
Multiple Papers from the School of Computer Science Selected for the Top Conference in Systems, USENIX ATC 2024
USENIX ATC stands for the USENIX Annual Technical Conference, which is one of the most important international conferences in the field of computer systems, enjoying a high academic reputation globally and is recommended as an A-class conference by CCF. Since its inception in 1992, it has successfully held over 30 sessions, attracting submissions from top universities, research institutions, and companies worldwide. This year, the conference received 488 paper submissions, of which 77 were accepted, resulting in an acceptance rate of only 15.8%, the lowest in recent years.
The School of Computer Science has had 4 papers accepted by USENIX ATC, covering multiple research areas. Below is a brief introduction to the papers:
1. A Framework for Hot Bloat Mitigation in Virtualized Environments
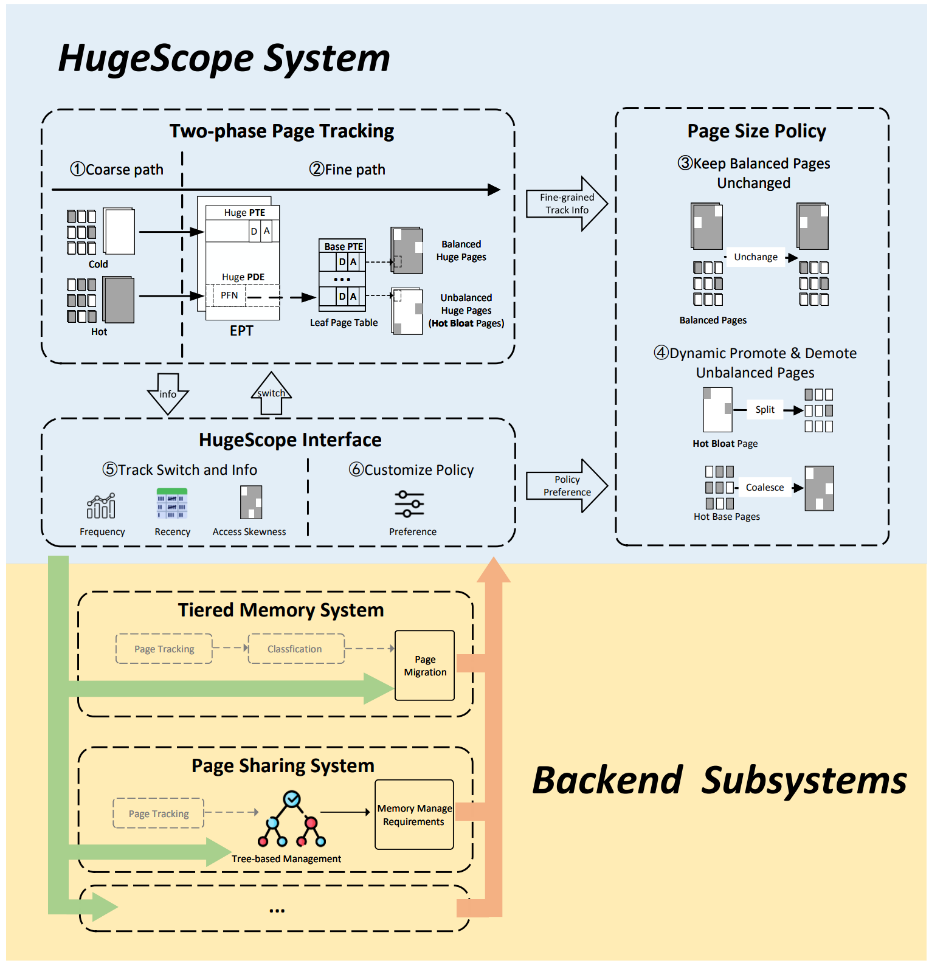
Large pages are widely used in virtualized environments to enhance two-level address translation efficiency. However, aggressive use of large pages can lead to the issue of hot bloat, where a large page that is heavily accessed in a small page region is incorrectly identified by the hypervisor as a hot large page. Solutions to the hot bloat problem have been proposed in non-virtualized environments, but they require trade-offs in accuracy, performance, and hardware modifications. In fact, in virtualized environments, hot bloat can significantly impact performance and resource utilization across more application scenarios. To address this challenge, the paper “Taming Hot Bloat Under Virtualization with HugeScope” proposes the first framework for mitigating hot bloat in virtualized environments, called HugeScope. The core idea of the paper is to leverage the stable characteristics of the second-level address space provided by virtualization, ensuring that the EPT is rarely modified and is always accessed through a stable software interface. HugeScope achieves this by: 1) utilizing inconsistently split EPT page tables to create a low-overhead, high-accuracy small page granularity monitoring mechanism, adding code hooks to the EPT access interface for security, thus obtaining access information at the small page granularity within large pages; 2) abstracting the system’s hot page bloat rate based on page frequency, recency, and skewness, allowing for comprehensive and dynamic decision-making and adjustment of page sizes; 3) providing a modular interface to support different management subsystems. Compared to existing mechanisms, HugeScope can achieve a 61% performance improvement in layered memory scenarios and a 41% increase in memory resource sharing in page sharing scenarios. The first author of this paper is Li Chuan Dong, a PhD student from the 2021 cohort at the School of Computer Science (supervised by Professors Wang Xiaolin and Luo Yingwei), with co-authors including Dr. Sha Sai from Huawei, Zeng Yangqing and Yang Xiran from Peking University, Professors Luo Yingwei and Wang Xiaolin, Professor Wang Zhenlin from Michigan Technological University, and Assistant Professor Zhou Diyu from EPFL/Peking University.
2. User-Space Page Cache with Software-Hardware Coordination
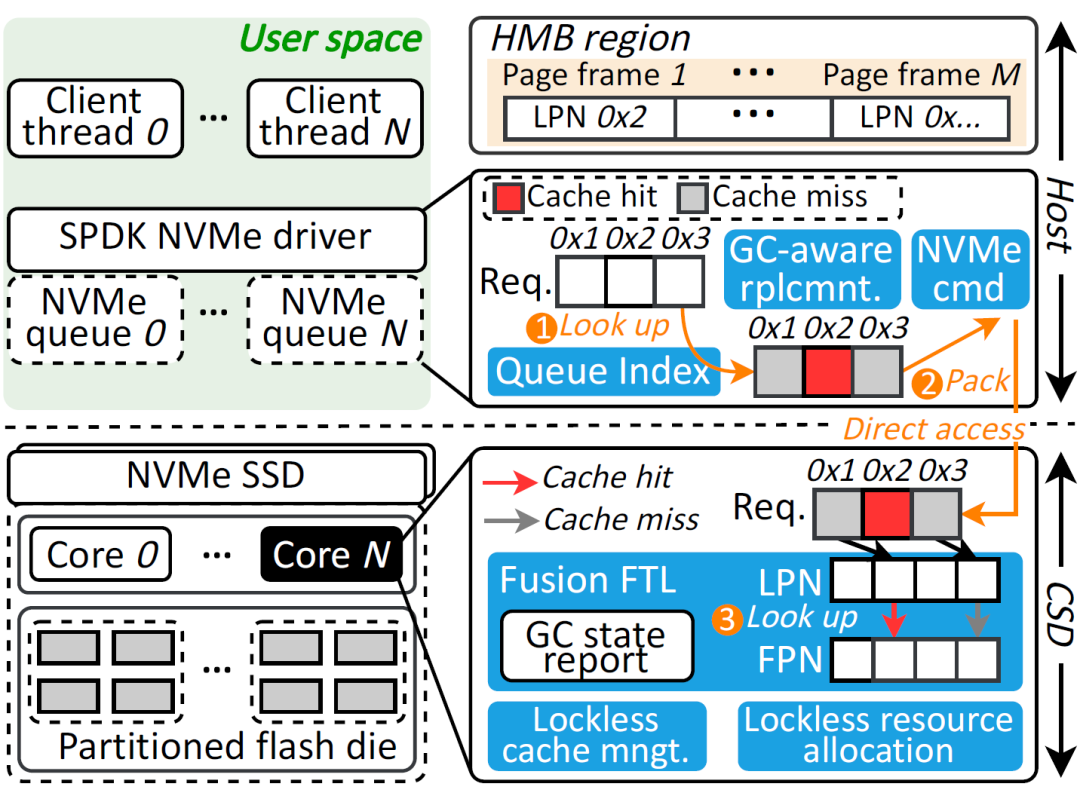
The storage software stack typically integrates a page cache management module that caches hot data in main memory to accelerate application I/O access. However, existing page cache management modules are designed based on a host-centric principle, which leads to issues such as CPU overhead, communication overhead, and SSD garbage collection interference. To address these challenges, the paper “ScalaCache: Scalable User-Space Page Cache Management with Software-Hardware Coordination” proposes a user-space page cache module, ScalaCache, with software-hardware coordination. Specifically, to reduce the overhead on host CPU resources, ScalaCache offloads cache management to computational solid-state drives (Computational SSD, CSD) and further merges the index structures in the cache management module with the flash translation layer in the CSD firmware to achieve lightweight cache management. To further enhance performance scalability, ScalaCache designs a lock-free resource management framework that allows multiple CSD cores to concurrently manage the cache. Additionally, ScalaCache aggregates the computational capabilities of multiple CSDs to achieve performance scalability based on the number of CSDs. ScalaCache also reduces communication overhead by simplifying the I/O control path and designs a garbage collection-aware replacement strategy to mitigate interference caused by garbage collection. Compared to the Linux kernel page cache and state-of-the-art user-space cache management modules, ScalaCache achieves a bandwidth improvement of 3.38 times and 1.70 times, respectively. The first author of this paper is Peng Li, a PhD student from the 2023 cohort at the School of Computer Science, with Assistant Professor Zhang Jie as the supervisor and corresponding author, and co-authors including Associate Researcher Zhou You from Huazhong University of Science and Technology, Associate Researcher Wang Chenxi from the Institute of Computing Technology, Chinese Academy of Sciences, Associate Professor Li Qiao from Xiamen University, and Dr. Cheng Chuan Ning from Huawei.
3. User-Space All-Flash Array Engine Based on Software-Hardware Collaborative Design
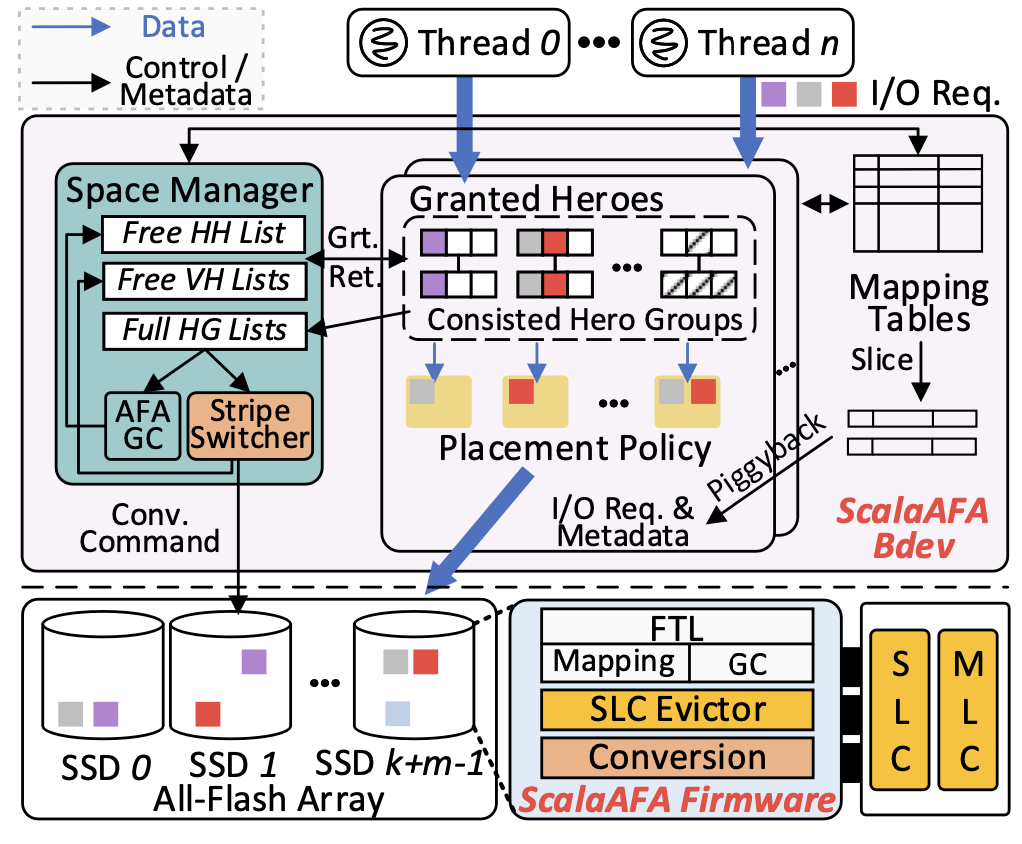
Compared to disks, flash memory has been widely used in data centers, high-performance computing, and mobile devices due to its high performance. However, a single flash memory cannot meet the growing demands for reliability, large capacity, and high throughput. Building an all-flash array using multiple flash memories, utilizing striping techniques to increase bandwidth while providing fault tolerance through checksums, is a feasible solution to this problem. However, existing flash array frameworks suffer from significant software overhead, which becomes a key factor limiting the performance and scalability of all-flash arrays. The paper “ScalaAFA: Constructing User-Space All-Flash Array Engine with Holistic Designs” proposes a solution to this problem using a software-hardware collaborative design approach. On one hand, it integrates the all-flash array engine into user space and designs a lock-free inter-thread synchronization scheme to reduce the overhead of the storage software stack. On the other hand, it decentralizes the tasks of checksum generation and offloads them to the flash memory, utilizing the built-in computational resources of the flash for processing. Additionally, ScalaAFA designs an innovative data layout scheme that cleverly avoids the overhead of data movement during checksum generation. ScalaAFA also leverages the architectural advantages of flash memory to address the metadata persistence and write amplification issues of all-flash arrays. The first author of this paper is Yi Shushu, a PhD student from the 2022 cohort at the School of Computer Science, with Assistant Professor Zhang Jie as the supervisor and corresponding author, and co-authors including Pan Xiurui from Peking University, Associate Professor Li Qiao from Xiamen University, Professor Mao Bo, Associate Researcher Wang Chenxi from the Chinese Academy of Sciences, Dr. Li Qiang from Alibaba, and Associate Professor Myoungsoo Jung from KAIST.
4. Efficient Decentralized Federated Singular Value Decomposition
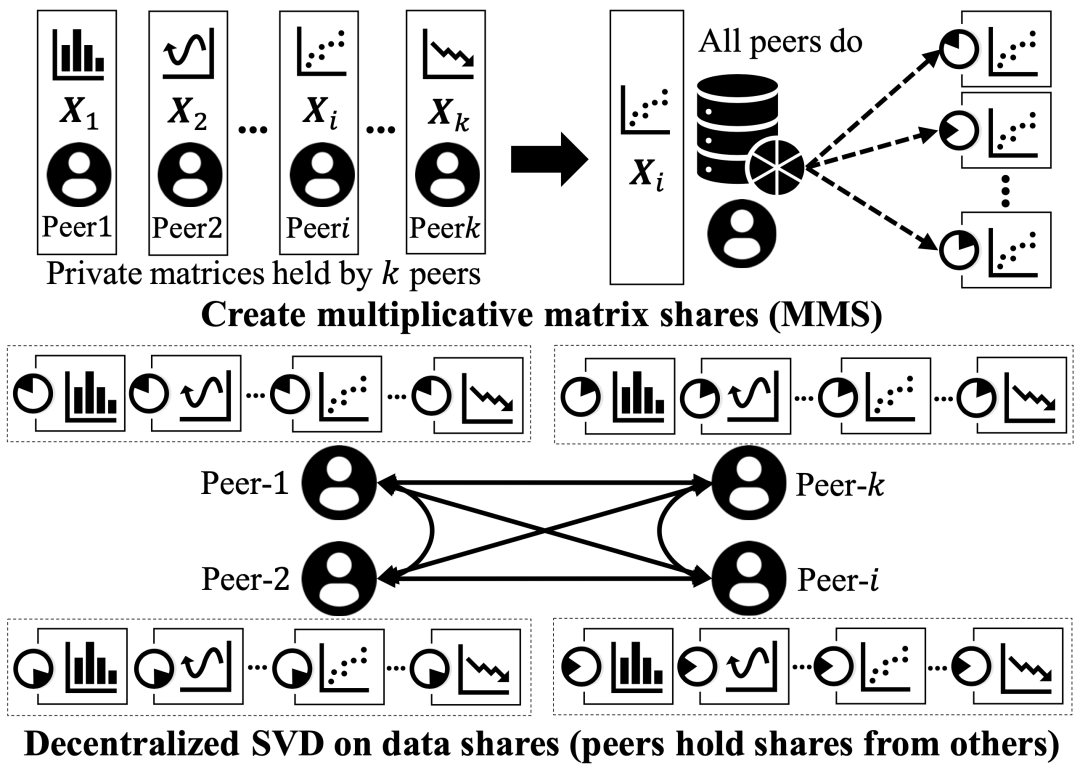
Federated Singular Value Decomposition (SVD) is fundamental to many distributed applications. For example, it is used to decompose large-scale genomic data held by multiple parties for genome-wide association studies (GWAS), to decompose large-scale user profiles held by banks and internet companies for feature dimensionality reduction (PCA) and linear regression modeling (LR), and to decompose large-scale document data held by multiple parties for latent semantic analysis (LSA). However, existing federated SVD solutions either rely on external servers, posing significant security risks, or use homomorphic encryption techniques to eliminate the need for external servers (i.e., decentralization), but this leads to significant efficiency losses due to extensive computation and communication overhead. This paper proposes Excalibur, an efficient, decentralized federated SVD system. The core design of Excalibur consists of two parts. First, Excalibur proposes a lightweight, decentralized matrix protection method to reduce performance degradation caused by encryption operations. Additionally, by conducting a quantitative analysis of the communication in the design space of decentralized SVD systems, a communication-efficient decentralized SVD workflow is designed, significantly optimizing communication performance. To validate the efficiency of Excalibur, we implemented a fully functional prototype system and conducted extensive testing on practical applications based on SVD. The results show that Excalibur not only eliminates the need for external servers but also outperforms current state-of-the-art server-assisted SVD systems by 3 to 6 times on billion-scale matrices of various shapes. Furthermore, Excalibur’s throughput is over 23,000 times greater than that of the most advanced homomorphic encryption SVD systems. The first author of this paper is Chai Di, a PhD student from the Hong Kong University of Science and Technology, with co-authors including Professors Chen Kai and Yang Qiang from the Hong Kong University of Science and Technology, and Assistant Professor Wang Leye from Peking University.



Scan to Follow
iPKU-CS1978
WeChat ID|iPKU-CS1978
Website|https://cs.pku.edu.cn/
Twitter & Instagram|PKUCS1978