Voice recognition, as an important method of human-computer interaction, is gradually becoming one of the core functions of smart devices. However, traditional voice recognition systems often rely on cloud servers for audio data processing and analysis, which brings issues such as latency and privacy.
TensorFlow Lite provides an efficient and fast solution for voice recognition on local devices, capable of running in resource-constrained environments and having fast inference capabilities. By deploying the voice recognition model on local devices, it reduces reliance on cloud servers.
This article will introduce how to build a local voice recognition system using TensorFlow Lite, including voice front-end processing, training the voice recognition model, and how to convert it to TensorFlow Lite format and deploy it on ESP32.
2. Voice Feature Extraction
Audio Signal Acquisition and Transmission
The input for voice recognition is audio signals, which are fluctuations of sound over time. Audio signals can be collected through microphones or other recording devices.
-
Sample Rate:The sample rate refers to the number of times audio signals are sampled per second. Common sample rates include 8KHz, 16KHz, 44.1KHz, and 48KHz. The sample rate determines the frequency range and fidelity of digital audio.
-
Bits per Sample:The bits per sample describe the number of bits used for each sample during the audio digitization process. In digital audio, sound waveforms are represented by quantizing discrete digital values at each sample point. The bits per sample define the number of discrete levels each sample can express. Higher bits indicate greater accuracy and dynamic range, capturing audio signal details and variations more precisely. Common bit depths for audio include 8-bit, 16-bit, and 24-bit. 16-bit is the standard for CD quality, while 24-bit offers a higher dynamic range. Higher bit depths consume more storage space and bandwidth but provide better audio quality.
-
I2S (Inter-IC Sound):I2S is a digital audio transmission interface standard used for transmitting audio data and clock signals between audio devices. It is typically used for transmitting mono or stereo audio data and supports high-quality audio transmission.
-
PCM (Pulse Code Modulation): PCM is a basic audio encoding method that converts analog audio signals into digital signals. PCM samples audio signals and discretizes the amplitude values of each sample point into fixed bit-length digital values, typically using 16-bit or 24-bit to represent each sample.
-
PDM (Pulse-Density Modulation): PDM is an audio encoding method that represents the continuous variation of audio signals through pulse density modulation. PDM encoding uses the number and frequency of pulses to represent the amplitude and frequency of audio signals, suitable for high-resolution and high-dynamic-range audio data transmission.
-
TDM (Time-Division Multiplexing): TDM is an audio communication mode used to transmit multiple audio data streams over a single interface. By using time-division multiplexing technology, TDM can simultaneously transmit multiple audio data streams over a single interface. Each audio data stream is allocated to different time slots, transmitted sequentially in time order.
Audio Feature Related Concepts
Before voice recognition, audio signals usually need preprocessing, including noise reduction, volume normalization, voice activity detection, etc., to improve the accuracy and robustness of voice recognition.
-
Time Domain and Frequency Domain:Audio signals can be analyzed in both time and frequency domains. The time domain represents the changes of signals over time, while the frequency domain represents the frequency components of signals.
-
Fourier Transform: The Fourier transform is a method for converting signals from the time domain to the frequency domain, representing signals as a sum of frequency components.
-
Spectrogram: A spectrogram is a graphical representation used to visualize the frequency content of audio signals over time. It can represent the frequency spectrum information of audio signals with time on the horizontal axis and frequency on the vertical axis, using color or grayscale to indicate the amplitude or energy of the signal. Spectrograms are commonly used in audio signal analysis, voice recognition, music processing, etc., providing an intuitive understanding of the spectral and temporal characteristics of audio signals.
-
Mel Spectrum: Spectrograms are often large images, and to obtain appropriately sized sound features, they are often transformed into Mel spectra using Mel-scale filter banks. Mel frequency (Mel scale) is a nonlinear frequency scale designed to simulate human ear perception of audio. It is based on how the human ear perceives different frequencies, as the ear is more sensitive to low frequencies and less sensitive to high frequencies. In audio signal processing, converting frequencies to Mel frequencies provides a feature representation that better aligns with human auditory perception, aiding in improving audio processing algorithms’ performance and effectiveness.
-
Center Frequency: The center frequency is used to describe the central position of frequency bands or filters, which can be used to analyze and process the spectral characteristics of audio signals. In spectral analysis, the spectrum region is typically divided into a series of frequency bands, each with a center frequency. These bands can be of equal width or designed according to the characteristics of human auditory perception. For example, the Mel filter bank consists of a set of filters used to decompose the spectrum into Mel spectra. Each Mel filter has a center frequency representing the center position of the corresponding frequency band in the spectrum.
MFCC and Filterbank are commonly used voice features, and the feature extraction process is shown in the diagram below:
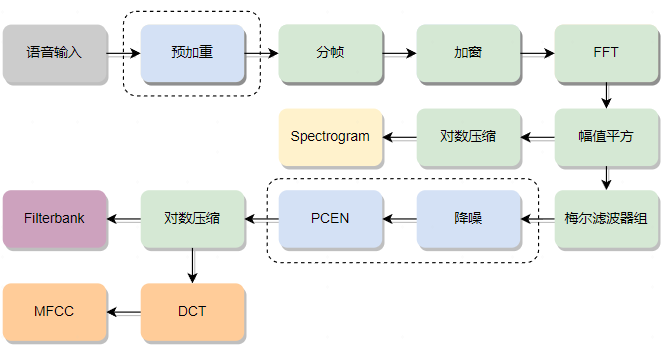
Pre-emphasis is used to enhance the energy of high-frequency components to improve the frequency response of the signal. Due to the characteristic that the amplitude of low-frequency components in audio signals is higher while that of high-frequency components is lower, this may lead to the loss of high-frequency components during transmission, making them less pronounced. Pre-emphasis solves this problem by filtering the signal, using a first-order high-pass filter (typically a difference equation, since the amplitude changes of low-frequency components are slow, the differences between adjacent sample points are small, and the difference operation can reduce the amplitude of low-frequency components; while the amplitude changes of high-frequency components are rapid, the differences between adjacent sample points are large, and the difference operation retains more amplitude of high-frequency components) to process the signal:
y(n) = x(n) - α * x(n-1) where, x(n) is the current sample point of the input signal, x(n-1) is the value of the previous sample point, y(n) is the output signal after pre-emphasis, α is the gain coefficient of the pre-emphasis filter.
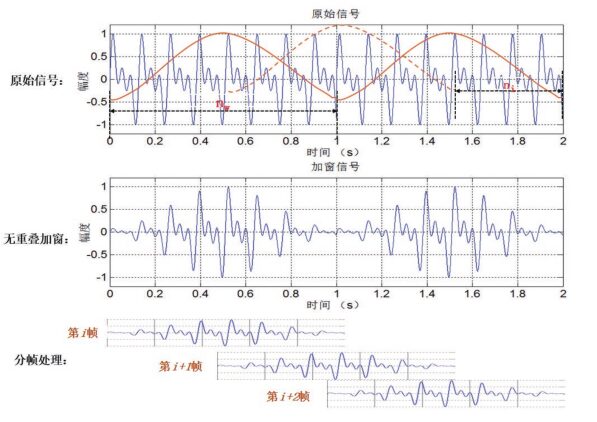
Framing is the process of dividing the variable-length audio into fixed-length segments. Since voice signals change rapidly and the Fourier transform is suitable for analyzing stationary signals, framing allows us to assume that the spectrum is stationary within each frame, enabling frequency domain analysis and processing. In voice recognition, the frame length is generally set to 10~30ms, ensuring that each frame contains enough cycles without too rapid changes.
Each frame of the signal is usually multiplied by a smooth window function, allowing the signal at the edges of the frame to smoothly decay to zero, which helps reduce the sidelobe intensity after the Fourier transform, achieving higher quality spectra.

As shown in the diagram below[1], after windowing, the signal at the connection between frames will be weakened, causing information loss. Since the Fourier transform is performed frame by frame, to avoid missing signals at the window boundaries, there should be overlap when offsetting frames.
(4) FFT Transform and Energy Spectrum Calculation
The Fourier transform can convert signals from the time domain to the frequency domain. The Fourier transform can be divided into continuous Fourier transform and discrete Fourier transform, and since digital audio (not analog audio) is used, the discrete Fourier transform is applied.
After the Fourier transform, the frequency domain signal is obtained, with different energy levels for each frequency band. The energy spectrum of different phonemes varies. A common calculation method is as follows:
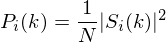
The conversion formula from Mel frequency to actual frequency is as follows:
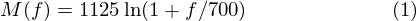
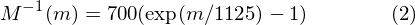
Mel filter banks usually need to set upper and lower frequency limits, filtering out unnecessary or noisy frequency ranges (the lower limit is generally set around 20Hz, and the upper limit is half of the audio sampling rate), and converting them to Mel frequencies. Then, k triangular filters are configured on the Mel frequency axis, where k is generally 40. The triangular window function is:
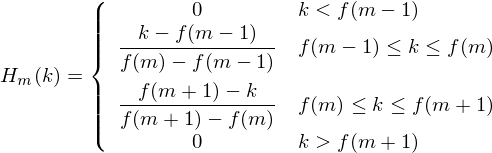
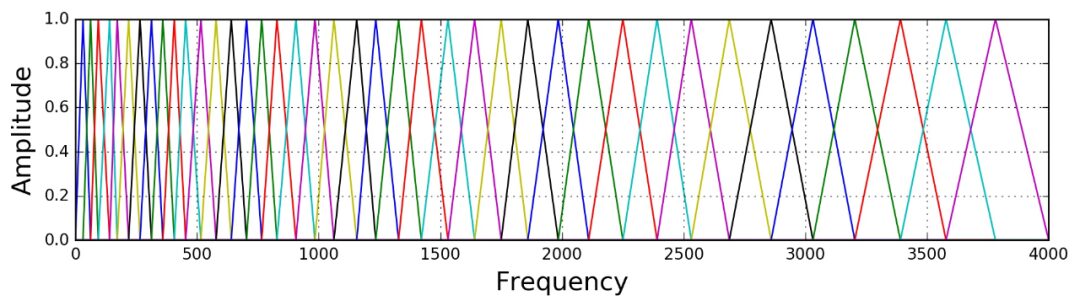
Where k represents the number of triangular windows, f(m) represents the frequency corresponding to each point after dividing the Mel frequency axis into k+1 parts (i.e., K+2 points). For instance, if we set 40 triangular windows in the range of 0-4000, the image on the Hz frequency axis is as follows[2]:
A common method for noise reduction on the output of Mel filter bank is spectral subtraction. Spectral subtraction is based on the assumption that the original signal is stationary in the frequency domain while the noise signal is non-stationary. Therefore, by comparing the signal spectrum with the estimated noise spectrum, the noise components in the signal can be estimated and subtracted.
(7) PCEN Channel Energy Normalization
PCEN (Per-Channel Energy Normalization) algorithm is a feature enhancement technique used in audio processing and voice recognition, aiming to improve the perceptibility and robustness of voice signals. The PCEN algorithm is based on the idea of perceptual contrast enhancement, normalizing and smoothing the audio signal to enhance useful information within the signal.
Specifically, the PCEN algorithm first calculates the energy of each frequency band, then normalizes the energy to reduce differences between different frequency bands, and finally applies a smoothing filter to the normalized energy to enhance the stability and robustness of the signal.
The diagram below[3] shows a soundscape including birds chirping, insects buzzing, and a passing vehicle. In (a), the logarithmic transformation of the Mel frequency spectrum maps all amplitudes to a scale similar to decibels; while in (b), channel energy normalization enhances transient events (bird chirping) while discarding static noise (insects) and sounds with slowly varying loudness (vehicles).
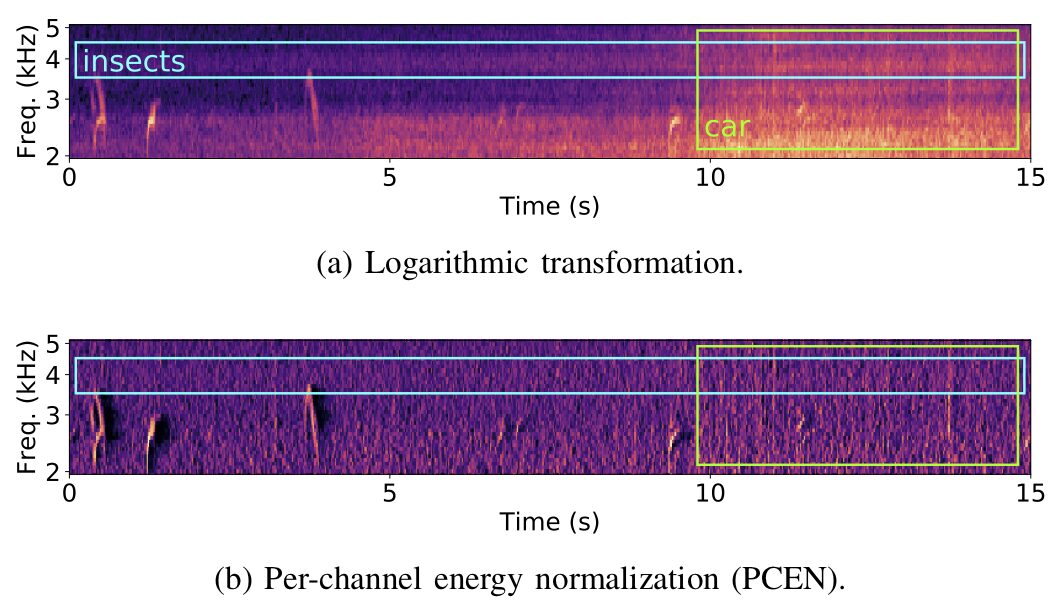
Log compression can amplify energy differences at low-energy areas.
DCT (Discrete Cosine Transform) is a linear transformation that converts signals from the time domain to the frequency domain by performing weighted sums on the signal to obtain the frequency domain representation. By performing DCT on the Filterbank, MFCC features can be obtained. MFCC and Gaussian Mixture Model – Hidden Markov Model (GMM-HMM) have evolved together to become standard methods for automatic speech recognition (ASR). Since DCT is a linear transformation, it retains only the linear characteristics of the signal but may discard some highly nonlinear information in the voice signal. Therefore, with the emergence of deep learning in voice systems, when deep neural networks are insensitive to highly correlated inputs, Filterbank is often chosen over MFCC as the feature input for voice signals to be learned by the neural network.
3. Model Training and Deployment
The model parameter initialization function is defined in models.py, in the Demo:
-
Sample rate used: sample_rate=16000
-
Audio data length: clip_duration_ms=1000
-
Frame size: window_size_ms=30
-
Frame stride length: window_stride_ms=20
-
Feature dimensions: feature_bin_count=40
def prepare_model_settings(label_count, sample_rate, clip_duration_ms, window_size_ms, window_stride_ms, feature_bin_count, preprocess): # Desired sample rate: 16000 desired_samples = int(sample_rate * clip_duration_ms / 1000) # Number of sample points per frame: 480 window_size_samples = int(sample_rate * window_size_ms / 1000) # Number of moving sample points per frame: 320 window_stride_samples = int(sample_rate * window_stride_ms / 1000) length_minus_window = (desired_samples - window_size_samples) if length_minus_window < 0: spectrogram_length = 0 else: # Spectrogram length: 1 + (16000-480)/320 = 49 spectrogram_length = 1 + int(length_minus_window / window_stride_samples) if preprocess == 'average': fft_bin_count = 1 + (_next_power_of_two(window_size_samples) / 2) average_window_width = int(math.floor(fft_bin_count / feature_bin_count)) fingerprint_width = int(math.ceil(fft_bin_count / average_window_width)) elif preprocess == 'mfcc': average_window_width = -1 fingerprint_width = feature_bin_count elif preprocess == 'micro': average_window_width = -1 # Voice
