
Application Architecture
The rapid development of the Internet is driven by commercial economics. Currently, almost all commercial applications are based on the Internet, and they generally use C/S architecture, B/S architecture, or M/S architecture.
C/S stands for Client-Server.
B/S stands for Browser-Server.
M/S stands for Mobile-Server.
HTTP Protocol
Currently, 90% of network transmissions on the Internet are based on the HTTP protocol.
HTTP stands for Hyper Text Transfer Protocol. It is a protocol used to transfer hypertext from World Wide Web (WWW) servers to local browsers.
HTTP is a protocol based on TCP/IP for transmitting data (HTML files, image files, query results, etc.).
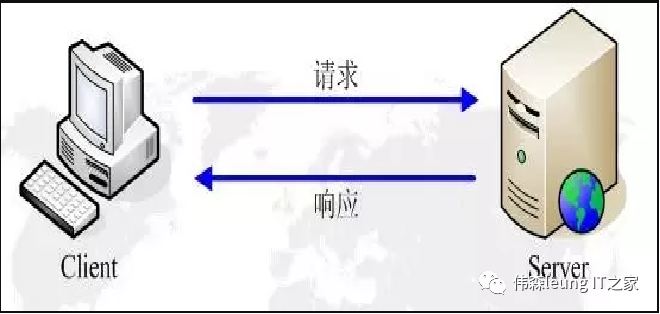
HTTP Request Process
The basic process of an HTTP request is that the client initiates a request to the server, and the server returns a response to the client after receiving it. Therefore, a complete HTTP request consists of both a request and a response. The default port for the HTTP protocol is port 80.
URL
When sending an HTTP request, the URL is used to locate network resources.
URL (Uniform Resource Locator) is used to identify the address of a resource, which is commonly referred to as a website address. Taking the following URL as an example, we will introduce the components of a typical URL:

HTTP Request Format
HTTP Request
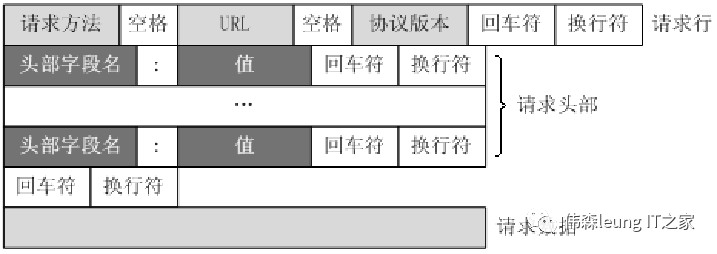
The request message sent by the client to the server includes the following parts: request line, request headers, an empty line, and request data.
The following image shows the general format of a request message.

HTTP Request Methods
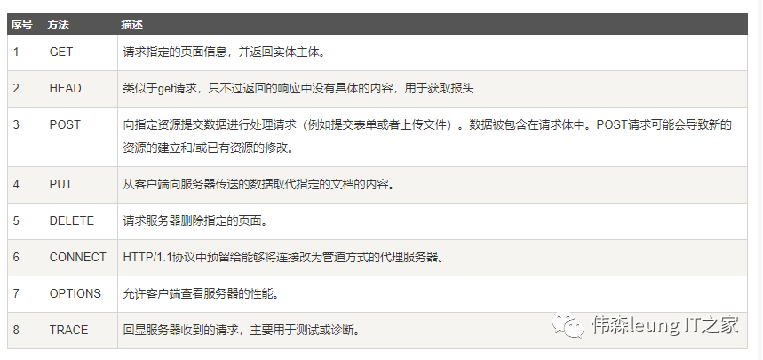
According to the HTTP standard, multiple request methods can be used in HTTP requests.
Version 1.0 defines three request methods: GET, POST, and HEAD methods.
Version 1.1 introduced five additional request methods: OPTIONS, PUT, DELETE, TRACE, and CONNECT methods.
The commonly used methods are GET and POST.
– `GET`
In simple terms, the `GET` method is generally used to retrieve data or to pass some short data through URL parameters to the server. It is more efficient and convenient than `POST`.
– `POST`
Since the `GET` method can carry a maximum of 1024 bytes of data in the URL, and passing data in the URL is not secure, especially when the data volume is large, the URL can become lengthy. Therefore, when transmitting large amounts of data or data that requires high security, it is best to use the `POST` method.
HTTP Request Headers


