1. Introduction: Why is Chaos Engineering Needed?
In the cloud-native era, system complexity is growing exponentially, and traditional testing methods can no longer cover all failure scenarios. Chaos Engineering is a proactive experimental approach that injects faults to help us discover system weaknesses before real failures occur in production environments.
As a CNCF incubated project, Chaos Mesh provides rich fault injection capabilities. This article will introduce you to the practical aspects of chaos engineering, focusing on three core fault injection scenarios: node failures, network jitter, and Pod termination experiments..
2. Basic Concepts and Architecture of Chaos Mesh
2.1 What is Chaos Mesh?
Chaos Mesh is an open-source cloud-native chaos engineering platform designed for Kubernetes environments. It simulates abnormal situations that may occur in real production environments by injecting various faults, helping development and operations teams build more resilient systems.
2.2 Core Architectural Components
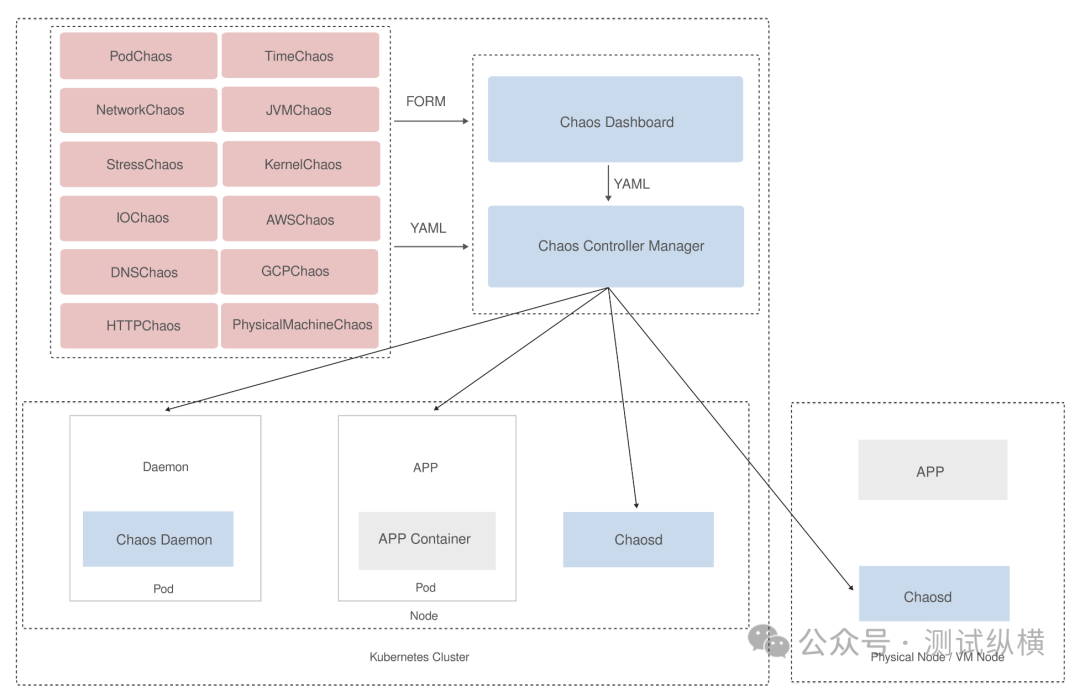
-
Chaos Dashboard: A visual console for creating and managing chaos experiments.
-
Chaos Controller Manager: The core controller responsible for scheduling and managing chaos experiments.
-
Chaos Daemon: Deployed on each node as a DaemonSet, executing specific fault injection operations.
-
Chaos Driver: Implementations of drivers for different types of faults.
2.3 Installation and Deployment
# Install Chaos Mesh using Helm
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm repo update
kubectl create ns chaos-testing
helm install chaos-mesh chaos-mesh/chaos-mesh -n chaos-testingAfter installation, you can access the Dashboard via port forwarding:
kubectl port-forward -n chaos-testing svc/chaos-dashboard 2333:2333Then visit http://localhost:2333 to open the console.
3. Core Fault Injection Practices
3.1 Node Failure Simulation (NodeChaos)
1. Types of Node Failures
Chaos Mesh supports the following node-level faults:
-
Node crash
-
Node restart
-
Kernel panic
-
Resource pressure (e.g., CPU, memory)
2. Experiment Case: Simulating Node CPU Pressure
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: node-cpu-stress
namespace: chaos-testing
spec:
mode: one
selector:
nodes:
- worker-node-1
stressors:
cpu:
workers: 2
load: 100
options: ["--cpu 2", "--timeout 300s"]
duration: "5m"This experiment will simulate 2 CPU processes with 100% load on worker-node-1 for 5 minutes.3. Observation and Verification
# Check node resource usage
kubectl top node worker-node-1
# Check the Pod status on that node
kubectl get pods -o wide | grep worker-node-1Key Metrics:
-
CPU usage
-
Pod response latency
-
Pod eviction status
3.2 Network Jitter Simulation (NetworkChaos)
1. Types of Network Failures
-
Network latency
-
Network packet loss
-
Network corruption
-
Network partition
-
Bandwidth limitation
2. Experiment Case: Network Latency Between Microservices
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: service-latency
namespace: business
spec:
action: delay
mode: all
selector:
namespaces:
- business
labelSelectors:
app: frontend
target:
selector:
namespaces:
- business
labelSelectors:
app: backend
mode: all
delay:
latency: "200ms"
correlation: "25"
jitter: "50ms"
duration: "10m"This simulates a 200ms delay when the frontend service accesses the backend service, with 25% correlation and 50ms jitter, lasting for 10 minutes.3. Observation and Verification
kubectl get networkchaos -n business
kubectl exec -it -n business deploy/frontend -- \
curl -o /dev/null -s -w "%{time_total}\n" http://backend:8080/api/v1/dataKey Metrics:
-
Response time
-
Timeout errors
-
Retry counts
-
Service circuit breaking/downgrade
3.3 Pod Termination Experiment (PodChaos)
1. Types of Pod Failures
-
Pod termination
-
Pod failure
-
Container termination
-
Container failure
2. Experiment Case: Randomly Terminating Database Replicas
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: database-pod-kill
namespace: database
spec:
action: pod-kill
mode: random-max-percent
value: "40"
selector:
namespaces:
- database
labelSelectors:
app: mysql
role: replica
scheduler:
cron: "@every 5m"
duration: "30m"Every 5 minutes, randomly kill up to 40% of the replica Pods, lasting for 30 minutes.3. Observation and Verification
kubectl get pods -n database -l app=mysql,role=replica -w
kubectl logs -n business deploy/api-service -f | grep -i "database\|connection\|mysql"Key Metrics:
-
Pod restart counts
-
Database connection error rate
-
Application retry success rate
4. Best Practices for Chaos Experiment Design
4.1 Principles of Experiment Design
-
Start small
-
Clearly define hypotheses and expected behaviors
-
Set up monitoring metrics in advance
-
Establish termination conditions
-
Prepare rollback mechanisms
4.2 Chaos Experiment Workflow
-
Steady state definition: Determine the baseline metrics for normal system operation.
-
Hypothesis formation: Propose hypotheses about system behavior under failure.
-
Experiment design: Design the minimal experiment that can validate the hypothesis.
-
Experiment execution: Execute the experiment in a controlled environment.
-
Result analysis: Compare experimental results with expected hypotheses.
-
System strengthening: Improve the system based on discovered issues.
4.3 Practical Case: E-commerce System Resilience Testing
Below is a complete chaos experiment design case targeting the critical path of an e-commerce system:
apiVersion: chaos-mesh.org/v1alpha1
kind: Schedule
metadata:
name: e-commerce-resilience-test
namespace: chaos-testing
spec:
schedule: "0 2 * * *" # Execute every day at 2 AM
historyLimit: 5
concurrencyPolicy: Forbid
type: "workflow"
workflow:
entry: "entry"
templates:
- name: "entry"
templateType: Serial
deadline: "60m"
children:
- "network-delay"
- "pause-5m"
- "pod-kill"
- "pause-5m"
- "node-stress"
- name: "network-delay"
templateType: NetworkChaos
networkChaos:
action: delay
mode: all
selector:
namespaces:
- e-commerce
labelSelectors:
app: payment-service
delay:
latency: "500ms"
correlation: "50"
duration: "10m"
- name: "pod-kill"
templateType: PodChaos
podChaos:
action: pod-kill
mode: random-max-percent
value: "30"
selector:
namespaces:
- e-commerce
labelSelectors:
app: inventory-service
- name: "node-stress"
templateType: StressChaos
stressChaos:
mode: one
selector:
nodes:
- "{{env.WORKER_NODE}}"
stressors:
cpu:
workers: 2
load: 80
duration: "15m"
- name: "pause-5m"
templateType: Suspend
deadline: "5m"This workflow will execute in the following order:
-
Inject network delay into the payment service
-
Pause for 5 minutes to observe
-
Randomly kill 30% of the inventory service Pods
-
Pause for another 5 minutes to observe
-
Inject CPU pressure into the worker node
5. Conclusion and Next Episode Preview
5.1 The Value of Chaos Engineering
-
Identify issues early: Discover system weaknesses before real failures occur in production.
-
Validate recovery mechanisms: Ensure the system’s self-healing and fault tolerance capabilities are effective.
-
Cultivate failure awareness: Help teams build sensitivity and response capabilities to failures.
-
Enhance system resilience: Build more reliable systems through continuous testing and improvement.
5.2 Advanced Directions
-
Automated chaos experiments: Integrate chaos experiments into the CI/CD process.
-
Game day activities: Organize regular chaos engineering drills.
-
Expand fault types: Explore more fault injection scenarios, such as data corruption, clock skew, etc.
-
Chaos experiment metrics: Establish an evaluation system for the effectiveness of chaos engineering.
5.3 Precautions
-
Before executing chaos experiments in production, ensure that there are comprehensive monitoring and rollback mechanisms.
-
Start experiments in small, non-critical systems.
-
Chaos engineering is not about creating chaos, but about building confidence in system behavior.
-
Continuously iterate on experiment design and improve the system based on findings.
Chaos engineering is not only a technical practice but also a mindset that helps us build a deep understanding and confidence in complex systems.
5.4 Next Episode Preview
K8S Lecture 25: Advanced Chaos Engineering
Follow “Testing Across” to explore the infinite possibilities of technology!
Review of previous K8S series:
K8S Lecture 22: Deployment of Harbor Image Repository and Integration with GitLab CI