For a period of time, I used <span>shared_ptr</span> throughout a server-side project, from construction to parameter passing and storage in containers, but the P99 jitter on a single path could not be suppressed. After gradually replacing the hot paths with <span>unique_ptr</span> / raw pointers, the latency tail significantly converged.
This article will follow that review and clarify the true cost of <span>shared_ptr</span>: it is expensive due to control blocks + atomic reference counting + possible additional allocations; whereas raw pointers only perform addressing without ownership management.
📚 The C++ Knowledge Base has been launched on ima! The current content covered by the knowledge base is shown in the image below👇👇👇
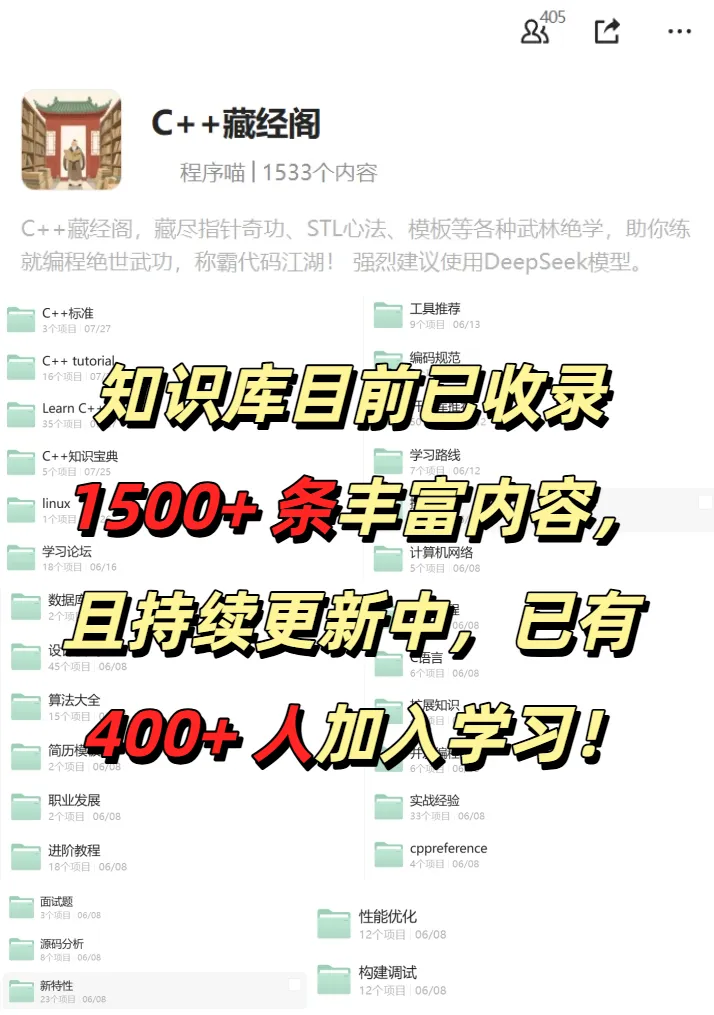
📌 Students interested in the knowledge base can add the assistant vx (chuzi345) with the note 【Knowledge Base】 or click 👉 C++ Knowledge Base (tap to jump) to view the complete introduction to the knowledge base~
1. First, provide a reliable conclusion boundary
- Copying/Destroying is Expensive:
<span>shared_ptr</span>copying requires atomic increment counting, and destruction requires atomic decrement counting and may trigger destruction; raw pointers only perform literal transportation. - Allocation may be more frequent:
<span>shared_ptr<T>(new T)</span>typically results in two allocations: one for the object + one for the control block (which includes strong/weak counts, deleters, etc.).<span>make_shared<T></span>can merge into a single allocation, significantly improving locality. - Thread Safety → Introduces Barriers/Bus Traffic: C++11 requires that counting operations on the same control block be thread-safe, usually implemented through atomic instructions; under high concurrency, these atomic operations introduce cache coherence traffic.
- Read Path Differences are Minimal: Once you obtain
<span>T*</span>, dereferencing to access data shows minimal instruction-level differences; the main differences in hot paths come from the frequency of ownership operations and allocation behavior. - The gap in real projects depends on “copy density & allocation heat”: The more frequent the copying/passing/adding to containers, the more pronounced the additional cost of
<span>shared_ptr</span>; the more<span>make_shared</span>is used and the less cross-thread sharing occurs, the closer it gets to raw pointers.
2. Where does the cost of <span>shared_ptr</span> come from?
2.1 Control Block
The control block contains at least: strong reference count, weak reference count, deleter/allocator records, and the object pointer (except in the case of <span>make_shared</span>). This means:
- Additional Memory Access (reading/updating counts touches the control block).
- Additional Allocations (not using
<span>make_shared</span>).
2.2 Atomic Counting
- Copy Construction/Assignment: strong count
<span>fetch_add</span>. - Destruction/Reset: strong count
<span>fetch_sub</span>, destroys the object when it reaches 0 and adjusts the weak count. - Cross-Thread Sharing: atomic instructions cause cache lines to transfer between cores, amplifying latency and jitter.
3. Minimal Reproducible Experiment (Beware of Testing Pitfalls)
Below is a relatively “neutral” micro-benchmark. It does not perform IO, does not print, does not allocate in loops (<span>make_shared</span> is prepared in advance), and separates data access from ownership operations to avoid mixing Cache Miss, branches, and other factors into “ownership costs”.
Tip: Micro-benchmarks can only show trends; do not take the numbers below as the “standard answer” for your machine.
#include <chrono>
#include <iostream>
#include <memory>
#include <vector>
#include <numeric>
struct Node {
int x;
double y;
void touch() noexcept { x += 1; y *= 1.0000001; }
};
template <class F>
long long bench(F&& f, int iters) {
using namespace std::chrono;
auto t0 = steady_clock::now();
f();
auto t1 = steady_clock::now();
return duration_cast<nanoseconds>(t1 - t0).count() / iters;
}
int main() {
constex print N = 1'000'000;
// Case A: shared_ptr copy/destroy cost (excluding allocation)
std::vector<std::shared_ptr<Node>> pool;
pool.reserve(N);
for (int i = 0; i < N; ++i) pool.emplace_back(std::make_shared<Node>());
auto cost_shared_copy = bench([&] {
long long sum = 0;
for (int i = 0; i < N; ++i) {
auto p = pool[i]; // Copy: atomic +1
sum += p->x; // Read: main access
} // p destructs: atomic -1
(void)sum;
}, N);
// Case B: raw pointer "copy/destroy" (essentially assignment/no destruction)
std::vector<Node*> raws;
raws.reserve(N);
for (auto& sp : pool) raws.push_back(sp.get());
auto cost_raw_copy = bench([&] {
long long sum = 0;
for (int i = 0; i < N; ++i) {
Node* p = raws[i]; // Assignment: no counting
sum += p->x;
} // No additional operations
(void)sum;
}, N);
// Case C: pure access (same carrier, trying to strip ownership differences)
auto cost_shared_access = bench([&] {
for (int i = 0; i < N; ++i) pool[i]->touch();
}, N);
auto cost_raw_access = bench([&] {
for (int i = 0; i < N; ++i) raws[i]->touch();
}, N);
std::cout << "shared_ptr copy/dtor (ns per op): " << cost_shared_copy << "\n";
std::cout << "raw ptr copy (ns per op): " << cost_raw_copy << "\n";
std::cout << "shared_ptr access (ns per op): " << cost_shared_access << "\n";
std::cout << "raw ptr access (ns per op): " << cost_raw_access << "\n";
}
How to Read the Results
<span>shared_ptr copy/dtor</span>vs<span>raw ptr copy</span>difference mainly reflects the cost of atomic counting (non-zero even in non-competitive situations, and will further amplify under multi-core competition).<span>shared_ptr access</span>vs<span>raw ptr access</span>being close indicates that the core read path differences are minimal; if the deviation is large, it is mostly due to locality/cache and compiler optimization effects (it may also be that you have disabled optimization options).
4. Why is there sometimes a large difference, and sometimes almost none?
- Business is “copy-intensive” (e.g., repeatedly
<span>push_back</span>/<span>emplace</span>in containers, passing parameters by value across layers), the gap will be amplified. - Business is “access-intensive/IO-dominated” (large amounts of operators, network/disk IO), ownership costs are submerged, and
<span>shared_ptr</span>and raw pointers experience similar performance. - Whether it is shared across threads: passing
<span>shared_ptr</span>across threads will frequently cause the control block’s cache line to move between cores; temporary copies in a single thread incur much less overhead. - Whether to use
<span>make_shared</span>: whether it can merge allocations often determines whether one-time jitter on the path is visible. - **Whether to misuse
<span>enable_shared_from_this</span>/<span>weak_ptr</span>**: weak counts are also on the control block, increasing write pressure (especially in high-concurrency structures).
5. Usage Guidelines from an Engineering Perspective (How I Write Now)
- Default Ownership
- Unique Ownership:
<span>unique_ptr<T></span>(zero atomic, zero sharing, the lightest). - **Use
<span>shared_ptr<T></span>only when sharing is needed**: and clearly define “who owns it, who breaks the cycle”. - Non-ownership Semantics: prefer passing parameters using
<span>T&/const T&</span><span> or </span><code><span>T*</span>, do not pass<span>shared_ptr</span>everywhere for convenience.
- No need to extend the lifecycle:
<span>const T&</span>/<span>T*</span>. - Need to share and extend the lifecycle:
<span>shared_ptr<T></span>passed by value (clearly expresses “I want to increase one ownership”). - Only observe without holding:
<span>std::weak_ptr<T></span><code><span> (lock() at the boundary, be careful of null checks).</span>
- If
<span>make_shared<T>(...)</span><span> can be used, do not use </span><code><span>shared_ptr<T>(new T)</span><span>, to reduce one allocation and pointer indirection;</span> - For large objects or when a custom deleter/alignment is needed, evaluate whether it is still suitable to use
<span>make_shared</span><span> (custom deleters cannot use </span><code><span>make_shared</span><span>, in which case consider object pools or dedicated allocators).</span>
- Storing
<span>shared_ptr</span>in containers will make every copy/move carry atomic counting; when building in bulk, reserve first to reduce transport times; - Avoid frequently constructing/destructing
<span>shared_ptr</span>in critical paths of high concurrency; if necessary, move “count increment/decrement” outside the lock or use object caching.
- Ownership graphs need to have “roots” and “leaves”, and cycle boundaries should be broken with
<span>weak_ptr</span>; - UI/callback code should avoid “mutual holding”, using weak references on one end.
6. Common Misconceptions Correction
- “
<span>shared_ptr</span>is slow, don’t use it”: Exaggerated. It solves semantic issues like shared ownership; in most non-hot code, its cost is acceptable. - “Passing
<span>const shared_ptr<T>&</span>is more efficient”: If the caller needs to increase ownership, passing by value is clearer (one copy + RVO/move optimization);<span>const&</span><span> may obscure semantics.</span> - “Just use raw pointers”: When there is cross-domain/asynchronous lifecycle extension, raw pointers cannot express “who is responsible for releasing”, ultimately transferring complexity to more hidden places.
7. A More Practical Splitting Strategy
Divide the link into three segments: Creation → Propagation → Usage
- Creation: Try to use
<span>make_shared</span>; concentrate construction and reduce temporaries. - Propagation: Only copy a
<span>shared_ptr</span>when it is truly necessary to extend the lifecycle; everywhere else use<span>T*</span>/<span>T&</span>. - Usage: Operations after obtaining
<span>T*</span>are basically consistent with raw pointers—this part shows minimal differences.
8. Summary
- Is shared ownership really needed? If
<span>unique_ptr</span>can be used, do not use<span>shared_ptr</span>. - Have you used
<span>make_shared</span>? If it can merge allocations, do so. - Are parameter passing semantics clear? Pass
<span>shared_ptr</span>by value to extend the lifecycle; otherwise, use references/pointers. - Have you placed counting operations in hot critical paths? Try to move them out.
- Have containers been reserved? To reduce unnecessary copies.
- Are there any cycle references? Use
<span>weak_ptr</span>to break cycles.
The performance gap does not have a fixed multiple: In scenarios that are “copy-intensive + cross-thread sharing”, <span>shared_ptr</span> can be an order of magnitude slower than raw pointers; in “computation/IO-dominated” scenarios, the gap is often negligible. The key is to place ownership semantics in the right position, remove expensive atomic counting from hot paths, and let <span>shared_ptr</span> do what it excels at, rather than being the “default pointer” everywhere.
Many students are currently participating in autumn recruitment/preparing for job changes, and we have launched 👉C++ Project Practical Camp, in addition to systematically sorting out C++ basic and advanced knowledge, you can also choose from the project pool to work on C++ practical projects from 0 to 1!

1v1 personal review of code by mentors + professional guidance for Q&A
Regular problem-solving/studying can only improve coding skills, but during interviews, companies value your ability to build projects from 0 to 1 and solve real problems!
Our training camp is designed for this goal:
- Full process practical projects: development environment, compilation scripts, architecture design, framework setup, code release, problem debugging, unit testing.
- Exercise full-process capabilities from requirement analysis to task breakdown and version management
- Improve your debugging skills, problem localization techniques, and master more real-world skills
- Complete project materials: source code + comments + videos + documentation are all included
- 1v1 online Q&A with mentors, helping you to complete the project effectively!
Students interested can reply with the keyword: training camp to view the training camp introduction or directly add vx (chuzi345), to quickly learn about the training camp details!
Trust me, these projects will definitely help you improve significantly! Below are descriptions of some of the projects
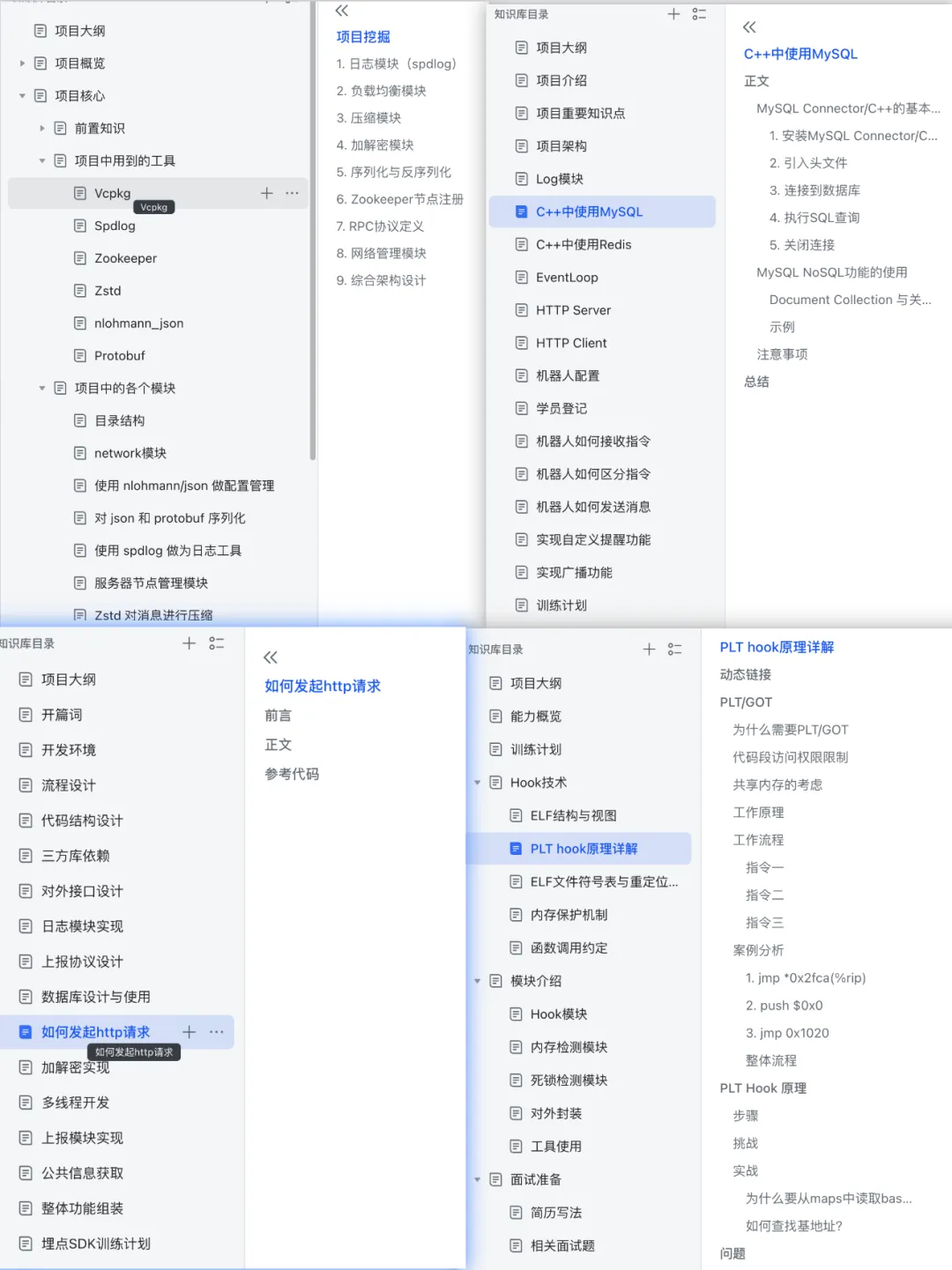
Target Audience for the Training Camp:
- Graduates preparing for spring and autumn recruitment, both majoring and non-majoring in the field,
- Students with less than 3 years of work experience looking to change jobs
- If you have the following concerns, feel free to contact us, and we are willing to provide help and support
- Not sure what content to review or how to start reviewing.
- Unclear about the key points of the interview assessment, low review efficiency.
- Lack of valuable practical project experience.
- Want to improve practical abilities, enhance project execution and problem-solving skills
- Struggling with algorithm questions, lacking problem-solving ideas and common templates.
- Lacking self-discipline, finding it hard to focus on systematic review.
- Hoping to get internal referral opportunities from large companies.
- Feeling lonely preparing for campus recruitment and social recruitment alone, wanting to find study partners.
Not Suitable for:
- People lacking patience and perseverance, eager for quick success
- People with weak programming logic thinking foundation who are unwilling to improve
- People who only want quick results without focusing on foundational learning
Recommended Reading:
Common Misunderstandings in Using C++ Virtual Destructors: From Resource Leaks to Correct Solutions
Old iostream.h vs Standard iostream: One Mistake, Three Explosions!
Writing Exceptions is Like Hell, std::expected Revives C++ Error Handling!