Reported by Machine Heart
Editors: Zenan, Xiaozhou
Supports up to 10,000+ concurrent threads.
After nearly a decade of relentless effort and in-depth research into the core of computer science, a dream has finally been realized: running high-level languages on GPUs.
Last weekend, a programming language called Bend sparked heated discussions in the open-source community, with its GitHub Stars exceeding 8500.
GitHub: https://github.com/HigherOrderCO/Bend
As a high-level programming language for large-scale parallelism, it is still in the research phase, but the proposed ideas have already amazed many. With Bend, you can write parallel code for multi-core CPUs/GPUs without needing to be a C/CUDA expert with 10 years of experience; it feels just like Python!
Yes, Bend uses Python syntax.
Unlike low-level alternatives like CUDA and Metal, Bend incorporates features of expressive languages such as Python and Haskell, including fast object allocation, higher-order functions with full closure support, unrestricted recursion, and even continuations. Bend runs on large-scale parallel hardware, achieving near-linear acceleration based on the number of cores. Bend is supported by the HVM2 runtime.
The main contributor to the project, Victor Taelin, is from Brazil, and he shared the main features and development ideas of Bend on the X platform.
First, Bend is not suitable for modern machine learning algorithms, as these algorithms are highly regularized (matrix multiplication), have pre-allocated memory, and often already have CUDA kernels written for them.
The significant advantage of Bend is evident in practical applications, as “real applications” typically do not have the budget to create dedicated GPU kernels. Who has made a website in CUDA? Even if someone did, it would be impractical because:
1. Real applications need to import functions from many different libraries, making it impossible to write CUDA kernels for them;
2. Real applications have dynamic functions and closures;
3. Real applications dynamically and unpredictably allocate large amounts of memory.
Bend has made some new attempts and can be quite fast in certain cases, but it is certainly not ready for writing large language models yet.
The author compared the old method and the new method using the same algorithm tree for bidirectional sorting, involving JSON allocation and operations. The speed of Node.js was 3.5 seconds (Apple M3 Max), while Bend achieved 0.5 seconds (NVIDIA RTX 4090).
Yes, currently Bend requires a whole GPU to outperform Node.js on a single core. On the other hand, this is still a comparison between a nascent new method and a JIT compiler optimized by a large company (Google) for 16 years. There are many possibilities for the future.
How to Use
On GitHub, the author briefly outlines the usage process for Bend.
First, install Rust. If you want to use the C runtime, install a C compiler (such as GCC or Clang); if you want to use the CUDA runtime, install the CUDA toolkit (CUDA and nvcc) version 12.x. Bend currently only supports Nvidia GPUs.
Then, install HVM2 and Bend:
cargo +nightly install hvmcargo +nightly install bend-langFinally, write some Bend files and run them using one of the following commands:
bend run <file.bend> # uses the Rust interpreter (sequential)bend run-c <file.bend> # uses the C interpreter (parallel)bend run-cu <file.bend> # uses the CUDA interpreter (massively parallel)You can also use gen-c and gen-cu to compile Bend into standalone C/CUDA files for optimal performance. However, gen-c and gen-cu are still in their infancy and are far from being as mature as state-of-the-art compilers like GCC and GHC.
Parallel Programming in Bend
Here is an example of a program that can run in parallel in Bend. For instance, the expression:
(((1 + 2) + 3) + 4)cannot run in parallel because + 4 depends on + 3, which in turn depends on (1+2). However, the expression:
((1 + 2) + (3 + 4))can run in parallel because (1+2) and (3+4) are independent. The condition for parallel execution in Bend is that it conforms to parallel logic.
Now let’s look at a more complete code example:
# Sorting Network = just rotate trees!def sort (d, s, tree): switch d: case 0: return treecase _: (x,y) = treelft = sort (d-1, 0, x) rgt = sort (d-1, 1, y) return rots (d, s, lft, rgt)# Rotates sub-trees (Blue/Green Box)def rots (d, s, tree): switch d: case 0: return treecase _: (x,y) = treereturn down (d, s, warp (d-1, s, x, y))This file implements a bidirectional sorter with immutable tree rotations. It is not the algorithm many expect to run quickly on a GPU. However, because it uses a fundamentally parallel divide-and-conquer approach, Bend runs it in a multithreaded manner. Some speed benchmarks:
-
CPU, Apple M3 Max, 1 thread: 12.15 seconds
-
CPU, Apple M3 Max, 16 threads: 0.96 seconds
-
GPU, NVIDIA RTX 4090, 16k threads: 0.21 seconds
A 57-fold speedup is achieved without performing any operations. There is no thread generation, no explicit management of locks or mutexes. We simply ask Bend to run our program on the RTX, and that’s it.
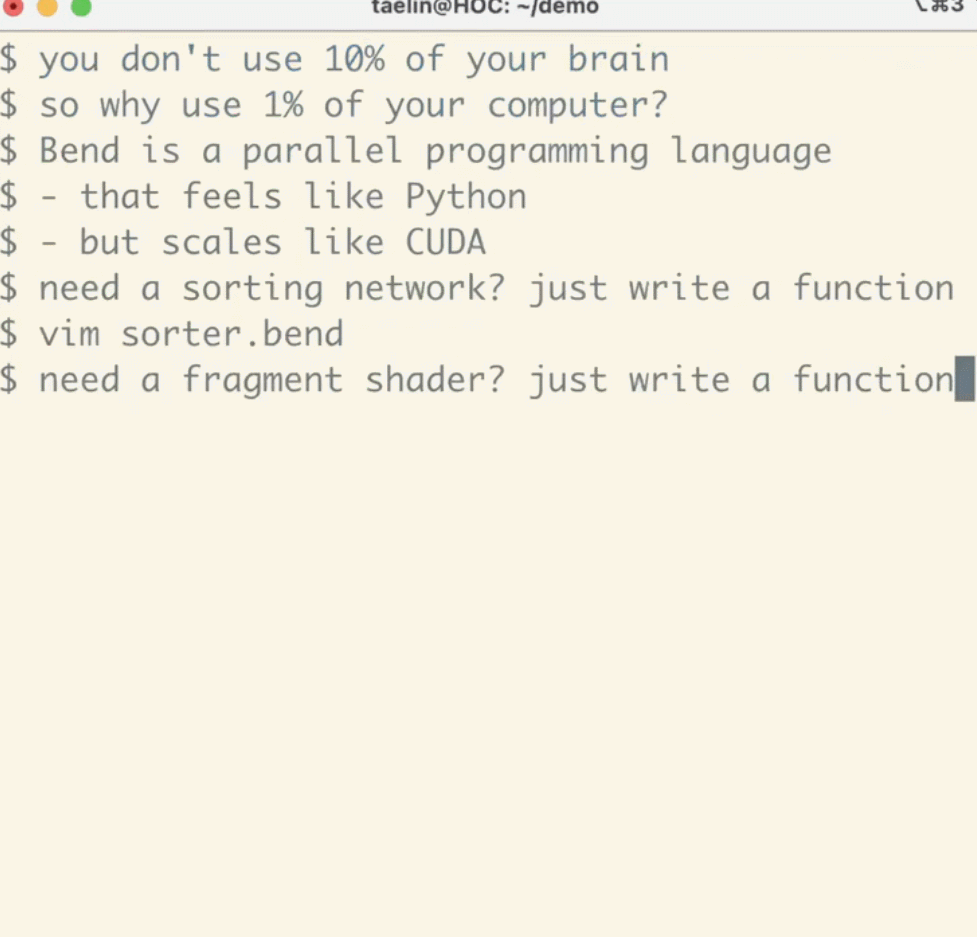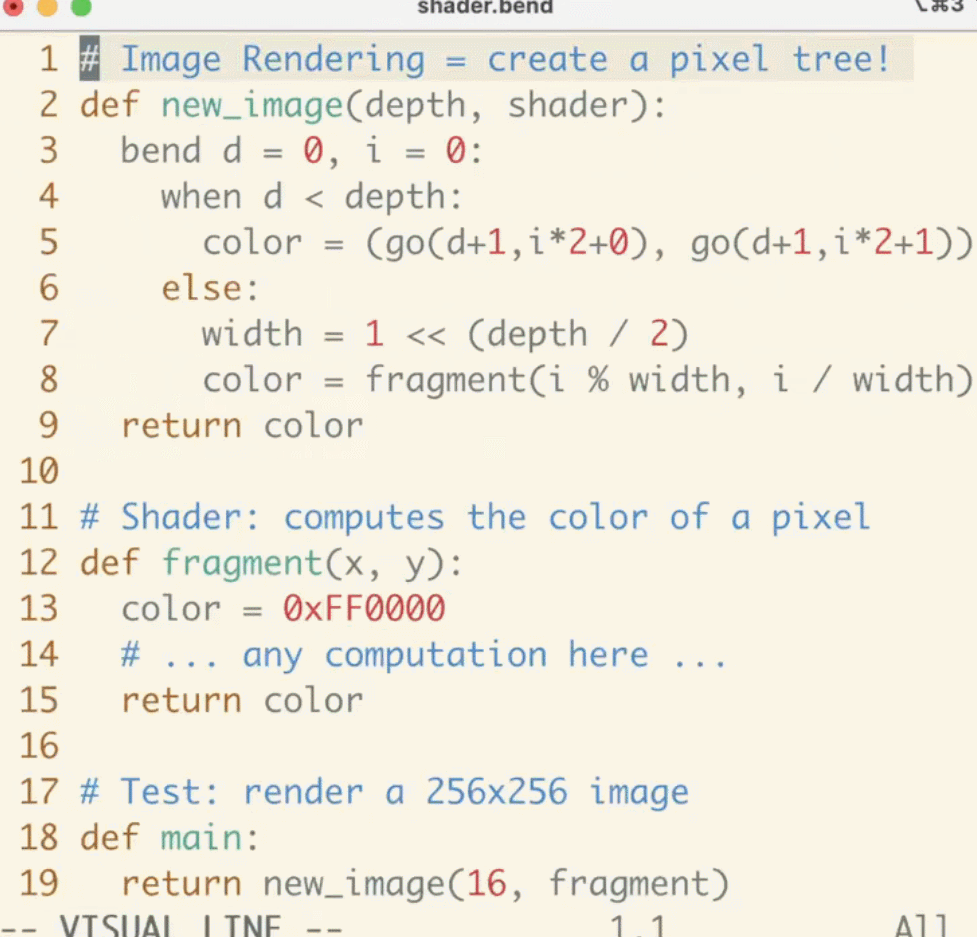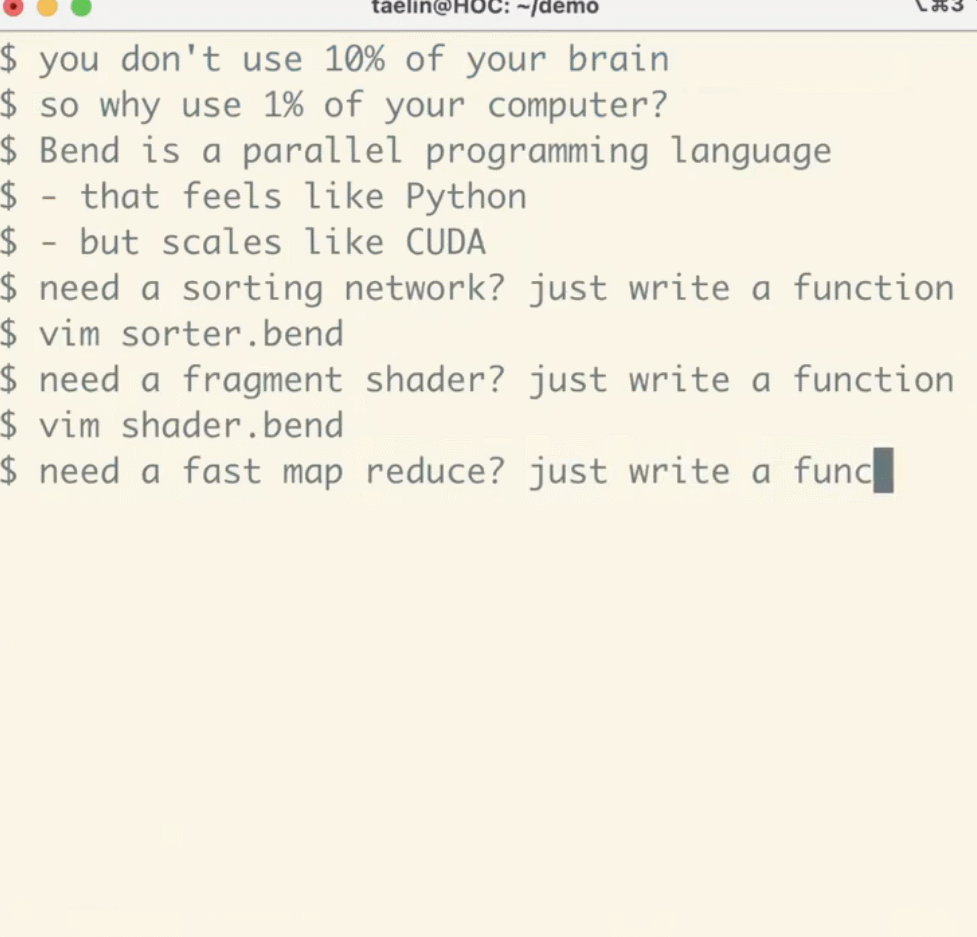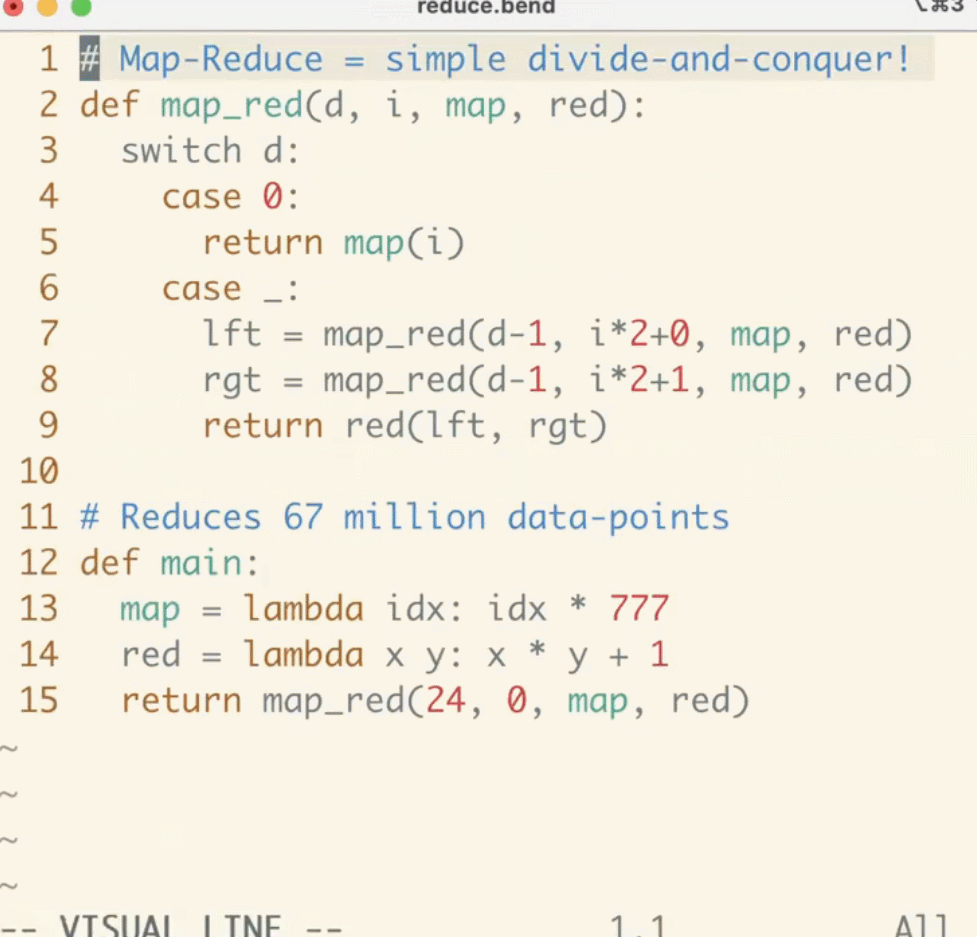
Bend is not limited to specific paradigms, such as tensors or matrices. Any concurrent system, from shaders to class Erlang’s actor model, can be simulated in Bend. For example, to render an image in real-time, we can simply allocate an immutable tree on each frame:
# given a shader, returns a square imagedef render (depth, shader): bend d = 0, i = 0: when d < depth: color = (fork (d+1, i*2+0), fork (d+1, i*2+1)) else: width = depth / 2color = shader (i % width, i /width) return color# given a position, returns a color# for this demo, it just busy loopsdef demo_shader (x, y): bend i = 0: when i < 5000: color = fork (i + 1) else: color = 0x000001return color# renders a 256x256 image using demo_shaderdef main: return render (16, demo_shader)It does work, even if the algorithms involved can parallelize well on Bend. Long-distance communication is executed through global beta reduction (based on interactive calculations) and is correctly and efficiently synchronized through HVM2’s atomic linker.
Finally, the author states that Bend is currently just the first version and has not yet invested much effort into a suitable compiler. Everyone can expect significant performance improvements with each future version. For now, we can use the interpreter to get a glimpse of large-scale parallel programming from the perspective of a high-level Python-like language.
References:
https://news.ycombinator.com/item?id=40390287
https://x.com/VictorTaelin?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
https://x.com/DrJimFan/status/1791514371086250291

© THE END
For reprints, please contact this public account for authorization
For submissions or inquiries: [email protected]