Keywords: Microrobots, Biomedical Engineering, Reinforcement Learning


Paper Title: Autonomous 3D positional control of a magnetic microrobot using reinforcement learning Journal: Nature Machine Intelligence Paper Link: https://www.nature.com/articles/s42256-023-00779-2
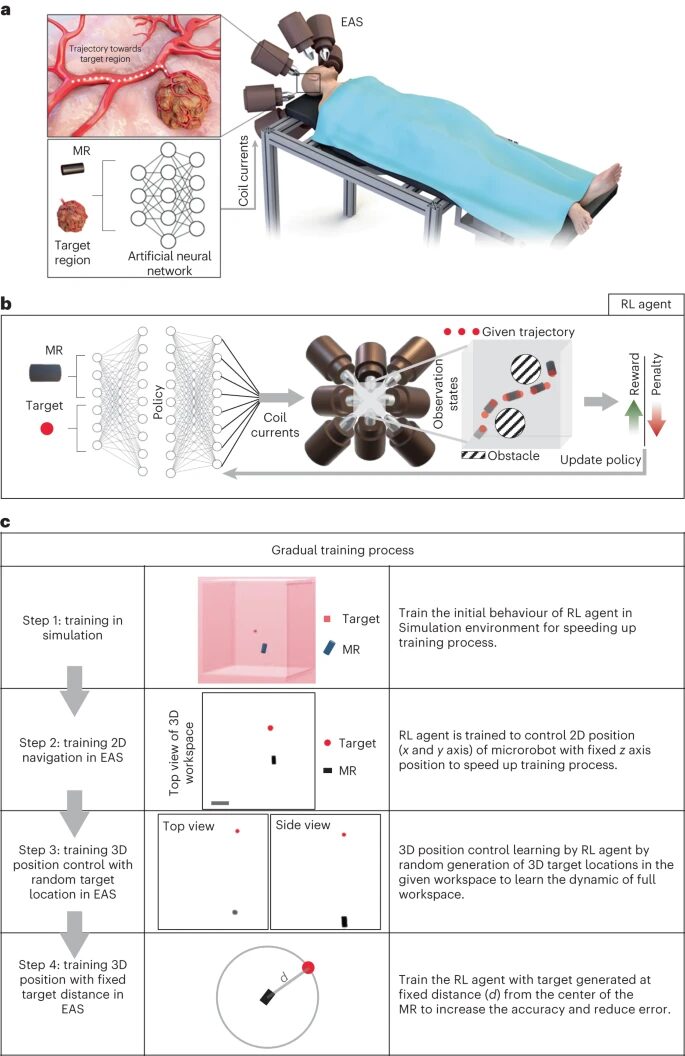
Figure 1 a, Navigation of magnetic microrobots based on reinforcement learning. This study developed an autonomous method to navigate microrobots in complex environments using reinforcement learning to control the external actuation system (EAS). b, The RL agent precisely controls the position of the MR by changing the EAS coil current. The MR reaches the target position PT in the least number of steps according to the policy π (neural network, part of the RL agent), while maintaining within the defined workspace region of interest (ROI). c, A four-step training process was adopted in this study to reduce the training time of the agent and improve accuracy. This aids in initial exploration and gradually increases complexity, ensuring accurate navigation.
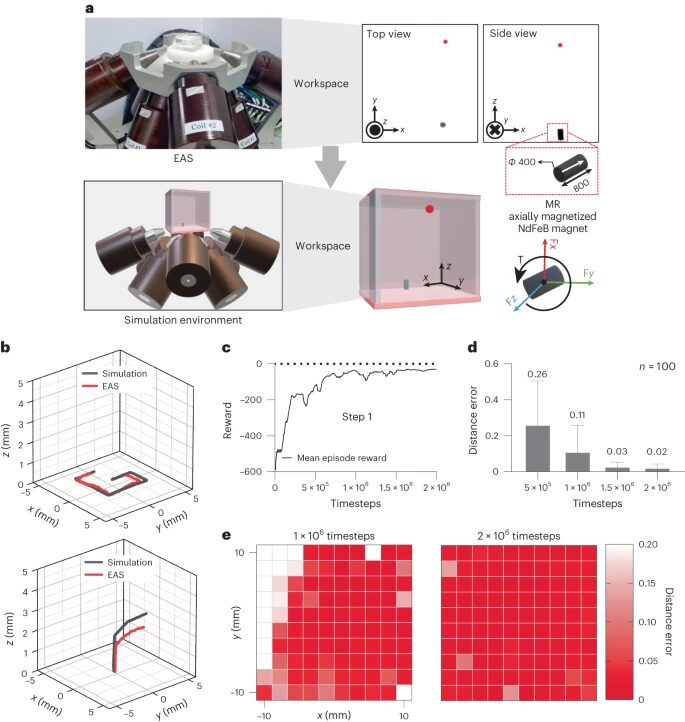
Figure 2 Evaluation and training results in a simulation environment. a, A simulation environment developed in Unity 3D for an EAS with eight coils and a magnetic microrobot (a permanent magnet with a south-to-north magnetization direction, as indicated by the white arrow) immersed in 350cSt silicone oil, with NdFeB representing neodymium-iron-boron material. b, Environment evaluation. c, Training results of the reinforcement learning agent model in the first step of the training process, represented by the average reward value changing over time steps. d, Distance error (distance from the microrobot to the target point) changes as the reinforcement learning agent navigates through different training steps. e, A heatmap of distance error across the entire workspace.
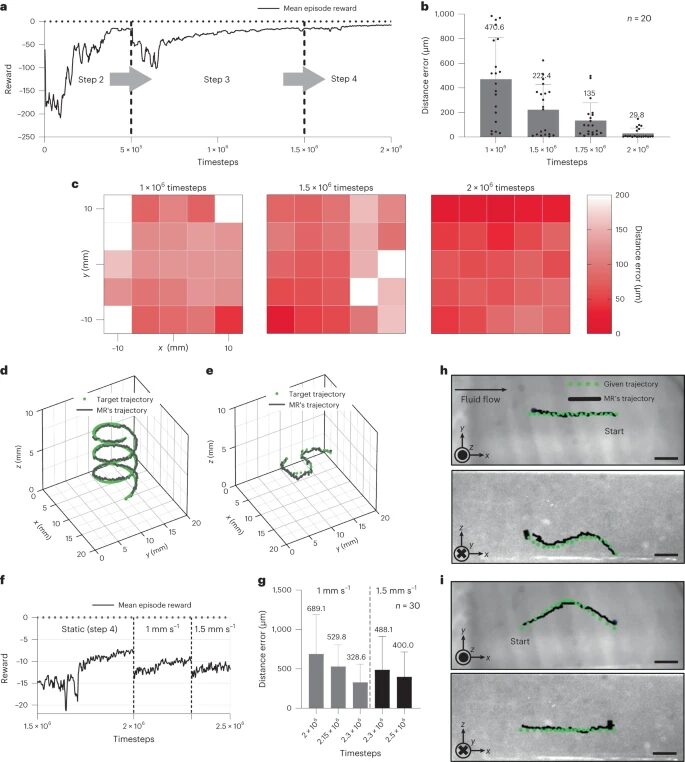
Figure 3 Retraining the reinforcement learning agent model using EAS (real environment). a, The RL agent was retrained with EAS for 2×106 time steps, with training conditions changed after each saturation point (steps 2-4). b, Distance error (distance from the microrobot to the target point) changes as the reinforcement learning agent navigates the MR through various training intervals. c, A heatmap of distance error across the entire workspace. d, The spiral trajectory given to the reinforcement learning agent for navigating the microrobot. This task involves changes across three axes, validating the agent’s performance. e, The MR navigates along an S-shaped trajectory in the xy-plane; the z-axis is fixed. This method validates the hovering capability of the reinforcement learning agent. f, The RL agent was retrained under fluid flow conditions, involving 300,000 and 200,000 time steps at fluid speeds of 1 mm/s and 1.5 mm/s respectively. g, Distance error during retraining in a dynamic fluid environment at two different speeds. h, Navigation against fluid flow (1 mm/s). i, Navigation with fluid flow (1 mm/s).
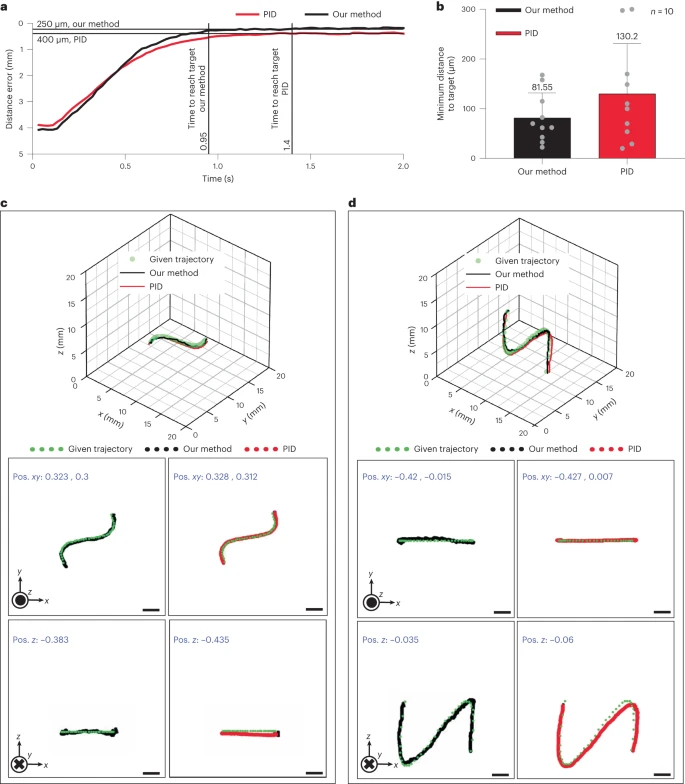
Figure 4 Comparison of the method with closed-loop control using PID controller. a, Using both methods, a target point 4mm away from the current MR position was created to evaluate the time required to reach the target point. b, The accuracy was compared by navigating the MR to random target points and recording the minimum distance to the target point. c, Trajectories used to compare the hovering performance (fixed z-axis). d, Trajectories used to assess performance under gravity (fixed y-axis).
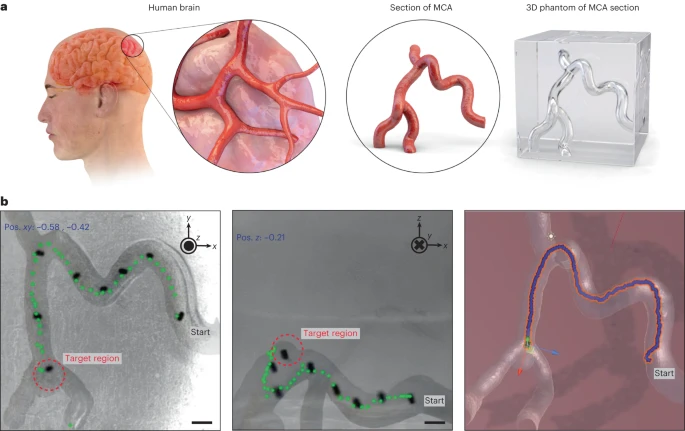
Figure 5 Navigating MR in a cerebral vascular simulation model. a, A scaled replica of the MCA cross-section as a cerebral vascular simulation model, used to evaluate the performance of the RL agent as a potential medical application. b, The RL agent navigates from a specified starting point to the target point, which is an aneurysm within the simulation model.
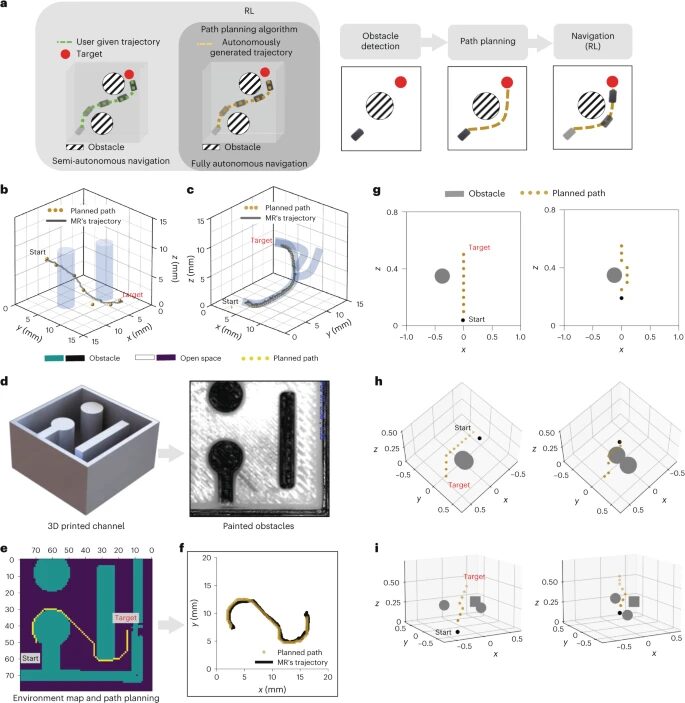
Figure 6 Fully autonomous control of MR in different environments. a, The RL agent generates optimal currents for 3D closed-loop position control (assuming nonlinear systems and nonlinear environments) as the “brain” (the navigation trajectory is human-selected). The RL agent merges with path planning algorithms to generate trajectories towards the target; this constitutes fully autonomous control. b, c, Two different MR navigation scenarios using trajectories generated by A*: the first includes virtual obstacles (two cylinders) (b), and the second includes a 3D virtual channel (c). d, Environmental mapping using image processing to detect obstacles and open spaces. A cube channel with obstacles was used to test path planning and navigation. e, Results of path planning. f, Navigating through a channel with physical obstacles. g, h, i, MR navigation encountering a single dynamic obstacle (g), two dynamic obstacles (h), and two dynamic obstacles plus one static obstacle (i).
Reading Club on Large Language Models and Multi-Agent Systems

Click “Read Original” to Register for the Reading Club