As computer programming technology continues to evolve, people’s understanding of the Python language has deepened, and Python has gradually developed into a programming language widely favored by programmers. This section will introduce an overview of the Python language, its development history, and Python library files.
1 Overview and Development History of Python Language
The Python language, as a development tool beloved by software developers, is an object-oriented language. Since its inception in the early 1990s, it has been widely used in scientific computing such as machine learning, deep learning, and image recognition. Especially in the current era of big data, Python is increasingly popular among developers, frequently used by personnel in higher education institutions, research organizations, and the IT industry for its powerful data processing and visualization capabilities. With each version update, more and more toolkits have been added to Python, further enhancing its data processing capabilities. Currently, Python has become the best choice for solving big data algorithm problems.
The founder of Python is Guido van Rossum from the Netherlands. Throughout its development, many versions have emerged, with the first Python released on October 16, 2000, and Python 3 released on December 3, 2008. In 2010, Python was rated as the most favored language by programmers.
Its characteristics:
Currently, many renowned universities both domestically and internationally, such as MIT and Carnegie Mellon, use Python as a foundational programming language in their teaching, especially in courses like program design and programming introduction.
Compared to other object-oriented languages, Python has a unique rule, namely the indentation rule, which gives Python a clear and uniform style. As Python has developed, its indentation rule has become a very important aspect of its syntax. This rule makes Python a very maintainable language, laying the foundation for its rapid global development, making it one of the most widely used and user-friendly languages.
To facilitate programmers, Python provides many convenient scientific computing packages, such as the foundational package NumPy for scientific computing, the foundational package PyTorch for deep learning, the data analysis package Pandas, the deep learning framework Caffe, the computer vision library OpenCV, the medical image processing library ITK, and the three-dimensional visualization library VTK. Below, we will introduce each of these.
2 Python Software Packages
In Python, there are many software packages for scientific computing, providing us with many convenient functions, especially in scientific computing and data analysis, solving engineering problems conveniently. These include the foundational scientific computing package NumPy, the data analysis package Pandas, and frameworks like PyTorch and Caffe2.
1. NumPy
NumPy is a foundational data package that primarily provides functions related to scientific computing in Python, capable of complex data calculations, with the following characteristics:
• Provides efficient processing functions;
• Defines N-dimensional array objects;
• Supports vectorized operations;
• Stores large matrices and vector processing;
• Efficient nested list structure.
NumPy offers many data types to programmers, the most important being the N-dimensional array type ndarray, which differs from native Python lists as shown in the figure below:
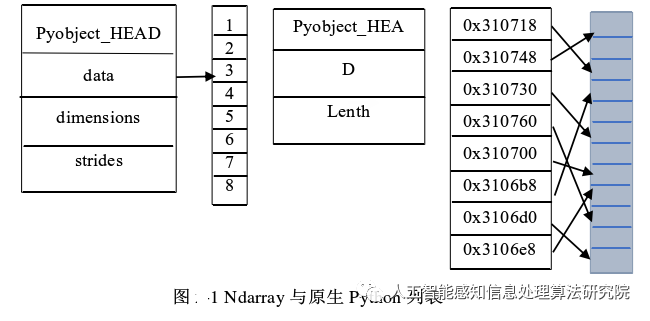
In the above image, the data types stored in ndarray are all the same, while the data types in native Python lists can be arbitrary. This means that the storage addresses of data in ndarray are contiguous, while data in native Python lists are stored randomly. This storage method allows ndarray to process array elements faster in bulk.
2. Pandas
Pandas is a data analysis package included in the NumPy foundational package, specifically developed to solve data analysis tasks, with the following characteristics:
• Open-source nature, Pandas is released as open-source;
• Defines data structures of different dimensions;
• Defines various data types, including strings and booleans.
3. PyTorch
PyTorch is a deep learning framework developed by the Facebook team, characterized by:
• Using dynamic computation graphs;
• Utilizing GPUs for computation;
Therefore, once released, PyTorch was favored by many developers and researchers, becoming one of the most popular tools in the field of artificial intelligence. Its advantages include:
• Simple code that is easy to understand: The design of PyTorch adopts a low-to-high abstraction level, pursuing minimal encapsulation, making its code more acceptable to developers;
• High operational speed: In many evaluations, PyTorch has a speed advantage compared to other deep learning frameworks;
• Friendly and easy-to-use interface: PyTorch inherits the interface design from Torch, allowing developers to focus on implementing their ideas without worrying too much about the framework itself;
• Mature community service: The online community provided by the Facebook research team facilitates mutual discussion among developers, online communication, and detailed guide documentation, making program development more convenient.
PyTorch leverages its advantages for efficient production and flexible experimentation. Its convenience and high computational efficiency, along with its unique advantages, allow it to stand out among many deep learning frameworks, making it one of the most effective tools for artificial intelligence processing.
4. Caffe2 Package
Caffe2 (Convolutional Architecture for Fast Feature Embedding 2) was released on April 18, 2017, developed in C++, and is a typical open-source deep learning framework that can run on both CPUs and GPUs. Its characteristics include simplicity of use, fast running speed, easy code extensibility, and a mature community, making Caffe2 widely adopted by many research and development personnel upon its release.
Caffe and Caffe2 are two typical deep learning frameworks, but they have significant differences in their input and hidden layers, as shown in the following figure:
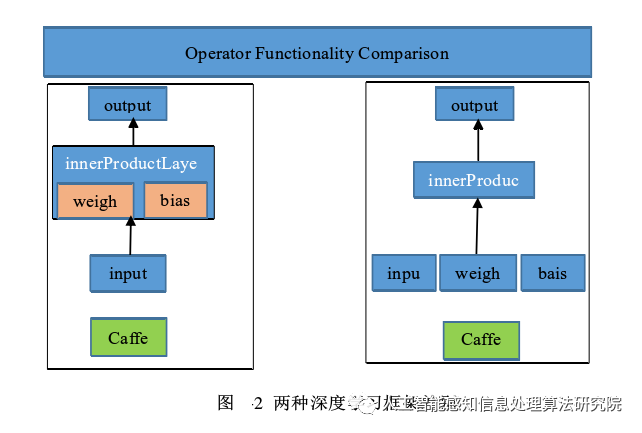
From the figure, we can see that Caffe2 has moved the weight and bias values from Caffe to the input layer, with the middle hidden layer called Operators. An Operator is the basic computational unit of Caffe2, each Operator includes the required computational logic. This difference is also reflected in the structure of the neural network. The Caffe network consists of coarser-grained layers, where the weight and bias values are stored at the layer level. While this approach is simple and intuitive, it has the following disadvantages:
(1) Platform optimization is cumbersome; when optimizing for ARM, not only must the ARM implementation for that layer be achieved, but other code sections must also be modified.
(2) The caffe.proto file needs to be modified to add new layers, and recompilation is required, which becomes particularly complex when adding multiple layers.
(3) The parameters for bias and weight values are tied to the layer, making setup complex.
In Caffe2, since the weight and bias values are moved to the input layer, each layer can be composed of finer-grained operators. Additionally, other deep learning frameworks are adopted. The advantages of Caffe2 include:
(1) Support for multiple platforms; in Caffe2, operators are merely the logic for processing data, allowing for targeted optimizations, including optimizations for multiple operator combinations.
(2) Easier generation of new layers; each layer becomes a combination of operators, separating the parameters for weight and bias values. On the other hand, it also allows for more convenient control of weight and bias values. For example, treating weight and bias values as parameters can transform a single function into a class of functions.
(3) Efficient code writing; neural networks can be written in a declarative manner, akin to writing documents in LaTeX, using a WYSIWYG approach.
Caffe2, as an outstanding open-source deep learning framework, significantly reduces the learning difficulty for both novices new to deep learning and professional developers, judging from its structure, performance, code quality, and the thoroughness of its official documentation and examples. Currently, Caffe can fully utilize NVIDIA’s GPU deep learning platform and seamlessly switch between CPU and GPU based on operational status.