Click the blue text
Follow us
Follow and star
Never get lost again
Computer Vision Research Institute

Public Account ID|Computer Vision Research Institute
Learning Group|Scan the code on the homepage to get the joining method
Article link:https://link.springer.com/article/10.1186/s13640-021-00559-1
Column of Computer Vision Institute
Computer vision is an interdisciplinary field used for target detection. Target detection is a crucial part of assisting monitoring, vehicle detection, and pose estimation.
PART/1
Overview
In this study, we propose a novel deep You Only Look Once (deep YOLOV3) method for multi-target detection. This method focuses on the entire frame image during training and testing phases, employing a regression-based technique to locate targets using a probabilistic model. In this process, we constructed 106 convolutional layers, followed by 2 fully connected layers, and used an input size of 812×812×3 to detect small drones. We first pre-trained the convolutional layers at half resolution, then doubled the resolution for detection. The number of filters in each layer was set to 16, with the last scale layer having more than 16 filters to enhance small target detection performance. This structure employs upsampling techniques to improve unnecessary spectral images into existing signals and rescales features at specific locations, significantly enhancing the detection capability of small targets and effectively increasing the sampling rate. The reason for choosing this YOLO architecture is that it focuses more on reducing memory resources and computational costs compared to having more filters. The proposed system is designed and trained specifically for detecting and tracking a single category, “drone” based on an embedded system’s deep YOLO implementation. This YOLO method can predict multiple bounding boxes for each grid cell with higher accuracy. We trained the model using a large number of small drones in various scenarios (such as open fields and complex background marine environments).
PART/2
Background
Drones are increasingly used in various fields, especially in military and surveillance applications, to perform precision tasks in specific scenarios. Real-time detection of drones is crucial for security assurance. Achieving real-time detection of drones in various environments such as rainy days, bright light, and nighttime remains a significant challenge. Deep learning plays a key role in target detection under different conditions. Recently, computer vision and deep learning methods (such as R-CNN, Faster R-CNN, and Mask-RCNN) have provided solutions for target detection. Target detection and tracking systems have been widely applied in military, medical fields, and security monitoring scenarios equipped with autonomous robots. Traditional target recognition mainly relies on edges, cuts, and template assumptions, which have low accuracy and high error rates. Additionally, content-based image retrieval (CBIR) employs various feature extraction methods combined with filtering techniques to process detected targets to ensure recognition. Gradient histograms are used in image classifiers, while local binary patterns scan target images through sliding window assumptions. Machine learning techniques enhance image accuracy using handcrafted features (such as PASCAL VOC target detection), but all these mechanisms still face challenges in target tracking in embedded system monitoring scenarios. To overcome these issues, researchers have proposed various deep learning models to improve detection accuracy. R-CNN, Faster R-CNN, and Mask-RCNN deep learning models are not suitable for fast detection of small targets. This paper proposes a novel deep YOLOV3 algorithm for small target detection. This method achieves detection of small drone targets through confidence scoring, backbone classifiers, and multi-scale predictions. The deep YOLOV3 has the following mechanisms for small drone detection:
The contributions of this paper are as follows:
-
Propose the deep YOLOV3 algorithm to quickly address the small target detection problem.
-
Calculate confidence scores based on conditional probabilities for detecting the bounding boxes of target objects.
-
Utilize backbone classifiers and multi-scale predictions to achieve high-precision classification of targets, enhancing monitoring accuracy.
-
The proposed deep YOLOV3 model achieves a detection accuracy of 99.99% for small drones, with low error rates.
Deep learning-based target detection has achieved different levels of accuracy. Song Han et al. pointed out that low-cost aerial photography can obtain high-brightness images and videos through advanced drones but is prone to errors. They proposed a deep drone solution based on an embedded system framework, focusing on the visual and automatic tracking capabilities of drones. At the hardware level, using GPU (such as NVIDIA GTX 980) and embedded GPU (such as NVIDIA Tegra K1, Tegra X1) for tracking and detection, the embedded configuration’s frame rate, accuracy assessment, and power consumption analysis show a tracking speed of 1.6 fps. Redman et al. proposed a new application of the YOLO detector, transforming target detection and classification into bounding box regression problems and association probability calculations. Some studies proposed end-to-end neural networks for probabilistic classification analysis, while Faster R-CNN has been widely used for target detection.
Krizhevsky et al. found that deep neural networks are widely used in computer vision for binary classification and multi-image classification analysis. The classic network tool AlexNet contains 8 layers and 60 million connections, followed by the emergence of VGGNet. Szegedy et al. proposed GoogleNet, which supports different scale zooming through CNN with convolutional layers designed with 1×1, 3×3, and 5×5 kernel levels, solving gradient issues through multi-layer cross connections. He et al. proposed ResNet to enhance image recognition accuracy by strengthening absolute values through cross-layer connections; SqueezeNet is applied to CNN to achieve higher accuracy with 50 times fewer connections.
Henriques et al. emphasized kernelized correlation filters (based on DFT) for image classification detection, combining fast algorithms to achieve diagonal transformation, allowing the tracker to reach 70 frames/ second on the NVIDIA TK1 suite. Sabir Hossain et al. pointed out that target detection and tracking of aerial images can be achieved through smart sensors and drones, proposing an embedded framework based on deep learning (such as Jetson TX or AGX Xavier paired with Intel Neural Compute Stick). Flying drones are limited by coverage, so they need to rely on GPU embedded computing capabilities to improve accuracy through multi-target detection algorithms. Deep SORT employs Kalman filtering assumptions for tracking, combined with multi-rotor drone association metrics.
Roberto Opromolla pointed out that drones have various applications in civilian and military fields, achieving frame sequence tracking and detection of cooperative targets (based on deep learning) through visual cameras. YOLO as a target detection system requires its processing architecture to integrate machine vision algorithms with cooperative prompts into flight tests of two multi-rotor drones, achieving both accuracy and robustness in detecting target range vulnerabilities in complex environments.
Christos Kyrkou et al. proposed a trade-off mechanism for single-stage target detectors based on deep CNN, where drones detect vehicles in specific environments, providing an overall optimization scheme for drone deployment. Aerial images run at 6-19 frames/ second on low-power embedded processors, achieving an accuracy of 95%. Tsung-Yi Lin et al. pointed out that RetinaNet utilizes backbone networks for target detection, supporting classification and regression; the backbone network combines convolutional features of input images, while Faster R-CNN uses feature pyramid networks (FPN), calculating the probability of target presence through pyramid-level C channel feature mapping, A anchor boxes, and N target classes with ReLU activation.
Yi Liu et al. emphasized the application of drones in detecting power transmission equipment, where deep learning algorithms need to focus on drone transmission control. Mask R-CNN processes transmission equipment components (applied to wireless communication) through edge detection, hole filling, and Hough transformation, achieving 100% detection accuracy based on drone transmission parameters.
LIY et al. proposed multi-block single-stage multi-box detectors (SSD) for small target detection in drone railway track monitoring, segmenting input images into patches and processing truncated targets through two-stage sub-layer detection (including sub-layer suppression and training sample filtering). For bounding boxes not detected by the main layer, improvements to SSD significantly enhance detection rates; this deep learning model is also used for landslide labeling and key communication scenarios in rainy weather.
Jun-Ichiro Watanabe et al. applied YOLO to marine environmental plastic (microplastics and macroplastics) protection, achieving global environmental monitoring through satellite remote sensing technology combined with surface target trackers. Autonomous robots are used for marine environmental target observation control, and underwater ecosystem research employs deep network learning algorithms, with YOLOv3 achieving an accuracy of 77.2%. Kaliappan et al. proposed machine learning techniques such as clustering and genetic algorithms for load balancing; Vimal et al. proposed a Markov model based on machine learning for energy optimization in cognitive radio networks; Aybora et al. simulated labeling errors in YOLOv3 target detection, analyzing errors in training and testing phases; Sabir et al. designed a GPU-based embedded flying robot, utilizing deep learning algorithms for real-time multi-target detection and tracking of aerial images.
PART/3
New Algorithm Framework Analysis
The goal of the proposed model is to analyze target detection in real-time environments through a novel YOLOV3 model and make motion decisions using bounding boxes within boundary coordinates. YOLOv3 employs a hybrid method with Darknet and residual networks, offering superior feature extraction capabilities compared to YOLOv2. Images are captured and segmented within bounding box layer coordinates, and in the new YOLOV3 model, these coordinates are mapped to the boxes at frame intervals per second. The model applies deep convolutional neural networks (DCNN) to achieve high-precision predictions, processing frame pixels on a per-pixel basis using different filter sizes of 32, 64, 128, 256, and 1024 combined with stride and padding operations. Different convolutional layers adopt various sizes of kernelized correlation filter (KCF) schemes, which typically run extremely fast in video processing. CNN layers segment images into multiple regions, predicting accurate bounding boxes based on the confidence scores of all segmented regions. The proposed YOLOv3 is trained on a Dell EMC workstation, which is configured with: two Intel Xeon Gold 5118 core processors, six-channel 256GB 2666MHz DDR4 ECC memory, 2×NVIDIA Quadro GV100 GPU, 4×1TB NVMe 40 SSDs, and 1TB SATA HDD.
Research Plan
This study proposes a novel YOLOV3 deep learning embedded model for small target detection in real-time systems. YOLO can process the entire image in a single instance to predict bounding box coordinates and calculate the class probabilities of all bounding boxes. YOLO can process 45 frames per second, and this study employs deep convolutional neural networks (DCNN) to achieve high-precision predictions.
The above image shows the deep YOLOV3 prediction model used for predicting drones, with the marked input image trained for 45,000 rounds. Each area is a 7×7 grid, capable of predicting 5 bounding boxes, and this model can simultaneously detect drone targets. The proposed embedded YOLO algorithm predicts target categories and bounding box coordinates for specific target locations through a regression mechanism in a single-pass processing of the entire image.
This paper designs a deep convolutional neural network (DCNN) containing 106 convolutional layers, integrating convolutional layers, pooling layers, and fully connected layers with classification functions. By sliding filters along the input image to compute feature maps, a two-dimensional matrix is ultimately generated. The following image shows the sample feature maps computed in the convolutional layers.
PART/4
Experiments and Visualization
This paper downloaded approximately 2GB of 3000 drone images from the Kaggle dataset and Google. In the proposed YOLOv3 model, the drone dataset was trained for 45,000 rounds to achieve high accuracy and sensitivity. Figure 3 shows sample images of drones used for training and testing. This study employed a pre-trained YOLOv3 model for training and implemented the YOLOv3 algorithm on a GPU-based workstation.
The input images were trained using the pre-trained YOLOv3 model with 106 convolutional layers, taking over 8 hours to build the model. The trained YOLO model can accept image or video input, achieving an accuracy of 99.99% in detecting drone images/videos.

The above image shows the detection effect on drone videos during the testing phase. Table 1 compares the accuracy of three models: YOLO, YOLOv2, and YOLOv3: YOLO and YOLOv2 are suitable for fast detection of large targets, while the proposed YOLOv3 architecture, due to its hybrid network structure, is more suitable for small target detection.
The proposed deep YOLOV3 model achieved an accuracy of 99.99% during training and testing phases, thanks to its design of 106 convolutional layers and different size feature maps. The study also used the YOLOv2 model for training and testing, achieving an accuracy of 98.27%, which relies solely on residual networks for target detection. Furthermore, the YOLOV3 model also designed a confidence scoring mechanism based on conditional probabilities to effectively predict target objects.
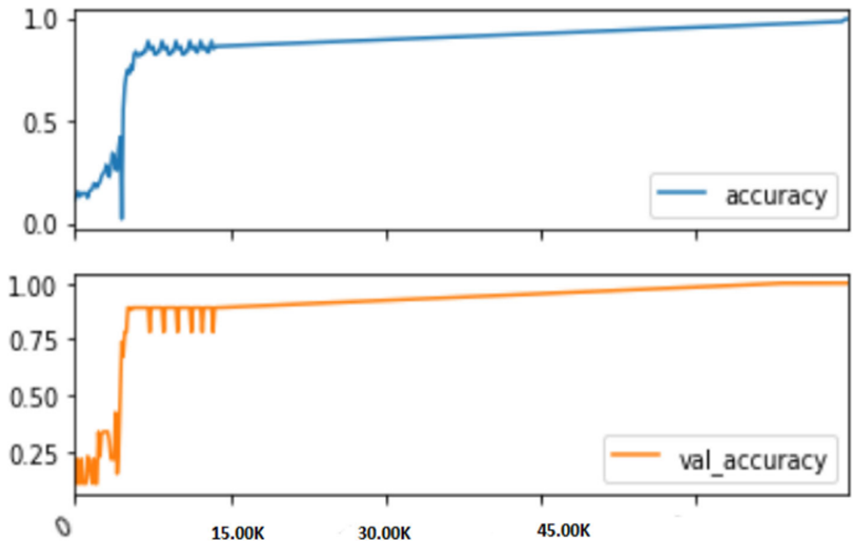
The above image shows that the model achieved a very high accuracy at the end of the training cycle. The proposed method also employs a backbone classifier to achieve precise classification of targets.
Conclusion
This study proposes a novel deep YOLOV3 model for small target detection, utilizing a pre-trained YOLOV3 combined with drone images for model training. Simulation results indicate that the proposed deep YOLOV3 model is suitable for computer vision processing. The model is designed with 106 convolutional layers and multi-scale feature maps to learn the features of small drone targets. YOLOv3 achieves superior feature extraction capabilities by combining Darknet with residual networks, reaching high detection accuracy after 45,000 rounds of training.
The scheme utilizes Intersection over Union (IOU) to synchronize the prediction of bounding boxes and confidence scores of grid cells, employing logistic classifiers and binary cross-entropy loss functions to optimize small target detection. Deep YOLOV3 achieves a detection accuracy of 99.99% through multi-scale predictions and backbone classifiers, with various loss analyses indicating that the model constructs a reliable confidence scoring mechanism based on conditional probabilities, ensuring precise predictions of target bounding boxes. Compared to older versions like YOLO and YOLOv2, YOLOv3 has weaker adaptability for detecting large targets.
Future research could expand the algorithm to train on massive small drone data in complex visible conditions and remote area scenarios.