Click the card below to follow the “LiteAI” public account
Hi, everyone, I am Lite. A while ago, I shared the Efficient Large Model Full-Stack Technology from Part 1 to Part 19, which includes content on large model quantization and fine-tuning, efficient LLM inference, quantum computing, generative AI acceleration, etc. The content links are as follows:
Efficient Large Model Full-Stack Technology (Nineteen): Efficient Training and Inference Framework | TorchSparse++: Efficient Training and Inference Framework for Sparse Convolutions on GPU
Subsequent content will be updated, stay tuned!
The first two articles of the TinyML project are related to efficient ML systems:
TinyML Project (One): Efficient ML System | TinyChat: Visual Language Model and Edge AI 2.0
TinyML Project (Two): Efficient ML System | TinyChat Engine: On-device LLM Inference Library
In the efficient large model full-stack technology section, I also shared efficient ML-related articles — PockEngine:
Efficient Large Model Full-Stack Technology (Thirteen): On-device Training | MICRO 2023 PockEngine: Pocket-sized Sparse Efficient Fine-tuning
The first two articles on Efficient CNN Algorithms & System Co-design:
TinyML Project (Three): Efficient CNN Algorithms & System Co-design | MCUNetV3: Device-side Training with 256KB Memory
TinyML Project (Four): Efficient CNN Algorithms & System Co-design | TinyTL: Reducing Activation Counts and Non-trainable Parameters for Efficient Learning on Devices
Overview of Block Sparse Attention
1. Background
– Large Language Models (LLMs) perform exceptionally well in tasks such as multi-turn dialogue, long document summarization, and multi-modal understanding.
– Traditional attention mechanisms incur high computational costs when handling long sequences, with latency and pre-fill time increasing as sequence length grows.
– FlashAttention, Big Bird, and ETC have proposed block sparse attention patterns to reduce computational costs.
2. Block Sparse Attention
– Provides various sparse attention patterns, including flow attention (token-level and block-level) and block sparse attention.
– Supports assigning different patterns for different attention heads.
3. Performance Improvement
– Compared to dense FlashAttention2 2.4.2, block sparse attention achieves significant acceleration on A100 GPUs.
– It also shows good performance improvement in mixed masking scenarios (with some attention heads using dense masks and others using flow masks).
4. Conclusion
– Block sparse attention effectively reduces computational costs by leveraging sparsity, enhancing the efficiency of processing long sequences.
– It paves the way for efficient handling of long context LLM/VLM services.
TL;DR
Block sparse attention is a sparse attention kernel library that supports various sparse patterns, including token-level flow attention, block-level flow attention, and block sparse attention. By combining these patterns, block sparse attention can significantly reduce the computational costs of LLMs, improving their efficiency and scalability. The author has released an implementation of Block Sparse Attention based on FlashAttention 2.4.2.
Today, LLMs are transforming AI applications, supporting complex tasks such as multi-turn dialogues, long document summarization, and multi-modal understanding involving images and videos. These tasks often require processing large amounts of context tokens. For example, summarizing long documents like the Harry Potter series may involve millions of tokens. In the field of visual understanding, the challenges are even more pronounced. Assuming a 224×224 image corresponds to 256 tokens, a 3-minute video at 24 FPS would generate over a million tokens.
Processing long context inputs poses significant challenges to the efficiency of inference systems. Traditional attention requires each token to attend to all previous tokens, leading to linear growth in decoding latency and quadratic growth in pre-fill time as sequence length increases. This relationship makes the computational cost of processing long sequences very high, becoming a bottleneck in overall inference speed, especially the time for the first token.
To address this issue, FlashAttention, Big Bird, and ETC proposed the idea of computing attention using block sparse patterns. Duo Attention and MInference 1.0 discussed how to leverage mixed sparse patterns for faster computation. By utilizing the inherent sparsity of attention patterns, we can significantly reduce the attention costs in computation and memory usage, effectively enhancing the inference speed of LLMs with long contexts. This approach not only improves the efficiency of LLMs but also allows them to handle longer and more complex prompts without proportionally increasing resource consumption.
To this end, we introduce the sparse attention kernel library Block Sparse Attention, developed based on FlashAttention 2.4.2. It supports various sparse patterns, including token-level flow attention, block-level flow attention, and block sparse attention. By combining these patterns, block sparse attention significantly reduces the computational costs of attention, paving the way for more efficient long-context LLM/VLM services.
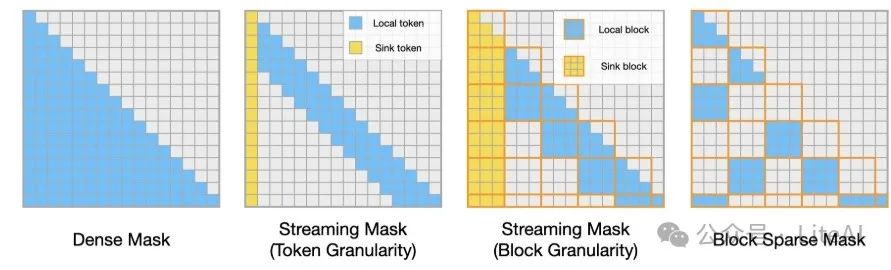
Block sparse attention supports four modes:
-
Dense Attention: Computes the full attention matrix.
-
Token-level Flow Attention: Computes attention for a fixed number of sink tokens and local tokens.
-
Block-level Flow Attention, block size 128: Computes attention for a fixed number of aggregation blocks and local blocks.
-
Block Sparse Attention, block size 128: Uses a block mask to compute attention.
More importantly, this kernel library supports assigning different patterns for different heads.
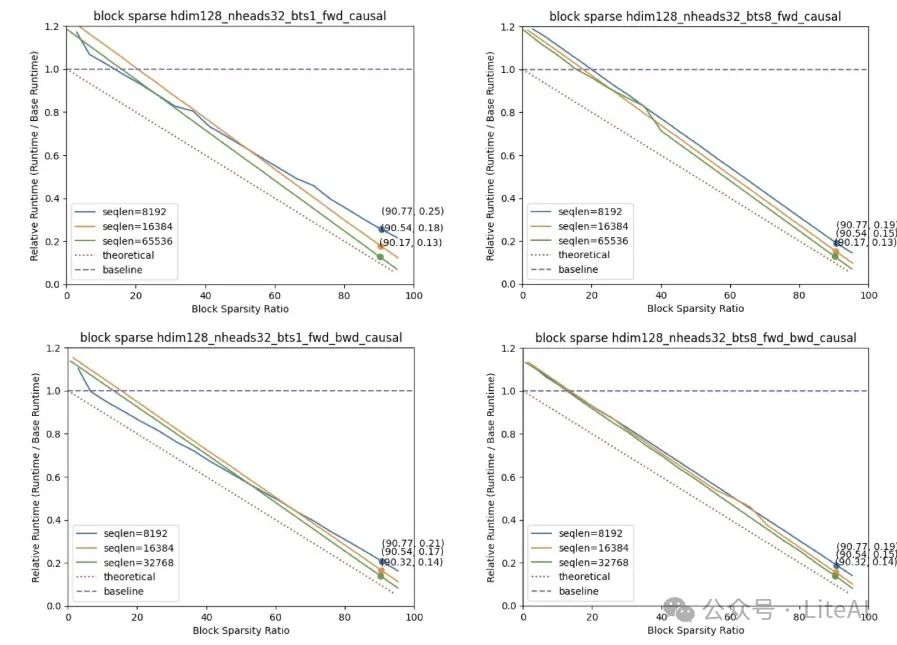
The above figure illustrates the acceleration achieved using block sparse attention compared to dense FlashAttention2 2.4.2. This acceleration was measured on A100 GPUs.
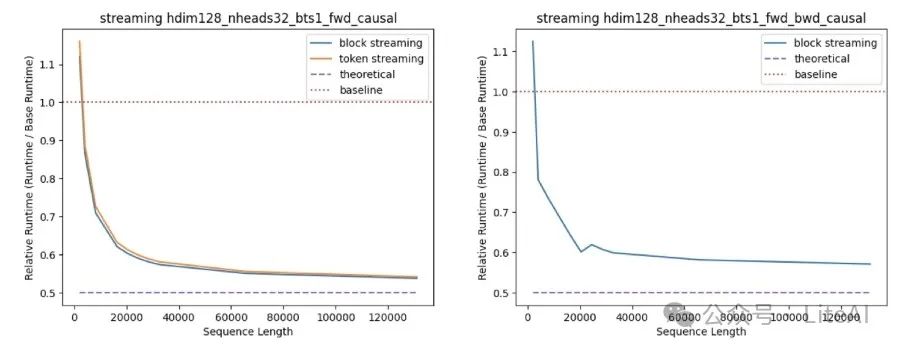
In Duo Attention, a mixed mask scheme was introduced where half of the attention heads use dense masks, and the other half use flow masks. This pattern has also proven to be an accurate method for LLM inference.
The chart above shows the performance of our kernel under this specified workload. For token-level flow masks, we allocate 64 sink tokens and 256 local tokens. For block-level flow masks, we allocate 1 sink token and 3 local tokens, with each block consisting of 128 tokens. The acceleration results were measured on A100 GPUs, using dense FlashAttention2 as a baseline, with a head size of 128, 32 attention heads, and a batch size of 1.
Reference Link: https://hanlab.mit.edu/blog/block-sparse-attention
Final Thoughts
Here, I recommend the latest course 6.5940 from hanlab for Fall 2024 (the course is ongoing).
Course Link: https://efficientml.ai
Courseware: https://pan.quark.cn/s/1324c20d7efd
Your likes, views, and follows are my greatest motivation to continue!
Scan to add me, or add WeChat (ID: LiteAI01), to discuss technology, career, and professional planning. Please note “Research Direction + School/Region + Name”