consumption of the system.
Therefore, the core idea of many emerging semiconductor companies’ product architecture is to bring “memory closer to processing tasks to speed up the system”—near-memory computing. This concept is not new, but very few companies can produce real products.
So what exactly has Graphcore achieved? Simply put, it has “changed the way memory is deployed on processors.”
On an IPU processor, which is about the size of a small soda cracker, in addition to integrating 1216 units called IPU-Cores, the biggest difference from GPUs and CPUs is the large-scale deployment of “on-chip memory.”
In simple terms, it disperses SRAM (Static Random Access Memory) integrated next to the computing units, discarding external storage, and minimizing data movement. The goal of this method is to break through the memory bandwidth bottleneck by reducing load and storage quantity, significantly reducing data transmission latency while lowering power consumption.
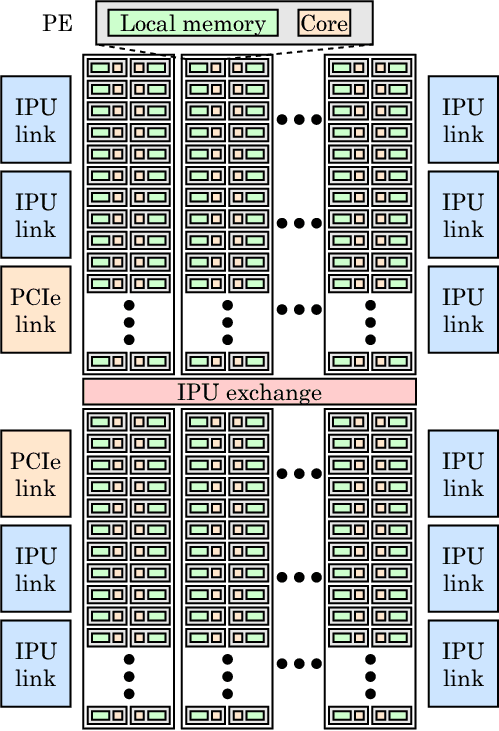 IPU architecture
IPU architecture
Because of this, in some specific algorithm training tasks, since all models can be stored within the processor, tests have indeed shown that the speed of the IPU can reach 20 to 30 times that of GPUs.
For example, in the field of computer vision, besides the well-known and widely used residual network model ResNets (which is very compatible with GPUs), image classification models based on grouped convolutions and depthwise convolutions, such as EfficientNet and ResNeXt, are also gradually emerging as research areas.
Grouped convolutions have a characteristic of having less dense data.
Therefore, Microsoft machine learning scientist Sujeeth used Graphcore’s IPU to conduct image classification training based on the EfficientNet model. The final result was that the IPU completed an analysis of chest X-ray images for COVID-19 in 30 minutes, a task that would typically take a traditional GPU 5 hours to complete.
Multiple Challenges
However, just as the popularity of GPUs and the widespread application of the mainstream algorithm model ResNets in the field of computer vision complement each other, the key to Graphcore’s success or failure also lies in “specificity.”
As the Vice President of Sales and General Manager for China at Graphcore pointed out in an interview with Huxiu:
On one hand, their products are indeed more suitable for deep learning tasks with sparse data and high precision requirements in the training market, such as recommendation tasks related to natural language processing, which is also one of the important reasons why Alibaba Cloud and Baidu are willing to cooperate with them.
On the other hand, the new models that have just become popular in the field of computer vision are the direction that the IPU is striving to “conquer,” while many previous models are still best suited for GPUs.
Moreover, the powerful software ecosystem created by GPUs, Cuda, is much harder to disrupt than hardware (about Cuda, there is a detailed explanation in the article “Taking Down NVIDIA”) and this layer of wall is precisely the key to opening up industrial influence.
Undoubtedly, Graphcore’s foundation in this area is still shallow, so in addition to regular operations, they choose to make some relatively bold attempts based on the programming software Poplar.
For example, they opened the source code of the computing library PopLibs in their developer community, allowing developers to try to describe a new convolutional network layer. This layer corresponds to NVIDIA’s cnDNN and cuBLAS, which NVIDIA has not opened.
To pay tribute to the open-source community, Poplar v1.4 added comprehensive support for PyTorch. This clever move will help simplify acceptance and attract broader community participation.
Additionally, to quickly open up the market, Graphcore did not take the laboratory sales route of “competing in contests to enhance industry visibility,” but directly pushed the IPU into the industry, knocking on the doors of server integrators, cloud vendors, and other customers one by one.
“The AI industry itself, whether in terms of algorithm iteration or model changes, is actually very fast. Some cloud vendors have complained that a certain processor performs very well on a certain model, but when the model is slightly modified, the performance drops dramatically.”
Graphcore’s head of technical applications in China, Luo Xu, believes that although the market is heavily promoting ASICs (Application-Specific Integrated Circuits) and FPGAs (Field-Programmable Gate Arrays), versatility remains the primary consideration for chip procurement in the industry, especially for internet companies.
“Internet companies have very diverse applications, and each application will have different applicable models. If a processor can only adapt to one model, then customers cannot introduce this processor for large-scale promotion.”
What “programming environment friendliness” is, is also the second key procurement criterion, which is the kind of power contributed by NVIDIA’s Cuda.
“Currently, customers generally use AI frameworks to design models, such as Google’s TensorFlow, Facebook’s PyTorch, etc. They will consider whether the upper-level SDK of this processor can be easily integrated into the framework and whether the programming model is user-friendly.
Customers may have some operator-level optimizations and need to create some custom operators. The ease of developing custom operators actually depends on how friendly the programming environment is.” If customers care about anything else, it is certainly product performance.
Whether it is cloud vendors, server manufacturers, or developers purchasing computing power through cloud services, they will test the performance of various models running on the chip.
“If they mainly focus on NLP (Natural Language Processing) models, they may focus on testing BERT during performance testing. If they focus on computer vision, they may focus on testing some classic models in computer vision during performance testing.
Overall, customers need to comprehensively evaluate from the above dimensions to decide whether to use this processor or determine how much benefit this processor can bring them.”
In this regard, whether it is NVIDIA, Graphcore’s IPU, or other manufacturers’ dedicated chips, each has its strengths in specific models, and it can only be said that “each has its merits,” and it is absolutely wrong to generalize.
Winners Take All Will No Longer Exist
From the product benchmark indicators and promotional focus provided by Graphcore, this company is actively looking for nails with a hammer, striving to expand the application scenarios where the IPU excels to maximize the efficiency of the IPU architecture.
In other words, Graphcore may share a piece of the pie with NVIDIA, but it will never be able to replace them.
As the meaning of the word “specific” suggests, the market for AI training and inference chips, due to the diversity and complexity of models, will certainly accommodate more chip companies, including NVIDIA and Graphcore.
Nigel Toon also acknowledged that AI computing will give birth to three vertical chip markets:
-
A relatively simple small dedicated accelerator market, such as a certain IP core in mobile phones, cameras, and other smart devices;
-
Then there are ASIC chips suitable for specific functions in data centers, solving specific problems, where large-scale data center operators (cloud vendors) will have many opportunities in this market;
-
Finally, there is the programmable AI processor market, which is where GPUs are located. This market will certainly have more companies, and more innovations will generate larger shares in the future.
CPUs will continue to exist, and GPUs will continue to innovate; they are indispensable or the best choice for certain AI computing tasks. However, the trends of Moore’s Law failure, AI computing, and data explosion will inevitably give rise to new markets that are vast and diverse. It is precisely because of this diversity that it provides more opportunities for dedicated chip companies.
Therefore, chip startups like Cerebras, Groq, SambaNova Systems, and Mythic AI have been able to raise hundreds of millions of dollars, and Intel has also invested in Untether AI, which is innovating AI chip architecture this year. Many have predicted that the next generation of ‘Apple’ and ‘Intel’ may emerge in the AI computing market.
At a time when software has not yet kept pace with hardware, this means that fierce competition is just beginning.
If you have any objections or complaints about this article, please contact [email protected]
End
Follow Huxiu’s video account for hot search comments